数据还原
应用场景
基于 CDC 的实时开发流程,采集工具负责采集数据库的增量日志数据,输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费这些日志数据写入到目标端,此时的目标端可以是各种 DB,数据湖,实时数仓和离线数仓。
数据还原应用场景:
- 数据还原能力。直接将上游的增量日志包括DML/DDL语句,还原为下游目标端的执行语句。最终实现的效果是上游增/删/改数据、表结构,均会在目标端同步完成相同的操作。过程不支持逻辑加工,适用于数据迁移、数据实时入湖等场景。
- 批流一体的采集任务。支持一个任务完成存量数据同步,并无缝衔接增量数据还原。
该功能仅旗舰版支持
目前支持:
- Kafka(OGG消息格式)—>Kafka/MySQL/Hyperbase 的数据还原任务
- MySQL/Oracle—>MySQL/Oracle 的批流一体采集还原任务
MySQL—>MySQL的实时采集任务数据还原
任务配置
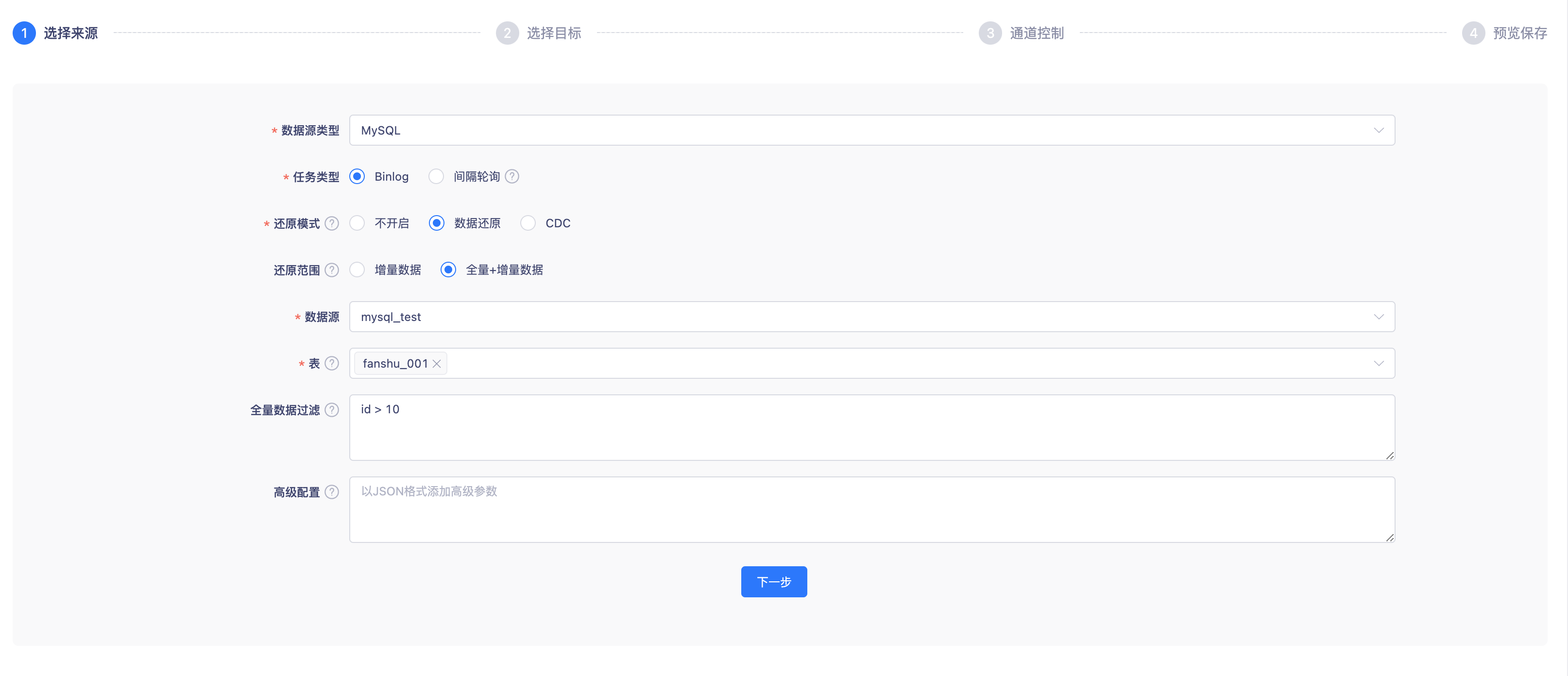
创建一个实时采集任务,数据源类型选择MySQL,任务类型选择Binlog
此时配置项中会出现一个非必选项:数据还原
MySQL开启数据还原后,目标端仅支持选择MySQL/Oracle类型
开启数据还原后,会将采集到的DML/DDL日志数据,在目标端还原为对应的执行语句
勾选数据还原后,需要再选择需要还原的数据范围。
增量数据:**采集并还原从采集起点开始,源表产生的DDL和DML日志
全量+增量数据:**先同步源表历史全量数据,完成后自动采集并还原从任务开始运行时产生的新增日志信息
目标端选择Mysql数据源。目标端的表由任务开始运行时自动创建。
相同表名:**目标端自动创建和源表相同的表名,作为采集还原的写入表
自定义表名:**目标端自动创建的表名可有常量+变量组成。比如想表示该表是从MySQL同步过来的,则可以定义表名:mysql2${tableName}
选择DDL执行方式:自动执行、手动执行
自动执行:**当源表发生DDL操作时,目标表自动执行,不影响任务状态
手动执行:当源表发生DDL操作时,该任务状态变为【DDL待处理】。您可以至【任务运维-日志-采集日志】中查看待处理的日志内容,待线下手动执行后,在日志中点击「处理」按钮修改任务状态,任务继续运行。(该方案适用于下游DDL操作不允许自动执行,需要人为介入的情况)**
选择DDL日志存储:该数据源用于存储执行失败的DDL日志和之后采集到但是未执行的堆积日志。如下拉无选项请先至「数据源中心」创建一个拥有读写权限的MySQL并引入该项目。
告警用户和方式:当任务状态变为【DDL待处理】时,提醒告警用户进行相关操作。
任务运维
开启数据还原的实时采集任务,运维内容和普通采集任务相比,在【任务运维-运行信息】里会新增【待处理的DDL操作】列表。列表会显示内容:
在任务开发时,DDL执行方式选择了手动执行
每当采集到DDL日志时,都会把源表的DDL语句、以及还原成目标端的DDL语句显示在列表中,此时任务状态变为【DDL待执行】
此时观察运行曲线,source端的采集动作依然正常执行,只是sink端无法写入。列表内会统计已堆积待执行的日志数量。(堆积日志会先打到内存中,内存满了后打到任务开发时指定的MySQL数据库。该统计数量只计算写入MySQL的部分日志)
需要开发人员复制目标端的DDL语句,线下在目标端完成执行,然后在该列表点击【处理】按钮。任务状态恢复正常,继续还原堆积的日志
在任务开发时,DDL执行方式选择了自动执行,但是执行失败的时候
列表中会打印在目标端自动执行失败的DDL日志,用户可以根据DDL语句和TM日志信息排查问题。可能会导致失败的原因有:
- 目标端的数据源链接账号没有DDL权限
- 当source端为MySQL、sink端为Oracle时,根据自动拼接创建的表名长度超过了Oracle的设置,无法建表
- source端的字段名称,和平台的保留字段相同,导致转化失败
Kafka—>MySQL数据还原任务案例
任务配置
创建一个实时采集任务,来源端数据源类型选择Kafka,并选择需要采集还原的Topic(支持多选)
目标端数据源类型选择MySQL,并选择需要还原写入的目标表(支持多选)。Kafka Format用于指定来源端的JSON格式,目前仅支持OGG格式
来源端和目标端选择多个Topic/多张表,一个任务即可实现多个Topic的采集还原
尽可能保障目标端的表结构和Topic中的数据结构相同,方便第三步的数据映射
配置数据映射:
数据映射匹配完成,在使用Insert时Kafka打入数据出现缺少字段的情况,目标端写入数据用Null值替代。
数据映射匹配完成,在使用Update时Kafka打入数据出现匹配失败的情况,目标端更新数据失败。
数据映射匹配完成,在使用Delete时Kafka打入数据出现匹配失败的情况,目标端删除数据失败。
3.1 先配置Topic和目标表的映射关系,指定Topic的数据还原至目标表关系
3.2 再配置表中字段的映射关系,指定Topic JSON中的数据结构和目标表字段的对应关系
JSON数据结构,可以通过输入Json样例数据,自动解析获取。也可以手动输入JSON中的表名、数据结构。
目标端数据结构,平台自动查询元数据获取。
数据映射支持点击同行映射或同名映射匹配数据的映射关系
字段添加支持采集元数据字段,例如:ogg Format 中的 table、current_ts、op_type、op_ts、pos这类元数据字段
- 通道控制:推荐根据Kafka的分区数量,选择对应的并行度