FlinkSQL使用自定义Connector案例
场景描述
在 Apache Flink 中,FlinkSQL 是一种声明式 SQL 语言,它允许用户以 SQL 的方式来编写流处理和批处理作业。Flink 官方提供了一系列的 Connector 来连接各种外部系统,例如 Kafka、HDFS、Elasticsearch 等。但是,由于业务的多样性,官方提供的 Connector 可能无法满足所有需求。这时,用户可以自定义 Connector 来扩展 FlinkSQL 的功能
操作步骤
前置环境准备
- 数栈6.0版本
- FlinkSQL1.12版本
- Mysql5.7数据源、Kafka2.x数据源
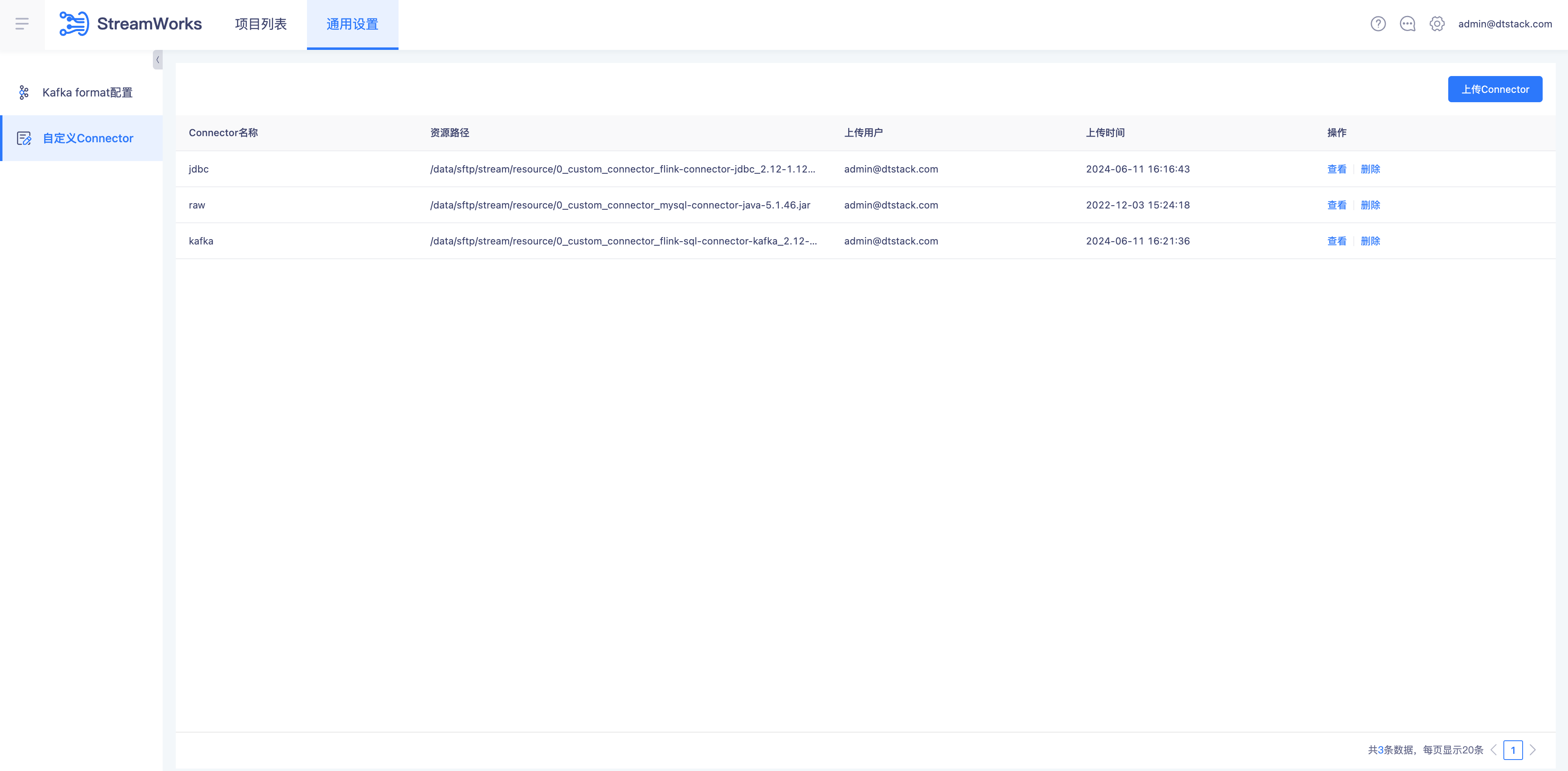
注册Connector
实时计算平台自定义Connector设置上传Connector
自定义Connector
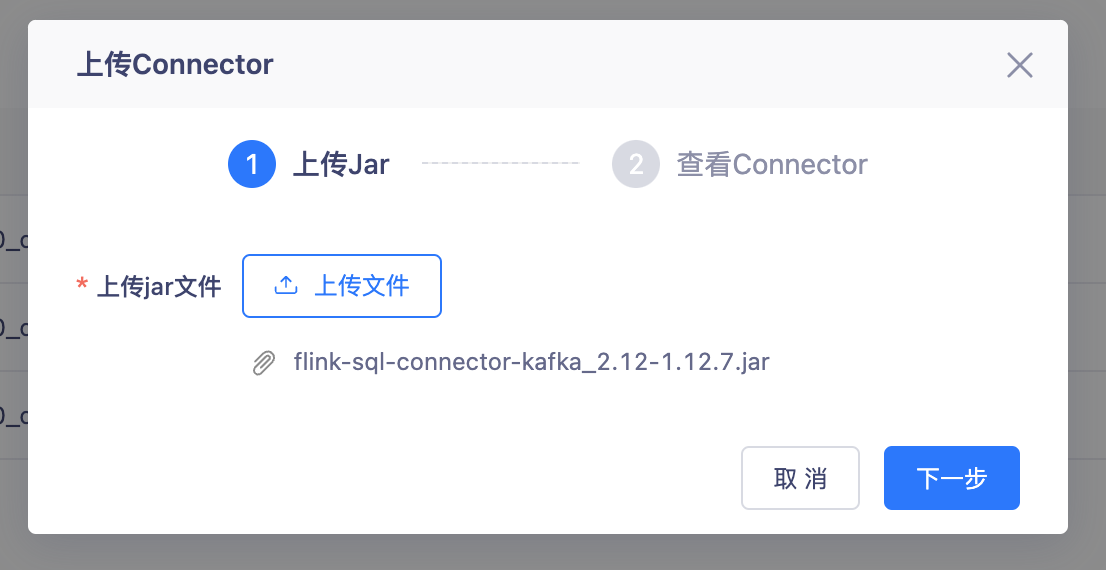
上传Kafka Connector
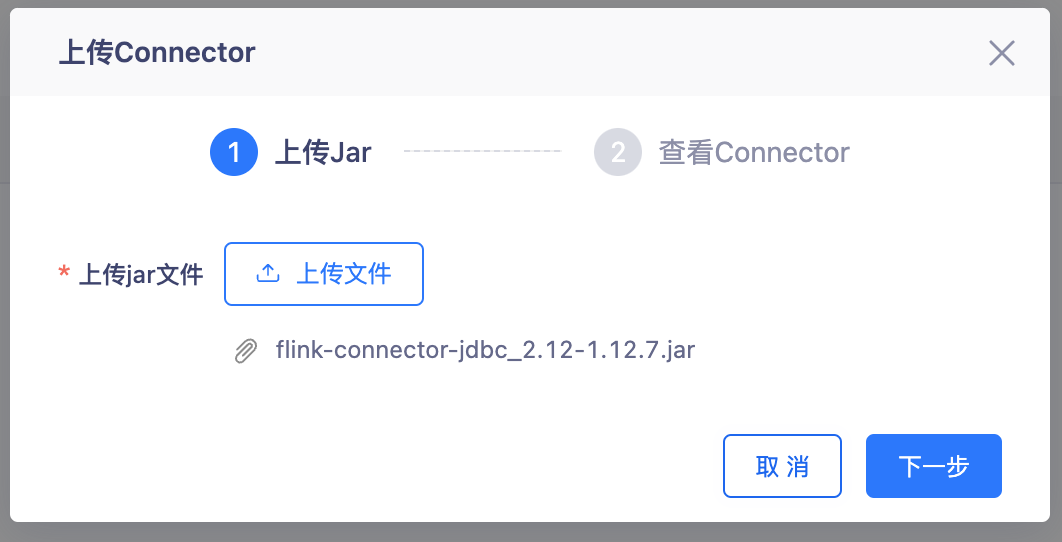
上传Jdbc Connector
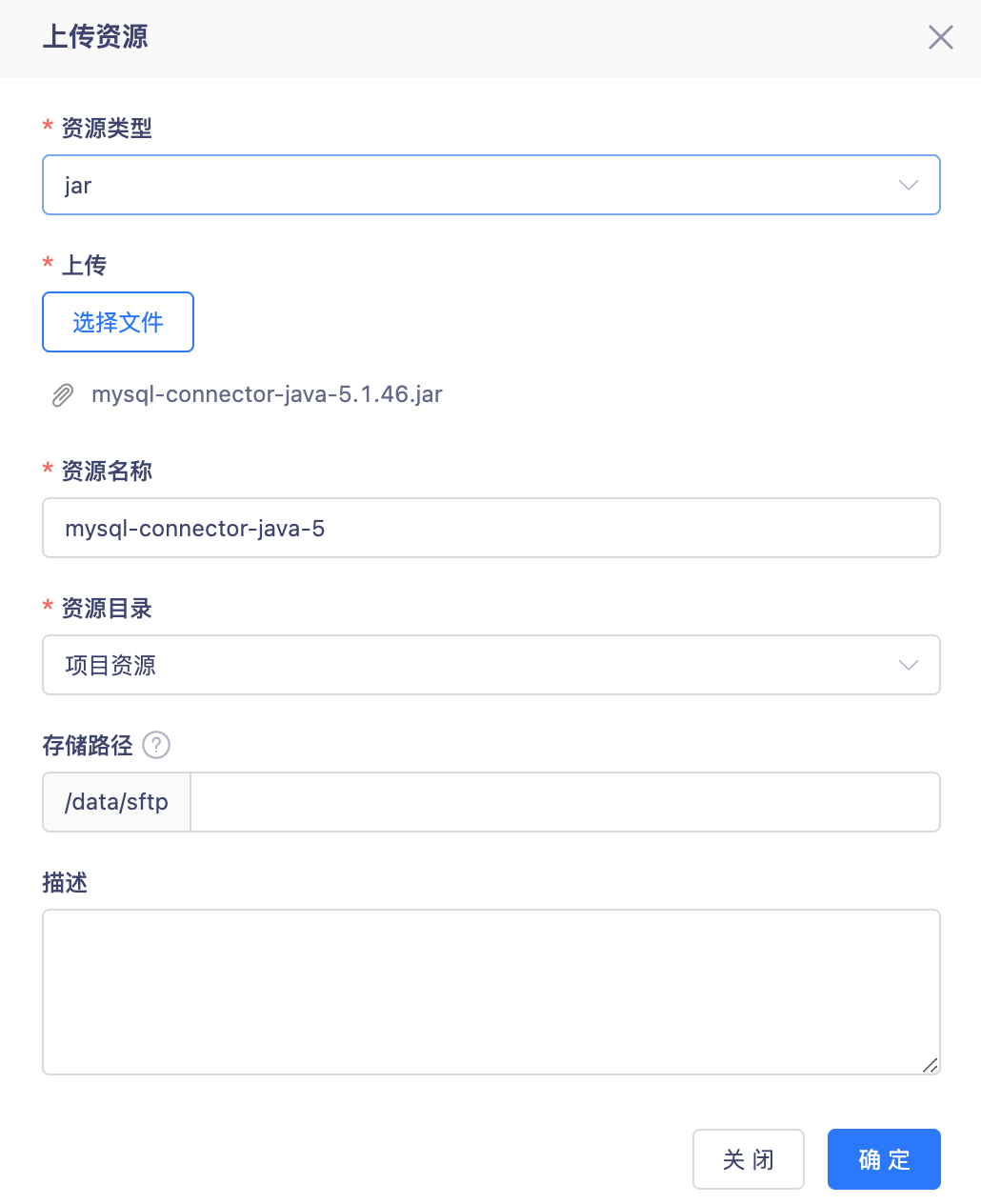
上传资源
- 实时计算平台资源管理上传Mysql
编写FlinkSQL
ADD JAR WITH /data/sftp/491_mysql-connector-java-5_mysql-connector-java-5.1.46.jar; -- 连接Mysql需要Jar手动输入文件sftp地址
CREATE TABLE KafkaTable(
id int,
int_data int,
varchar_data varchar
)WITH(
'connector' = 'kafka',-- 使用与自定义connector相同
'topic' = 'stream',
'properties.bootstrap.servers' = 'localhost:9092',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
CREATE TABLE SinkTable(
id INT,
int_data INT,
varchar_data VARCHAR
)WITH(
'connector'='jdbc',-- 使用与自定义connector相同
'url'='jdbc:mysql://localhost:3306/automation', --连接mysql需要添加mysql-connector.jar
'username'='${username}',
'password' = '${password}',
'table-name'='flink_catalog_one'
);
insert
into
SinkTable
select
*
from
KafkaTable;
运行FLinkSQL
- FlinkSQL语法检查通过并提交调度运行任务
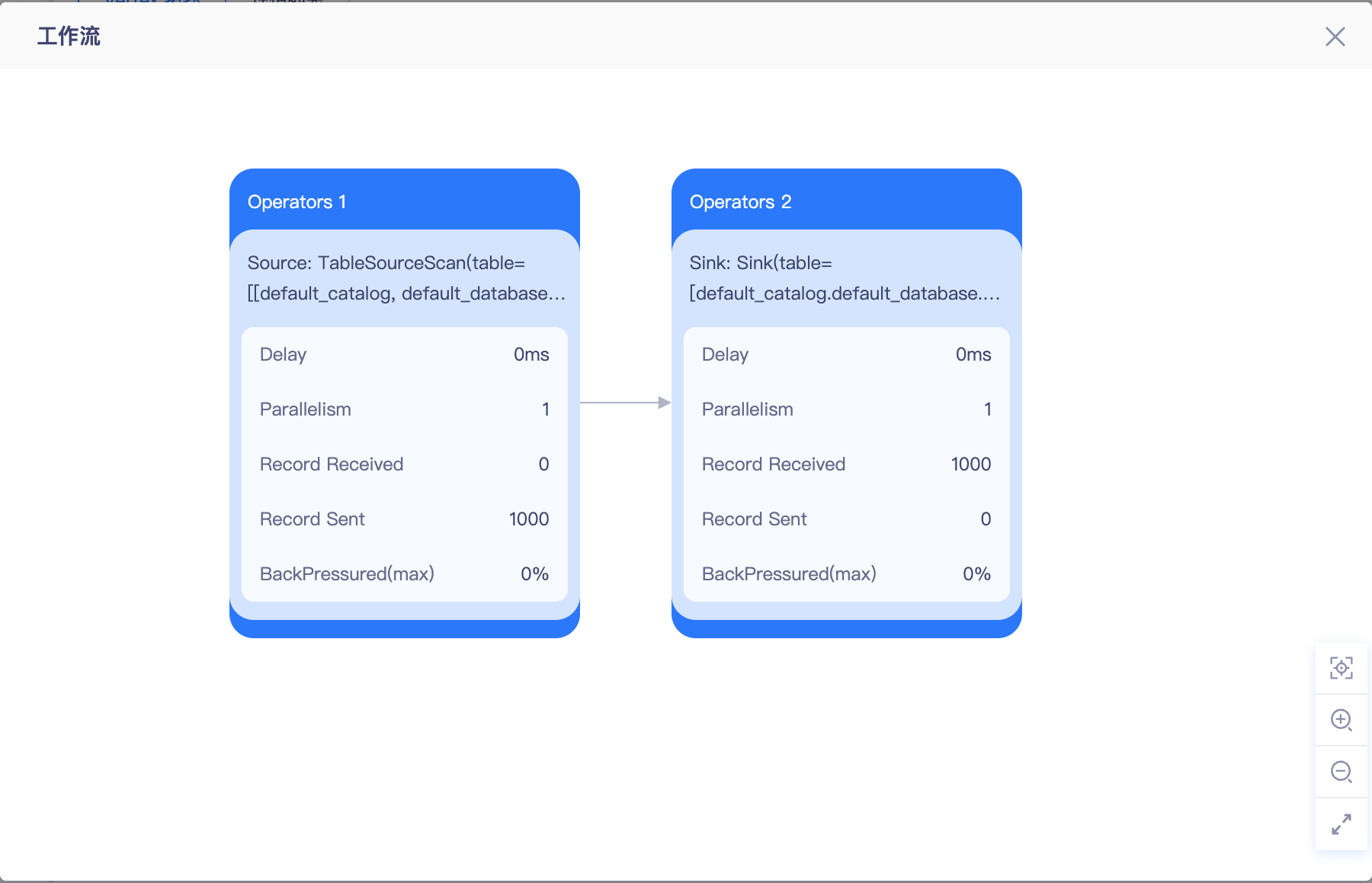
源表写入数据
- kafka Topic 生成写入1000条数据
{"id":1,"int_data":1,"varchar_data":"varchar_data"}
结果表查询数据
- 数据写入成功查看Metric