概述
在实时采集的应用场景中,大致分为如下三种:
日志采集:实时采集业务数据库的变更日志打到Kafka,然后通过FlinkSQL消费Kafka的数据进行任务开发。这是实时开发最常见的处理链路。
间隔轮询:周期查询业务数据库的数据,直接写到同类型或者异构数据源中提供数据服务。该场景目前不支持向导模式开发,用户可以通过脚本模式实现。该场景在实时采集中并不常用,因为间隔轮询会对源库造成压力,并且存在轮询间隔,不够实时。
数据还原:在日志采集的基础上,将采集到的日志数据还原为下游数据库的DDL/DML执行语句,直接对下游数据库的结构和数据进行变更。常用于不需要开发加工,仅将上游新增数据实时同步到下游数据库的场景。
支持的采集类型
| 采集的数据源 | 开发模式 | 采集模式 | 采集范围 | 写入的目标表 |
|---|---|---|---|---|
| MySQL | 向导模式+脚本模式 | 日志采集(支持数据还原) 间隔轮训 | DML DDL(开启数据还原) | Kafka Hive HDFS MySQL |
| Oracle | 向导模式+脚本模式 | 日志采集(支持数据还原) 间隔轮训 | DML DDL(开启数据还原) | Kafka Hive HDFS Oracle |
| SQLServer JDBC | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
| SQLServer | 向导模式+脚本模式 | 日志采集 | DML | Kafka Hive HDFS |
| PostgreSQL | 向导模式+脚本模式 | 日志采集 间隔轮训 | DML | Kafka Hive HDFS |
| Greenplum | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
| DB2 | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
| PolarDB for MySQL8 | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka Hive1、2 HDFS |
| UPDRDB | 向导模式+脚本模式 | 日志采集 间隔轮训 | DML | Kafka |
| Kafka | 向导模式+脚本模式 | / | / | Kafka Hive1、2 HDFS MySQL |
| EMQ | 向导模式+脚本模式 | / | / | Kafka Hive1、2 |
| WebSocket | 向导模式+脚本模式 | / | / | Kafka |
| Socket | 向导模式+脚本模式 | / | / | Kafka |
| Restful | 向导模式+脚本模式 | / | / | Kafka |
| ClickHouse | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
| DM For Mysql | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
| DM For Oracle | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
| OushuDB | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
| Doris | 向导模式+脚本模式 | 间隔轮训 | Insert | Kafka |
开发模式
向导模式: 提供向导式的开发引导,通过可视化的填写和下一步的引导,帮助快速完成实时采集任务的配置工作。向导模式的学习成本低,但无法享受到一些高级功能。每个采集类型的配置项及其说明,详见后几节内容。
脚本模式: 通过直接编写实时采集的JSON脚本来完成实时采集开发,适合高级用户,学习成本较高。脚本模式可以提供更丰富灵活的能力,做精细化的配置管理。脚本模式支持的读写数据源不仅限于上面的表格,还可实现各类RDBMS之间的实时同步。
采集模式
日志采集:其本质是通过读取数据库中的日志文件,比如MySQL Binlog文件(首先需要数据库开启binlog功能),而后插件通过解析Binlog文件,逐条读取用户Insert、Update、Delete操作,将其以流式数据的方式记录在Kafka中,供后续FlinkSQL进行消费。CDC的优点是读取压力小,数据准确,缺点是需要管理员手动开启日志服务才可使用。日志采集的实现逻辑详见下图:

- 间隔轮训:通过JDBC发起查询请求,通过短间隔的查询数据的方式来达到一个近似实时采集的功能。间隔轮训优点是不需要手动开启日志服务,缺点是间隔轮训间隔过短且轮训数据量大时,容易给服务器带来较高的负担,如要使用建议连接从库查询。并且只能采集到结果数据,对数据修改、删除操作无法采集。间隔轮训的实现逻辑详见下图:
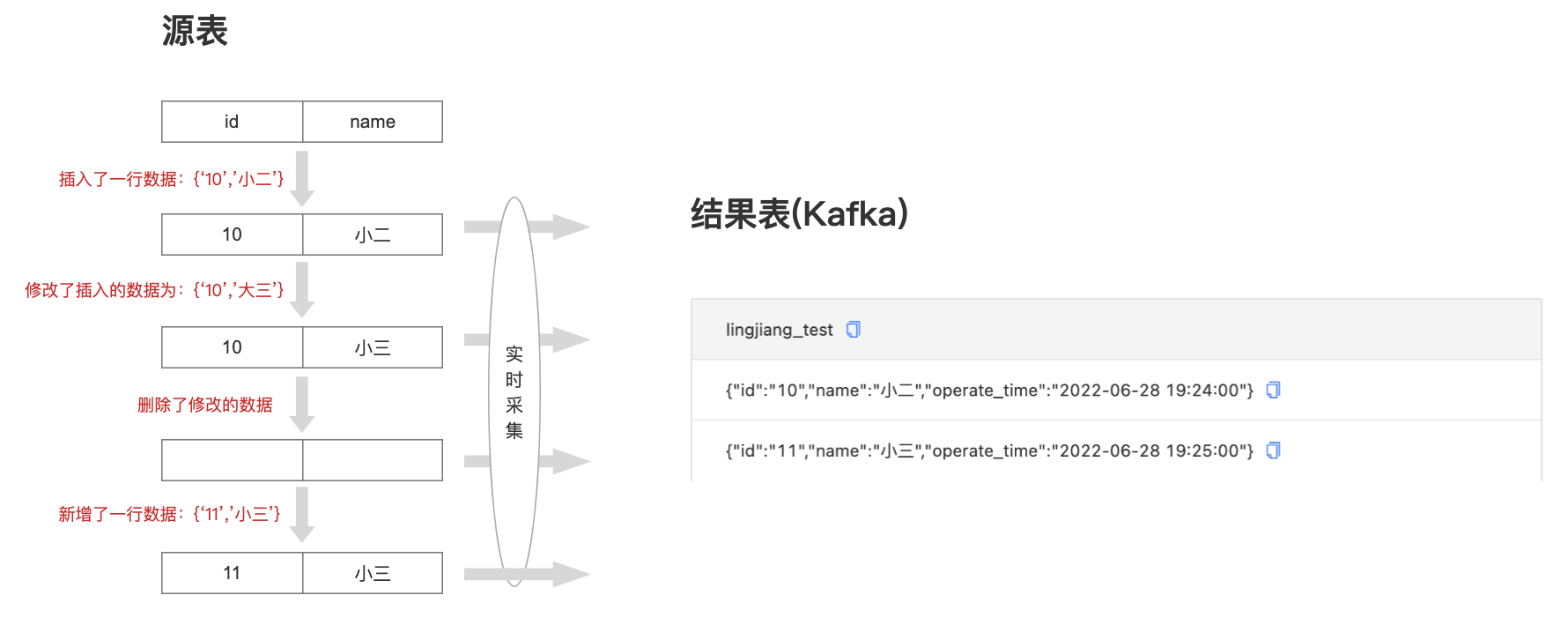
每次同步时会自动记录增量标识的最大值,下次运行时会从上一次的最大值继续同步数据,实现增量同步。
所以需要源表存在自增主键
采集范围
日志采集模式:支持采集上游表的Insert、Update、Delete这三种DML操作。
在日志采集的基础上开启数据还原功能,还可以采集上游表的DDL操作。
间隔轮训模式:支持采集上游表的Insert操作。
更多信息
更多关于实时采集的最新动态,请关注纯钧开源网址。