Chunjun Format
Flinkx(开源名Chunjun)具备CDC(Changelog Data Capture)采集功能,可以将Mysql PostgreSql Oracle SqlServer数据库的实时更改流式传输到Kafka,flinkx为changelog提供了统一的格式模式。 flinkx支持将kafka里flinkxcdc采集的数据解析并按照type对应的类型输出对应的RowKind数据输出到下游,注意如果cdc数据采集到kafka的flinkx任务里,cdc-connector的split参数为false,这个时候,flinkx-cdc-format会将一条update语句拆分为update_before和update_after数据
kafka-conector使用flinkx-cdc-format解析cdc数据,支持按照type字段生成对应的rowkind类型数据之后,就可以进行回撤流 数据还原等场景,而不是直接cdc-connector作为source
Chunjun Json
注意: 请参考 Chunjun 文档,了解如何设置 Chunjun Connect。
如何使用 Chunjun format
Flinkx为变更日志提供了统一的格式,下面是一个从Mysql products表中以JSON格式捕获的更新操作的简单示例:
-- products建表语句
create table products
(
id int null,
name varchar(255) null,
description varchar(255) null,
weight decimal(10, 2) null
);
//实时采集任务
{
"job": {
"content": [
{
"reader": {
"parameter": {
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/dujie",
"username": "root",
"password": "rootroot",
"host": "localhost",
"split": false,
"pavingData":true,
"table": ["dujie.products"],
"cat": "UPDATE,INSERT,DELETE",
"ddlSkip":false
},
"name": "binlogreader"
},
"writer": {
"name": "kafkasink",
"parameter": {
"topic": "flinkxjson_1",
"producerSettings": {
"auto.commit.enable": "false",
"bootstrap.servers": "172.16.100.109:9092"
}
}
}
}
],
"setting": {
"speed": {
"bytes": 0,
"channel": 1
}
}
}
}
输出的数据格式:字段含义可见Binlog Source | ChunJun 纯钧
{
"schema":"dujie",
"after_name":"scooter",
"lsn":"binlog.000030/000000000000077125",
"after_weight":5.25,
"before_description":"Big 2-wheel scooter",
"type":"UPDATE",
"before_name":"scooter",
"database":null,
"opTime":"1663209843000",
"after_id":1,
"after_description":"Big 2-wheel scooter",
"table":"products",
"ts":6976007703219015680,
"before_id":1,
"before_weight":5.18
}
将kafka的topic注册为一张表,字段为cdc采集表字段即可 注意value.format选择了 flinkx-cdc-json-x
CREATE TABLE topic_products (
-- schema is totally the same to the MySQL "products" table
id BIGINT,
name STRING,
description STRING,
weight DECIMAL(10, 2)
) WITH (
'connector' = 'kafka-x'
,'topic' = 'flinkxjson_1'
,'properties.bootstrap.servers' = '172.16.100.109:9092'
-- ,'scan.startup.mode' = 'latest-offset'
,'scan.startup.mode' = 'earliest-offset'
,'value.format' = 'flinkx-cdc-json-x'
)
写入stream-x中查看结果
CREATE TABLE SinkOne
(
id BIGINT,
name STRING,
description STRING,
weight DECIMAL(10, 2),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'stream-x'
);
insert into SinkOne
select *
from sourceIn u;
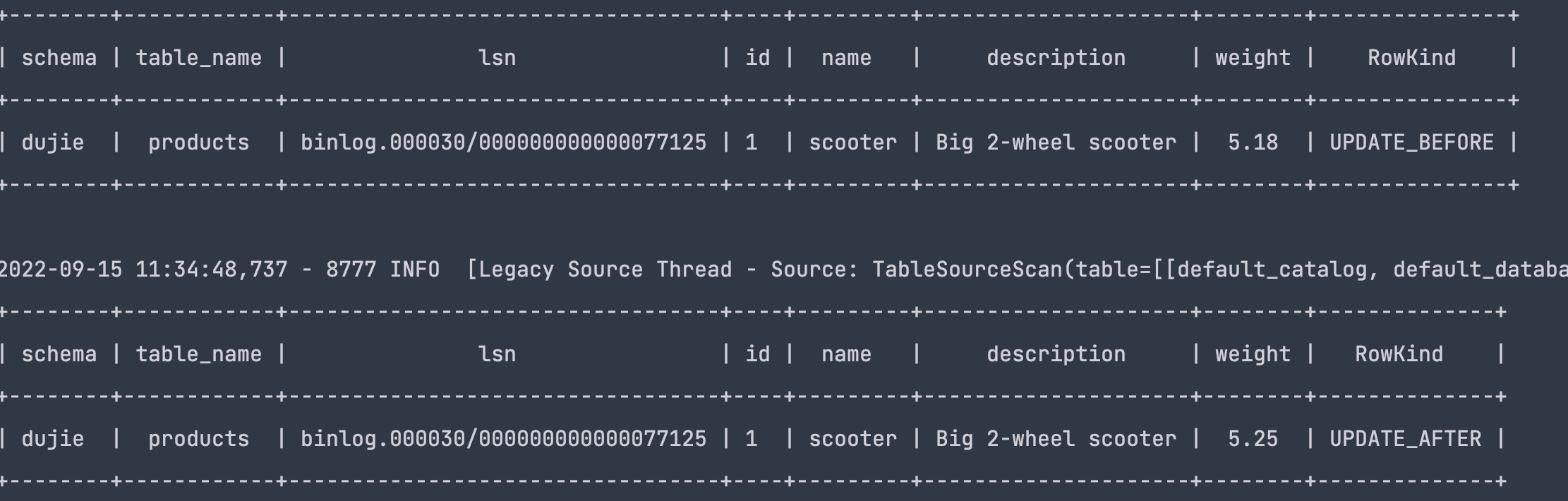
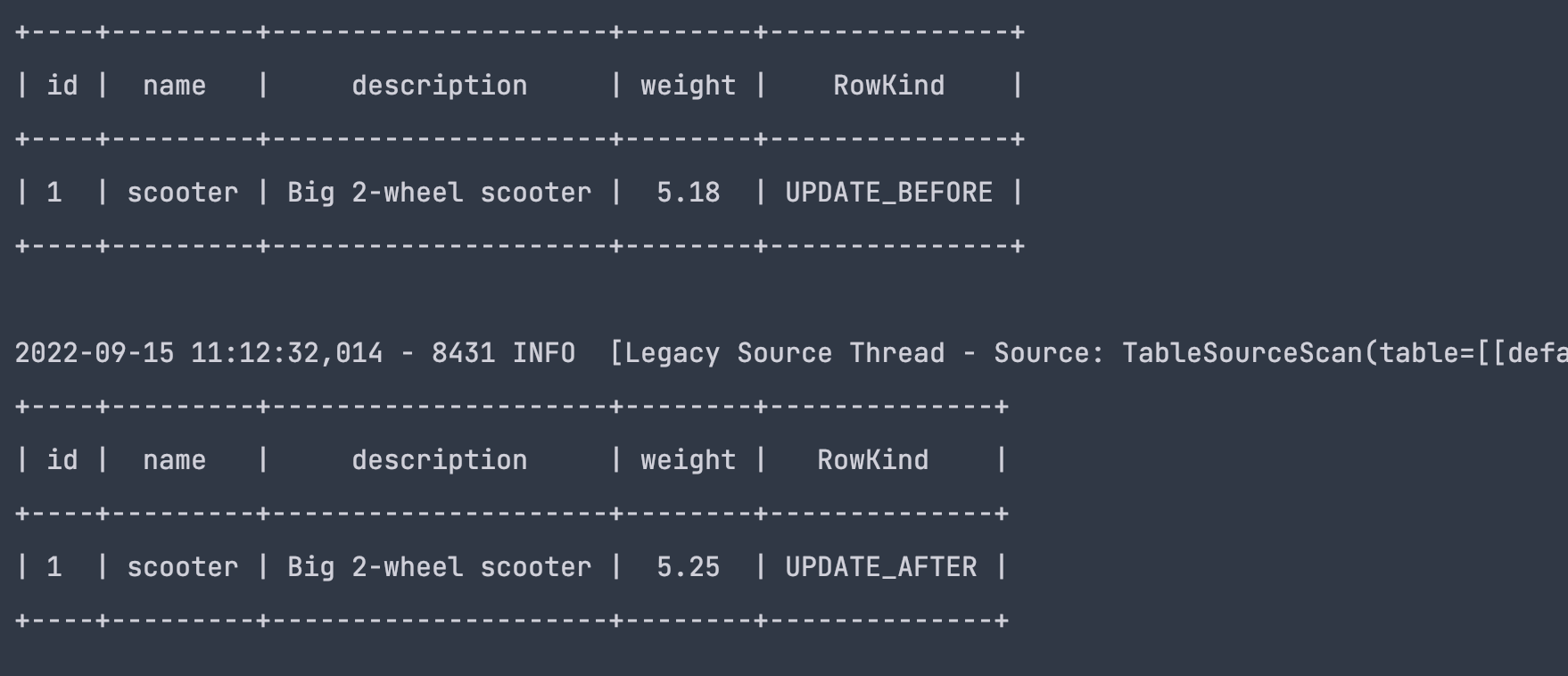
结果
一条UPDATE语句拆分为了2条数据,分别是update_before,uodate_after
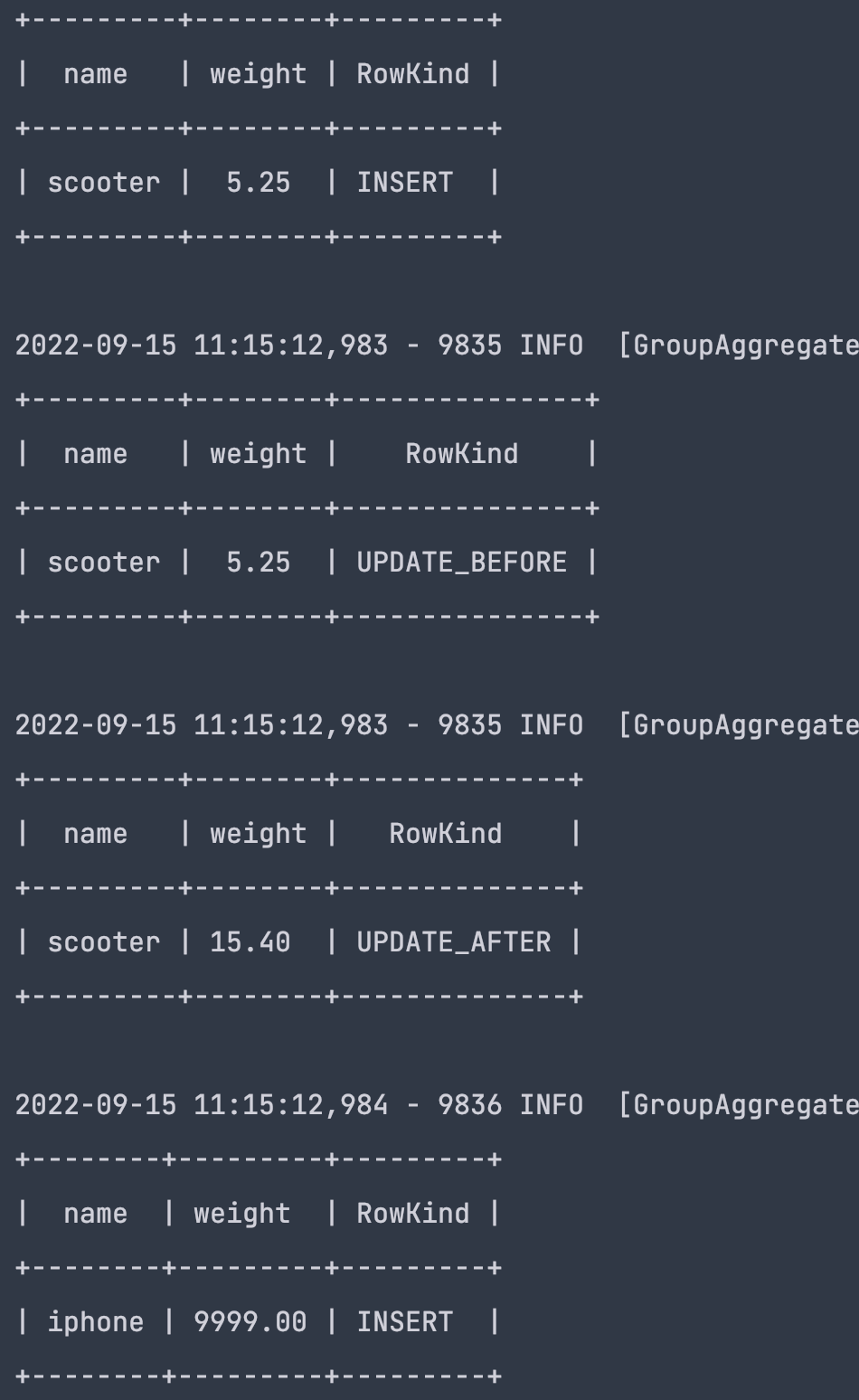
按照name分组求weight之和
CREATE TABLE SinkTwo
(
name STRING,
weight DECIMAL(10, 2)
) WITH (
'connector' = 'stream-x'
);
insert into SinkTwo
select name,sum(weight)
from sourceIn u group by name;
结果: 后续又新增了name为scooter,weight为10.15,以及name为iphone,weight为9999数据
INSERT INTO dujie.products (id, name, description, weight) VALUES (2, 'scooter', 'Big 4-wheel scooter', 10.15)
INSERT INTO dujie.products (id, name, description, weight) VALUES (3, 'iphone', 'iphone14', 9999)
可用元数据
| key | 类型 | 描述 |
|---|---|---|
| database | STRING | 源表databse,可为空 |
| schema | STRING | 源表schema |
| table | STRING | 源表table |
| opTime | STRING | dml数据库执行时间戳 |
| ts | BIGINT | flinx处理时间 生成规则可见对应cdc插件文档 |
| lsn | STRING | dml的偏移量 |
| scn | DECIMAL(38,0) | logminer-cdc的偏移量 和上述scn一致 |
| type | STRING | dml类型 支持的选项有update insert dedlete update_before update_after |
- 元数据字段支持在高级参数Json元数据映射中选择所需要的元数据字段
- 元数据字段固定,仅支持选择不做自定义编写
以下示例显示了如何访问 Kafka 中的 Flinkx 元数据字段:
CREATE TABLE sourceIn
(
schema STRING METADATA FROM 'value.schema',
table_name STRING METADATA FROM 'value.table' ,
lsn STRING METADATA FROM 'value.lsn',
id BIGINT,
name STRING,
description STRING,
weight DECIMAL(10, 2),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'kafka-x'
,'topic' = 'test'
,'properties.bootstrap.servers' = 'localhost:9092'
,'scan.startup.mode' = 'earliest-offset'
,'format' = 'flinkx-cdc-json-x'
);
结果: