FLinkSQL
概述
FlinkSQL任务可以让开发人员在IDE页面通过SQL开发的方式,完成实时数据的分析计算。相关的使用场景和详情如下:
开发逻辑
举一个常见的实时计算场景来介绍开发逻辑:
某任务需要分析实时日志数据按APP维度的统计指标,供下游大屏API查询。该场景中的日志数据会实时打入Kafka Topic中,维度数据存储在PostgreSQL中,最后计算加工好的数据需要写入HBase中。
接下去的基础开发逻辑主要分为两部分:
表定义
我们发现这个实时任务中涉及了三种结构完全不一致的数据源类型,要能在FlinkSQL中把它们串起来,就需要将这些表按照Flink的定义把它们映射成统一的、FlinkSQL能够看得懂的表。(借助Flink官方提供的Table API)
SQL加工
表定义完成后,通过SQL开发完成加工计算。(SQL加工逻辑和离线的SparkSQL类似,
insert into A as select * from B join C,只是在部分语法上略有区别,详见Flink1.16 SQL说明)
开发模式
在IDE页面开发SQL时,代码逻辑可通过三种模式完成开发:
向导模式(默认)
该方式就是按步骤还原了上面的开发逻辑。需要用户先在IDE面板右侧定义源表、维表、结果表,然后在SQL编辑器内引用右侧定义的表,进行SQL逻辑的加工。
脚本模式
该方式是基于官方定义的最基础的开发方法。将表定义和SQL加工在SQL编辑器内同时实现。具有更高的参数自由度,同时对开发能力的也会有更高的要求。
Catalog模式(作为向导或脚本模式开发时的补充能力)
上面两种方式均存在一个缺点,就是用户每次开发任务的时候都需要去定义表。假如我有5个实时任务都用到了同一张PG的维表,我需要在在5个实时任务中重复定义5次。
Catalog方式可以帮我们把表定义的元数据持久化存储下来,不管哪个实时任务需要用到,直接输入
catalog.database.table即可使用,避免重复定义的工作,提升开发效率。
向导模式的介绍
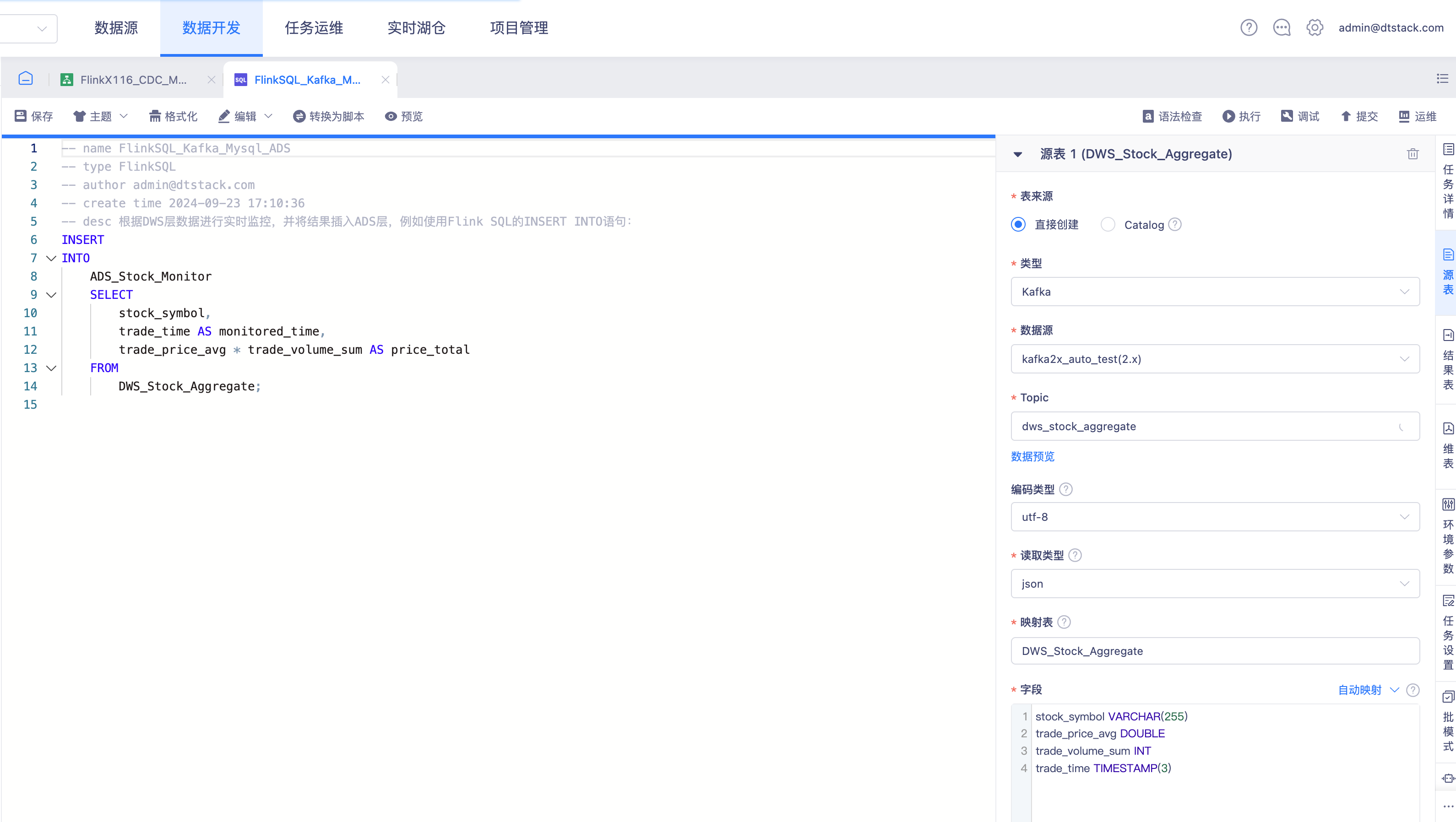
以上述案例介绍源表为Kafka、维表为PG、结果表为HBase时,创建一个向导模式的FlinkSQL任务。
表定义
各个配置参数的含义。更多参数以及解释,请参考Flink官方 Connector介绍。
Kafka源表
类型、数据源、Topic: 选择过滤出需要定义成Flink Table的Topic
编码类型: 指定kafka数据的编码类型,目前支持utf-8、gbk2312
读取类型: 将kafka获取到的消息字符串按指定格式进行解析,具体查看 Kafka formats
数据预览: 查看该Topic中最早或最近的数据
映射表: 定义成Flink Table之后的表名,用于SQL开发中使用
字段:
自动映射:用户不需要关心JSON格式,不需要手动维护字段映射。实现一键自动映射需要按固定的模版格式去解析,目前仅支持JSON、OGG-JSON、Chunjun-JSON、AR-JSON
- 点击「自动映射」,平台会自动采集所选Topic中的最近一条消息进行解析。
note因为Topic数据不支持过滤查询,因此采集最近一条数据可能并不包含完整的JSON KEY,或者并不是你想要的Table JSON。这个问题无法避免,您可以多采集几次进行覆盖。
如果多次采集解析的结果,均未达到预期。可以点击「自动映射」后的下拉ICON,手动输入样例JSON,平台会跳过JSON采集,直接解析样例JSON。
自动映射输出字段类型默认String类型,字段类型不满足时手动修改。
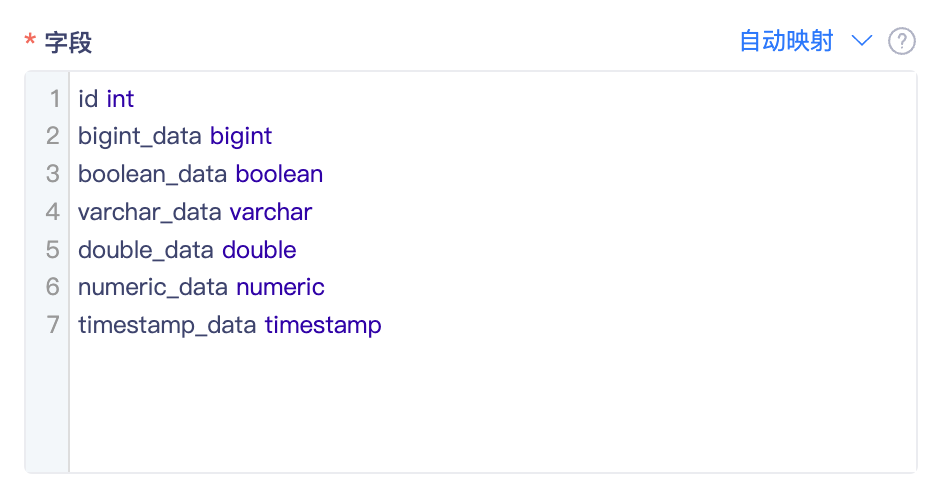
手动映射:将Kafka数据映射成行列结构的字段。根据topic中数据格式的不同,在输入框中的配置方式也略有区别。详见下表:
Topic数据样例 字段配置写法 {"id":"1","name":"张三","opt_time":"2022-06-28 19:25:00"} id int
name string
opt_time datetime{"user_info":{"id":"1","name":"张三"},"opt_time":"2022-06-28 19:25:00"} user_info ROW(id int, name string )
opt_time datetime{"jsonArray":[{"id":"1","name":"张三"}],"opt_time":"2022-06-28 19:25:00"} jsonArray ARRAY<ROW(id int, name string)
opt_time datetime更多复杂类型在Flink sql中的映射逻辑,详见 Flink JSON Format
note字段映射关键字: 向导模式遇到字段为Flink关键字的情况,支持对字段进行反引号处理,转脚本默认输出反引号格式数据 关键字参考地址
Offset: 支持如下方式
- Latest:latest-offset从Kafka Topic读取最新数据
- Earliest:earliest-offset从Kafka Topic可以读取的最早起点开始读取数据
- Time:timestamp从Kafka Topic指定时间开始读取数据
- 自定义参数:specific-offsets从指定的分区offset开始读取数据。使用自定义参数需要指定特定的偏移量,则需要配置每个分区指定特定的启动偏移量,例如选项值partition:0,offset:42;partition:1,offset:300 表示分区0的偏移量42和分区1的偏移量300
- 当日变量:1. 选择“当日变量+时间常量”,在实时任务提交时,kafka offset会从任务提交当日的指定时间开始消费;2. 配合自动启停策略可实现:消费每日数据,计算当日指标;
时间特征: Flink分为ProcTime和 EventTime两种时间特征,这两个时间特征的选择会对后续基于时间的各类计算结果产生影响。
Processing Time:表示数据进入Flink后,执行对应Operation的设备的系统时间。(选择该特征,后续的计算处理更简单)
Event Time(推荐):表示数据在它的生产设备上发生的时间。(选择该特征后,需要补充额外的两个配置信息。其数据计算结果最接近真实的业务情况)
时间列:必须是映射表中已声明的一列(当前仅支持为Timestamp类型)。Flink会基于该列生成Watermark,并且标识该列为Event Time列,可以在后续Query中用来定义窗口。
最大延迟时间:该配置项和Flink的Watermark(水印)机制有关。已下图为例:假设我们定义了一个10秒的计算窗口,并且允许延迟7秒。在Flink里会发生如下操作:
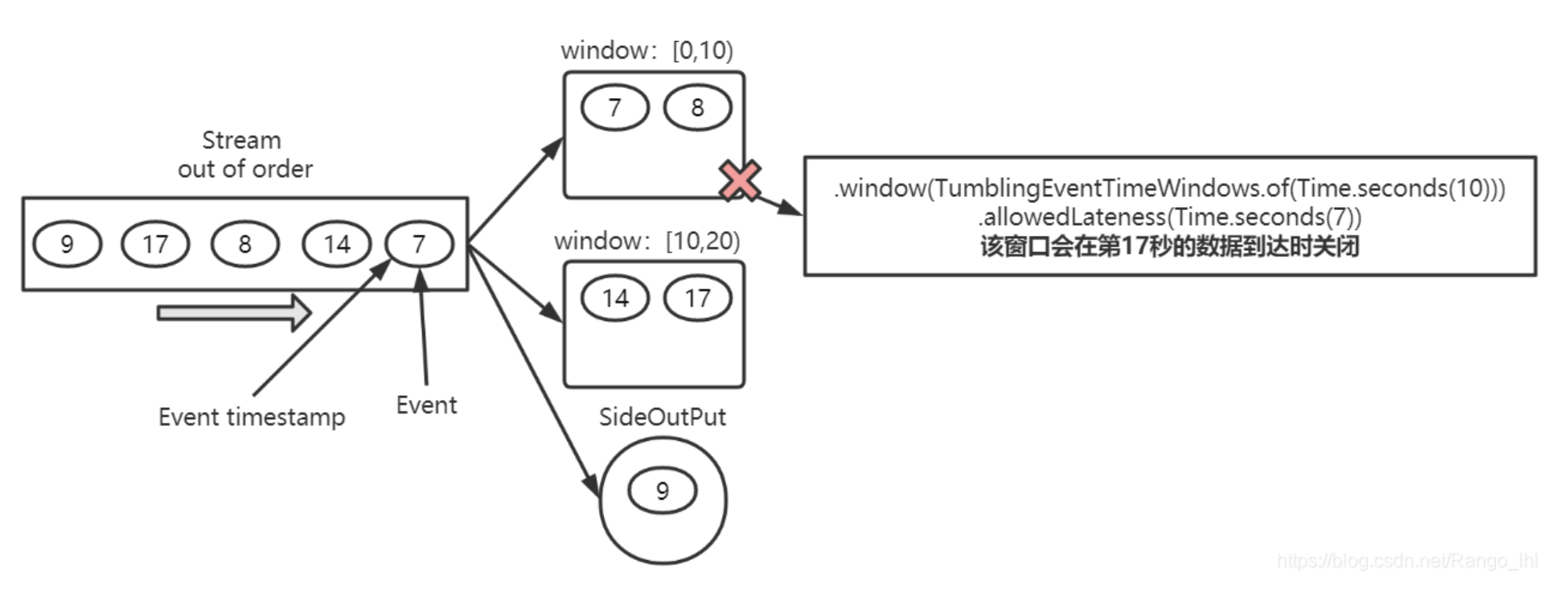

并行度: 算子的并发数,指的是Flink集群的Task Slot的数量。(每个任务的并行度配置不能超过整个Flink集群的Task Slot的数量,每个任务的并行度累加起来也不能超出,否则会造成任务的报错)
时区: 时区设置目前只针对时间特征为EventTime的任务生效,默认为Asia/shanghai
自定义参数: 自定义参数项和参数名
PostgreSQL维表
类型、数据源、Schema、表: 选择过滤出需要定义成Flink Table的表
映射表: 定义成Flink Table之后的表名,用于SQL开发中使用
字段: 定义Flink Table的表结构
- 导入全部字段:会将PG表中所有字段和数据类型完整的导入作为Flink Table的字段
- 添加输入:手动选择PG表中需要映射的字段
- 别名:如需要调整原字段名在Flink Table中的显示,可以维护别名
主键: 选择维表主键,系统进行缓存刷新时会根据主键判断数据的超时时间
并行度: 算子的并发数,指的是Flink集群的Task Slot的数量。(每个任务的并行度配置不能超过整个Flink集群的Task Slot的数量,每个任务的并行度累加起来也不能超出,否则会造成任务的报错)
缓存策略: 因为维表数据变更频率较低,因此在查询时可以将数据进行缓存,避免每次查询都连接数据库,提高查询效率。
- LRU(部分缓存):Least Recently Used,记录维表每条数据的访问热度,仅缓存热度较高的数据
- None(不缓存):表示不需要缓存
- ALL(全缓存):缓存维表的全部数据
缓存大小(行): 即缓存空间需要保存多少条数据
缓存超时时间: 超出缓存时间时会在缓存空间中删除数据
允许错误数据: 可以配置当出现N条错误数据时,任务置为失败。默认无限制。(可能出现目前不兼容的数据格式导致查询错误)
异步线程池: 维表缓存采用异步方式查询数据,支持配置线程池数量
HBase结果表:
类型、数据源、表: 选择过滤出需要定义成Flink Table的表
Rowkey: 指定表中的rowkey及其类型,提高查询效率避免数据热点问题
映射表: 定义成Flink Table之后的表名,用于SQL开发中使用
字段: 定义Flink Table的表结构。按$列族$ row<$字段名$ 类型,$字段名$ 类型>的格式进行映射,如:user_info row<id int,name varchar>
更新模式:支持append、upsert两种模式
append:表示结果数据会已一条新数据的形式,插入结果表。
upsert:表示结果数据会根据主键唯一性,更新至结果表。因此选择upsert方式时,必须选择主键。
SQL加工
当源表、维表、结果表都在右侧定义好之后,只需要在IDE页面输入符合业务逻辑的SQL代码,即可完成一个实时任务的开发。
脚本模式的介绍
脚本模式的底层逻辑和向导模式完全相同,并且平台也支持将向导模式的任务一键切换为脚本模式。(注意脚本模式无法切换为向导模式)
最主要的区别是,表定义这件事情不通过右侧面板进行配置,而是直接在SQL IDE中维护,如下案例:
-- 该案例通过一个最基础的查询源表、关联维表、输出至结果表的开发demo,介绍FlinkSQL的基础开发逻辑
-- 第一步:定义源表。
-- Flink的表不是内部表,不在内部维护,而是始终对外部数据库进行操作。
-- 表定义分为两部分:表结构和连接器配置。表结构定义了表中的列名及其类型,是查询操作的对象。连接器配置包含在WITH子句中,定义支持该表的外部数据库。
-- 该案例的连接器使用datagen作为测试数据集,实际场景需要根据实际数据源类型进行参数配置
CREATE TABLE orders (
order_uid BIGINT,
product_id BIGINT,
price DECIMAL(32,2) ,
order_time TIMESTAMP(3)
)WITH(
'connector'='datagen'
);
-- 第二步:定义维表。
CREATE TABLE products (
product_id BIGINT,
product_name STRING,
product_type STRING
)WITH(
'connector'='datagen'
);
-- 第三步:定义结果表。
CREATE TABLE product_order_analysis(
order_uid BIGINT,
product_id BIGINT,
product_name STRING,
product_type STRING,
price DECIMAL(32,2) ,
order_time TIMESTAMP(3)
)WITH(
'connector'='stream-x'
);
-- 第四步:根据业务需求编辑代码逻辑。本案例就是将源表和维表进行关联后写入结果表。
INSERT
INTO
product_order_analysis
SELECT
orders. order_uid as order_uid,
orders. product_id as product_id,
products. product_name as product_name,
products. product_type as product_type,
orders. price as price,
orders. order_time as order_time
FROM
orders
LEFT JOIN
products
on orders.product_id=products.product_id;
Catalog模式的介绍
Catalog作为对向导模式和脚本模式的补充,如果用户在SQL IDE中编辑的时候,使用catalog.database.table的方式,则表示使用在【表管理】模块中已经定义好的Flink Table,无须重复定义。
关于Catalog、Database、Table的创建维护介绍,详见实时湖仓模块。