湖仓快速入门
设计背景
1、解决Flink映射表的元数据持久化存储和管理的问题。
通过实时湖仓中的映射表管理,可以对Kafka、MySQL等数据源中的topic/表进行持久化映射。当某个映射表可以在多个任务中重复使用时,不需要在每个任务开发时都做一遍重复映射,直接通过Catalog.db.table的方式引用即可。
2、解决湖表(Paimon/Hudi/Iceberg)的创建/管理需求,为实时任务读写湖表提供基础。
湖表管理:在【实时湖仓】模块,创建维护湖表;
湖表读写:在【数据开发】模块,在IDE中通过Catalog.db.table的方式引用湖表,完成读写。
快速入门
通过DEMO串联介绍【实时湖仓】和【数据开发】的配合使用。
Hudi Demo需要实现:流式读取Hudi表,实时Join ES维表,流式写入另一张Hudi表。
一、创建两个Catalog
HMS Catalog用来存储管理Hudi表、DT Catalog用来管理ES映射表。
二、创建湖表和映射表
- 创建Hudi Source表
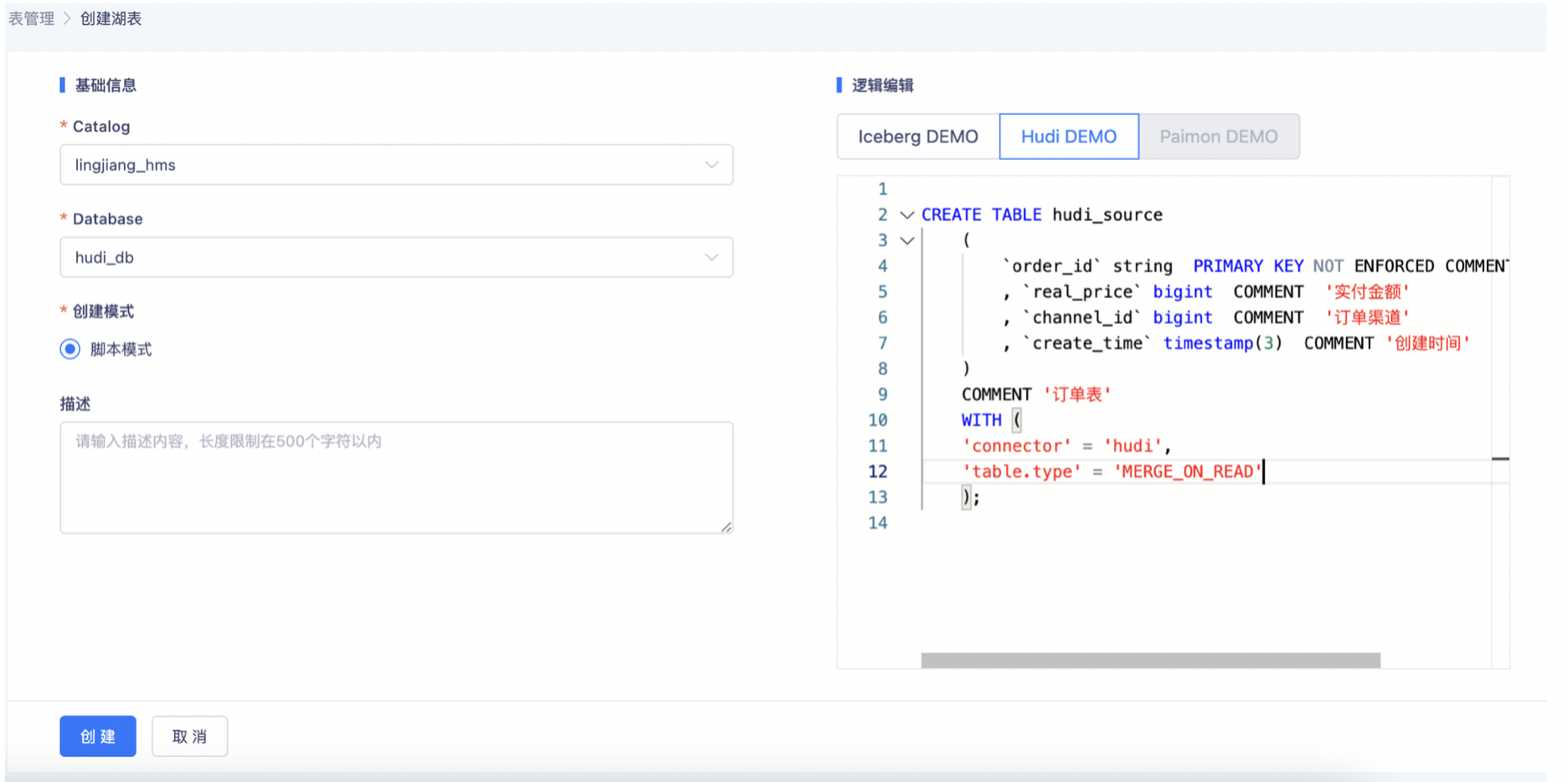
- 创建Hudi Sink表
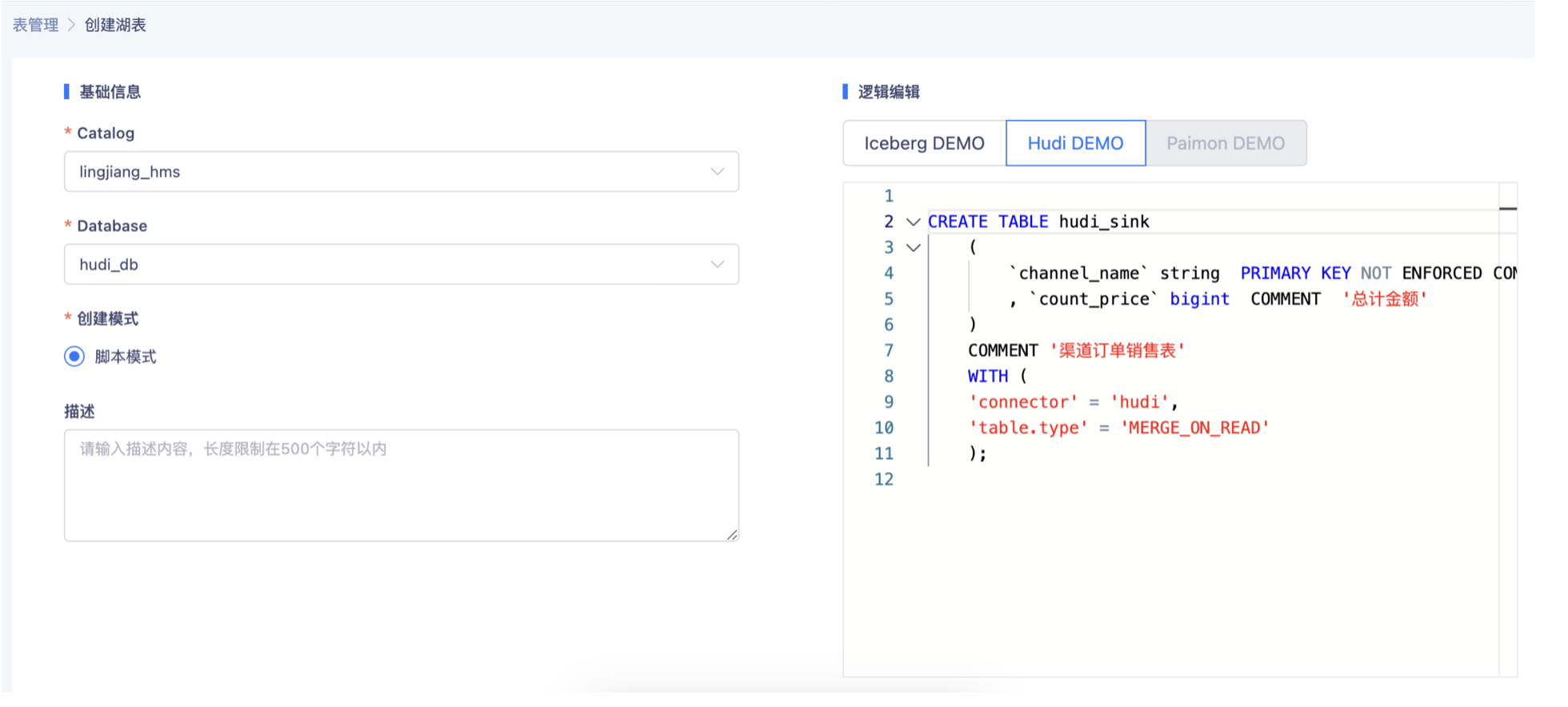
- 创建ES维表
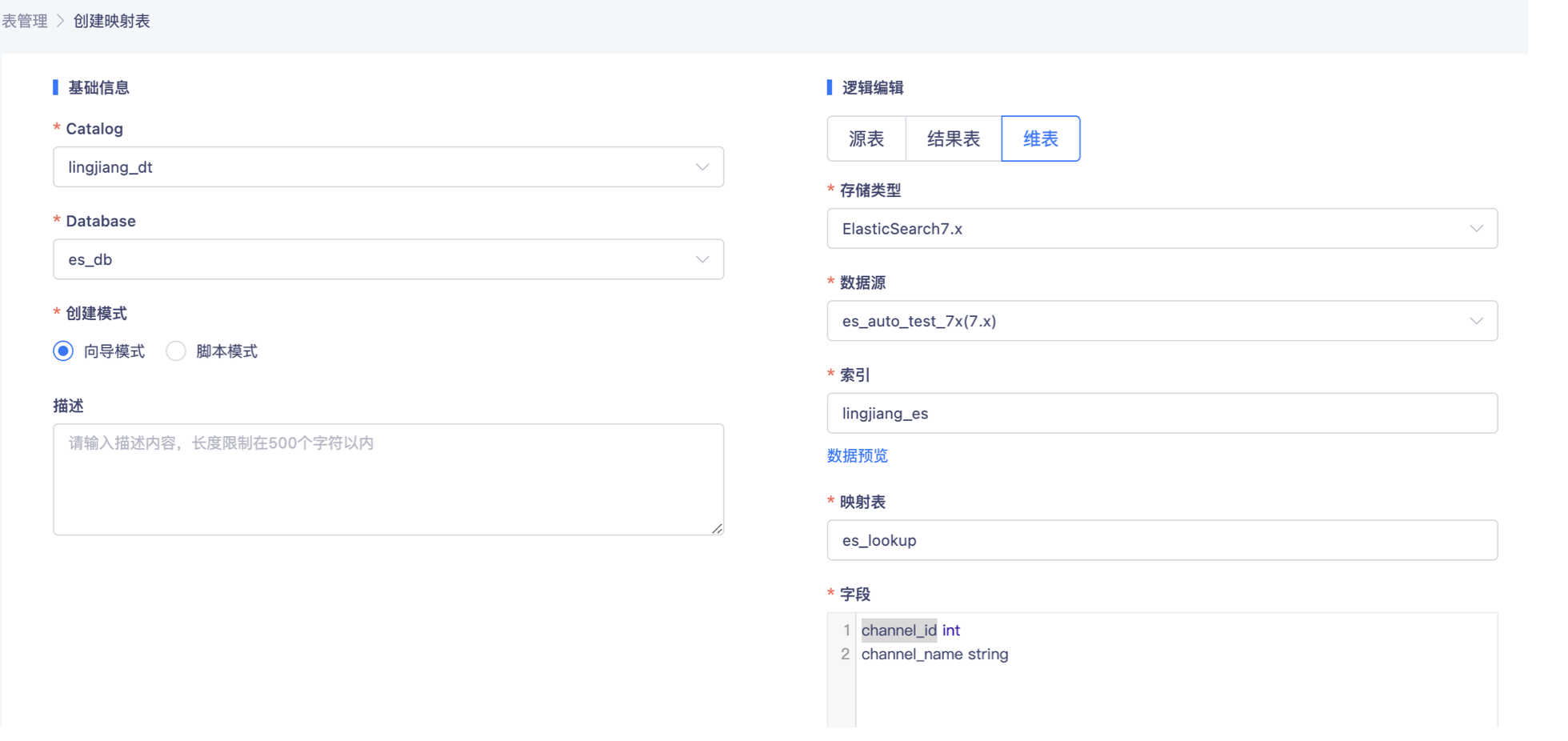
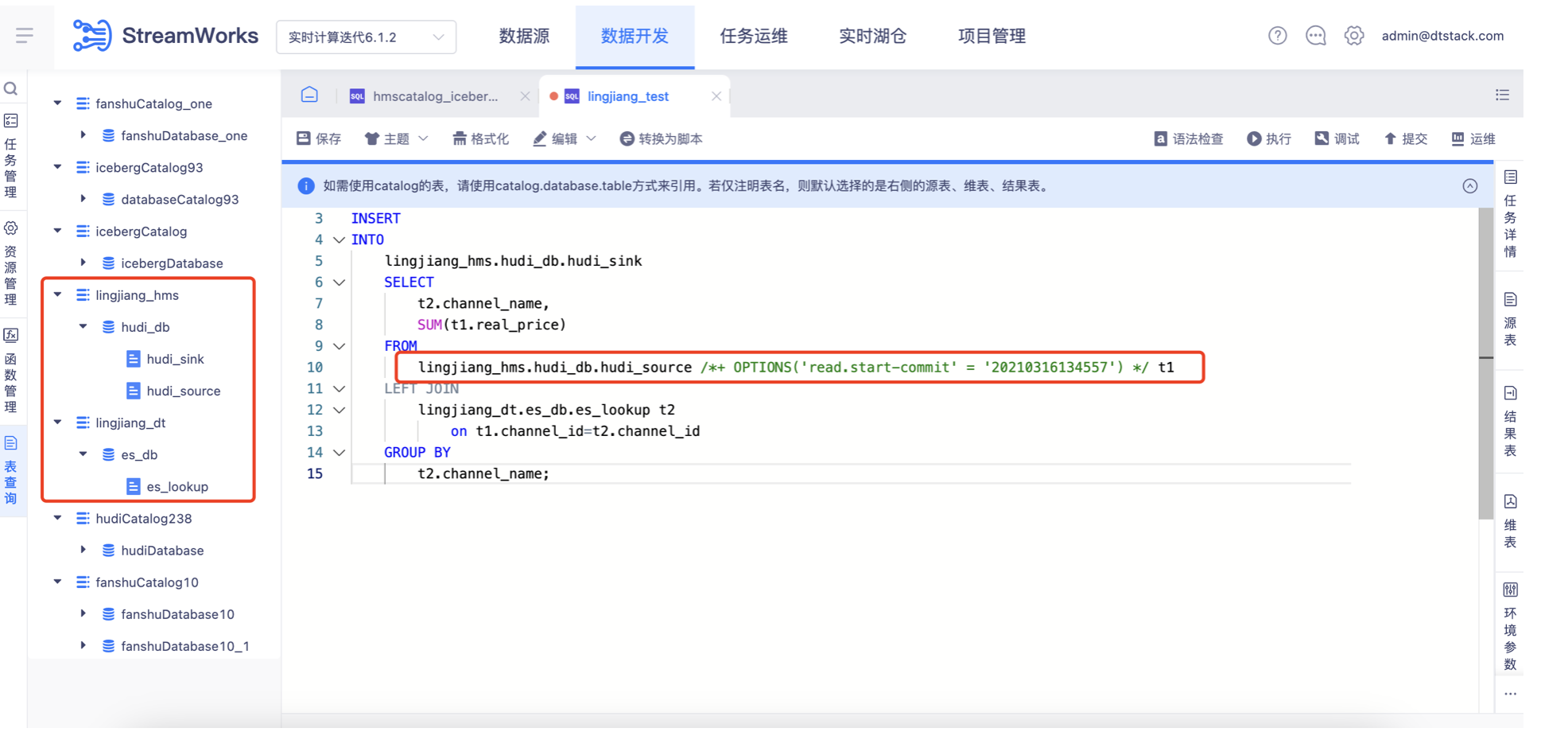
三、开发实时任务
通过左侧「表查询」,查询到【实时湖仓】中创建的表,并在IDE中通过catalog.db.table的方式引用,完成一个实时任务的代码编辑。
对于湖表的读写参数,需要通过外挂Hint的方式来实现,比如配置Hudi源表的读取起点。
Paimon Demo实现:流式读取Kafka,写入Paimon表数据入湖
一、创建Catalog
HMS Catalog 存储管理Catalog、Database信息
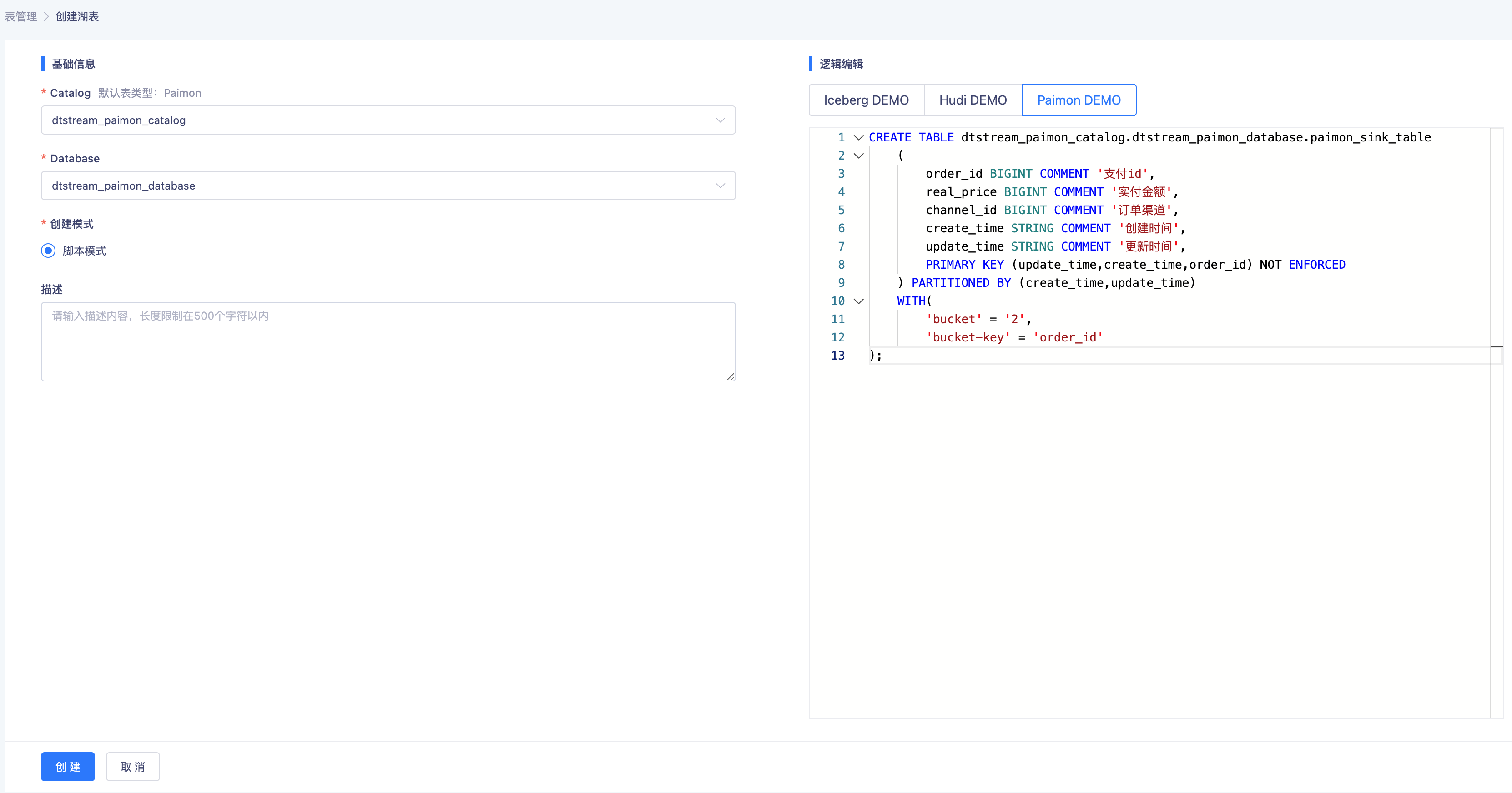
二、创建湖表
- 创建Paimon Sink表
三、开发实时任务
通过左侧「表查询」,查询到【实时湖仓】中创建的表,并在IDE中通过catalog.db.table的方式引用,完成一个实时FLinkSQL任务的代码编辑。
CREATE TABLE sourceTable(
order_id BIGINT,
real_price BIGINT,
channel_id BIGINT,
create_time STRING,
update_time STRING
)WITH(
'properties.bootstrap.servers'='localhost:9092',
'connector'='kafka-x',
'scan.parallelism'='1',
'format'='json',
'topic'='test',
'scan.startup.mode'='latest-offset'
);
INSERT
INTO
catalog_test.database_test.paimon_sink_table
SELECT
*
FROM
sourceTable;
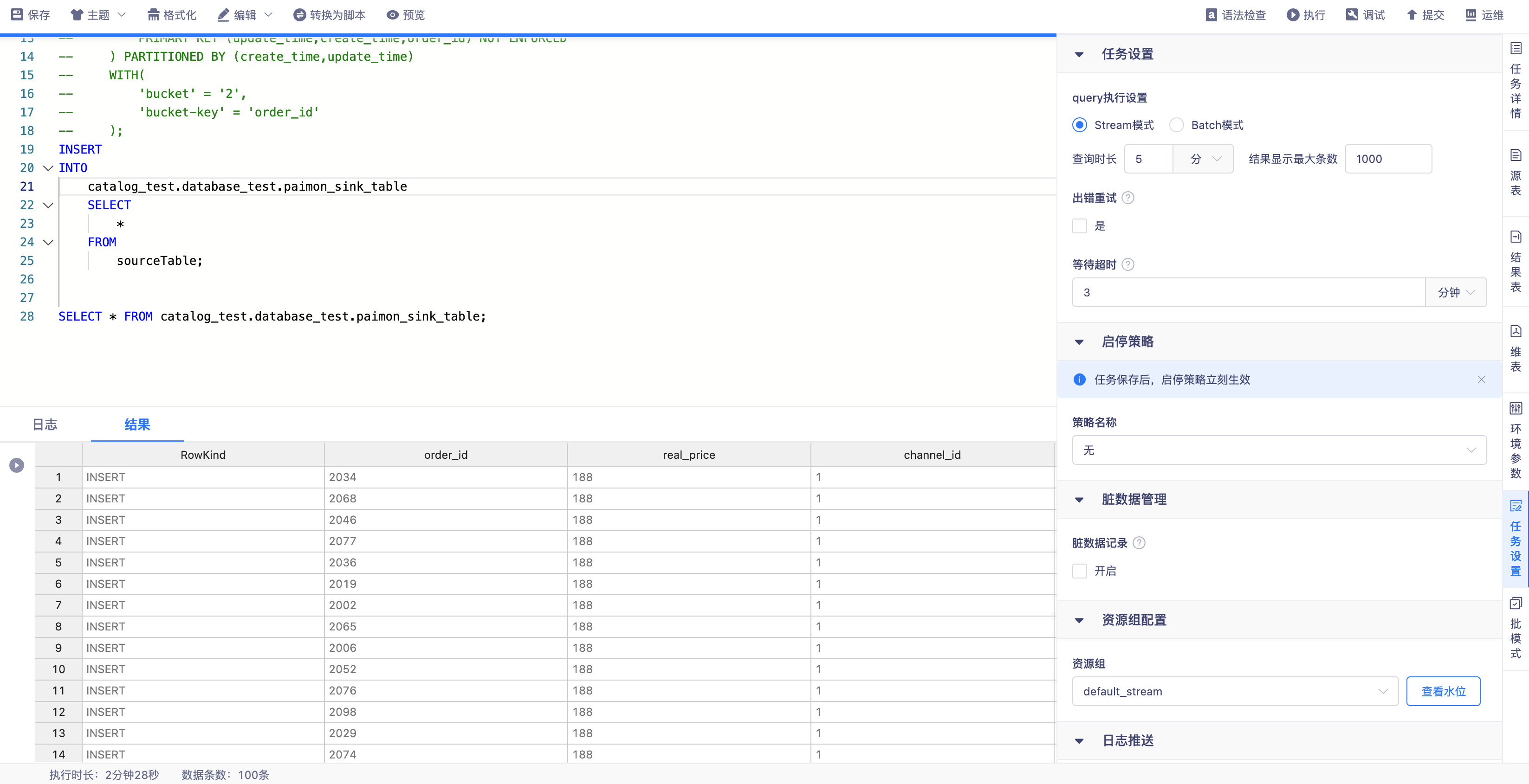
四、运行任务检查插入数据
运行FlinkSQL任务消费Kafka数据从当前latest位点,写入Paimon表后可通过平台SQL Query流批读取数据。