StreamWorks 5.3.1更新日志
发布时间:2022-12-29
功能新增
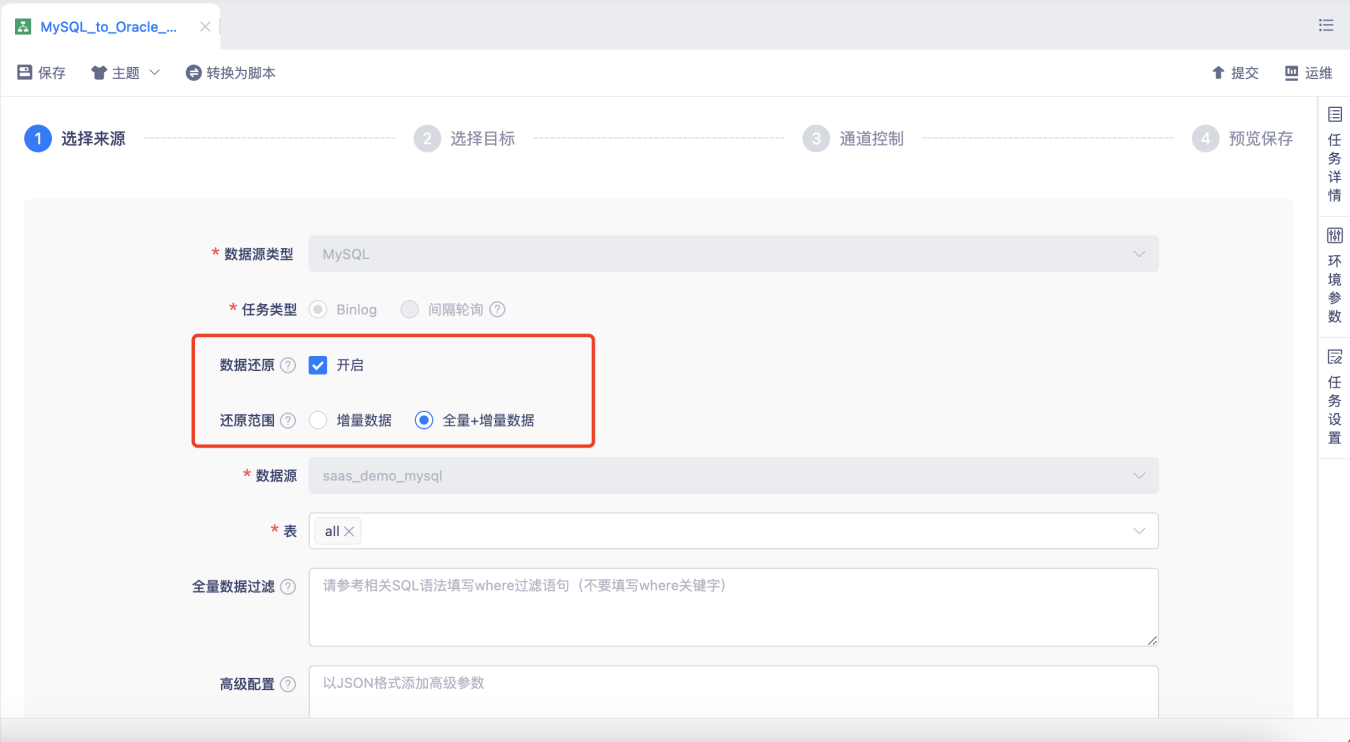
【数据还原】支持存量数据同步+增量日志还原的一体化任务,支持MySQL—>MySQL/Oracle【5.3】
背景:一个任务即可完成存量数据的同步,并无缝衔接增量日志的采集还原,在数据同步领域实现批流一体。常用于需要做实时备份的数据迁移场景。比如在金融领域,业务库出于稳定性考虑,无法直接面向各种上层应用提供数据查询服务。这时候就可以将业务数据实时迁移至外部数据库,由外部数据库再统一对外提供数据支撑。
功能:在创建实时采集任务时,开启【数据还原】,还原范围选择【全量+增量数据】。
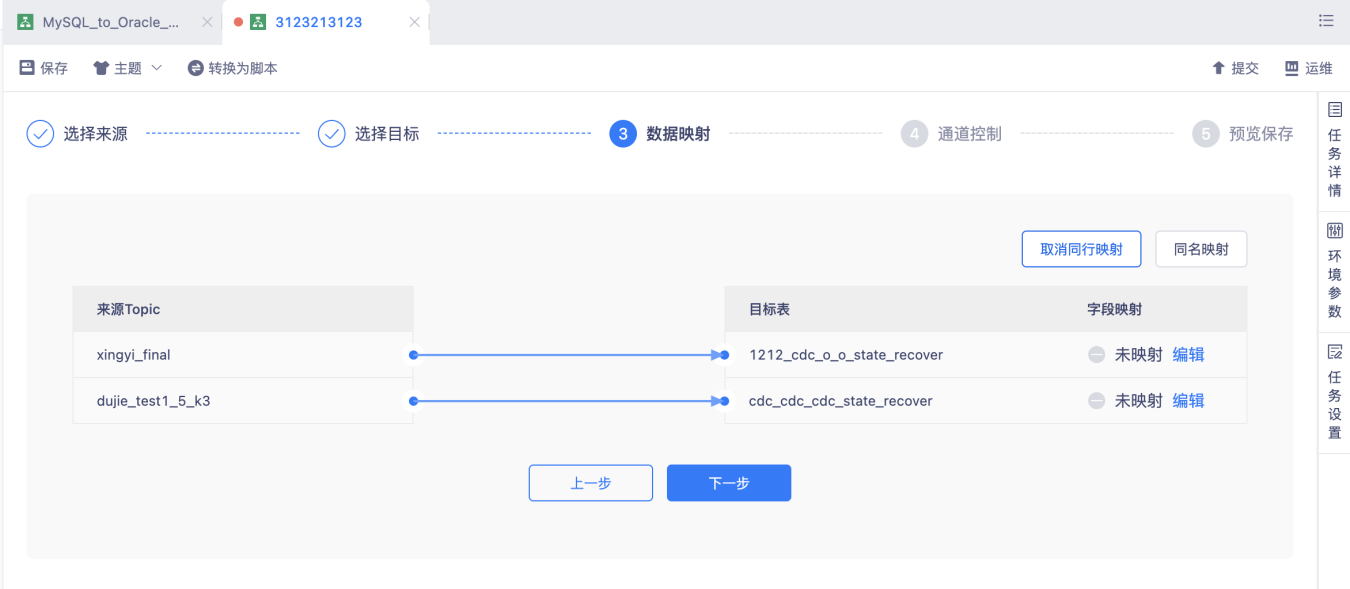
【数据还原】支持将Kafka(OGG格式)数据,采集还原至下游MySQL/Hyperbase/Kafka表【5.3】
背景:当用户对Kafka数据没有实时加工的需求,只希望能将kafka消息还原至下游数据库对外提供数据服务时,可以通过实时采集配置化的方式,批量完整此类采集还原任务,不需要一个个的维护FlinkSQL任务。
功能:在创建实时采集任务时,源表批量选择Kafka Topic,目标表批量选择MySQL表。再完成表映射、字段映射。
【任务热更新】修改环境参数、任务设置后,在数据开发页面提交任务后,任务运维处自动执行「停止-提交-续跑」操作【5.3】
背景:目前对于编辑修改实时任务的场景,操作比较繁琐。
- 需要先在【任务运维】处停止任务;
- 然后在【数据开发】页面提交修改后的任务;
- 最后再回到【任务运维】页面向YARN提交任务。
功能:在【数据开发】页面编辑/修改/提交任务后,任务运维处自动执行「停止-提交-续跑」操作。不需要人为多处操作。
note目前仅支持修改「环境参数」、「任务设置」后的热更新,暂不支持Flink表映射、SQL逻辑修改场景。
【数据源】新增ArgoDB作为FlinkSQL的维表/结果表【5.2】
【数据源】新增HUAWEI ES作为FlinkSQL的维表/结果表【5.1】
【数据源】新增Vastbase作为FlinkSQL的维表/结果表【5.3】
【数据源】新增Hyperbase作为Kafka采集还原的目标端【5.3】
功能优化
【数据还原】数据还原任务支持生成Checkpoint并续跑【5.3】
- 限制:如果是全量+增量的还原任务,在全量同步阶段失败,任务不支持续跑。
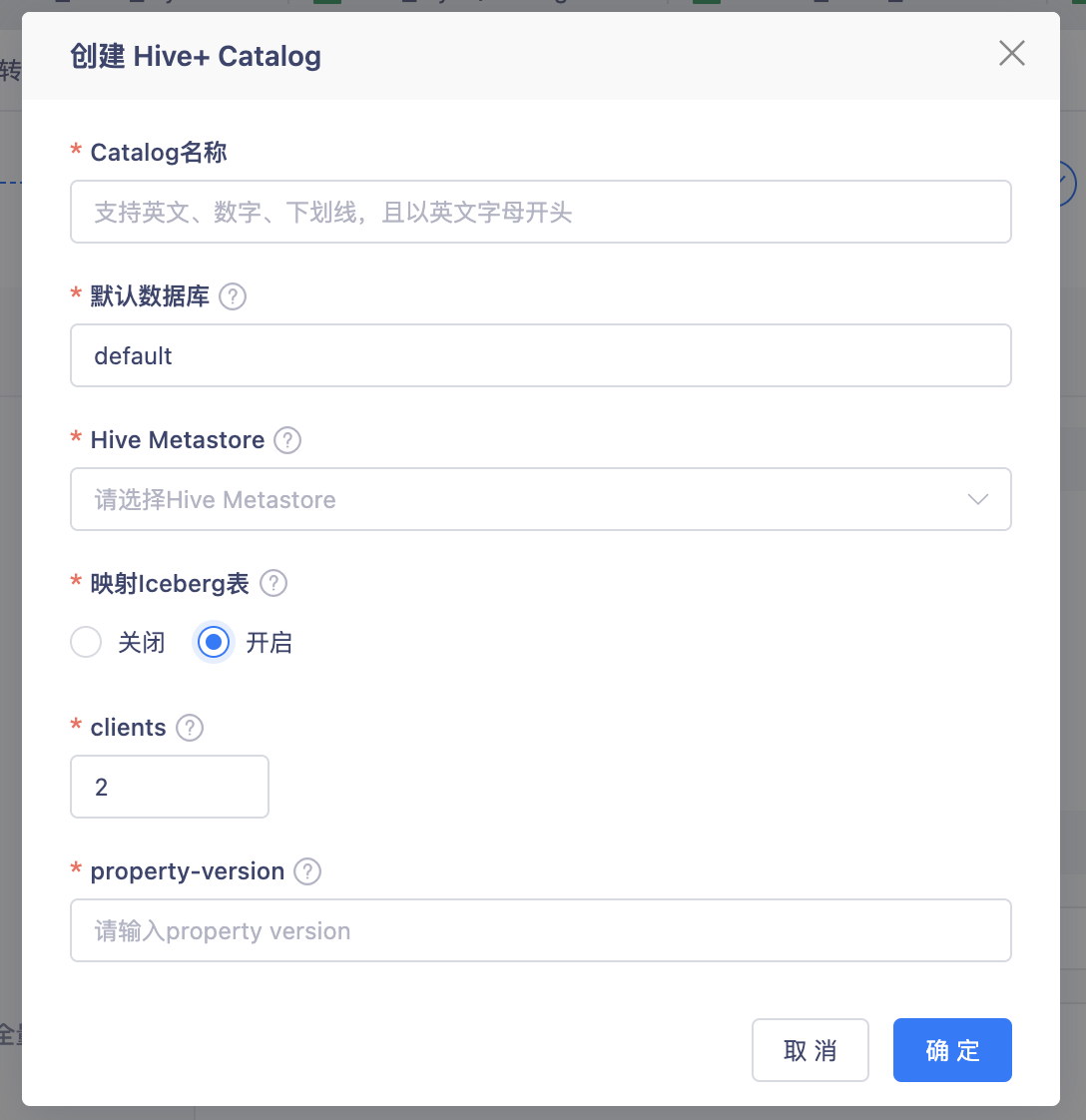
【表管理】合并原有的Hive Catalog和Iceberg Catalog为Hive+ Catalog【5.3】
背景:这两类Catalog,实际都是依赖Hive Metastore做元数据存储,Iceberg Catalog只需要在Hive Catalog基础上,开启额外的一些配置项即可,所以将这两类Catalog做了合并。
功能:在创建Hive Catalog,可以选择是否开启Iceberg表映射。如果开启了,在这个Catalog下创建Flink Table时,只支持映射Iceberg 表。
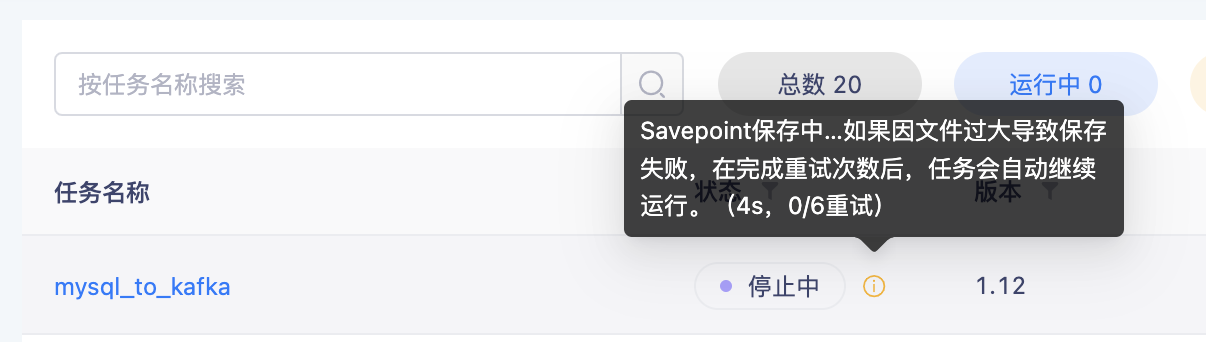
【任务运维】优化保存Savepoint时的任务停止逻辑【5.3】
背景:在保存Savepoint并停止任务时,因为Savepoint文件可能会比较大,保存时间需要比较久,但是状态一直显示「停止中」,用户无法感知停止流程。并且如果保存失败了,任务依然会一直显示「停止中」,任务状态不符合实际情况。
功能:在保存Savepoint并停止任务时,「停止中」状态会显示当前持续时间,以及保存失败的重试次数。当最终保存失败时(代表任务停止失败),此时任务会自动恢复至「运行中」状态。
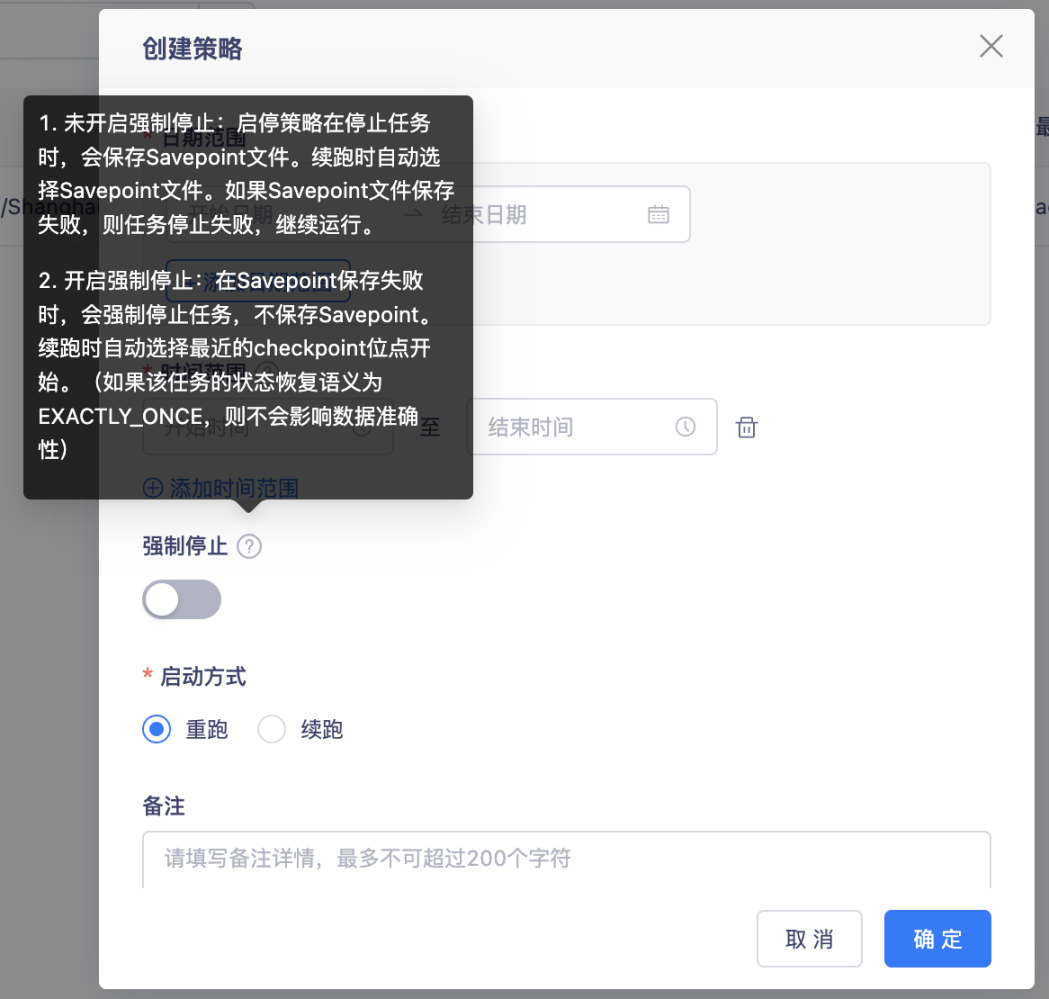
【启停策略】创建启停策略时,支持强制停止配置项【5.3】
背景:目前创建的启停策略,默认都是执行保存savepoint的逻辑。但是sp可能存在状态较大,出现无法正常生成/保存的场景。此时就不符合启停策略的设计目的了,因此需要这种情况时,支持直接丢弃sp,强制停止任务。
功能:创建启停策略,有个强制停止的开关。
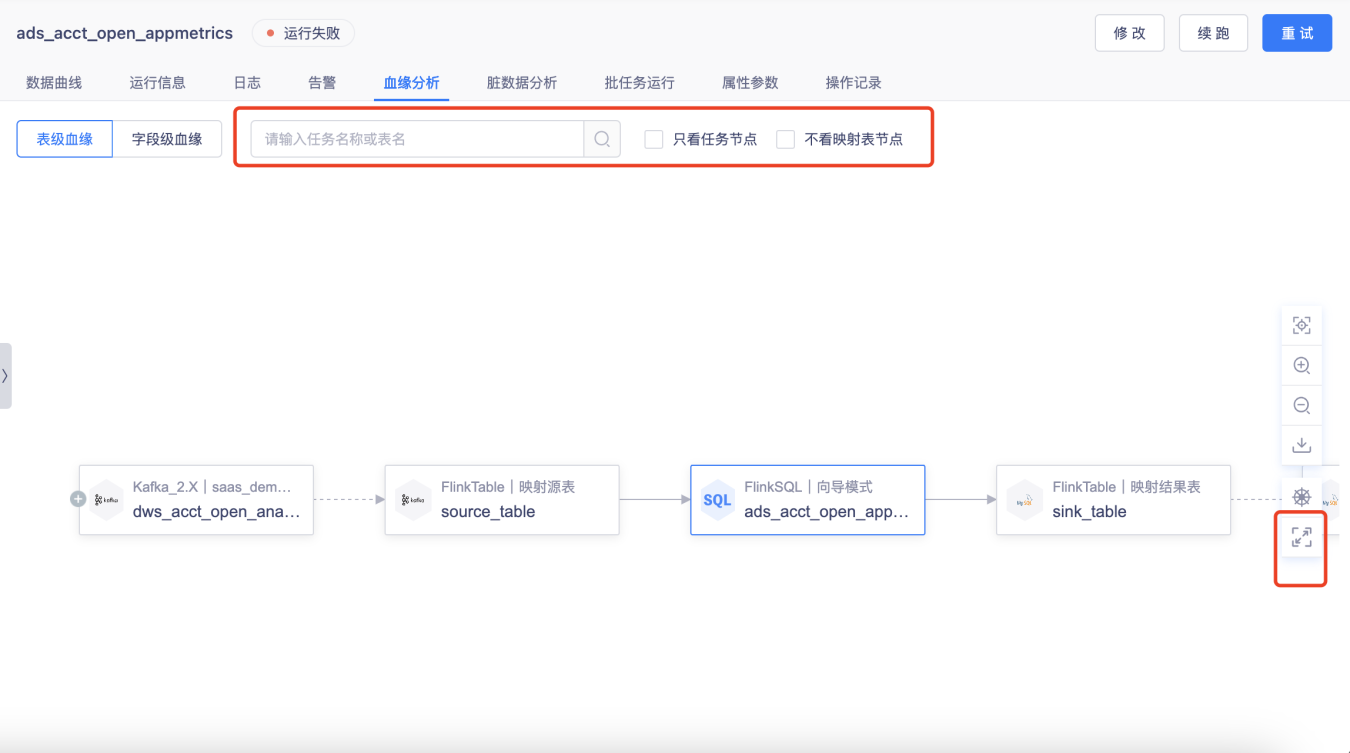
【血缘效果】支持过滤链路节点类型;支持全屏查看;支持搜索;任务节点支持查看状态【5.3】
【系统函数】更新系统函数,同步Flink官方内容【5.3】
说明:系统函数同步的是Flink1.16的函数内容,可能会出现部分函数在Flink1.12中不支持的情况