Hive/HDFS Sink
平台支持将采集到的数据实时写入至Hive表/HDFS文件,写入逻辑可查看概览页介绍。
Hive sink 实际是依赖了HFDS sink,所以底层实现逻辑是一样的,只是在上层做了自动建表、分组映射等拓展功能。
配置项操作和解释
- 操作页面:
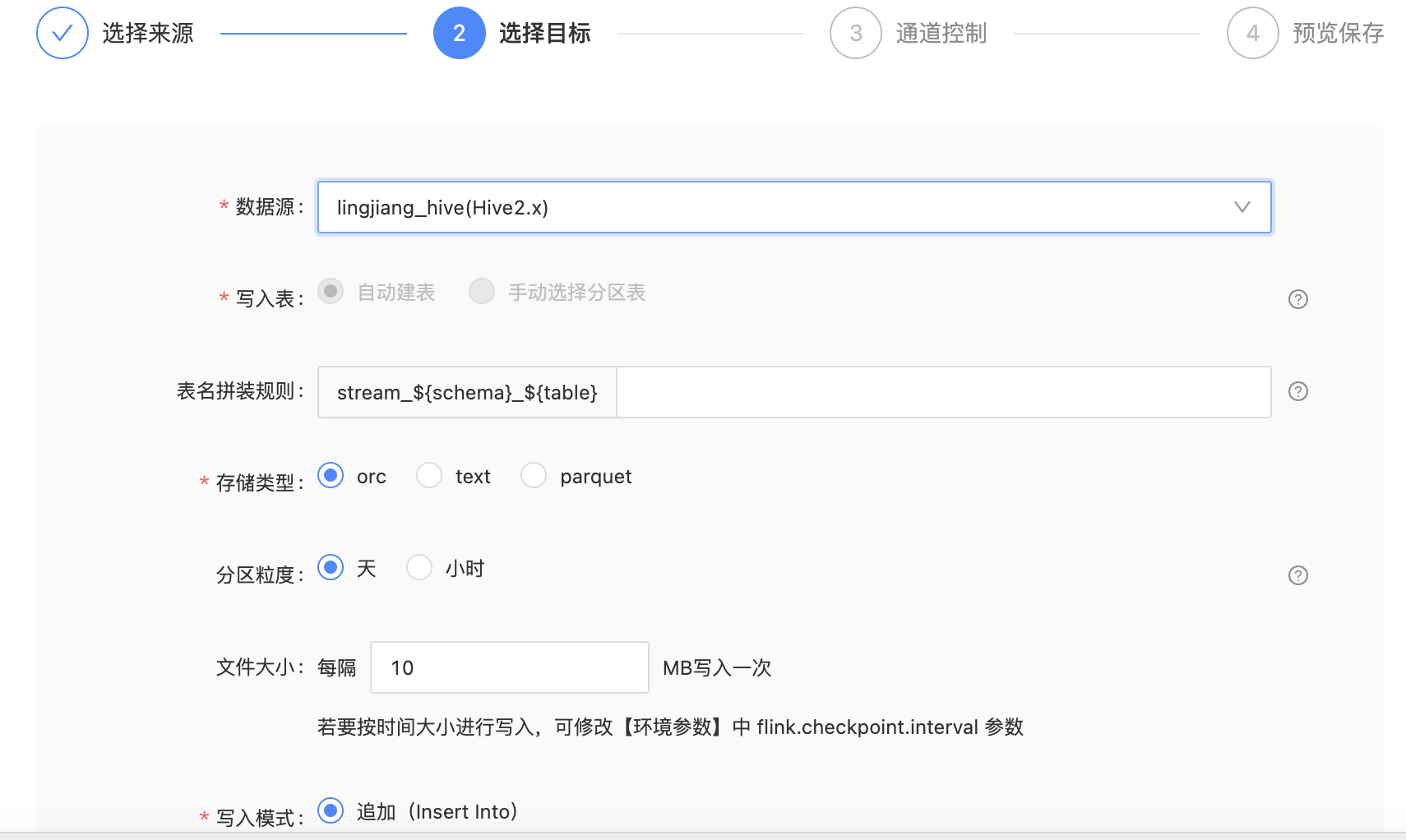
参数解释:
| 配置 | 说明 |
|---|---|
| 写入表 | 支持两种写入模式: 自动建表:会在Hive数据源为该采集任务自动创建一张和源表结构一致的Hive分区表,用于写入采集到的数据。 手动选择分区表:如果在Hive数据源中已经存在和源表结构一致的Hive分区表,则可以直接选择。 |
| 表名拼接规则 | 使用自动建表模式,在Hive中创建的表,其表结构和源表一致。表名会按照stream${schema}${table}_xxxxx规则进行拼接: 1. 固定stream前缀,表示是实时计算创建的表; 2. 变量${schema}前缀,自动获取源表所属的schema名称; 3. 变量${table}前缀,自动获取源表表名;(如果源表配了分组信息,此处自动替换组名) 4. 输入框可不填; |
| 存储格式 | 支持ORC、TEXT、PARQUET三种格式 |
| 分区粒度 | 支持天、小时。在自动建表时完成分区创建 |
| 文件大小 | 设置实时采集的写入频率,支持按文件大小和时间间隔两种方式: 文件大小:默认实时采集到的数据,每隔10M写入一次,可调整大小; 时间间隔:修改环境参数中的execution.checkpointing.interval,可实现按时间间隔写入,即使文件大小没满足配置要求; |
| 写入模式 | 支持insert into。 表示采集到的数据不管是什么操作,在hive中都会对应新增一条数据。详见概览页的图解。 |