Flink Jar
该功能专业版、旗舰版支持
Flink Jar任务
基于Flink官方提供的DataStream API,使用Java或者Scala语言进行实时计算任务的开发。该模式相比FlinkSQL拥有更高的自由度,同时对开发人员的能力要求也更高。目前平台支持用户在线下完成任务的开发,然后将代码打包成JAR上传至平台进行管理。
任务上传
首先通过资源管理上传任务JAR包,详见资源管理
note本文提供简单WordCount程序,使用Apache Flink流处理框架来统计文本中每个单词出现的次数。 可以点击WordCount.jar下载。
任务创建
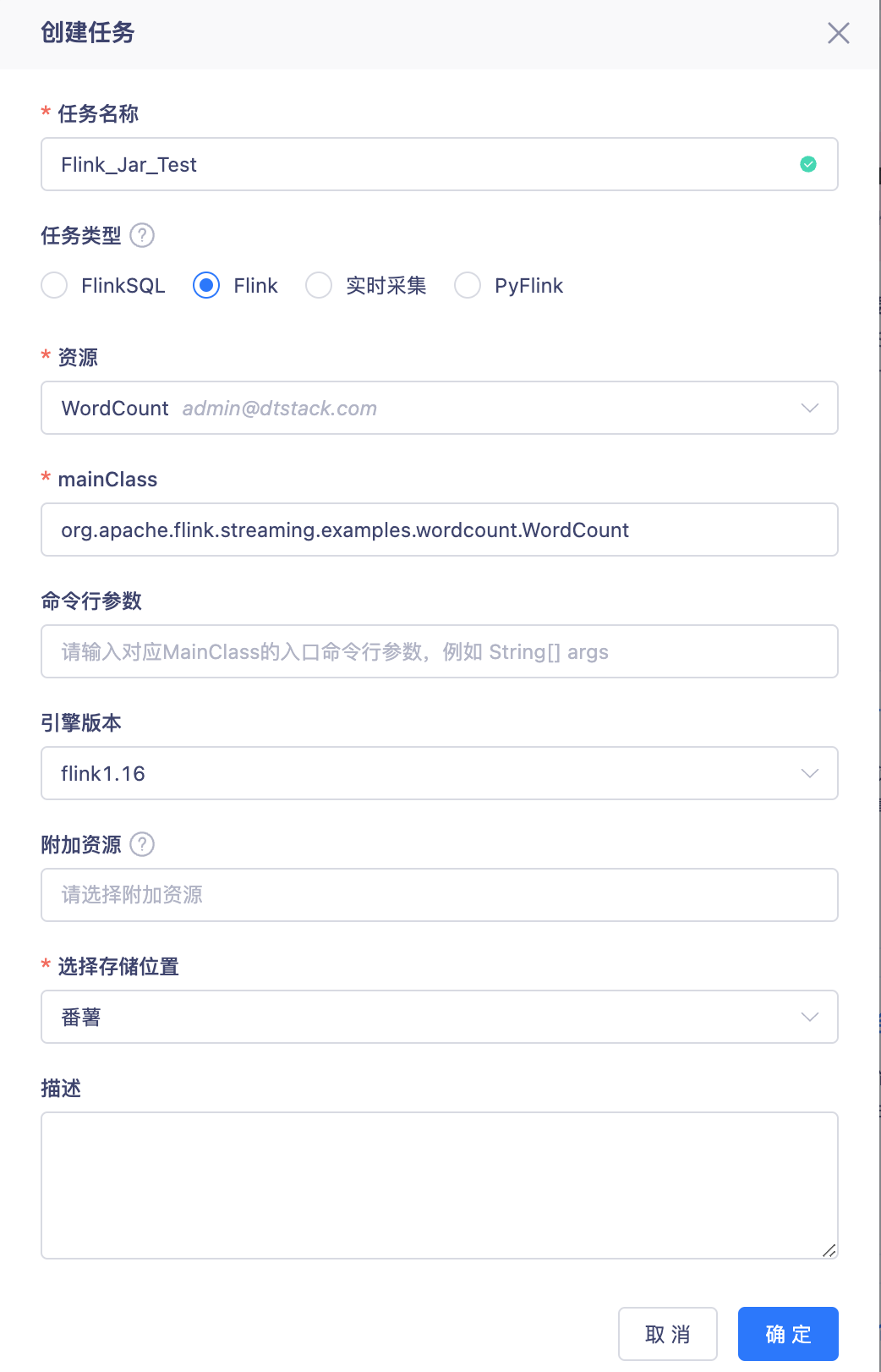
选择资源:下拉显示【资源管理】目录中上传的文件
Mainclass:所选择JAR包的入口函数
命令行参数:请输入对应MainClass的入口命令行参数,例如 String[] args
附加资源:关联上传至项目内的其他资源文件,例如Kerberos认证使用的krb5、Keytab文件等
note多资源引用创建Flink任务时不支持基于K8s进行运行和调度。
任务管理
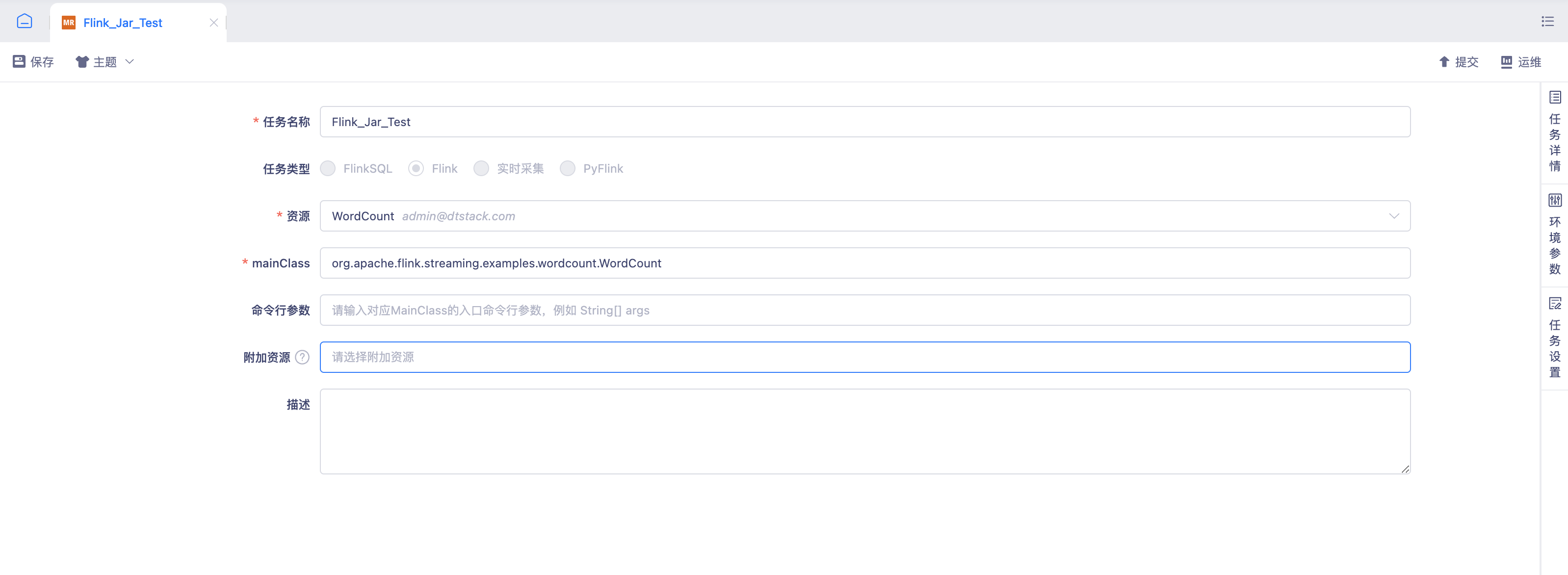
任务详情:任务属性、历史版本
noteFlinkJar任务的历史版本只做历史提交记录,不支持版本比对和回滚。
环境参数:任务运行相关的参数配置可以参考Flink Execution Configuration
任务设置:任务设置、启停策略、资源组配置、脏数据(不支持)
任务运维
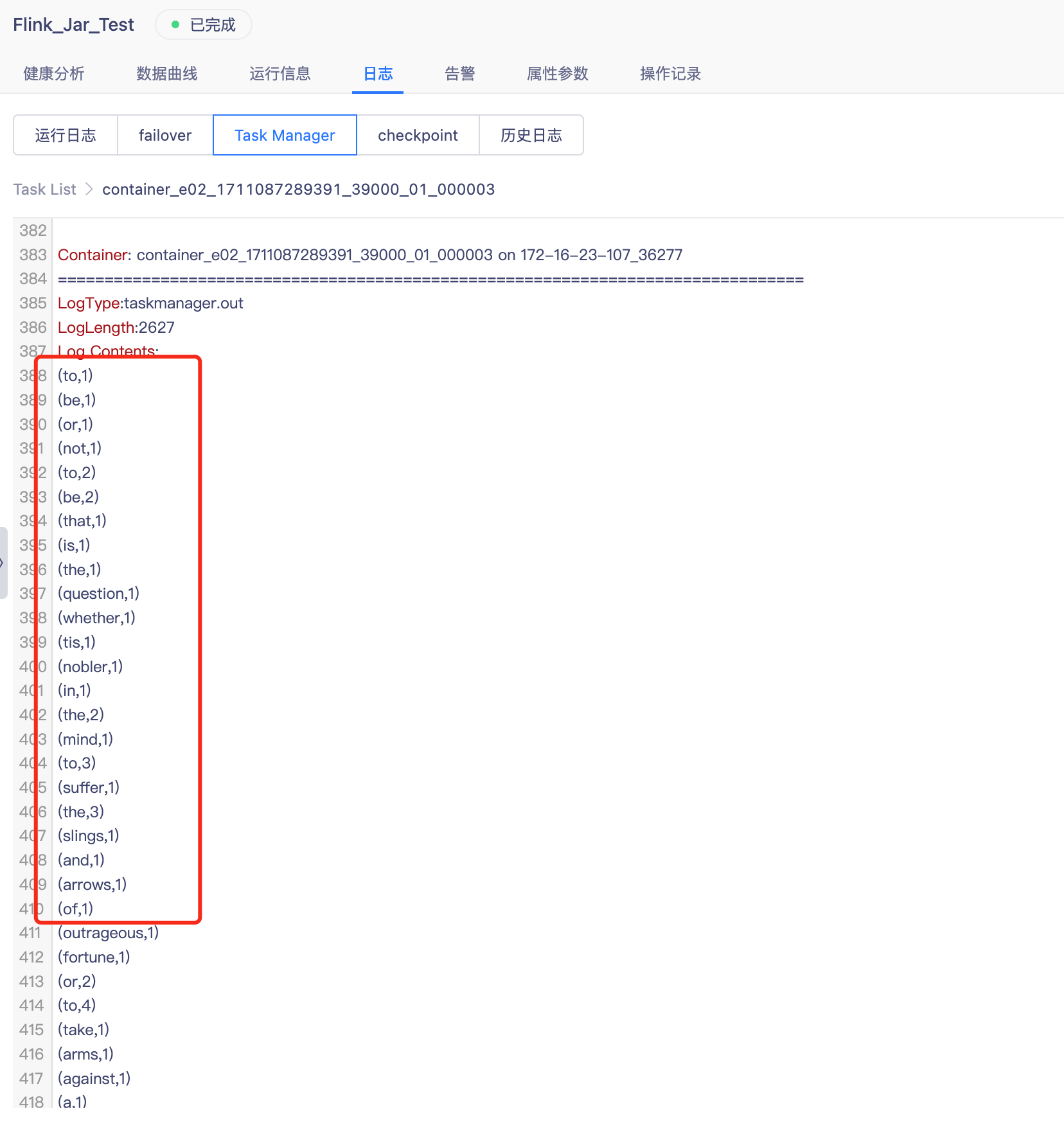
- 任务运行:任务提交任务运维-FlinkJar任务进行调度运行,任务运行完成后查看TaskManager日志。
- 流计算示例结果:在TaskManager日志中以.out结尾的日志文件中输出。
作业开发参考
Flink Jar 需要您在线下完成开发,在实时平台中上传Jar并运行Flink Jar 任务。
开发参考
- Apache Flink简介,以及它的体系架构、应用程序和特性功能等,请参见Apache Flink介绍。
- Apache Flink V1.16业务代码开发,请参见Flink DataStream API开发指南和 Flink Table API & SQL开发指南。
- Apache Flink的编码、Java语言、Scala语言、组件和格式等指南,请参见代码风格和质量指南。
- Apache Flink作业的源代码项目配置,请参见Project Configuration。
- Flink DataStream Connector依赖,请参见Connector依赖。
- Apache Flink编码过程中遇到的问题及解决方法,请参见常见问题。
开发Demo FlinkStreamAPI:基于数栈的flink api demo
如果您有兴趣研究其源代码,请单击FlinkStreamAPI.zip下载后进行编译
依赖管理
平台依赖的Flink版本分别是1.10.1和1.12.7,1.16.2 建议开发时版本保持一致,并按照以下要求引入依赖: 打包时保持默认配置即可的包:
- 一些无关hadoop,flink的包,比如:mysql-connector-java、jedis等
- Flink的连接器包,比如:flink-connector-kafka、flink-connector-jdbc等
- Flink的Formats包,比如:flink-json,flink-avro、flink-avro-confluent-registry等
打包时需要将依赖的**scope**属性设置为**provided**的包:
- Flink核心依赖,如core、planner、runtime、flink-java等
- Hadoop相关的依赖,如hadoop-common等
- scala相关的依赖,如scala-library等
- 日志相关的依赖,如log4j-api、log4j-core、slf4j-api等。在1.10中使用日志时,需要引入logback-classic并将其
scope保持默认打包。
若引入了其他的包,但是其中依赖了上述的包,需要使用exclusion将其排除,例如引入hive-jdbc时,配置如下:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<!--
SparkThrift对Driver版本要求比较严格,需要注意版本,否则会报错 Required field 'client_protocol' is unset!
Hiveserver2对Driver版本要求会宽松一些
-->
<version>1.1.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
</exclusion>
</exclusions>
</dependency>
若使用了Jackson,Guava,建议使用Flink shade的包,如
// 引入Blink就会包含下面的包
// Jackson
import org.apache.flink.calcite.shaded.com.fasterxml.jackson.databind.ObjectMapper;
// Guava
import org.apache.flink.calcite.shaded.com.google.common.cache.Cache;
下面是一个正常的Flink任务的依赖配置:
<!-- Scala scope需要设置为provided -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.7</version>
<scope>provided</scope>
</dependency>
<!-- Flink 核心依赖 scope需要设置为provided -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.varsion}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.varsion}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- Hadoop相关依赖,也设置成Provided -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Flink Formats -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro-confluent-registry</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink Connector -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.varsion}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.varsion}</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Flink Connector -->
<!-- 其他依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!--
这个依赖是我们需要打包包含的,但是它本身依赖了很多hadoop相关的包,我们需要将其排除掉。
若您在代码中用到了hadoop的某些依赖,需要单独引入,并设置scope为provided
-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
</exclusion>
</exclusions>
</dependency>
下面是使用日志需要的配置:
<!-- 日志 -->
<!-- 如果在代码中使用了日志,这个依赖是必须的 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.1.7</version>
</dependency>
附加资源使用
当前附加资源的使用会涉及到数栈内部enginePlugin,对于Flink Jar任务没有一个通用的获取资源文件的方式供自定义 jar 任务去获取资源文件。 对于每一个任务而言,调度引擎Engine都会创建一个与之对应的临时任务文件目录,此处记作 $TASK_PATH,该目录存放了任务所需的文件。
- Flink Jar 任务
对于客户的 Flink Jar 任务: Engine 会将Flink Jar 包上传至 $TASK_PATH/jar 目录中,会将附加资源上传至 $TASK_PATH/resource 目录中。 客户目前没有通用的手段去获取到 $TASK_PATH 的值。因此当前只能另一种方法去获取 $TASK_PATH 的值:
public class Test {
public static void main(String[] args){
String jarPath = Test.class.getProtectionDomain().getCodeSource().getLocation().getPath();
String taskPath = jarPath.substring(0, jarPath.lastIndexOf("/jar/"));
String resourcePath = taskPath + "/resource";
String propertiesPath = resourcePath + "/application.properties";
String confConf = resourcePath + "/xx.conf";
}
}
该方法先通过自定义 JAR 的入口函数获取到该类所在的 JAR 包路径也就是$TASK_PATH/jar 目录,然后再通过相对路径定位到 $TASK_PATH/resource 目录。最终获取到附加资源文件。该方法是强度依赖于 Engine 的代码实现的。