实时采集Mysql间隔轮训自定义SQL案例
场景描述
在日常采集任务开发中,会遇到对采集的源表需要进行简单的加工处理,例如仅采集表中某几个字段的数据、需要新增一些过滤条件、需要join一张维表丰富数据等,则可以通过自定义SQL的方式实现。本次针对实时采集1.16版本输出一个演示Demo。
实时采集-间隔轮训
前置环境准备
- 数栈6.2版本
- FLinkSQL1.16版本
- Mysql5.7数据源、Kafka2.x数据源
开发采集任务
实时采集任务来源表Mysql、目标表Kafka通过间隔轮训的采集方式
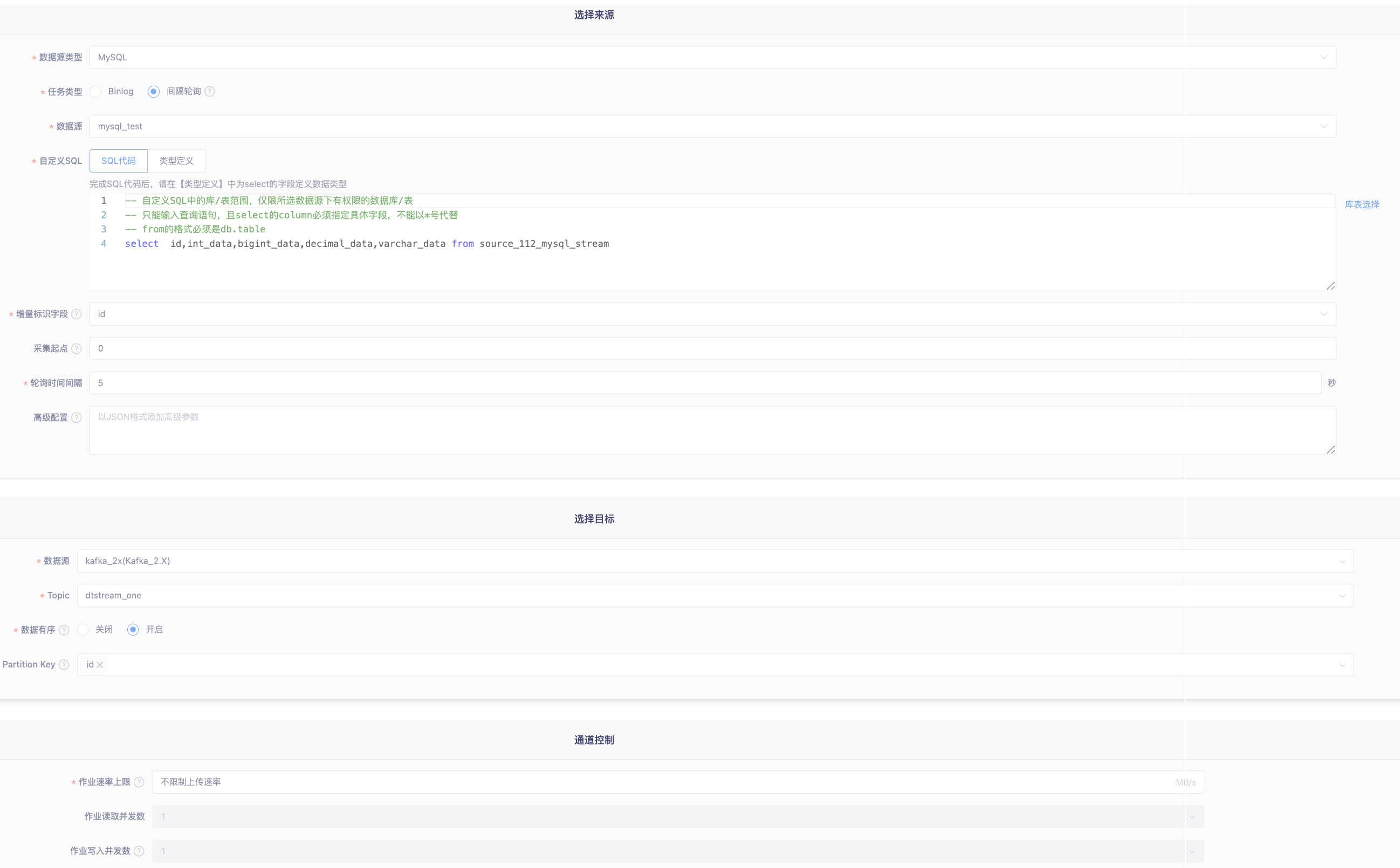
配置自定义SQL 手动输入查询SQL

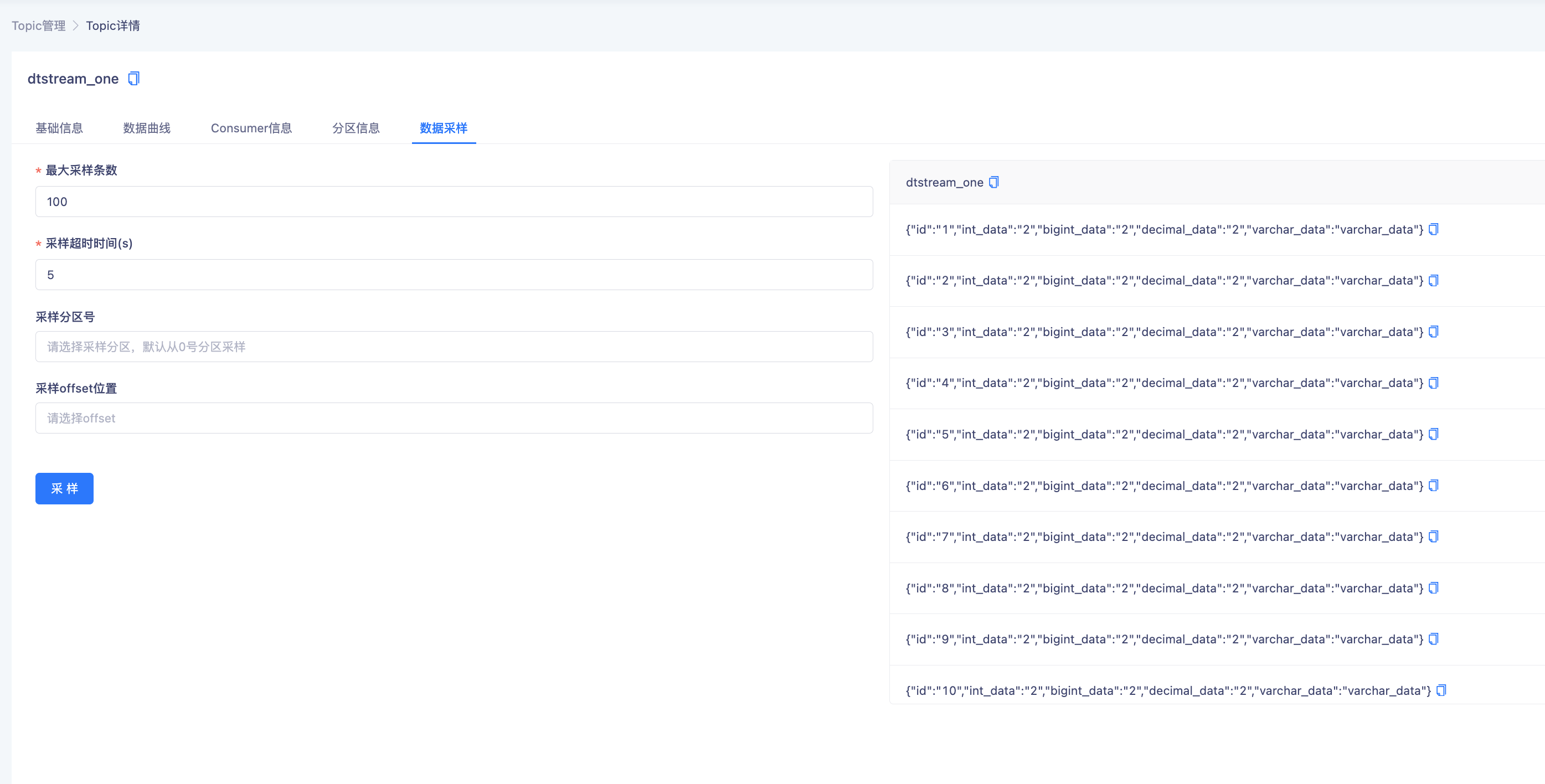
检查SQL定义的正确性查看字段类型

实时采集脚本预览
{
"job" : {
"content" : [ {
"reader" : {
"parameter" : {
"password" : "******",
"customSql" : "select id,int_data,bigint_data,decimal_data,varchar_data from source_112_mysql_stream",
"startLocation" : "0",
"increColumn" : "id",
"column" : [ {
"name" : "id",
"type" : "INT",
"key" : "id"
}, {
"name" : "int_data",
"type" : "INT",
"key" : "int_data"
}, {
"name" : "bigint_data",
"type" : "BIGINT",
"key" : "bigint_data"
}, {
"name" : "decimal_data",
"type" : "DECIMAL",
"key" : "decimal_data"
}, {
"name" : "varchar_data",
"type" : "VARCHAR(255) ",
"key" : "varchar_data"
} ],
"pollingInterval" : 5000,
"connection" : [ {
"jdbcUrl" : [ "jdbc:mysql://localhost:3306/automation" ]
} ],
"polling" : true,
"username" : "drpeco"
},
"name" : "mysqlreader"
},
"writer" : {
"parameter" : {
"tableFields" : [ "id", "int_data", "bigint_data", "decimal_data", "varchar_data" ],
"producerSettings" : {
"zookeeper.connect" : "",
"bootstrap.servers" : "localhost:9092"
},
"dataCompelOrder" : true,
"topic" : "dtstream_one",
"partitionAssignColumns" : [ "id" ]
},
"name" : "kafkawriter",
"type" : 37
}
} ],
"setting" : {
"restore" : {
"isRestore" : true,
"isStream" : true,
"restoreColumnName" : "id",
"restoreColumnIndex" : 0
},
"errorLimit" : { },
"speed" : {
"readerChannel" : 1,
"writerChannel" : 1,
"bytes" : -1048576,
"channel" : 1
}
}
}
}
提交运行后采集输出至Kafka