StreamWorks 6.4.0更新日志
发布时间:2025-08-25
新增
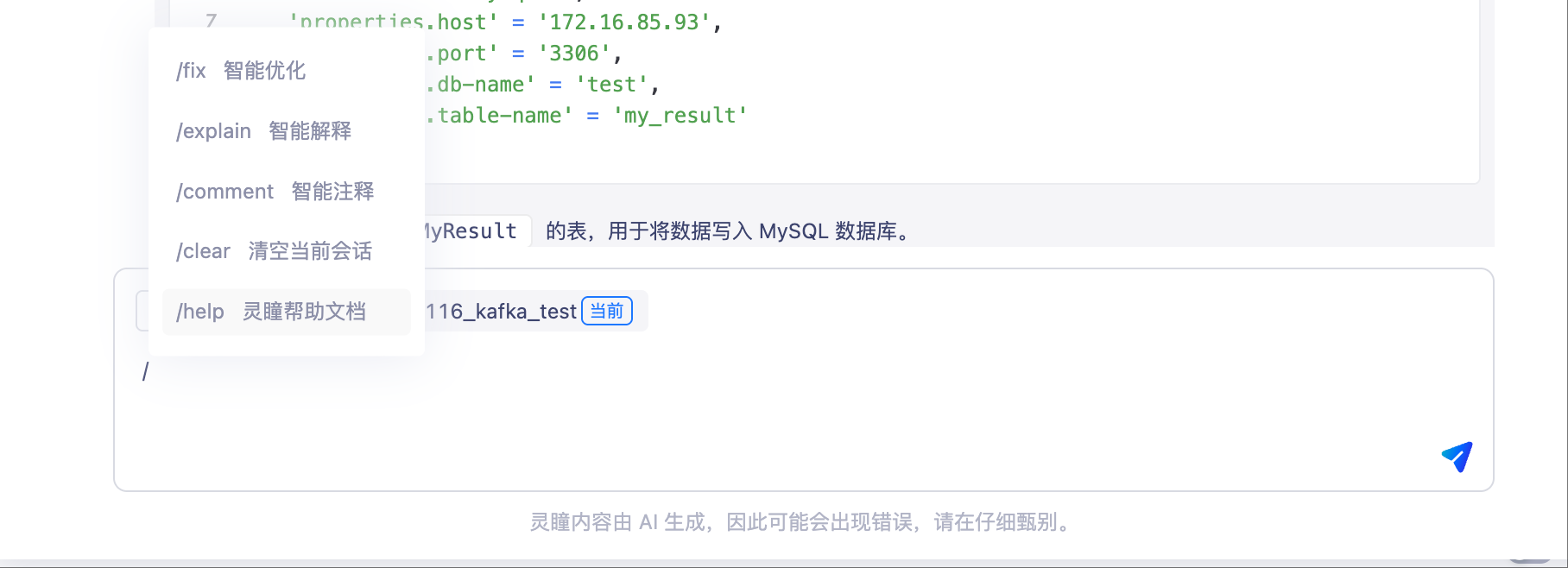
灵瞳问答支持预置快捷指令【6.4】【旗舰版】
背景:
预置快捷指令主要是为了提高用户的操作效率和交互体验,用户可以通过快捷指令快速输入常用的命令,无数手动输入完整内容。同时标准化的输入,通过预置指令可以引导用户使用规范的提问格式,帮助系统更准确地理解用户意图。对于新用户可以展示系统的核心功能和常见用法,降低学习成本。
说明:
灵瞳提供多种智能辅助功能,帮助用户在灵瞳编辑框中高效完成FlinkSQL的优化、注释、解释和添加上下文管理。
支持的扩展功能包括:
fix:智能优化当前选中的 FlinkSQL
comment:为当前选中的 FlinkSQL 添加专业代码注释
explain:逐步解析当前选中的 FlinkSQL
clear:清空当前灵瞳会话
help:查看灵瞳帮助文档
还可以通过使用以下变量提供额外的上下文来帮助我理解你的问题:
#task: 选择工作区中的FlinkSQL任务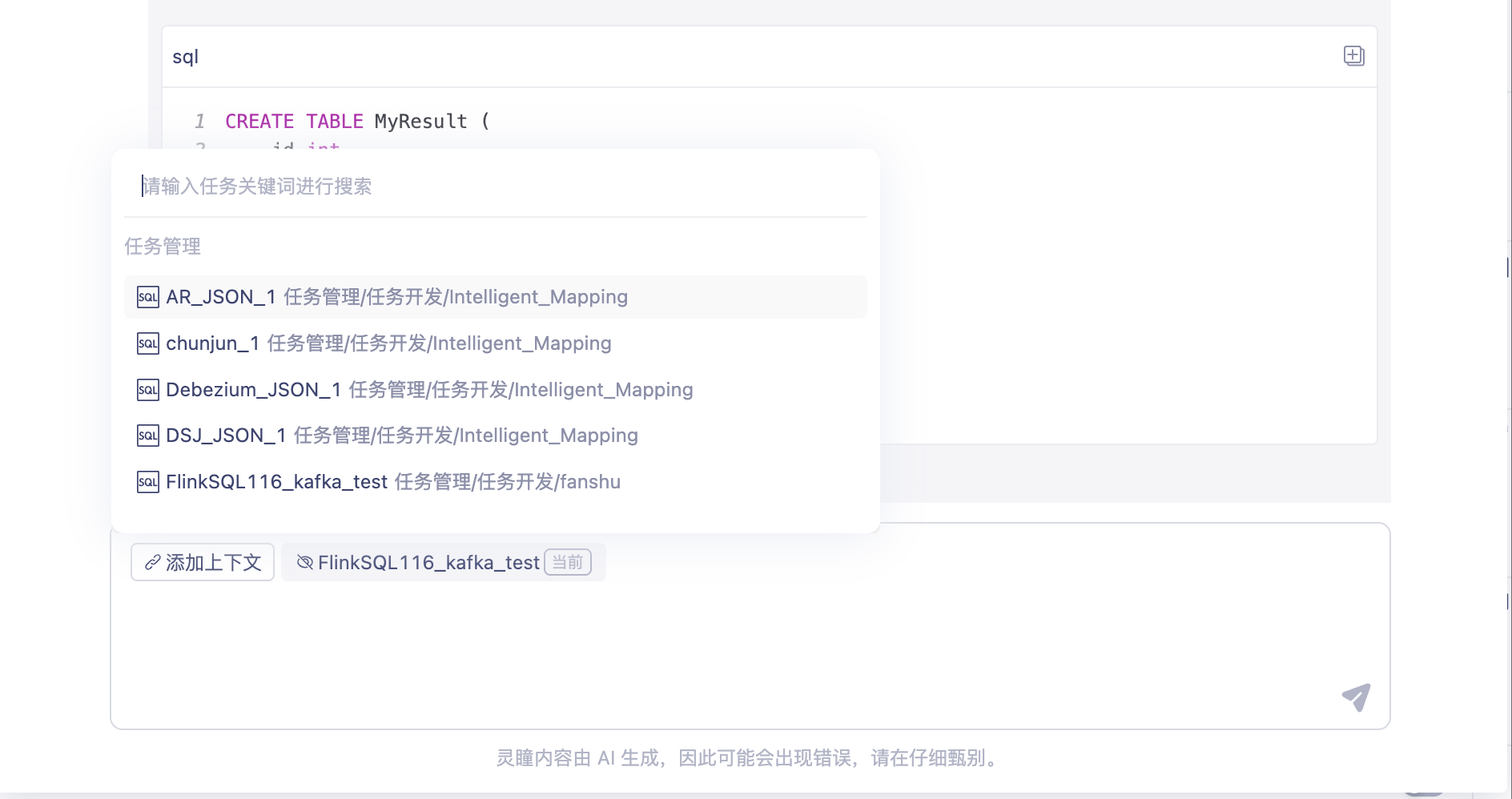
所有功能均在 灵瞳编辑框 中进行操作。
AI功能权限设置:访客不允许访问灵瞳、数据开发:智能优化、智能解释、智能注释、日志智能解析;任务运维:日志智能解析。
AI辅助数据智能映射【6.4】【旗舰版】
背景:
数据开发在开发FlinkSQL解析Json数据时,传统方式需要手动定义字段和类型难以满足动态变化解析Json中字段名Key及其数据类型Value Type。结合大模型LLM智能类型判断,通过Value的格式动态的生成Value Type,从而减少人工维护并且能实时的对Kafka Topic数据进行解析处理,增强功能的灵活性和可靠性。
说明:
当前数据源为 FlinkSQL Kafka 来源表
Kafka Topic 中的数据格式需为以下任一标准格式:
- JSON
- OGG-JSON
- Chunjun-JSON
- AR-JSON
- Debezium-JSON
- DSJ-JSON
智能映射开关: 控制是否启用 AI 能力进行字段映射。
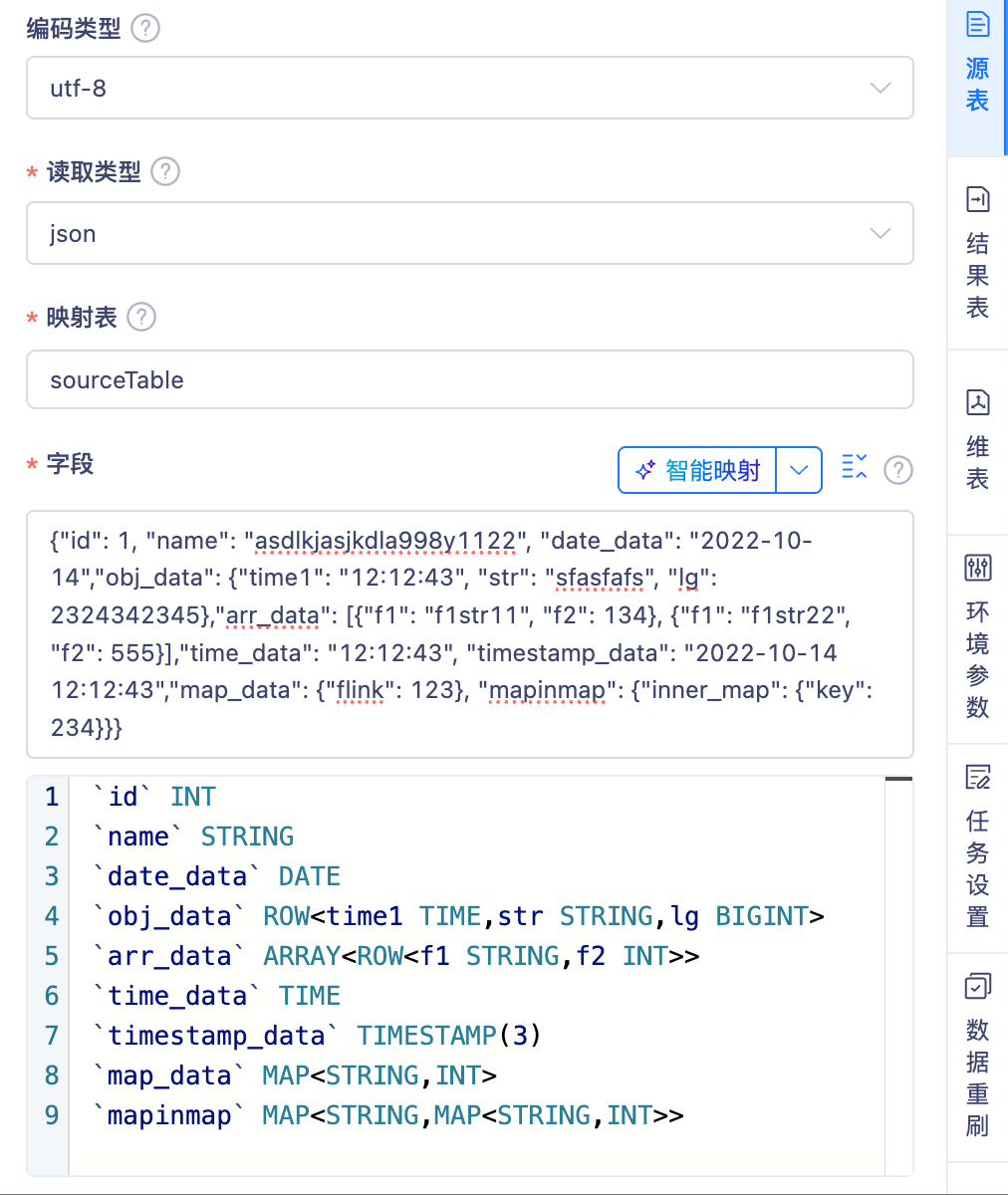
使用规则:
- 开启 AI 功能 → 自动映射方式自动切换为智能映射
- AI 调用失败 → 自动退回自动映射,不影响流程
- 不提供智能映射的额外选择项,由开关直接控制
- 支持手动切换为“手动输入”方式进行字段映射
中信建投-交付需求优化发布包流程【6.0】
背景:
- 当前实时任务发布包在执行批量发布、停止、启动等操作时效率不高,且缺乏对资源包版本管理、任务状态控制、异常提示等方面的优化。
- 为提升用户批量操作体验、减少出错率、提高发布流程的可控性,需对相关功能进行增强。
说明:
- 支持资源与函数关联打包:打包任务可同时选择并打包关联的资源、函数。
- 一键提交失败可重试:提交失败后支持再次一键提交或删除任务。
- 运行中任务可直接重启:一键提交时自动停止运行中任务并重新启动。
- 支持删除发布包:可删除已打包或导入的发布包。
- 资源/函数可版本更新:支持通过发布更新被多个任务引用的资源或函数。
中信建投-实时支持通过消息推送对公共管理租户数据源进行绑定【6.0】
背景:
- 支持通过消息推送进行租户数据源绑定,适用于多种数据源类型,需配合公共组件进行定制化开发。
说明:
支持数据源类型
- Oushu
- MySQL
- Oracle
- OceanBase(OB)
- SQL Server(SR)
- Greenplum(GP)
- 达梦(DM)
- Kafka
- HBase
任务参数支持密文优化统一参数语法和严格作用域限制【6.3】【标准版】
背景:
修改通过 统一参数语法 和 严格作用域限制,提升脚本模式的安全性和可维护性。需重点确保旧作业的平滑迁移和密文参数的加解密可靠性。
说明:
- 参数使用范围限制
原行为:允许在字段(如
SELECT ${param})、With参数、SQL语句中任意位置使用参数。新规:仅允许在
WITH参数 和 SQL语句体,禁止在字段定义中直接使用。示例:
-- 允许
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = ${group_id},
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
INSERT INTO sink_table SELECT * FROM ${table_name} WHERE dt = '${date}';
-- 禁止(字段中使用)
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`${table_name}` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) -- 报错
- 项目级加密参数语法简化
原语法:
${secret_values.参数名}(如${secret_values.password})。新语法:统一为
${参数名},通过参数类型(明文/密文)自动判断处理逻辑。示例:
-- 旧版(需废弃)
CREATE TABLE mysqlTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://localhost:3306/test',
'schema-name' = 'test',
'table-name' = 'flink_type',
'username' = 'root',
'password' = '${secret_values.password}'
)
-- 新版
CREATE TABLE mysqlTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://localhost:3306/test',
'schema-name' = 'test',
'table-name' = 'flink_type',
'username' = 'root',
'password' = '${password}'
)
- 密文参数全流程统一
- 应用场景:新建、编辑、复制作业时,所有密文参数均使用
${参数名}格式。 - 逻辑判断:
- 前端:根据参数类型(明文/密文)渲染输入框(明文显示普通文本,密文显示掩码)。
- 后端:存储时对密文参数值加密,运行时按类型解密。
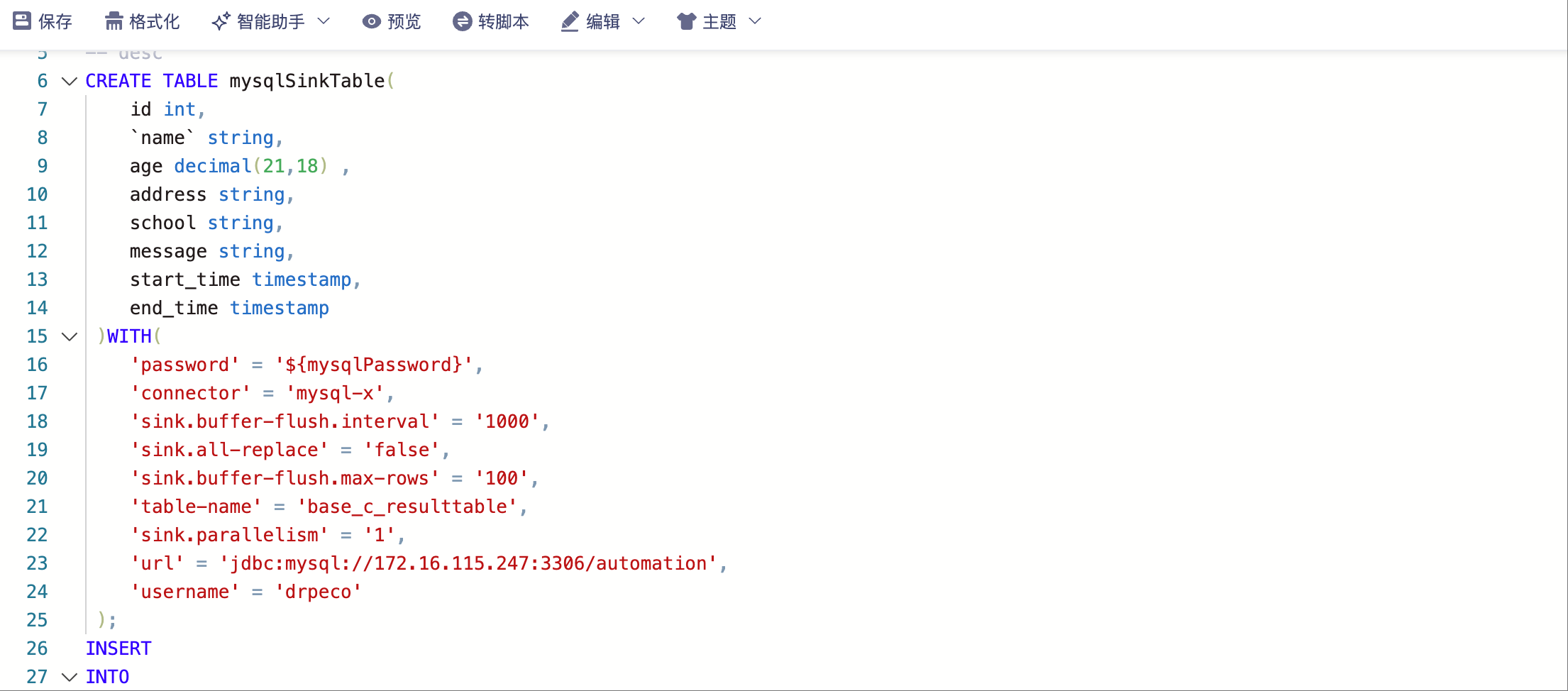
- 应用场景:新建、编辑、复制作业时,所有密文参数均使用
- 参数使用范围限制
优化
实时kafka预览功能自动销毁消费者机制【6.3】【旗舰版】
背景:
在 实时源表 Kafka 数据预览 功能中,系统会临时创建一个 Kafka 消费者,用于从指定 Topic 拉取最新数据并展示给用户。 为了避免在预览结束后仍占用集群资源,系统对临时消费者的生命周期进行了优化管理。
说明:
全部修改为默认的Topic消费组,通过后端配置切换是否使用每日新增Topic消费组的方式。默认开关使用默认的Topic消费组。
Engine-plguins优化FlinkSQL语法校验异步执行优化方案【6.4】【标准版】
背景:
当前实时平台的 SQL 语法检查为同步阻塞模式,遇到客户大 SQL(如大量
UNION ALL)时,Calcite 在解析过程中会构建大量对象,运行时间可达 3 分钟以上。平台通过 SDK 调用 engine 执行语法检查时,因默认超时 1 分钟且会重试三次,导致:1. **平台端问题**:语法检查超时抛出异常,用户体验差。
2. **调度端问题**:多次重复调用 grammarcheck,产生大量对象,加重 JVM GC 压力,影响稳定性。
3. **线程池问题**:语法检查与任务提交共用线程池,长时间阻塞会影响任务提交。
目前仅能通过临时调整 SDK 超时时间缓解,缺乏根本性优化。
说明:
- 将语法检查由同步阻塞改为异步获取,避免超时与重复调用问题。
- 支持平台端在异步模式下拉取语法检查结果,并在结果未返回前给予合理的用户提示。
- 调整任务调度逻辑,防止 grammarcheck 接口重复调用。
- 分离语法检查与任务提交线程池,保障任务提交不受影响。
前端优化数据开发模块FlinkSQL操作表功能交互响应保持稳定FPS【6.4】【标准版】
背景:
当数据开发任务数量超过2K+,导致的前端页面加载变慢以及卡顿问题,进行优化数据开发模块FlinkSQL右侧的新增源表功能交互响应 FPS,保持FPS稳定在 50 - 60 帧。
说明:
- 通过 Redux 优化、IndexDB 异步化、React 组件缓存、Antd 虚拟滚动 等策略,可显著提升 FPS。
FLinkSQL版本间内置函数展示区分以及SQL编辑时的区分版本【6.4】【标准版】
背景:
通过版本化函数清单和动态加载机制,实现 Flink 1.12/1.16 内置函数的精准区分,确保用户在不同版本环境下获得正确的语法支持。
说明:
Flink 1.12 和 1.16 版本的内置函数存在差异(如新增/废弃函数、语法变更),在平台中实现:
版本隔离:区分 1.12(及更低版本)和 1.16 的函数列表。
动态展示:根据用户选择的 Flink 版本,在数据开发 IDE 中返回对应的函数列表。
兼容性处理:支持单一版本环境(仅 1.12)和混合版本环境(同时存在 1.12 和 1.16)。
FLinkSQL任务SQLQuery执行操作支持手动切换Session和Perjob调度方式【6.4】【标准版】
背景:
当前 FlinkSQL 任务的 SQLQuery 执行仅支持单一调度模式(如默认 Session 模式),但实际场景中用户需要根据需求灵活切换。
说明:
- 后端默认使用Session方式。通过flinkTaskRunmode=per_job参数切换。
- 执行部署模式仅支持单选,不允许Perjob和Session同时配置参数。
- Session为默认支持方式、未配置时提示需要配置Session模式。如需要使用Perjob方式提交,需要配置任务环境参数进行调整。