PyFlink
基于Flink官方提供的Python API,开发人员可以在Flink上开发Python任务,更好地进行数据分析。
info
该功能仅旗舰版支持
开发环境准备
在平台开发、运行PyFlink任务前提是要准备Python环境。可以在【项目管理-PyFlink环境管理】模块上传准备好的环境文件。下文将以Python3.8为例,为您介绍如何准备虚拟环境。
生成环境包
- 在本地准备/build/setup-pyflink-virtual-env-linux.sh脚本,其内容如下:
set -e
# 下载Python 3.8 Miniconda3-py38_4.11.0-Linux-x86_64.sh 脚本。
wget "https://repo.anaconda.com/miniconda/Miniconda3-py38_4.11.0-Linux-x86_64.sh" -O "Miniconda3-py38_4.11.0-Linux-x86_64.sh"
# 为Python 3.8 miniconda.sh脚本添加执行权限。
chmod +x Miniconda3-py38_4.11.0-Linux-x86_64.sh
# 创建Python的虚拟环境。
./Miniconda3-py38_4.11.0-Linux-x86_64.sh -b -p linux_venv
# 激活Conda Python虚拟环境。
source linux_venv/bin/activate ""
# 安装PyFlink依赖。
# update the PyFlink version if needed
pip install "apache-flink==1.12.5"
# 关闭Conda Python虚拟环境。
conda deactivate
# 删除缓存的包。
rm -rf linux_venv/pkgs
# 将准备好的Conda Python虚拟环境打包。
zip -r linux_venv.zip linux_venv- 在本地准备 linux_build.sh 脚本,其内容如下:
#!/bin/bash
set -e -x
yum install -y zip wget
cd /root/
bash /build/setup-pyflink-virtual-env-linux.sh
mv linux_venv.zip /build/- 在CMD命令行,执行如下命令:
docker run -it --rm -v $PWD:/build -w /build quay.io/pypa/manylinux2014_x86_64 ./linux_build.sh- 执行完该命令后,会生成一个名字为venv.zip的文件,即为Python 3.8的虚拟环境。
- 上传环境包
- 登录实时平台后,进入项目管理 - PyFlink环境管理 菜单。
- 点击上传文件,上传刚刚生成的环境包venv.zip文件。
- 平台上传文件大小的限制为200 MB,而Python虚拟环境的大小通常会超过该限制。因此,您需要修改配置文件中的相关参数大小
- 打开平台配置文件: vim .../DTFront/tengine/conf/nginx.conf
- 修改client_max_body_size参数的大小
- 在创建PyFlink任务时,选择venv.zip文件。
- 通过任务数量,可查看当前环境被使用的任务列表。 没有任务引用该环境时,可删除虚拟环境。
开发任务
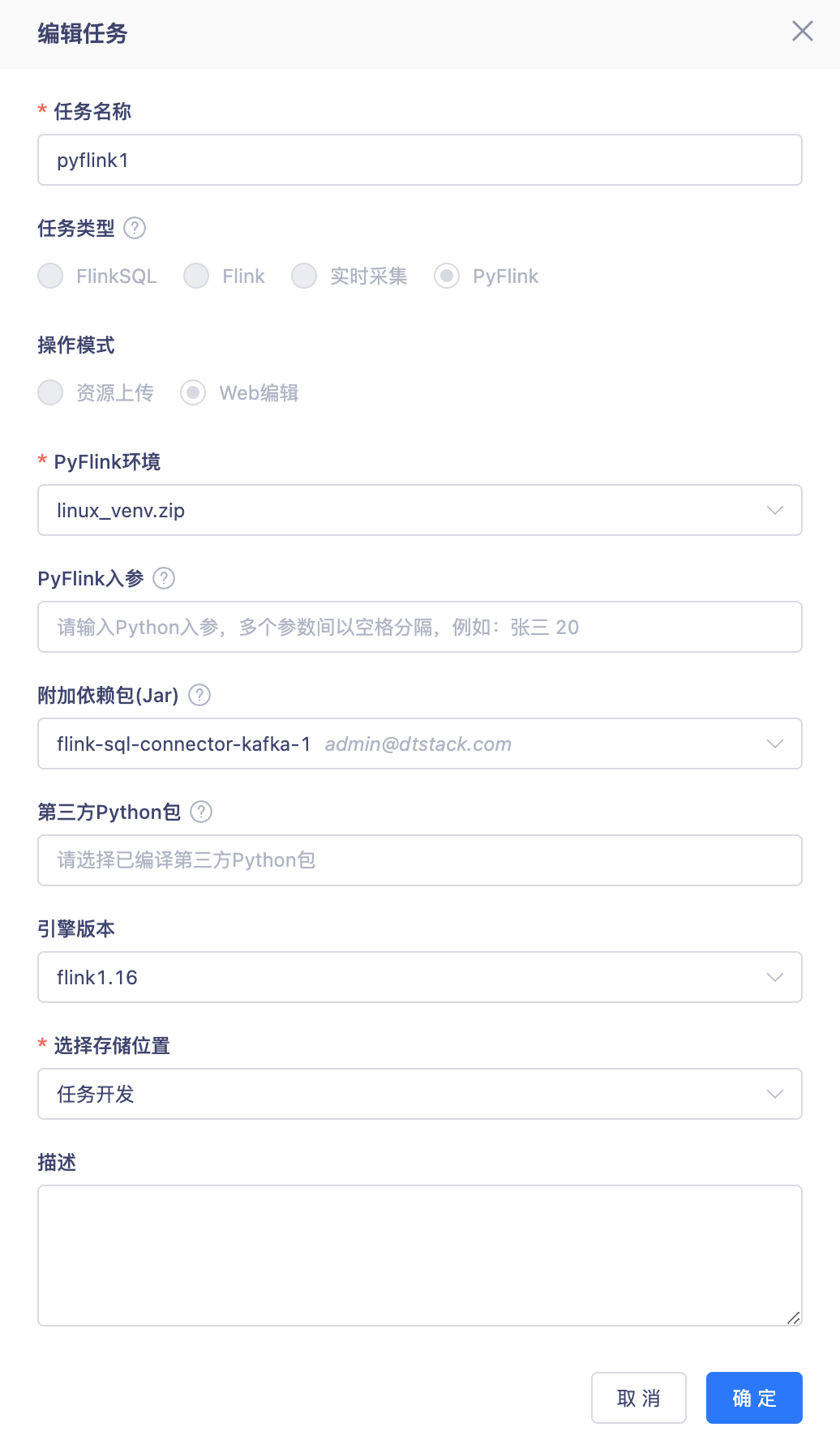
任务开发
- 新建PyFlink任务:直接在Web端编辑和维护Python代码(Flink1.16)
- Python脚本
import sys
from pyflink.common import Row
from pyflink.common.serialization import SimpleStringSchema
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import FlinkKafkaConsumer
def kafka_datastream_api_demo(a: str = 'default_a', b: str = 'default_b'):
# 1. create a StreamExecutionEnvironment
print(' a 参数为:', a)
print(' b 参数为:', b)
print(' datastream_api_demo 参数个数为:', len(sys.argv), '个参数。')
print(' datastream_api_demo 参数列表:', str(sys.argv))
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
kafka_source = FlinkKafkaConsumer(
topics='test1',
deserialization_schema=SimpleStringSchema(),
properties={'bootstrap.servers': 'localhost:9092', 'group.id': 'test1'})
# setStartFromGroupOffsets(默认方法):从 Kafka brokers 中的 consumer 组(consumer 属性中的 group.id 设置)提交的偏移量中开始读取分区。 如果找不到分区的偏移量,那么将会使用配置中的 auto.offset.reset 设置。
# setStartFromEarliest() 或者 setStartFromLatest():从最早或者最新的记录开始消费,在这些模式下,Kafka 中的 committed offset 将被忽略,不会用作起始位置。
# setStartFromTimestamp(long):从指定的时间戳开始。对于每个分区,其时间戳大于或等于指定时间戳的记录将用作起始位置。如果一个分区的最新记录早于指定的时间戳,则只从最新记录读取该分区数据。在这种模式下,Kafka 中的已提交 offset 将被忽略,不会用作起始位置。
kafka_source.set_start_from_earliest()
ds = env.add_source(kafka_source)
# 3. define the execution logic
ds = ds.map(lambda a: Row( a.split(',')[1] , 1), output_type=Types.ROW([Types.STRING(), Types.INT()])) \
.key_by(lambda a: a[0]) \
.reduce(lambda a, b: Row(a[0], a[1] + b[1]))
# 4. create sink and emit result to sink
ds.print()
# 5. execute the job
env.execute('datastream_api_demo')
if __name__ == '__main__':
print('参数个数为:', len(sys.argv), '个参数。')
print('参数列表:', str(sys.argv))
if (len(sys.argv) >= 3) :
kafka_datastream_api_demo(sys.argv[1],sys.argv[2])
else:
kafka_datastream_api_demo()- 环境配置:修改Python相关环境配置参数
## client 提交端的 python 环境路径
python.client.executable=linux_venv/bin/python3
## taskmanager 端的 python 环境路径
python.executable=linux_venv.zip/linux_venv/bin/python3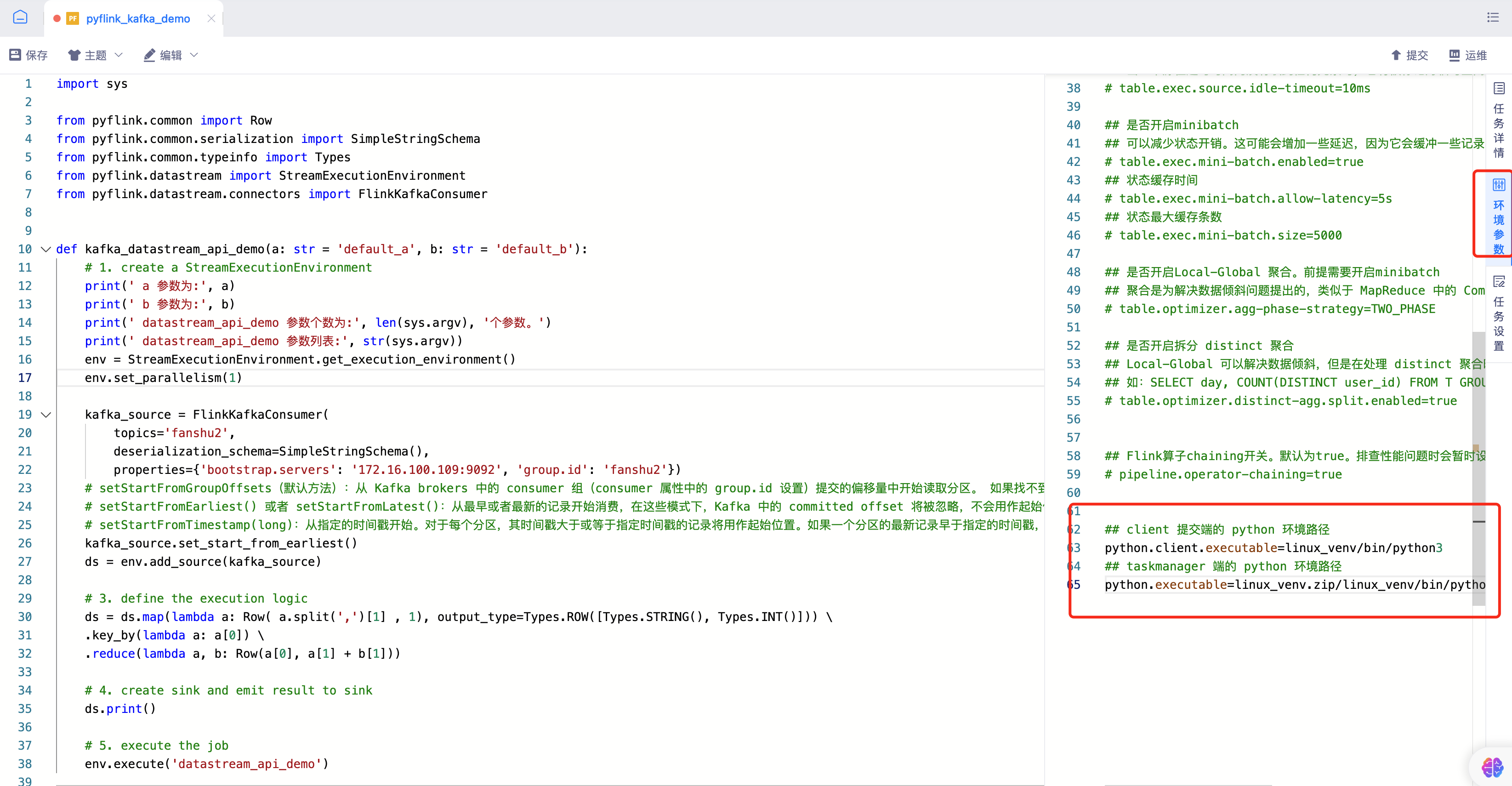
任务运行:PyFlink任务提交调度运行
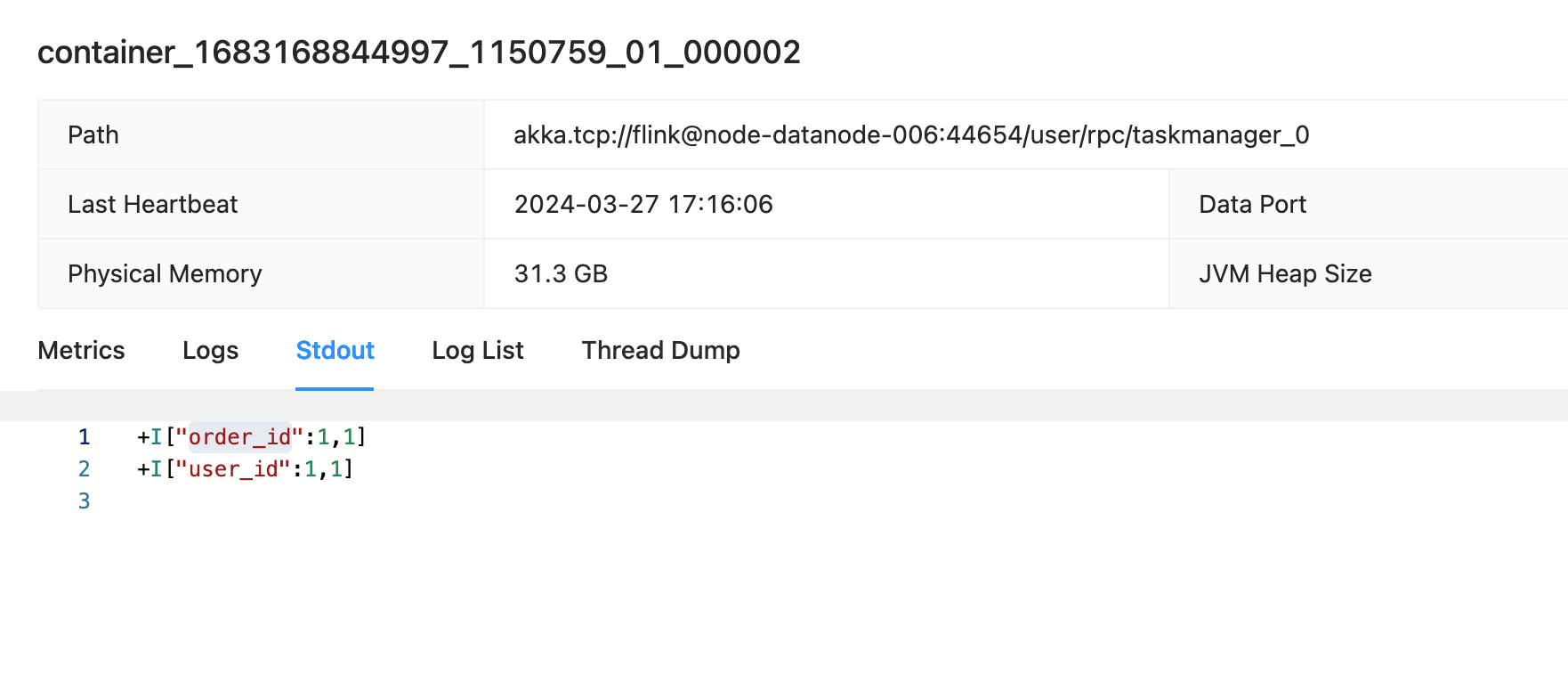
Kafka 输入:
{"id":1,"order_id":1,"item_id":1,"behavior":"content_dasta","real_price":188,"channel_id":1,"name":"name_1","age":"1"}
{"id":1,"user_id":1,"item_id":1,"behavior":"content_dasta","real_price":188,"channel_id":1,"name":"name_1","age":"1"}- 查看taskmaneger.stout:查看输出, 脚本中Json字段数量3个则取Kafka Json中, 对数据集进行处理,程序将数据集中的元素按照第二个部分进行分组,并对相同key的元素进行累加操作。
Kafka插件: flink-sql-connector-kafka-1.16.2.jar 请下载插件并上传资源管理
镜像包:linux_venv.zip 请下载镜像包并上传PyFlink环境管理,此链接为外网下载地址,网络不满足时请手动打包!
| 参数 | 说明 |
|---|---|
| 操作模式 | 资源上传:自己线下完成的Python API作业,必须为.py文件。 Web编辑:在实时开发平台的IDE中完成代码编辑。 |
| Python环境 | 选择在上一步中上传的Python环境 |
| Python入参 | 作业参数,在 python 里面可以通过 sys.argv[1] , sys.argv[2] 去使用。 |
| 附加依赖包 | 如果您的Flink Python作业中使用了Java类,例如作业中使用了Connector或者Java自定义函数时,可以通过如下方式来指定Connector或者Java自定义函数的JAR包。 目前只支持传一个 jar 包, 如果要引用多个。需要自己打包多个 jar 为一个 jar,然后上传。这个 jar 会被添加到 classpath 里面去。 |
| 第三方Python包 | 在python环境中未打包或者只是该任务需要使用的第三方Python包,可通过此处选择。 第三方Python包为.whl格式 |
任务管理
note
PyFlink任务必须在环境参数中维护两个python环境的路径,如下,具体路径请根据实际情况修改:
taskmanager 端的 python 环境路径
python.executable=venv.zip/linux_venv/bin/python3 --venv.zip 是上述PyFlink环境zip包client 提交端的 python 环境路径
python.client.executable=linux_venv/bin/python3 --linux_venv 是上述虚拟环境路径