任务配置管理
概述
在SQL IDE面板右侧,可以看到「任务详情、源表、维表、结果表、环境参数、任务设置、批模式」菜单。下文介绍任务配置相关菜单的功能
FlinkSQL任务管理的介绍
任务详情
使用说明: 任务详情页主要展示任务的元数据信息和版本信息。
任务属性:
- 任务名称:任务创建名称不允许修改。
- 任务类型:目前支持FlinkSQL、FlinkJar、实时采集、PyFlink四种类型。
- 引擎版本:支持切换任务执行的引擎版本,与控制台配置的引擎版本一致,当前Flink1.16和Flink1.12 两个版本的SQL语法存在区别,高低版本切换后需要调整代码,对于FlinkSQL任务不建议切换。
- 创建人员:任务创建者
- 创建时间:任务首次创建时间
- 最近修改时间:任务修改保存后的时间
- 描述:任务创建时描述信息支持编辑时修改
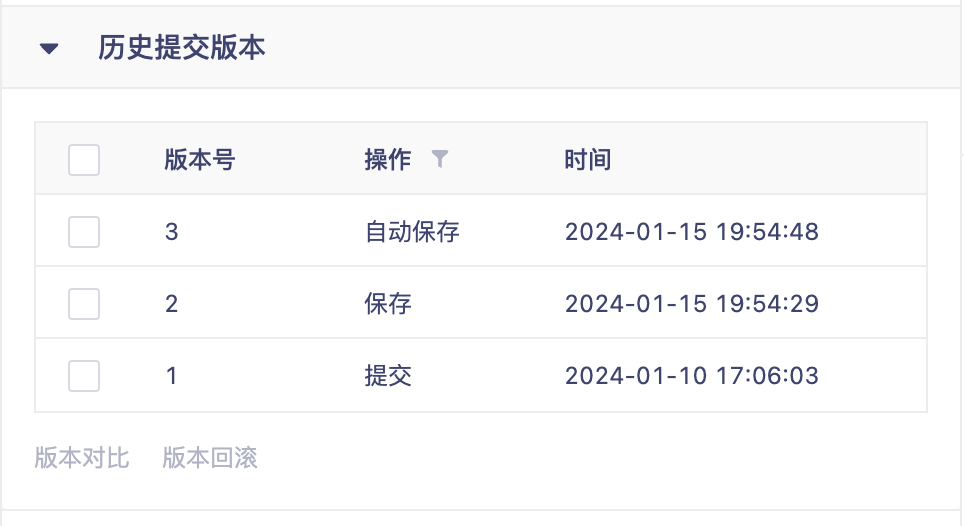
任务历史版本:每次保存、自动保存(任务退出等异常情况)、提交任务时会自动生成一个代码版本,支持任意两个版本之间的代码比对,以及回滚至指定版本。
任务列表最多展示1000次历史记录。
任务列表展示包含:版本号、操作、时间、操作人、描述。
任务历史版本三种操作:保存、自动保存、提交。
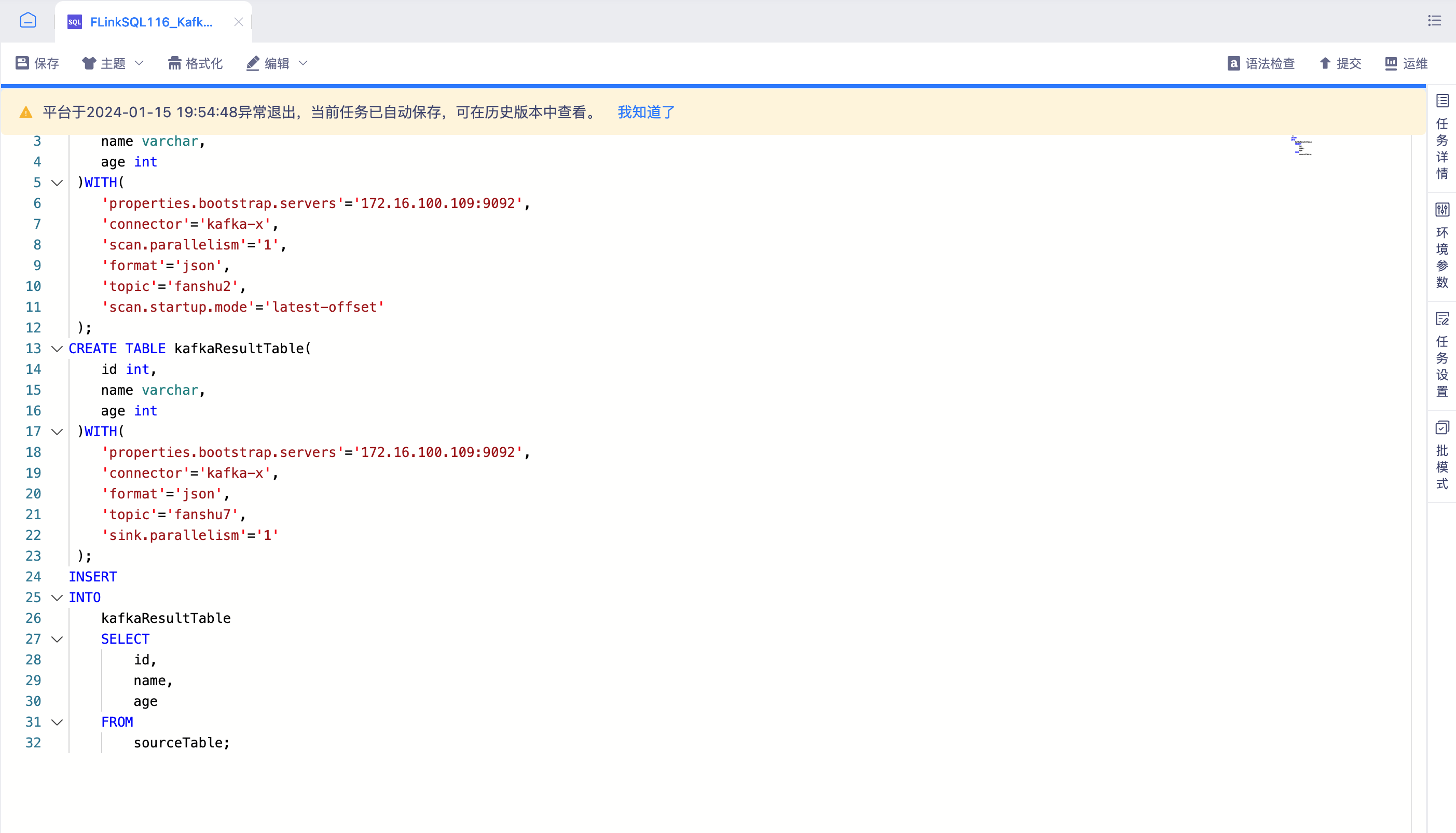
异常退出重新打开任务时提示。
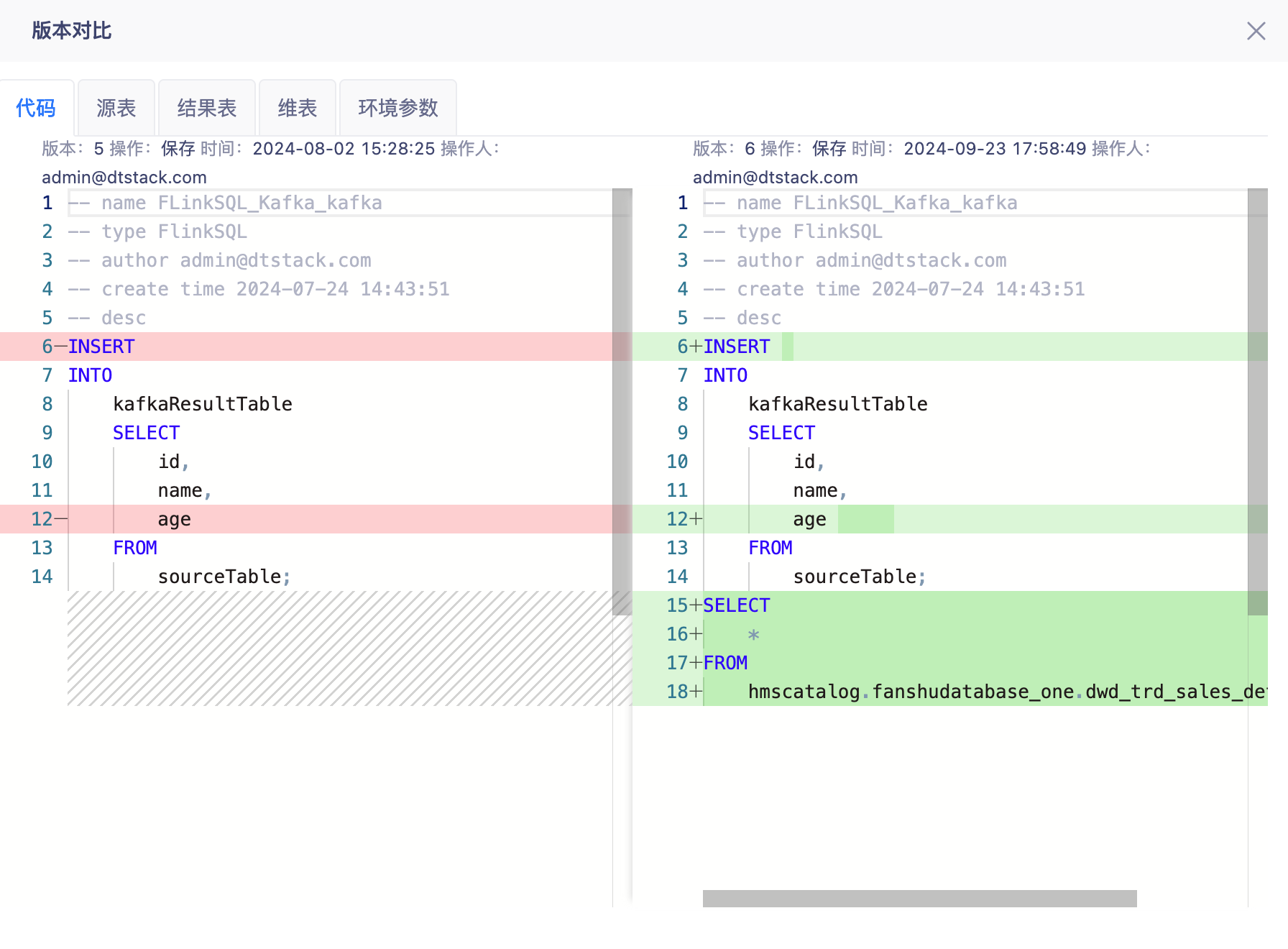
版本对比
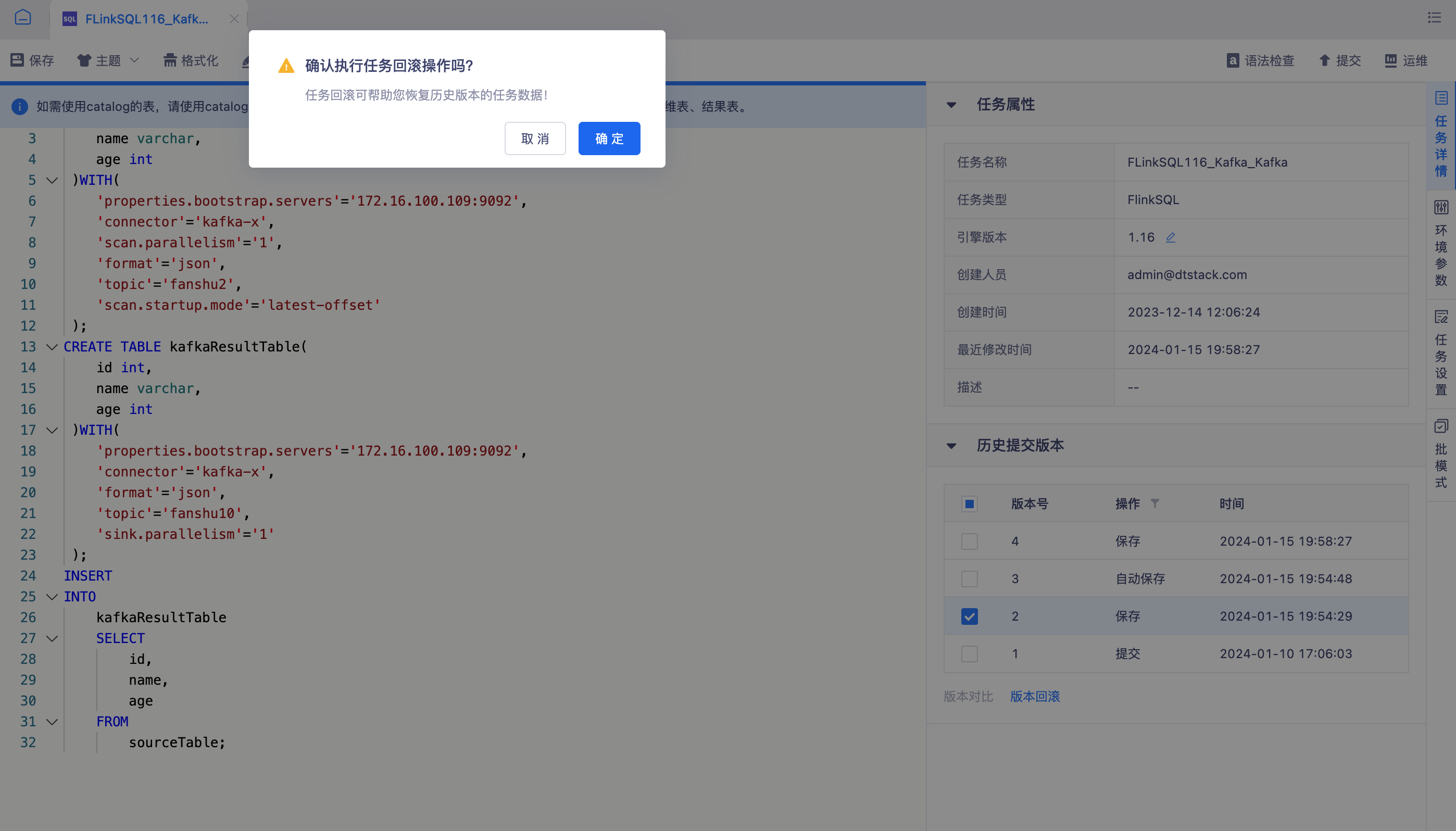
版本回滚
环境参数
使用说明: 实时任务运行过程中所使用的参数,系统均会配置默认值。您也可以根据环境、任务的实际情况进行调整,如调整任务并发数、数据一致性,CheckPoint生成间隔等参数,让任务更好地运行。下文介绍常用的参数内容:
- 资源相关:支持调整任务并行度、TaskSlots数量、JM/TM的内存大小。
- 时间相关:支持调整任务的时间特征,ProcessingTime、EventTime、IngestionTime。
- Checkpoint相关:控制任务取消后的CP自动生成、任务运行中的CP生成间隔、CP语义选择(支持EXACTLY_ONCE、AT_LEAST_ONCE)。
- FlinkSQL状态参数:支持设置状态过期时间,默认为1天。
- 日志等级:设置需要打印的日志等级,默认为info。
- 表动态参数:当你需要在任务中动态调整表参数的时候,开启该配置项。请参考Dynamic Table Options解读
- Kerberos相关:在FlinkSQL任务中使用开启了Kerberos认证的Kafka数据源时,需要手动开启认证参数。参数配置分如下三种情况:
- ZK开启Kerberos,Kafka没开:security.kerberos.login.contexts=Client
- ZK、Kafka都开启了Kerberos:security.kerberos.login.contexts=Client,KafkaClient
- Zookeeper、Kafka都不开启Kerberos:注销参数(默认)
- 窗口提前触发时间:当您希望在窗口结束之前就输出数据结果,可以开启改配置。比如需要统计一天的pv时,窗口设置为1day,开启窗口提前触发,时间设为5min,则每5分钟会计算一次输出upsert流。
- table.exec.source.idle-timeout:开启后,某些source partition没数据,等待N秒,忽略它,让窗口计算继续往下。
- 是否开启minibatch:MiniBatch 聚合的核心思想是将一组输入的数据缓存在聚合算子内部的缓冲区中。当输入的数据被触发处理时,每个 key 只需一个操作即可访问状态。这样可以大大减少状态开销并获得更好的吞吐量。但是,这可能会增加一些延迟,因为它会缓冲一些记录而不是立即处理它们。这是吞吐量和延迟之间的权衡。
- 是否开启Local-Global聚合:开启后,在遇到SUM、COUNT等聚合计算时,会现在本地预聚合,然后下游进行全局聚合,优化数据倾斜情况。
- Flink算子链开关:默认为开启。排查性能问题时可暂时设置成关闭,关闭后会降低实时计算性能。
任务设置
query执行设置: SQLQuery查询使用模式切换,默认Stream模式(查询时长5分钟、结果显示最大条数1000条)条件达到其一则停止任务。
出错重试: 开启后,当任务运行失败时会自动重试。您可以设置重试方式(重跑/续跑)、重试次数、重试间隔、等待超时(超过指定时间后,任务自动取消。建议等待超时时长 ≥ 重试次数 * 重试间隔时长)
启停策略: 选择启停策略,详见项目管理-启停策略管理
脏数据管理: 开启后,系统会自动存储sink到结果表失败的数据,具体原因需要具体分析。如数据格式转化后结果表不支持等原因。
- 内置脏数据记录表建表语句:
CREATE TABLE dirty_data (
job_id varchar(32) NOT NULL COMMENT 'Flink Job Id',
job_name varchar(255) NOT NULL COMMENT 'Flink Job Name',
operator_name varchar(255) NOT NULL COMMENT '出现异常数据的算子名,包含表名',
dirty_data text NOT NULL COMMENT '脏数据的异常数据',
error_message text COMMENT '脏数据中异常原因',
field_name varchar(255) DEFAULT NULL COMMENT '脏数据中异常字段名',
error_type varchar(255) DEFAULT NULL COMMENT '脏数据异常类型',
create_time timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) COMMENT '脏数据出现的时间点',
KEY idx_job_id (job_id),
KEY idx_operator_name (operator_name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='存储脏数据'; - 脏数据最大值:当脏数据达到指定条数时,任务置为失败。
- 失败条数:当脏数据处理失败(如写入脏数据表失败)达到指定次数时,任务置为失败。
- 脏数据保存:
- 不保存脏数据内容,仅输出日志。需要设置脏数据日志打印频率。(该模式不支持在任务运维处对脏数据进行分析)
- 保存脏数据内容至指定MySQL库表。
- 内置脏数据记录表建表语句:
资源组配置: 指定该任务运行的资源组。资源组在【控制台】模块配置。
日志推送:
note日志推送仅支持Flink1.16及以上版本,低于则置灰提示不支持。
- 开启日志推送后,通过编辑logback模版,平台会将任务的日志信息推送至指定Kafka。后续运维人员可以再根据实际需求开发对应的实时任务,达到根据日志内容自定义监控的目的。
- 日志模版中的kafka数据源信息,需要根据实际情况修改成真实可用的连接信息。如果开启kerberos认证,需要上传认证文件。
- 模版克隆:支持从该项目其他已经开启了日志推送的任务处克隆模版,减少logback编辑工作量。
批模式
- 当Source为Iceberg表的时候,FlinkSQL任务支持开启批模式。
- 开启批模式后,同一个任务在执行流式计算的同时,又可按批模式周期执行,不需要开发人员维护两套脚本。所以一般的应用应用场景有两种:
- 在刚创建任务的时候,通过批模式计算历史全量数据,流计算无缝衔接。
- 在流计算过程中,可能会出现数据丢失、数据重复等问题,通过定期的批计算对历史计算结果进行修正。
- 调度设置:目前支持配置任务生效日期和任务执行时间,跑批时执行的均是历史全量数据。(数据范围的限定会在后续迭代中支持)
- 批模式执行的前提是流任务在正常运行。