StreamWorks 5.3.0更新日志
发布时间:2022-12-02
功能新增
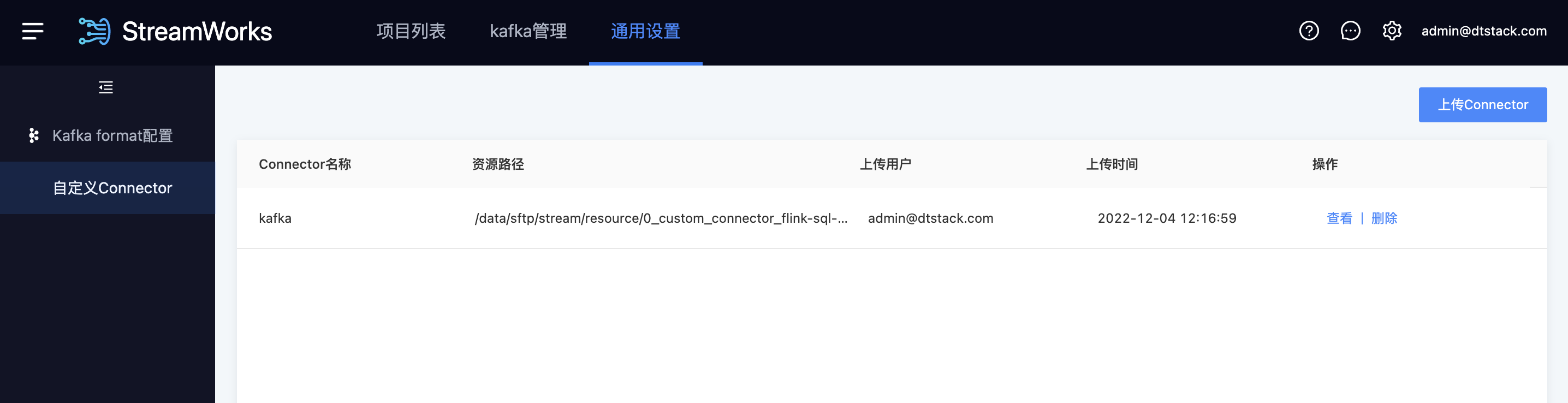
【自定义Connector】支持用户上传第三方数据源插件进行任务开发(仅限脚本模式)【5.2】
背景:随着实时产品客户的增长,各种各样的数据源插件需求不断。我们希望有开发能力的客户,可以不用等产品迭代,自行开发插件去使用产品,使产品能力越来越开放灵活。
功能:对于Chunjun尚未支持的数据源,支持上传【用户自行开发/第三方】的插件包(需符合Flink Connector的开发要求,平台不校验插件的可用性),然后在脚本模式的任务开发中使用。
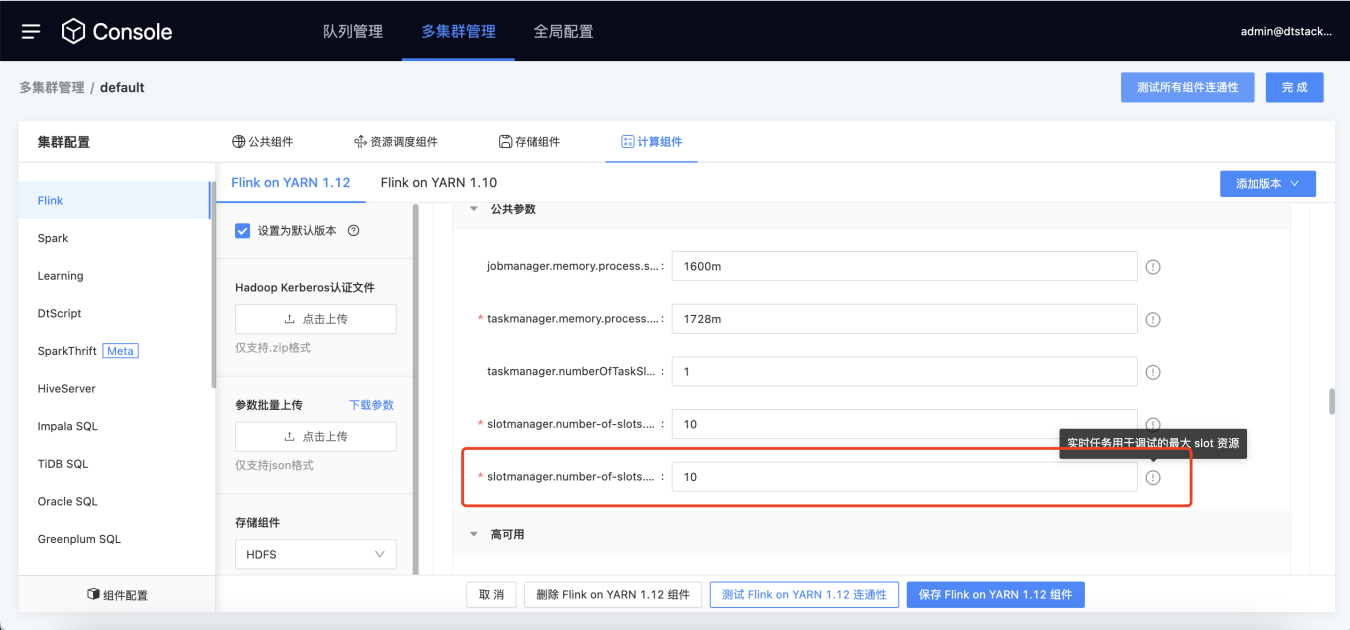
【Session模式】支持已Session模式进行任务调试 【5.3】
背景:之前实时任务的调试功能,和普通任务一样走的per job模式。虽然该模式可以保障任务运行的稳定性,但是整个的提交-申请资源-运行,后端处理流程较长,不符合调试的功能场景(调试不需要持续的稳定性,但是需要快速的出结果)
功能:调试任务默认已session模式运行,提高调试效率。用户需要先在控制台为实时debug分配slot资源。
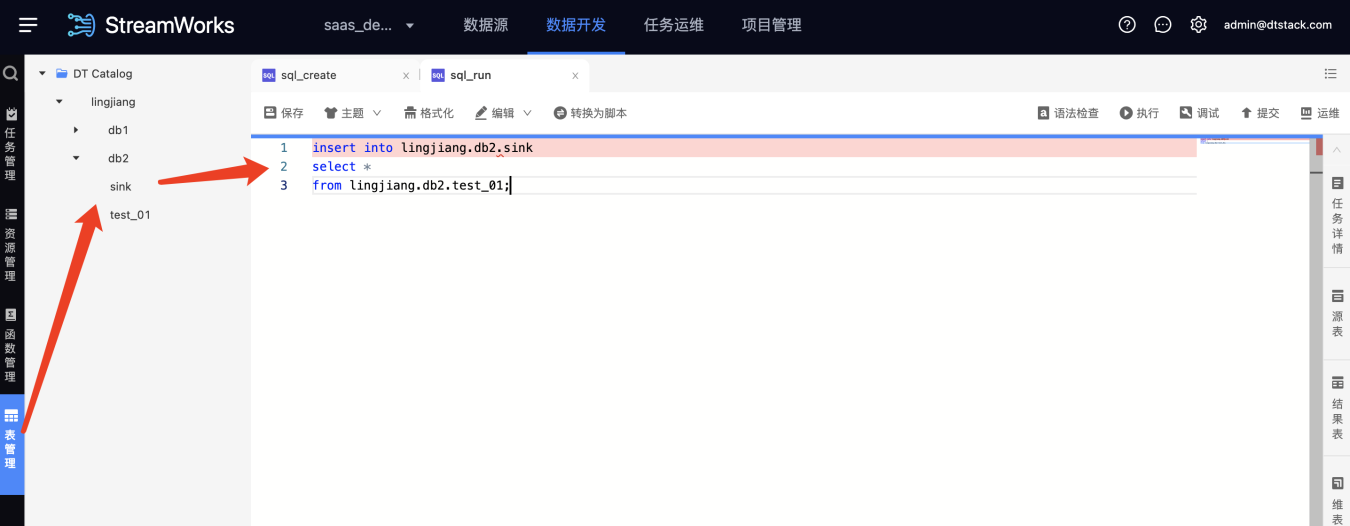
【表管理】表管理模块新增DT Catalog【5.3】
背景:之前每个实时任务的开发,都需要临时映射Flink表,开发效率较低;之前提供的Hive catalog表管理,需要用户维护Hive Metastore,对原Hive有一定的入侵。
功能:提供数栈MySQL作为Flink元数据的存储介质。提供向导和脚本两种模式维护Catalog-database-table。支持在IDE开发页面直接创建、引用Flink库表(需要已Catalog.DB.table的方式引用)。
【数据源】新增GreatDB作为FlinkSQL的维表/结果表【5.3】
【数据源】新增HBase2.x、Phoenix5.x作为FlinkSQL的维表/结果表【5.1】
【Oracle】Oracle sink支持序列管理、新增支持clob/blob长文本数据类型【5.3】
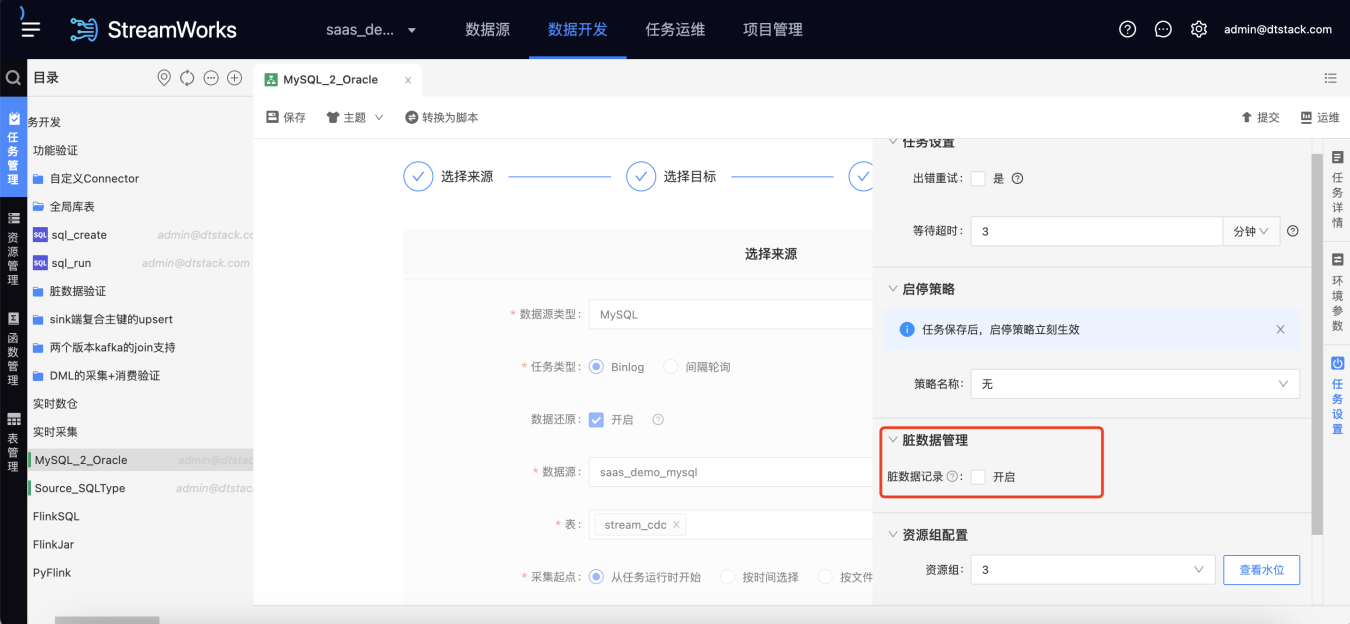
【实时采集】新增脏数据管理【5.3】
功能:实时采集任务支持脏数据管理