StreamWorks 6.0.1更新日志
发布时间:2023-03-03
功能新增
【数据还原】存量数据同步+增量日志还原的一体化任务,支持数据入湖能力【6.0】
背景:数据还原功能新增支持数据入湖(Oracle/MySQL—>Iceberg),该功能可以和数据湖平台配合使用。
功能:创建实时采集任务时,源端配置选择数据还原后,目标端支持选择Iceberg表。

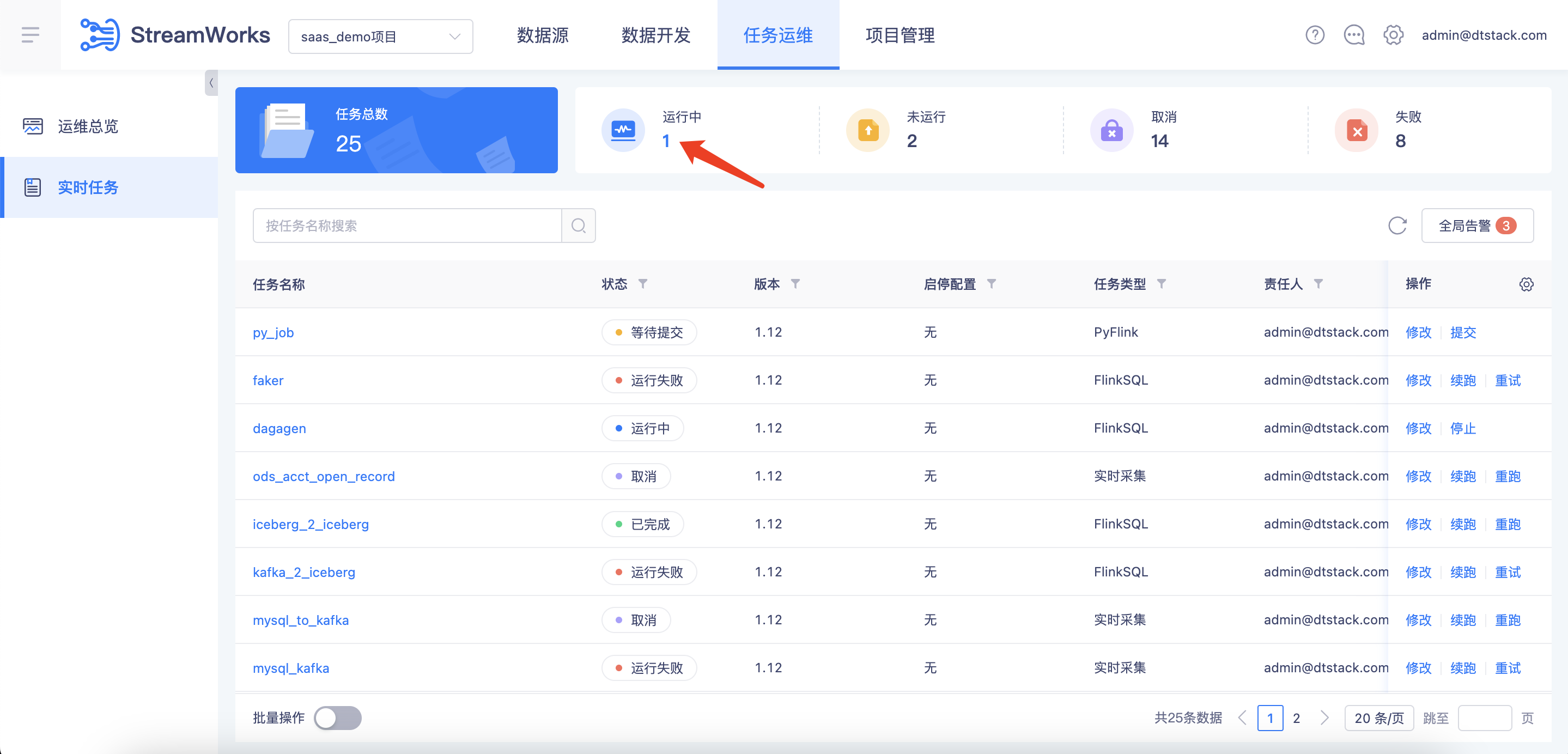
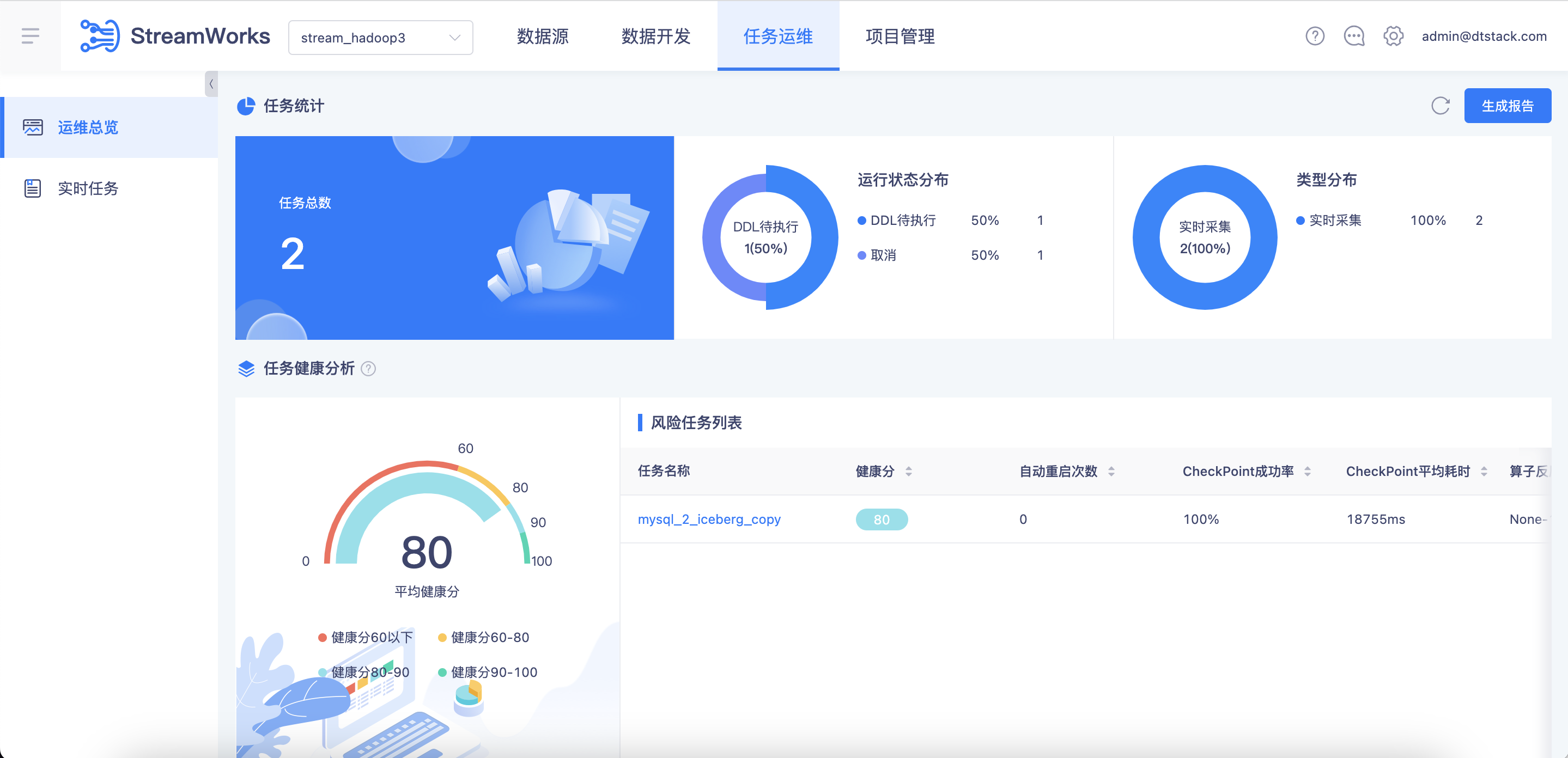
【运维总览】新增运维总览模块【6.0】
背景:之前实时平台的运维都是针对单任务的,缺乏全局性的运维统计和分析能力。并且缺乏对运行中任务的监控分析,因为实时任务一旦运行失败,就会立即对线上数据服务产生影响,我们希望能在任务失败之前,就能发现各种潜在风险。
功能:新增【运维总览】菜单,支持统计项目任务总数、状态分布、类型分布;通过健康分模型,对每个运行中的任务进行健康评分。
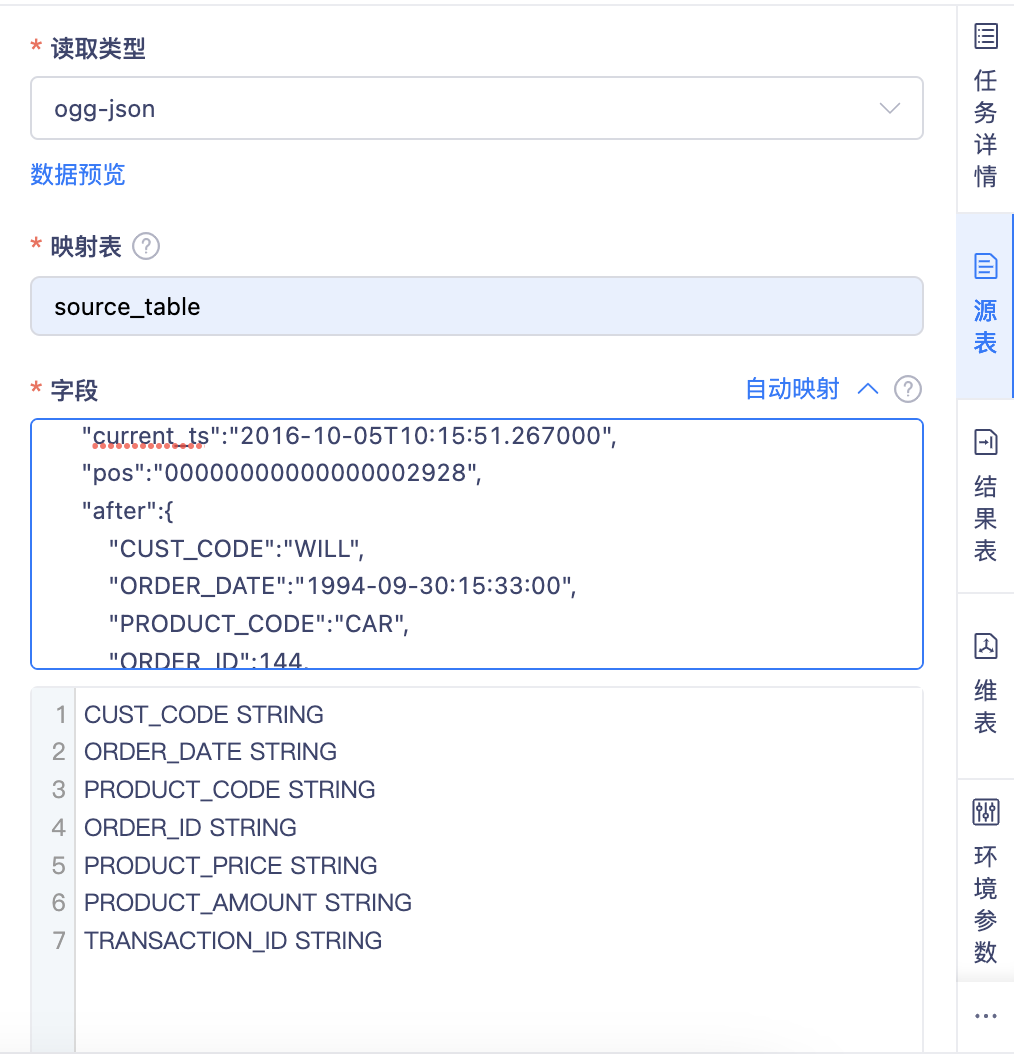
【Topic自动映射】FlinkSQL开发,针对OGG-JSON格式的Kafka Topic,支持一键自动映射FlinkTable【5.3】
背景:之前实时平台的FlinkSQL任务开发,对于Kafka Topic的映射操作非常麻烦,需要用户查询JSON中的每个KEY,配置成Flink表的字段,如果需要做上百个字段的映射,也需要人肉操作。开发往往选择在应用外想办法完成批量映射,再粘贴到平台内,交互比较差。
功能:Kafka Format新增OGG-JSON,支持对这类JSON数据实现一键映射:
一键采集线上样例数据,自动完成映射
手动输入样例数据,一键完成映射
note要实现自动映射,前提是后端需要根据固定的模版解析JSON格式。而每类采集工具的JSON格式都有差异,所以需要新增不同的Format去实现该功能。后续我们会陆续新增其他采集工具的JSON格式。
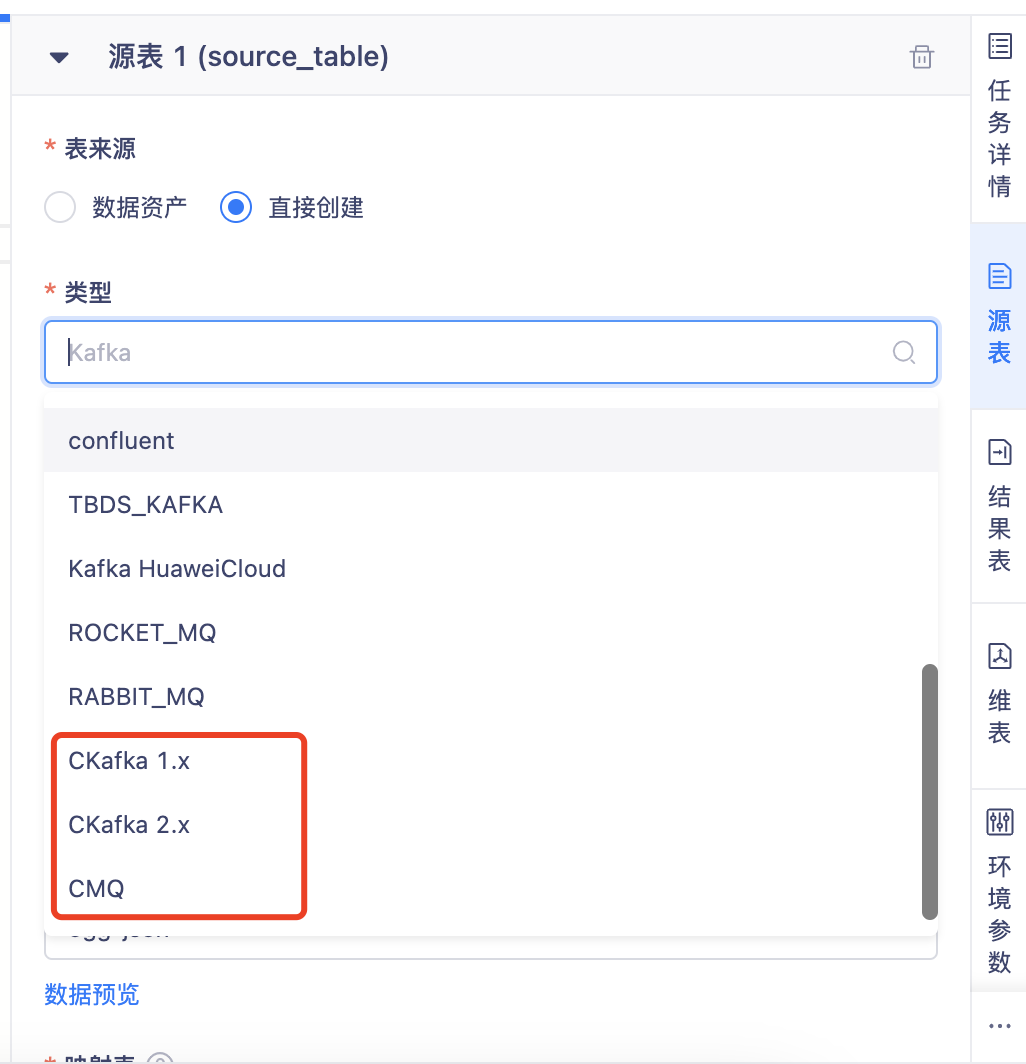
【数据源】新增Ckafka、CMQ数据源【6.0】
功能:FlinkSQL 的源表、结果表新增支持Ckafka、CMQ数据源类型(数栈6.0+Flink1.12)
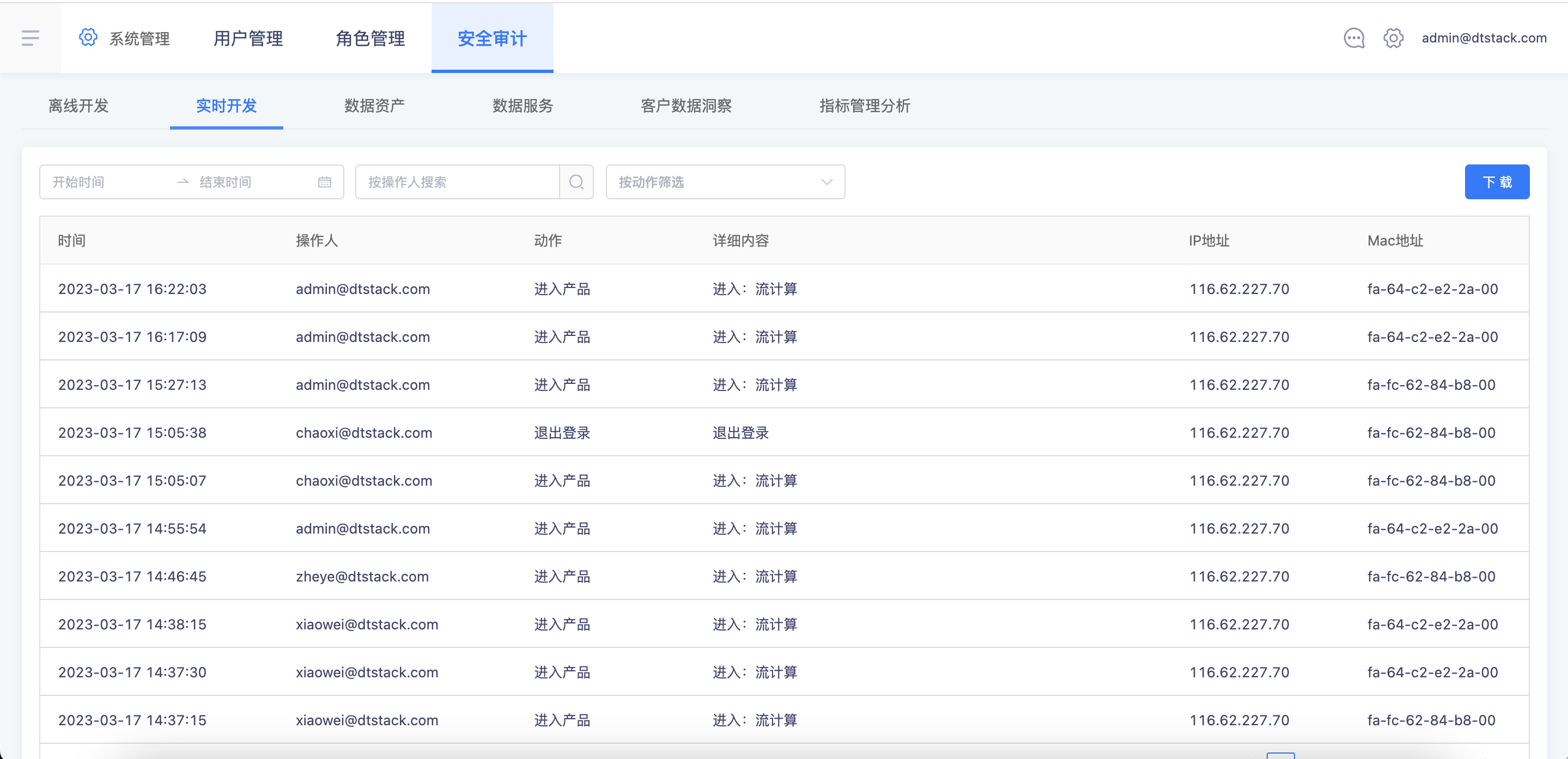
【日志审计】实时平台的操作记录新增IP/MAC信息【5.3】
功能:平台操作记录新增IP、MAC信息,并且支持导出。
功能优化
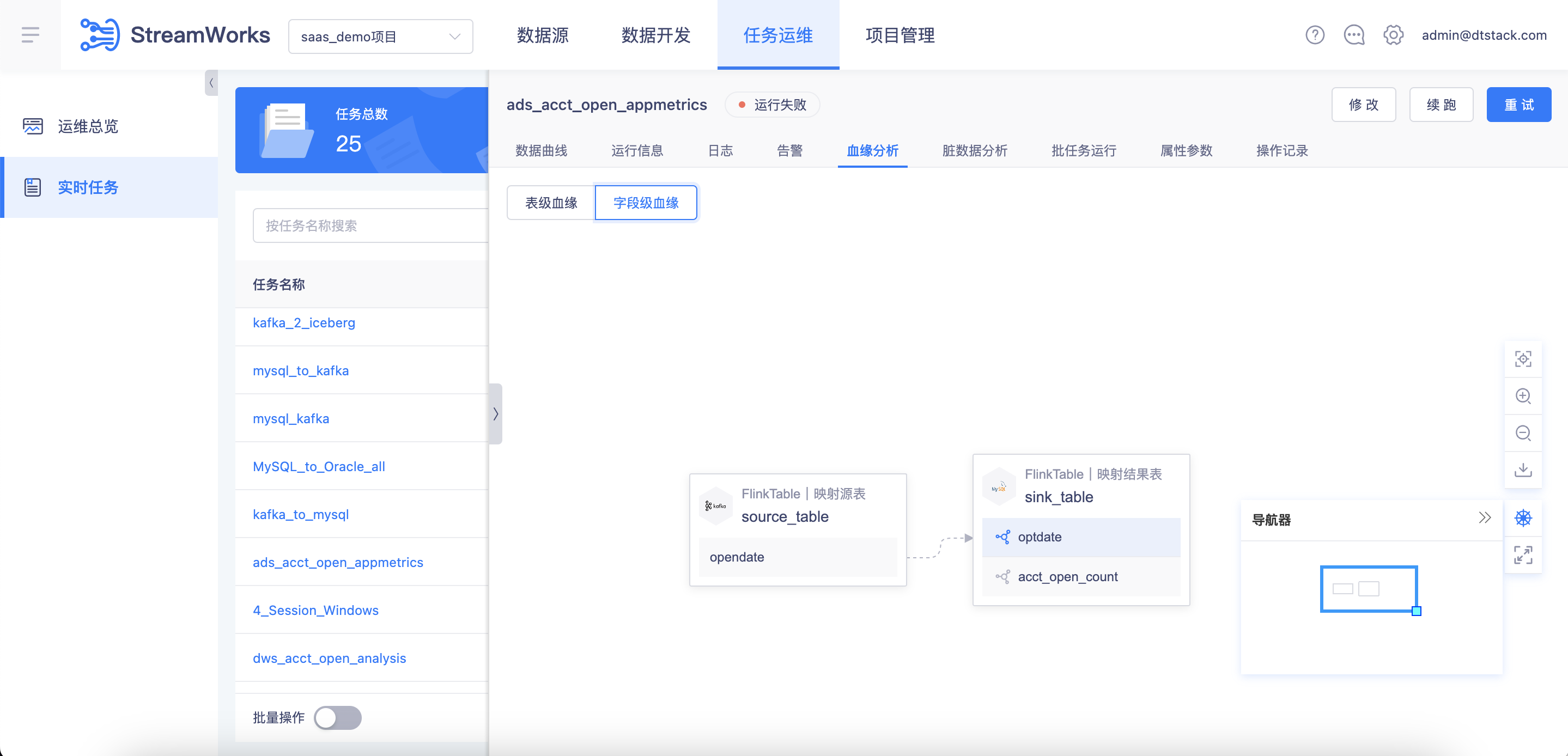
【血缘解析】支持基于FlinkSQL的字段级血缘解析,并支持上下钻【5.3】
背景:之前实时平台的字段级血缘解析只支持根据当前任务的FlinkSQL去解析,没有进行上下游串联。用户无法回溯或者下钻上下游关联字段。
功能:字段级血缘支持上下钻查询。使用限制:建议配合表级血缘一起分析,因为字段级血缘是纯SQL解析,不携带任务信息
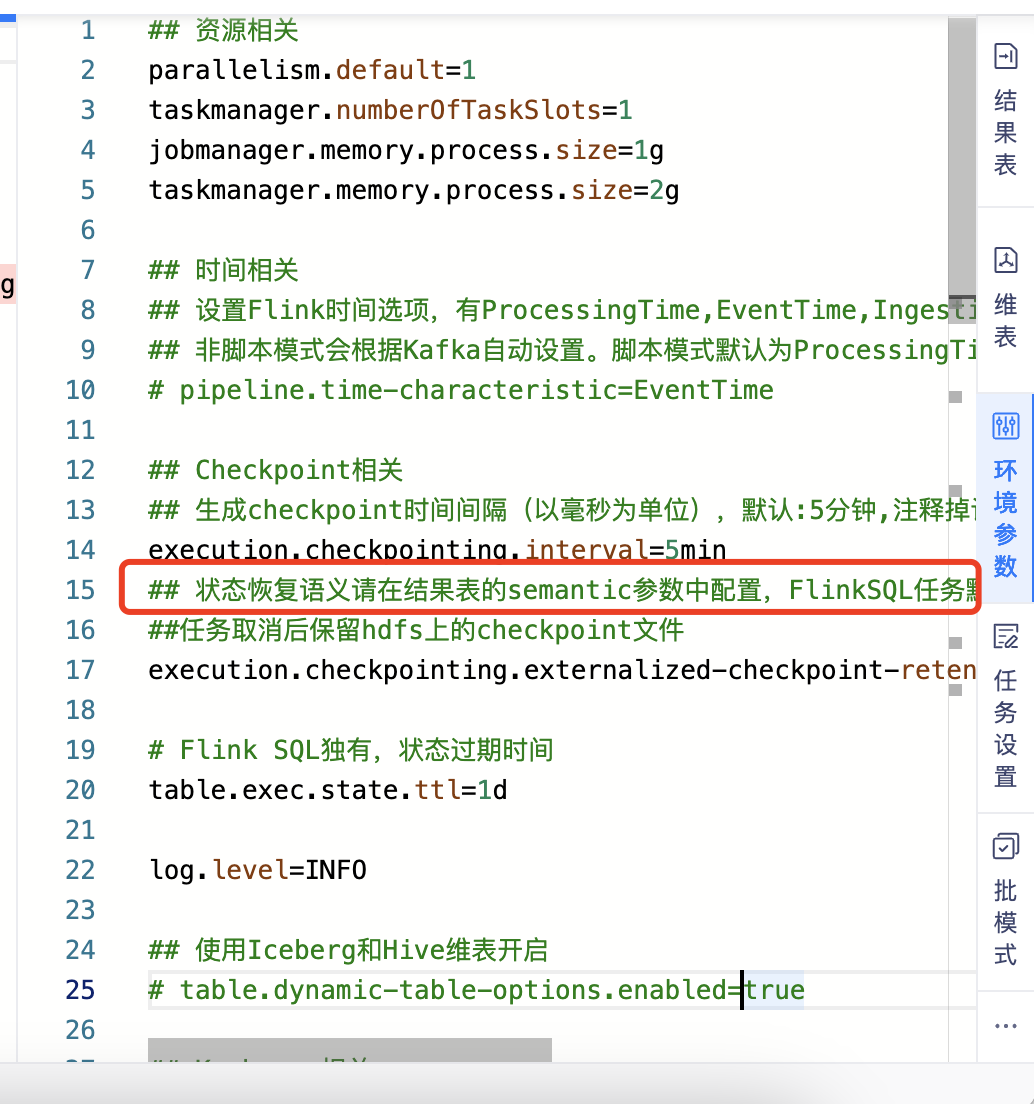
【CheckPoint】优化任务环境参数配置中关于状态恢复语义的说明【5.3】
- 背景:之前实时任务的Checkpoint恢复语义是放在环境参数中配置的(和开源Flink相同),但实际并不生效。因为我们Flink的实现是基于开源改造过的,状态恢复语义需要在任务的结果表中进行semantic参数配置。
- 功能:调整环境参数中的状态恢复语义提示文案,引导开发至结果表参数中配置。FlinkSQL任务默认为at-least-once(保障实时性)、数据还原任务默认为exactly-once(保障准确性)
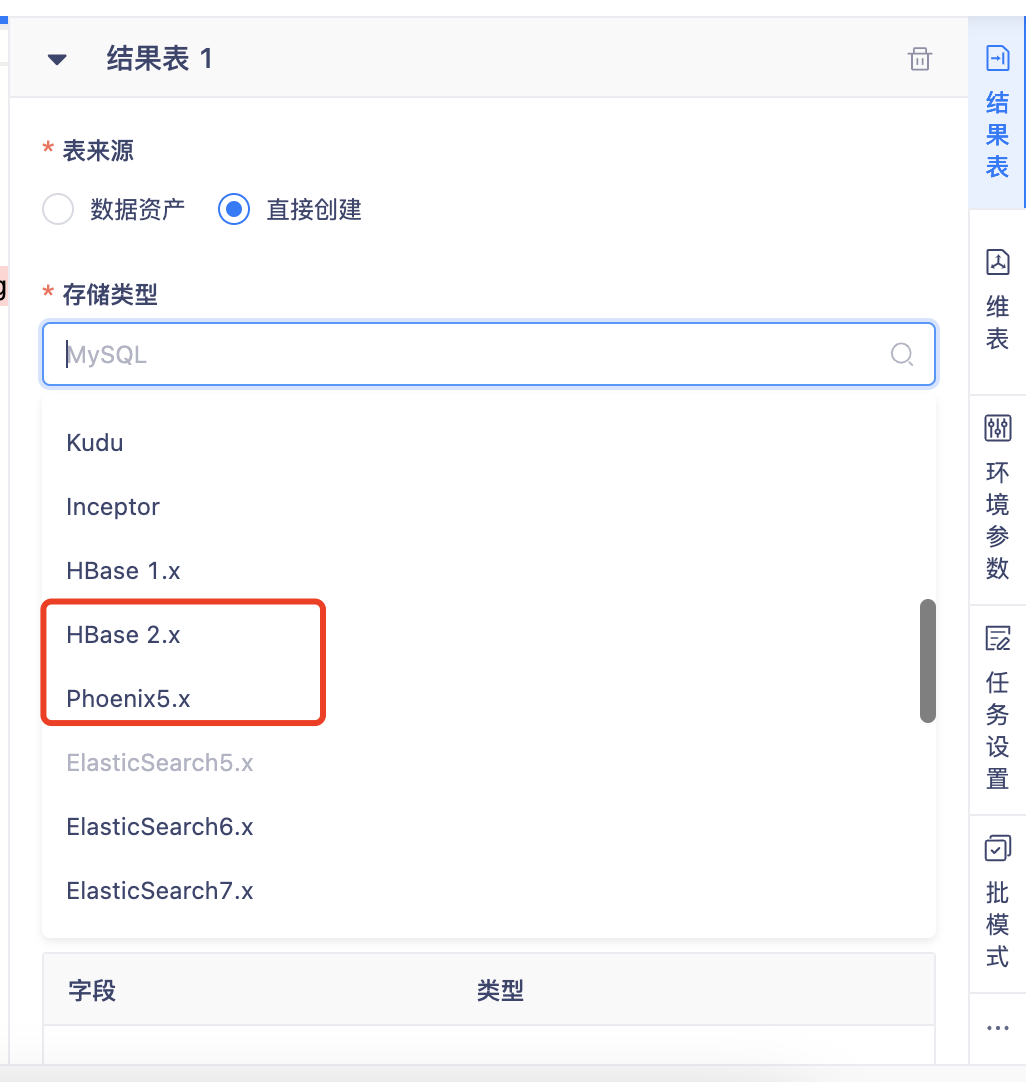
【插件适配】Flink1.12适配HBase2.x Sink、Phoenix5.x Sink【6.0】
功能:之前在Flink1.10中已经支持的HBase2.x和Phoenix5.x插件,在Flink1.12中进行适配
【任务运维】实时任务列表UI5.0改造,支持状态快速筛选【5.3】
功能:实时任务列表进行UI5.0升级,并且支持点击「任务状态统计」进行快速过滤筛选