常见问题
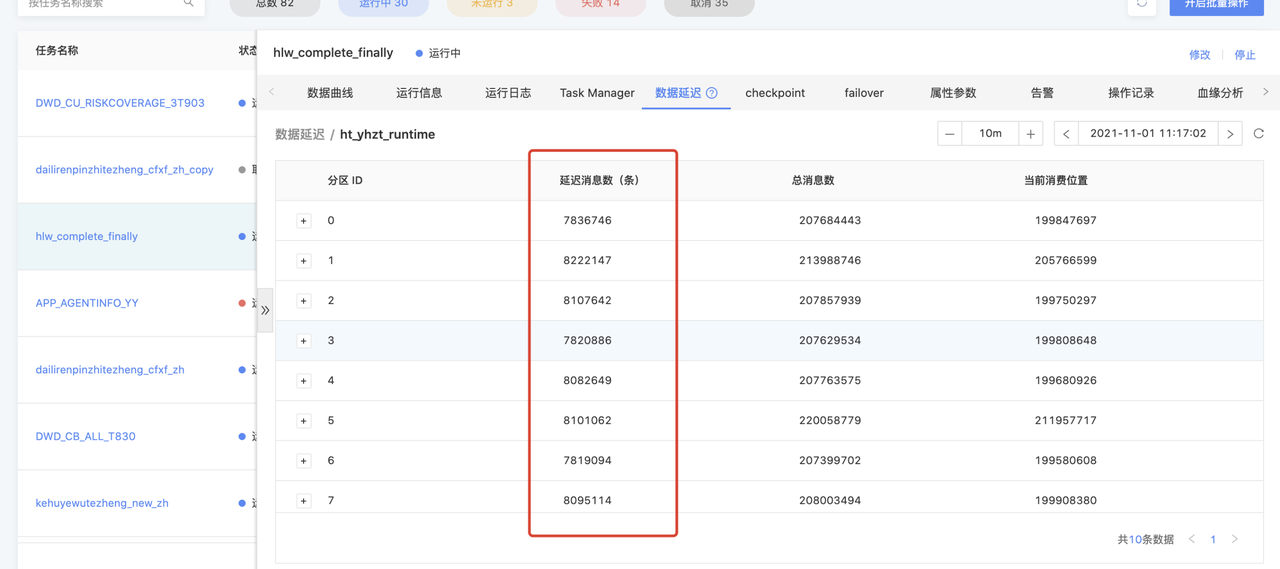
数据延迟量过大导致算子反压
- 问题详情
- 产生原因
下游数据的处理速度跟不上上游数据的产生速度,会导致数据延迟和反压
- 解决方案
- 在运行信息-Vertex拓扑中确定是哪个阶段产生的数据反压
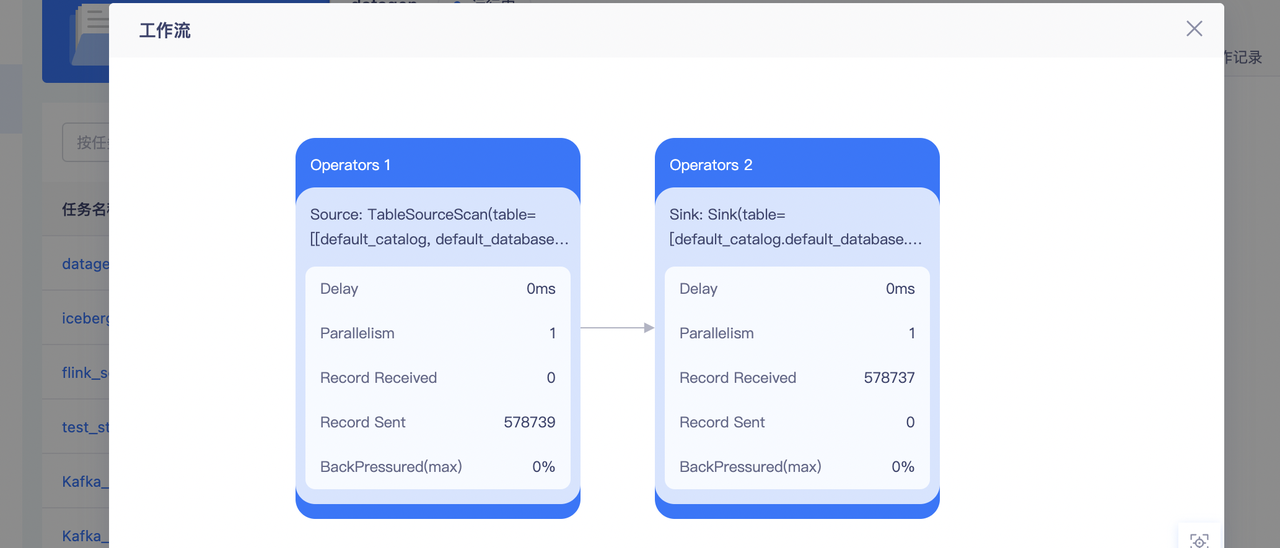
- 在任务开发中调高产生反压表相对应的并行度,具体可根据反压情况选择调大的数量
配置告警方式为邮箱但却接收不到邮件
- 问题原因
平台获取的邮箱是用户中心的「邮箱」,而创建账户时邮箱是空的
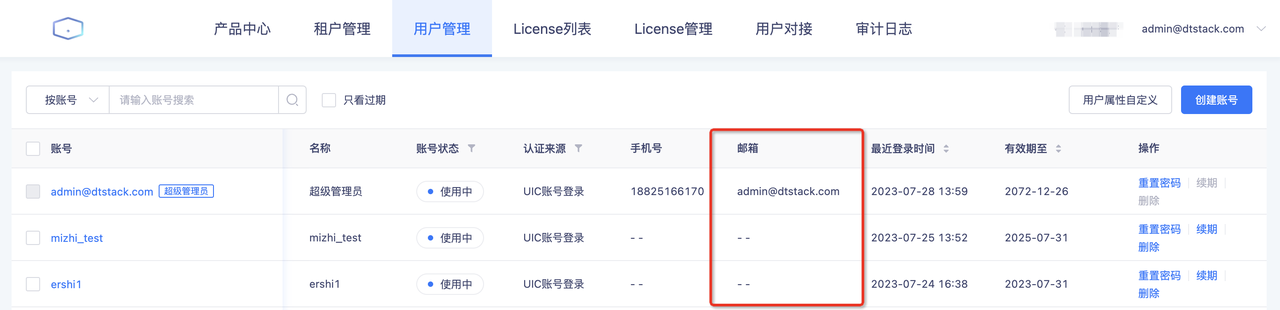
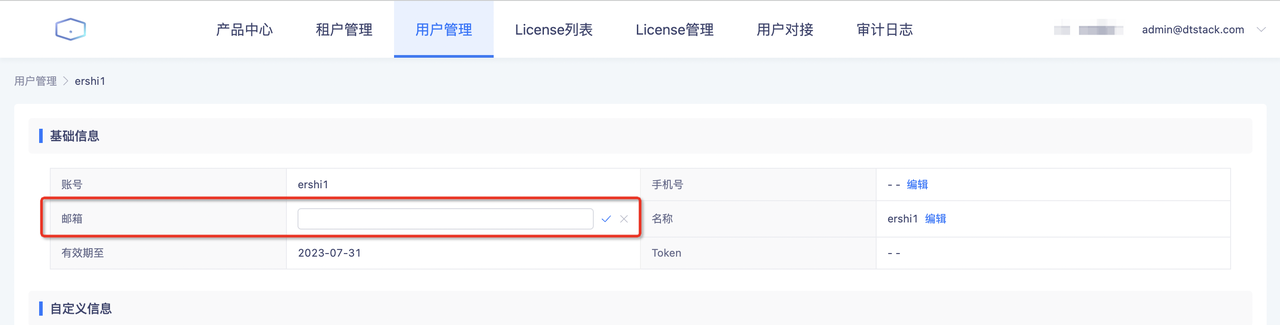
- 解决方案
在没接收到告警邮件的平台账号填写邮箱地址
FlinkSQL任务在结果表中查不到实时数据
- 报错原因
在任务开发中修改引擎版本后,任务的环境参数没有做相应更改,导致参数配置不生效
- 解决方案
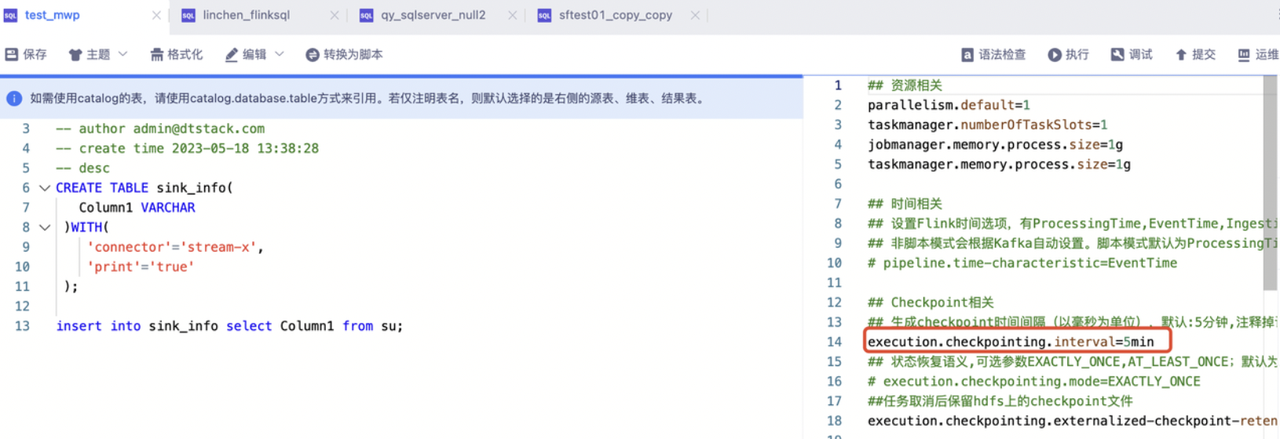
根据引擎的不同版本修改checkpoint相对应的参数
flink1.10:flink.checkpoint.interval=300000
flink1.12/flink1.16:execution.checkpointing.interval=5min
如何定位数据丢失的问题
- 排查数据丢失的位置
在结果表中查看是否有该数据,若没有则确认在写入结果表前丢失
(下面以丢失了id值为1的数据为例子)
select * from sink_table where id=1;
- 在kafka数据中查看数据是否存在
- 不存在:说明没有采集到该数据,需要排查上游采集任务
- 存在:可能业务逻辑出现问题,进行下一步排查
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning
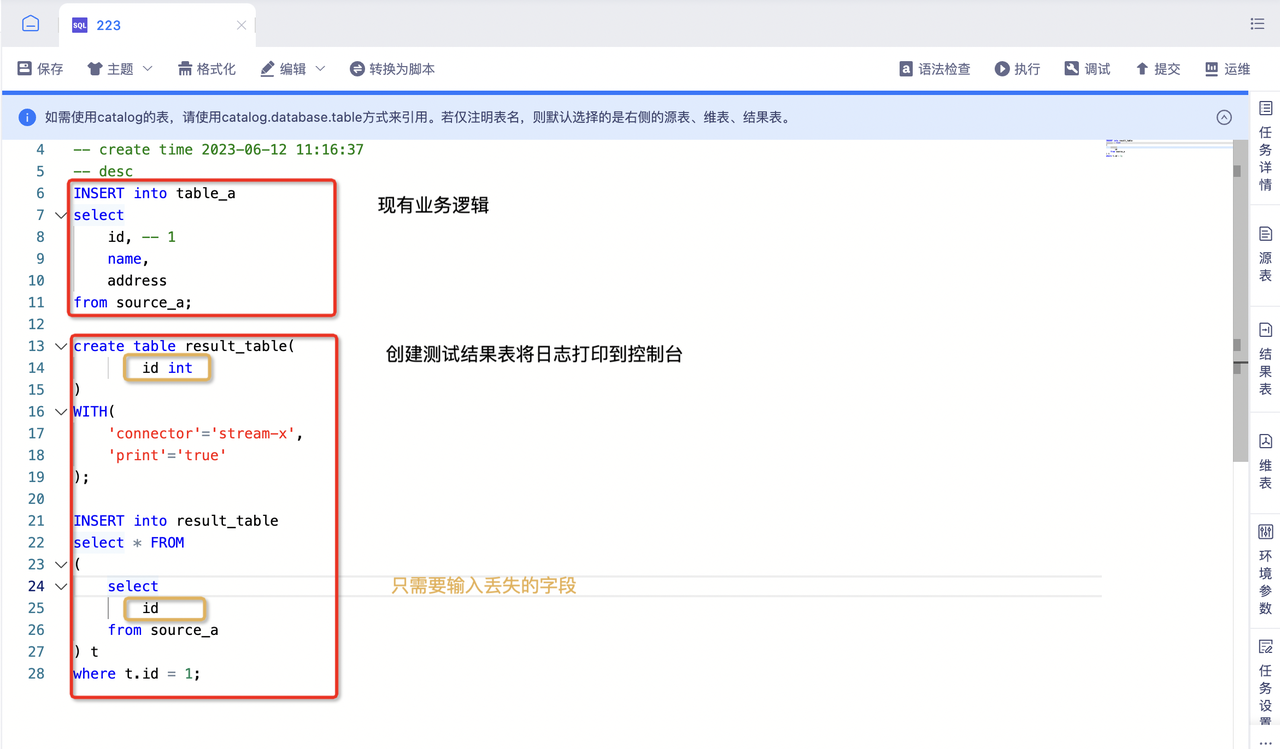
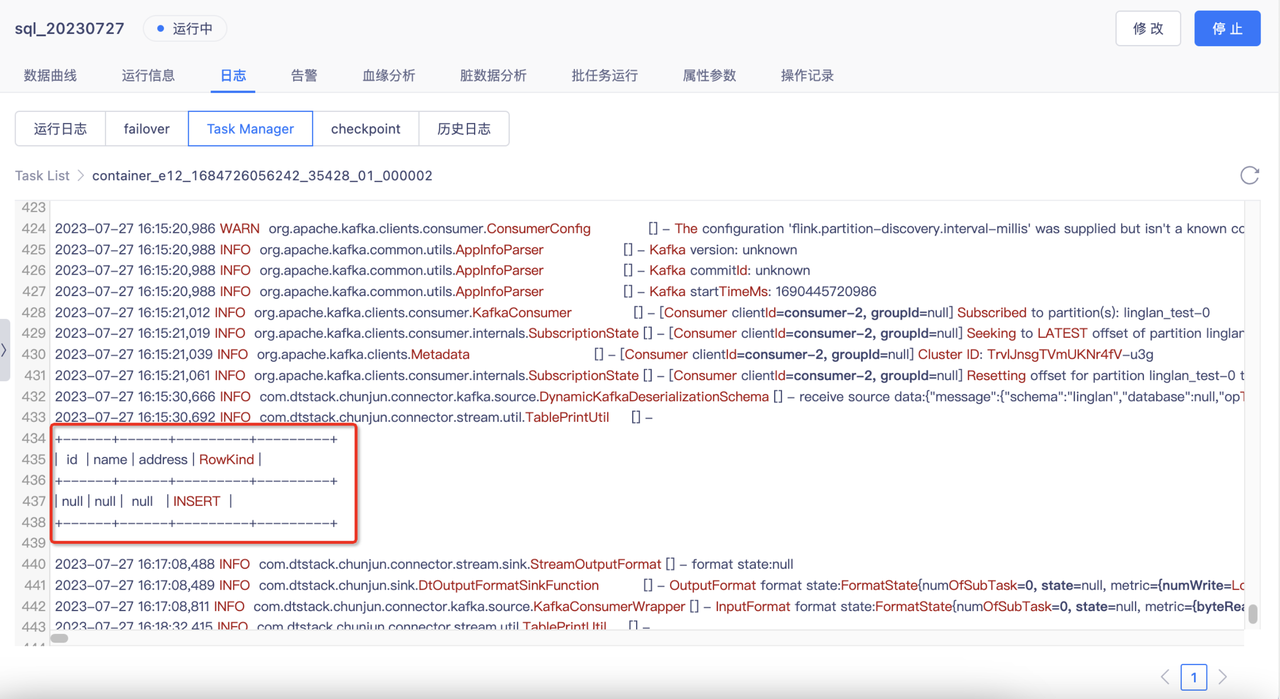
- 复制任务,模仿图中示例在现有业务逻辑下创建一个新的结果表,字段类型为丢失数据的类型。提交任务,在日志中查看是否有该数据(下图中为没有该数据),若不存在则说明SQL的业务逻辑有问题,需要检查SQL,如果存在则说明flink写入失败,需要找技术人员支持。
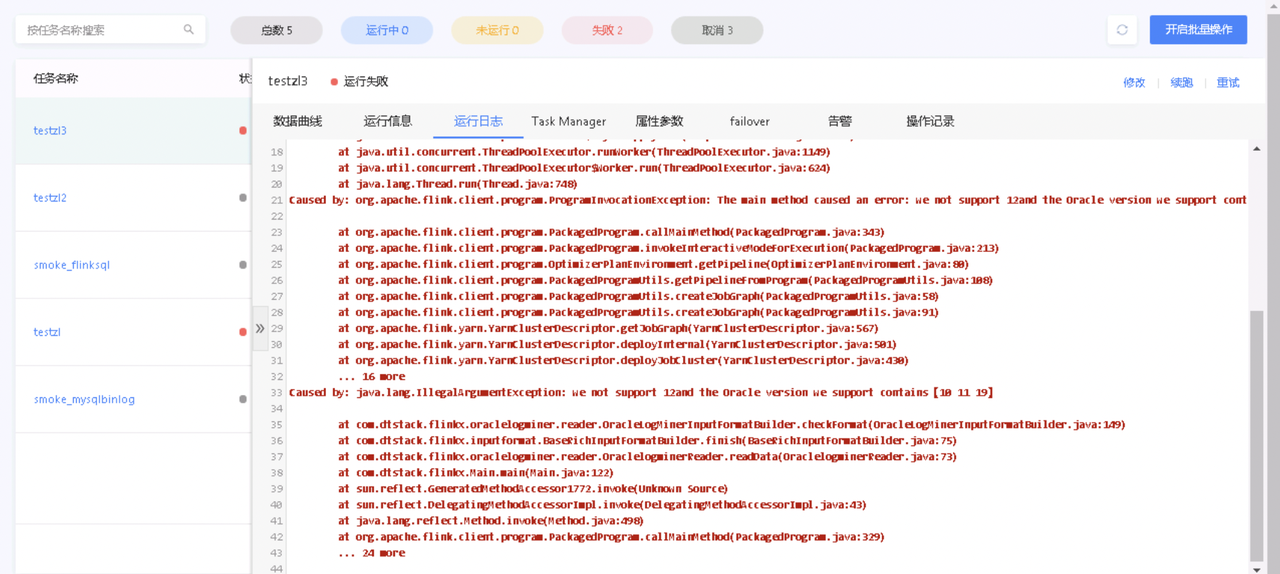
实时采集报错:we not support 12and the oracle version we support contains
- 报错详情
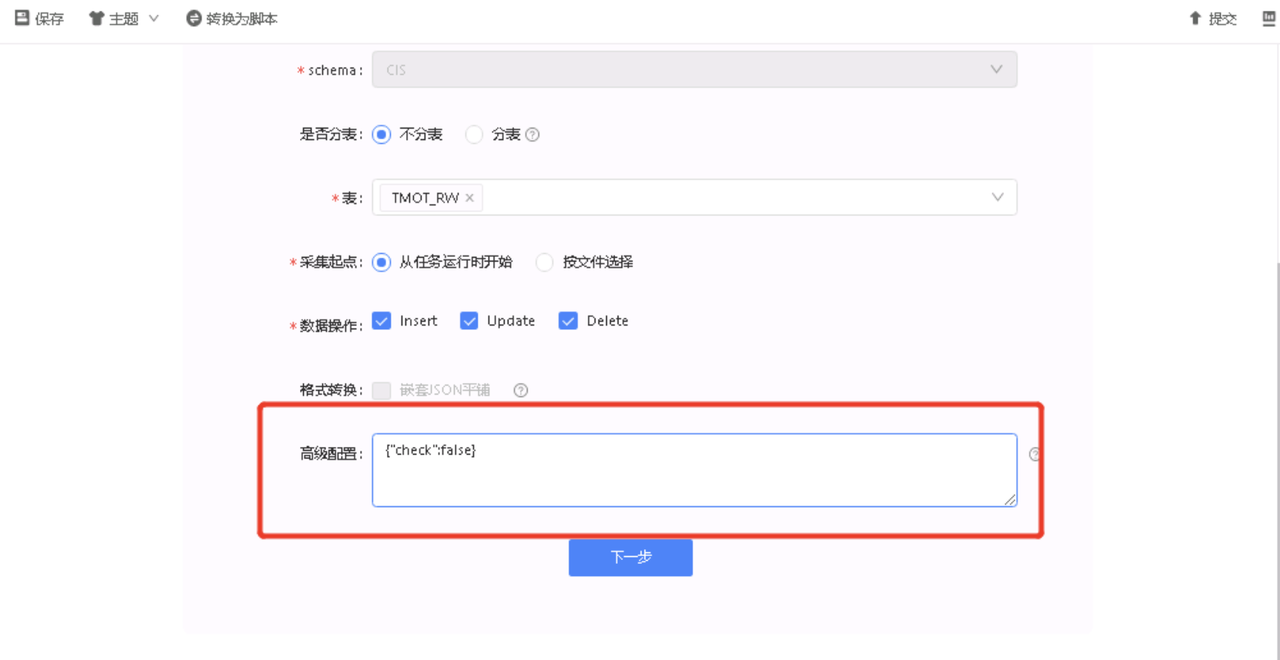
- 解决方案
在高级配置中加上{"check":false}
实时采集报错:No serviceName defined in either JAAS or Kafka config
- 报错详情
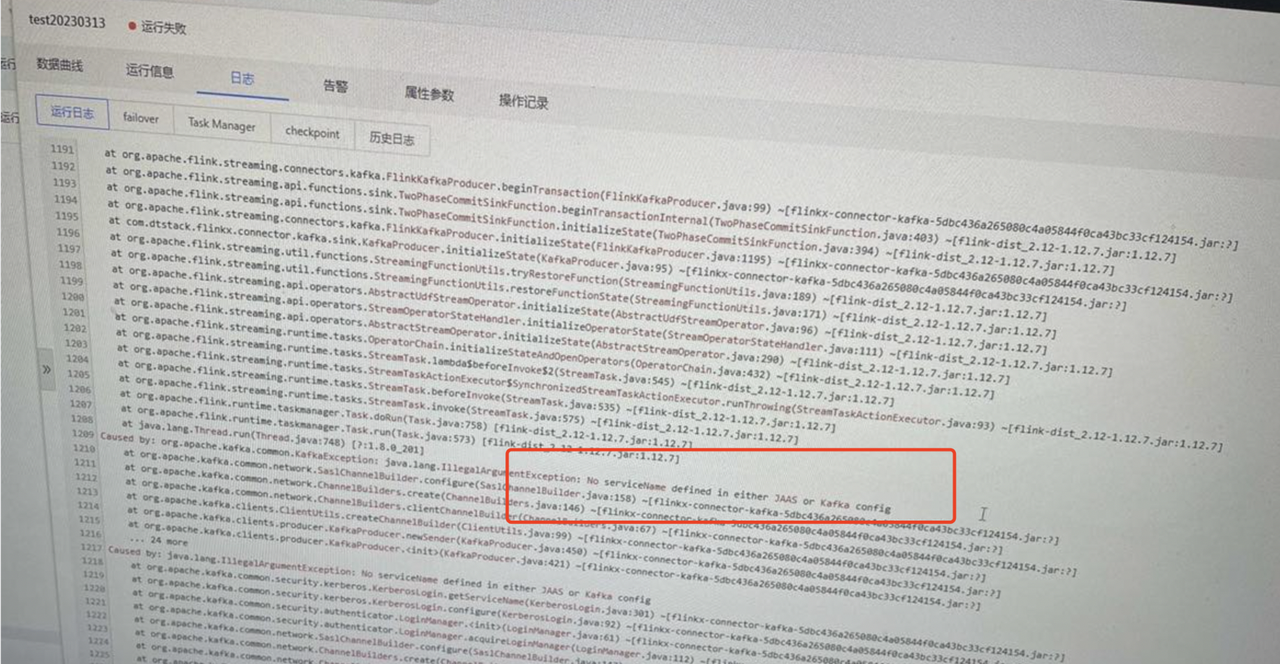
- 报错原因
客户端开启了kerberos认证
- 解决方案
- 如果Kafka zookeeper开启了kerberos,在环境参数中配置:security.kerberos.login.contexts: KafkaClient
- 如果kafka开启了kerberos,在环境参数中配置:security.kerberos.login.contexts=Client,KafkaClient
FlinkSQL报错:java.lang.stackOverflowError
- 报错详情
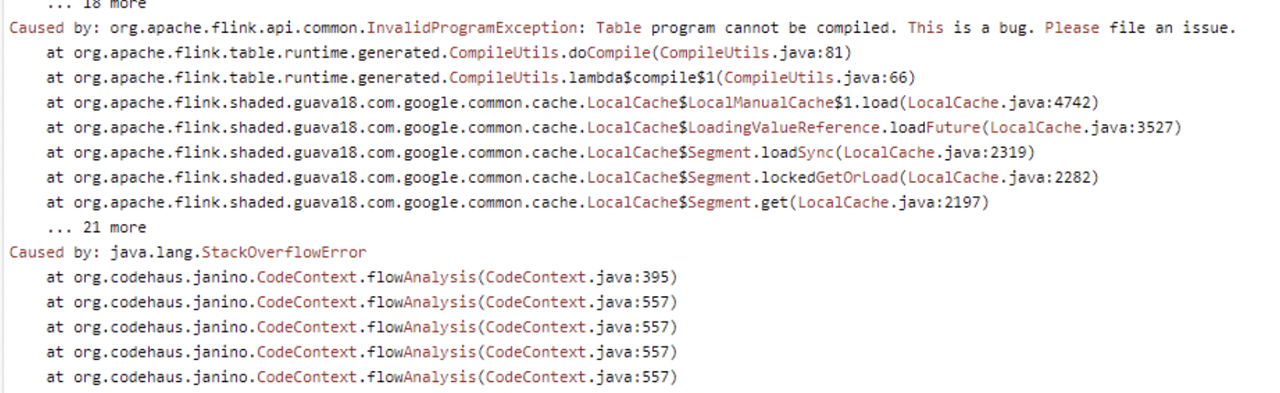
- 报错原因
SQL中大量字段使用了多个函数进行处理,导致任务正常接收数据,但无法写入结果表
- 解决方案
在环境参数中配置:env.java.opts.taskmanager:-Dfile.encoding=UTF-8 -XX:MaxMetaspaceSize=300m -Xss2m
FlinkSQL报错:java.lang.OutOfMemoryError:GCoverheadlimitexceeded
- 报错原因
由于堆太小,没有足够的内存才导致异常。
- 解决方案
- 查看系统是否有使用大内存的代码或死循环;
- 通过添加JVM配置,来限制使用内存。在环境参数中配置:env.java.opts.taskmanager:-Dfile.encoding=UTF-8 -XX:-UseGCOverheadLimit
FlinkSQL报错:Exceeded checkpoint tolerable failure threshold
- 报错详情
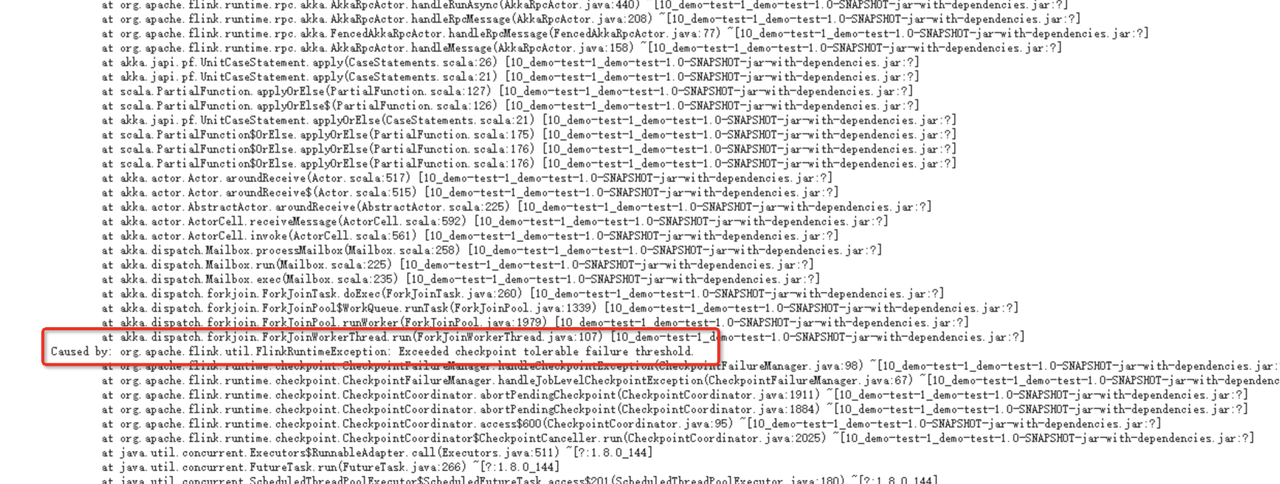
- 报错原因
由于网络等原因,checkpoint在保存时执行失败
- 解决方案
在环境参数中新增tolerableCheckpointFailureNumber=3,将连续失败的checkpoint最大可容忍数设为3
FlinkSQL报错:create downloader exception, File /tmp/logs/hdfs/logs/application_xxx does not exist
- 报错详情
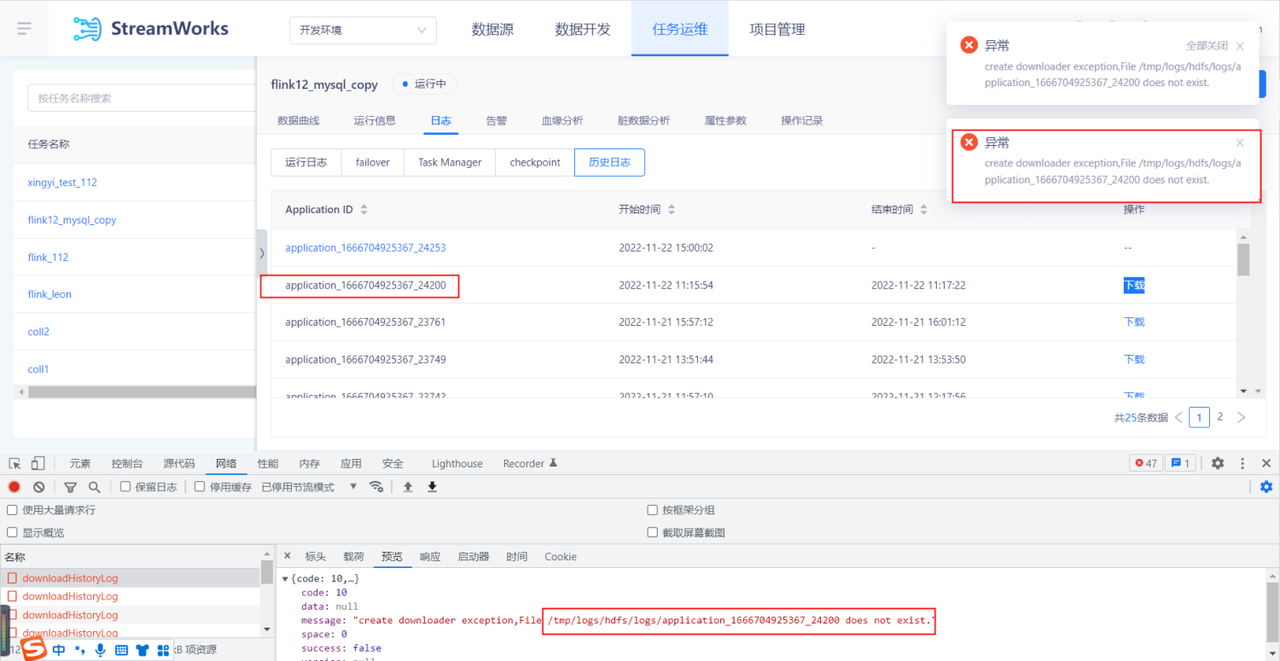
- 报错原因
yarn和控制台执行的用户名不同,导致报错路径和日志真正存的路径不一致
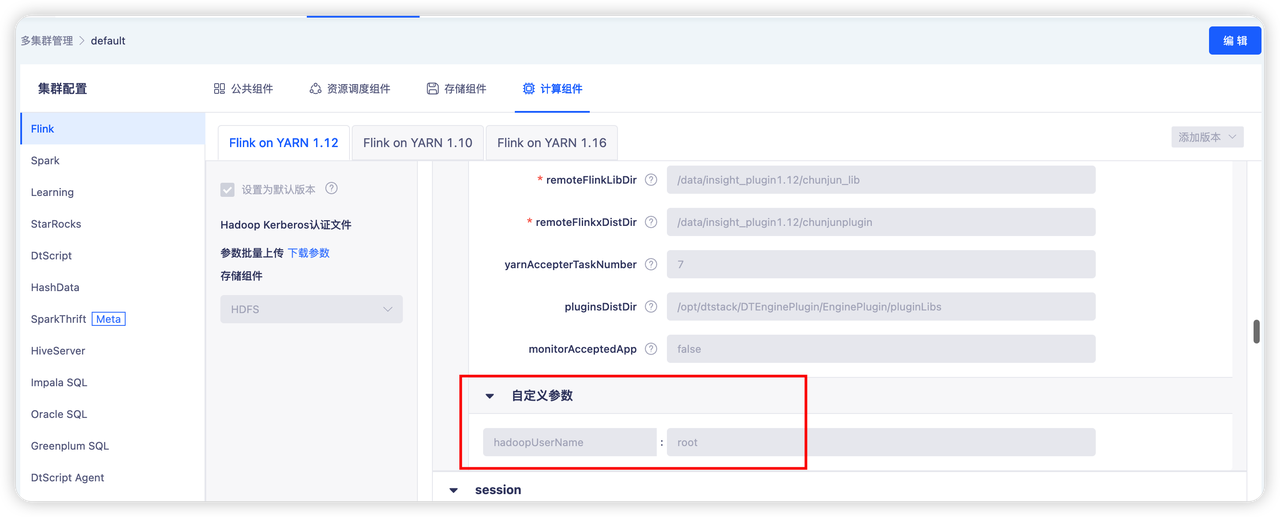
- 解决方案
在控制台配置“hadoopUserName:root”参数
FlinkSQL报错:The sink for table default catalog.default database.httpCollectSink' has a configured parallelism of while the input parallelism is -1. Since the configured parallelism is different from the input's parallelism and the changelog mode is not insert-only, a primary Key is reguired but could not be found.
- 报错详情
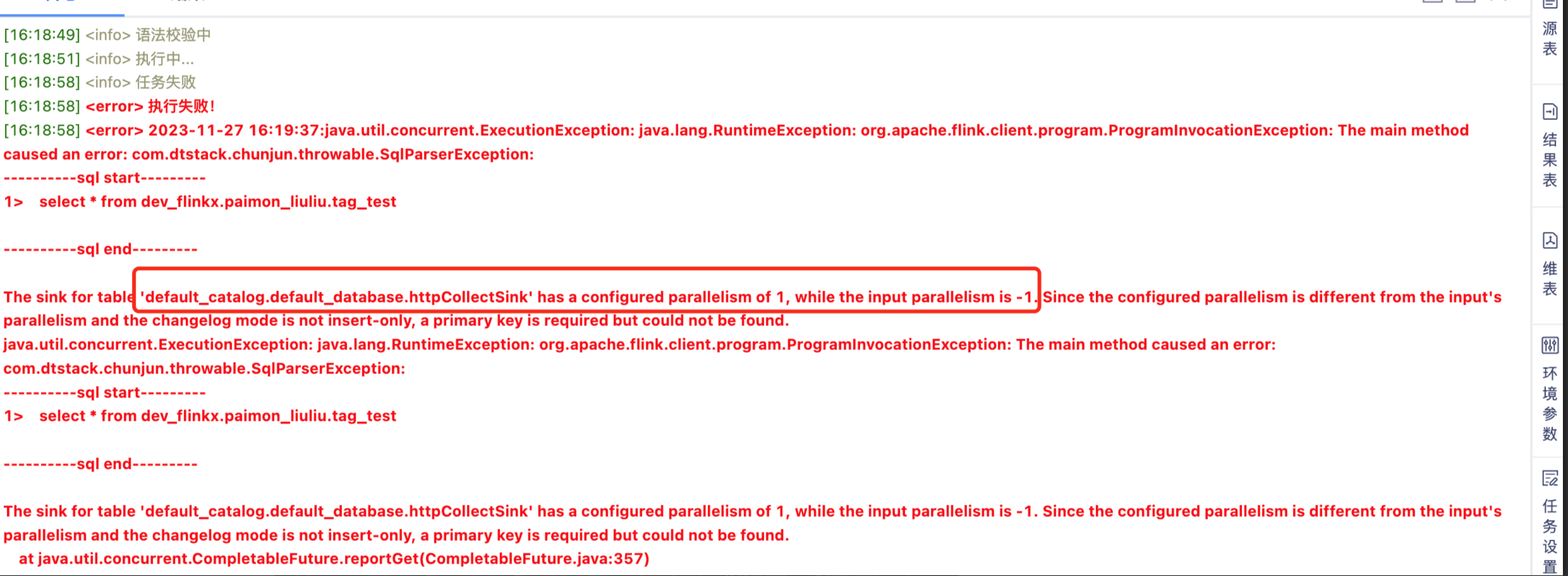
- 报错原因
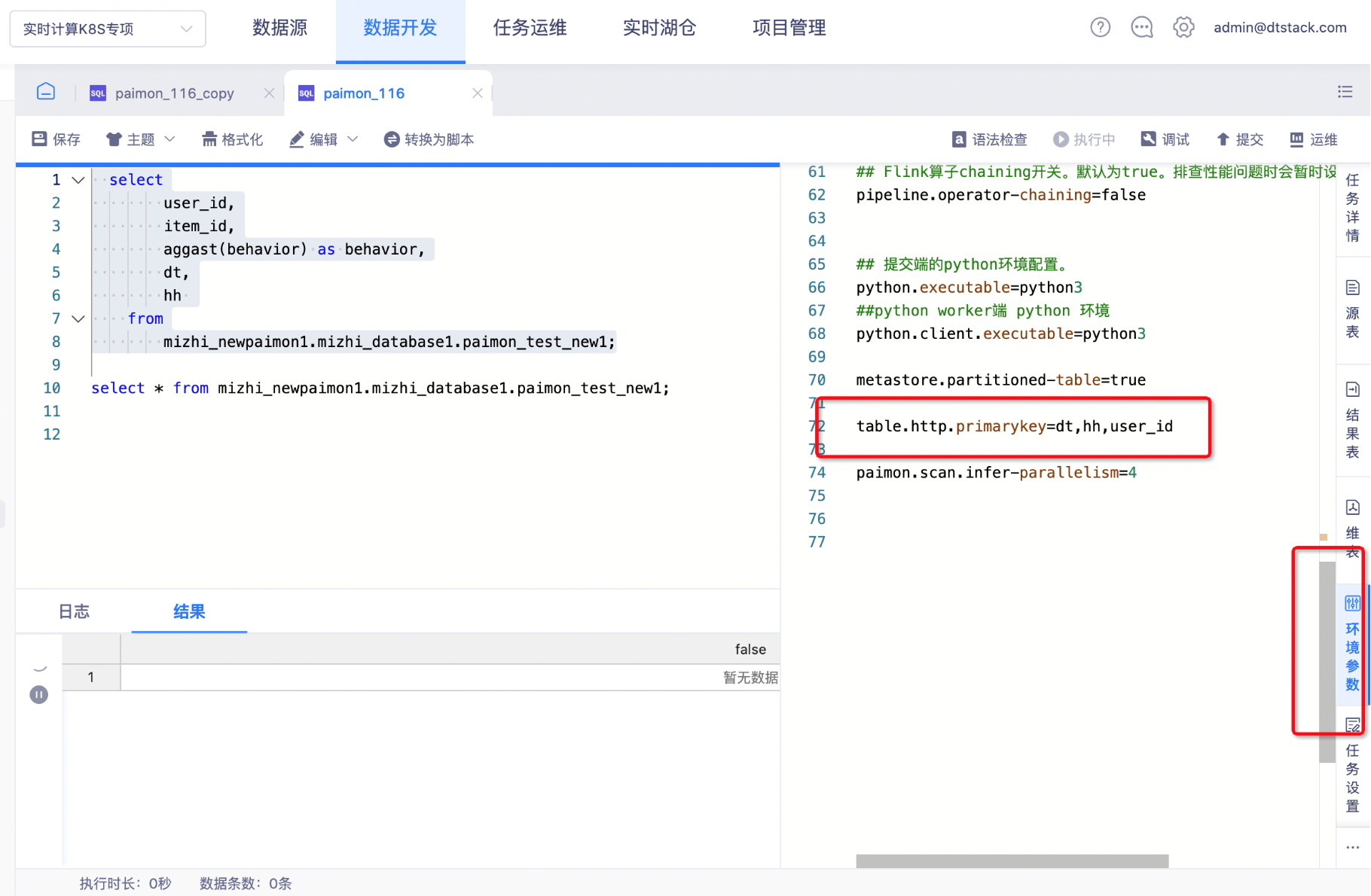
paimon在建表中指定了主键,但在运行SQL Query时未再环境参数添加主键配置导致报错
- 解决方案
想要使用sqlquery功能的话,就需要在环境参数中加上参数table.http.primarykey=xxx,需要自行拼接主键,多个主键用逗号分割即可
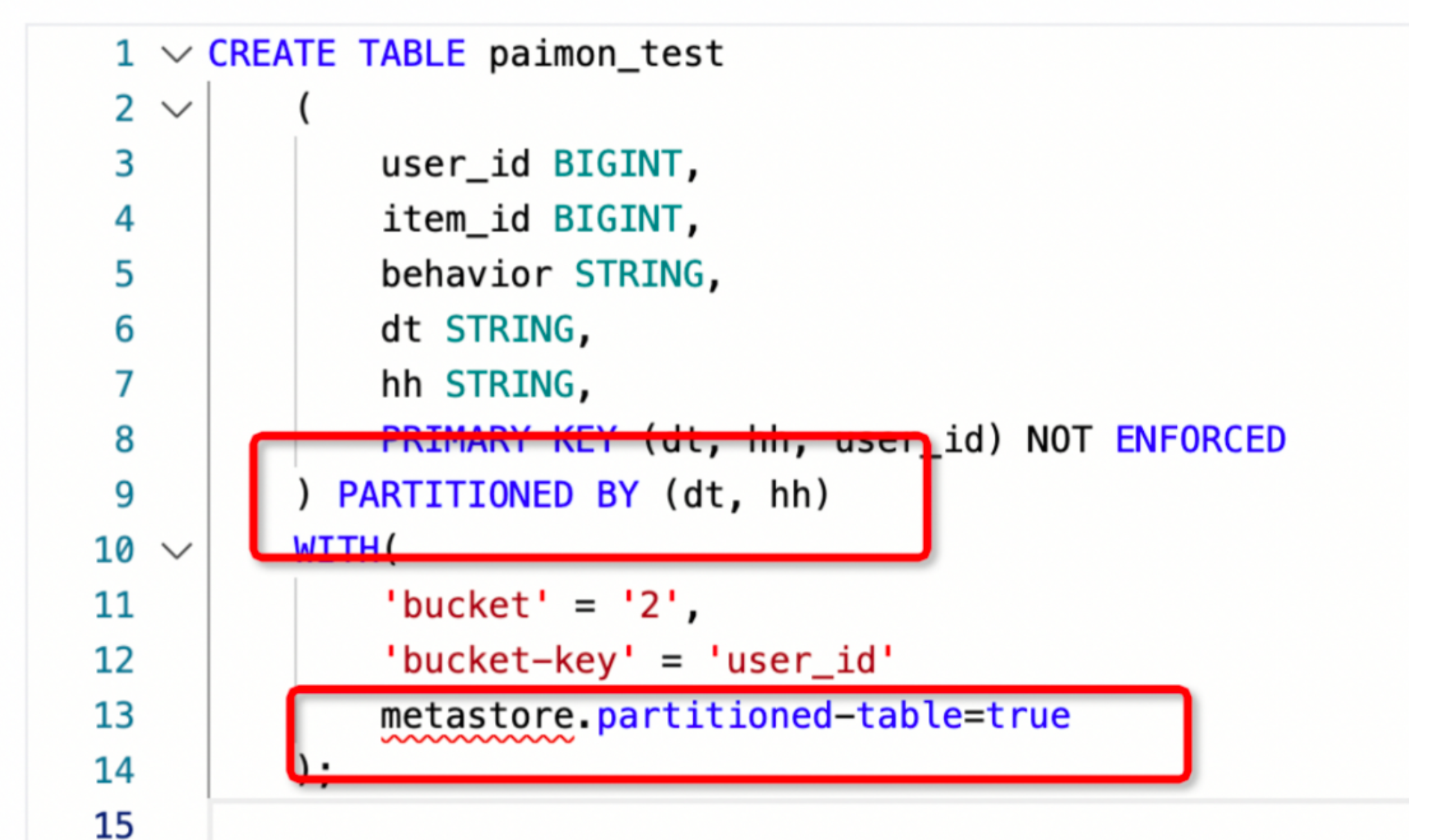
FlinkSQL报错:Caused by: org.apache.flink.table.api.TableException: Table not exists!
- 报错详情
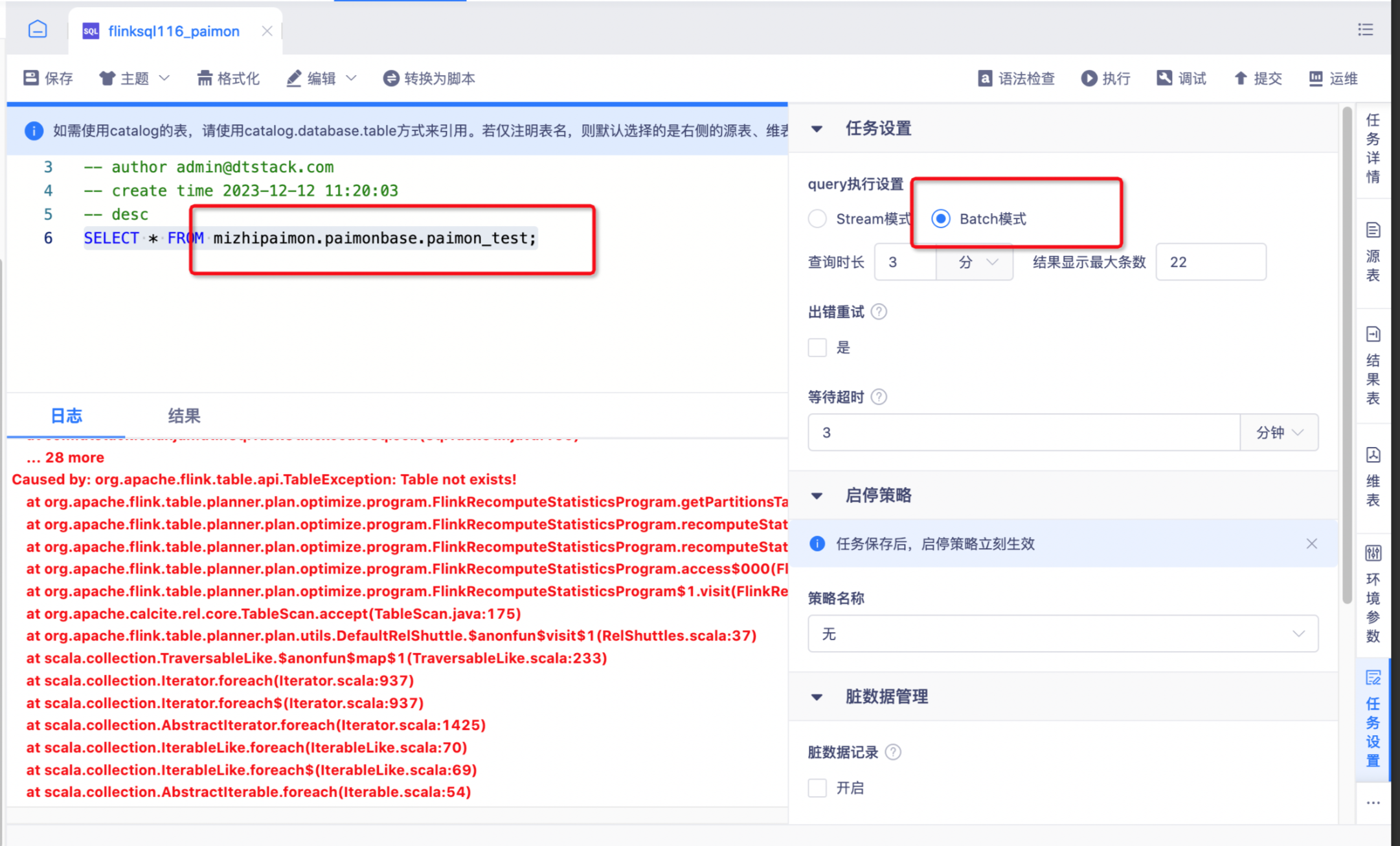
- 报错原因
paimon分区表 但在运行SQL Query时 batch读取报错,需要在建表时设置分区参数
- 解决方案
如果想解决这个问题,只需要在paimon的表属性中设置 metastore.partitioned-table=true 即可