运维总览
从项目全局维度,统计分析当前实时任务的整体情况。页面所有统计指标,每分钟计算一次。
该功能专业版、旗舰版支持
任务统计
- 任务总数:统计所有提交到「任务运维」的任务数量。
- 任务状态分布:按任务状态统计所有任务的分布情况。(数量为0的任务状态,不显示)
- 任务状态分布:按任务类型统计所有任务的分布情况。(数量为0的任务状态,不显示)

任务健康分析
传统的实时任务运维,只有简单的「运行中」和「运行失败」两种判断逻辑。
但是当运行失败时我们才发现的话,其实已经影响了线上实时数据服务。我们需要一种对运行中任务的风险评估,在任务还在正常运行状态下,提前发现潜在的风险问题并优化它,避免任务失败造成的业务影响。因此我们提出了任务健康分的概念。
什么是任务健康分
对平台正在运行的实时任务,按照健康分计算模型,进行合理打分的能力。
健康分计算逻辑
满分100分,当触发各项健康指标的阈值时,会扣除不等的分数。详见下表:
指标名称 扣分规则 自动重启次数 近3小时,Failover后自动重启次数达5-10次,扣10分;10次以上,扣20分 Checkpoint成功率 近3小时,Checkpoint生成成功率80%-95%,扣10分;低于80%,扣20分 Checkpoint平均耗时 近10个成功生成Checkpoint的平均耗时,大于生成checkpoint时间间隔配置的90%,扣10分 算子反压占比 近1小时,反压程度为Low的时长占比大于30%,或者程度为High的时长占比大于10%,扣20分 脏数据比例 近1小时,脏数据数量超过最大值的30%,扣10分(请先开启脏数据管理) TM 内存使用率 近3小时,TaskManager平均内存使用率小于30%,扣10分 TM CPU Load 近3小时,TaskManagerCPU平均负载小于5%,扣10分 note- 对于运行不足3小时的任务,统计时间从最近一次开始运行时间截止到当前;
- 后续该模型会持续完善,并且针对每个健康指标提供对应的问题排查指导说明;
解决方案
自动重启次数
产生原因
- 任务内存设置不合理
- checkpoint重试次数太多
解决方案
- 设置合理的内存
- 基于日志判断是否是因为内存设置不当导致的任务失败重启,并结合日志适当优化对应的内存模型
Checkpoint平均耗时和checkpoint成功率
产生原因
- Checkpoint间隔时间设置得太短可能会导致无法完成Checkpoint操作。
- Checkpoint需要将任务状态存储到可靠的存储系统中,例如分布式文件系统或对象存储。如果存储系统出现故障或无法访问,Checkpoint就会失败。可能的原因包括网络问题、存储系统配置错误或存储系统容量不足。
- 算子反压,导致barrier长时间未对齐checkpoint超时失败。
解决方案
- 根据任务的吞吐量合理设置checkpoint的超时时间。
- 设置checkpoint类型为增量checkpoint。
- 排查反压的算子,确定出是join数据处理慢还是sink端写的慢,再针对性对任务进行参数调整。
- 适当对状态后端的存储层进行优化以提高写入性能
算子反压占比
简述:反压(backpressure)是流式计算中十分常见的问题。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。由于实时计算应用通常使用消息队列来进行生产端和消费端的解耦,消费端数据源是 pull-based 的,所以反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。**
① 节点有性能瓶颈可能是该节点所在的机器有故障(网络、磁盘等)、机器的网络延迟和磁盘不足、频繁GC、数据热点等原因。
② 大多数消息中间件,例如kafka的consumer从broker把数据pull到本地,而producer把数据push到broker。
反压的影响
反压并不会直接影响作业的可用性,它表明作业处于亚健康的状态,有潜在的性能瓶颈并可能导致更大的数据处理延迟。通常来说,对于一些对延迟要求不高或者数据量较少的应用,反压的影响可能并不明显。然而对于规模比较大的 Flink 作业,反压可能会导致严重的问题。
反压会影响checkpoint
① checkpoint时长:checkpoint barrier跟随普通数据流动,如果数据处理被阻塞,使得checkpoint barrier流经整个数据管道的时长变长,导致checkpoint 总体时间变长。
② state大小:为保证Exactly-Once准确一次,对于有两个以上输入管道的 Operator,checkpoint barrier需要对齐,即接受到较快的输入管道的barrier后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的barrier也到达。这些被缓存的数据会被放到state 里面,导致checkpoint变大。
checkpoint是保证准确一次的关键,checkpoint时间变长有可能导致checkpoint超时失败,而state大小可能拖慢checkpoint甚至导致OOM。
数据延迟量过大导致算子反压
- 问题详情
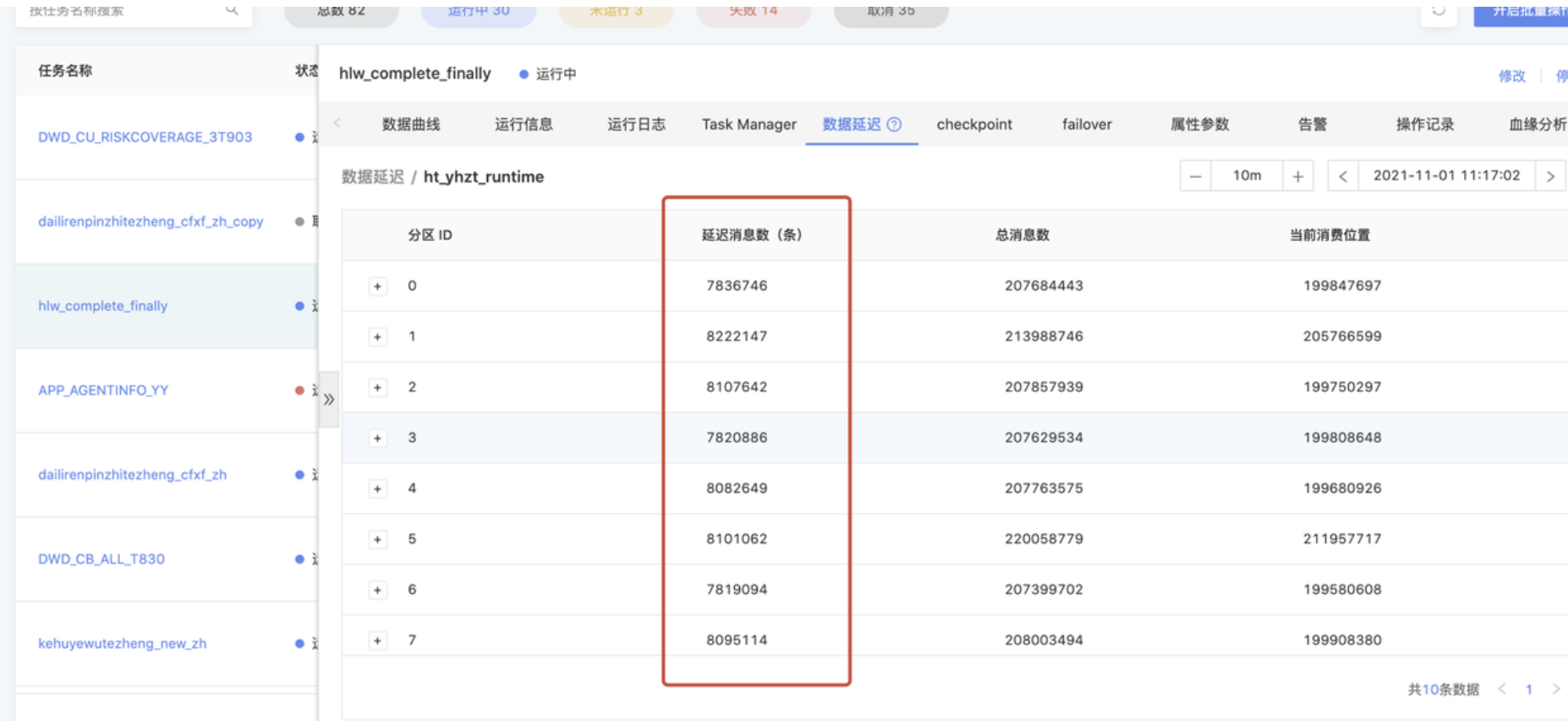
- 产生原因
下游数据的处理速度跟不上上游数据的产生速度,会导致数据延迟和反压
解决方案
- 在运行信息-Vertex拓扑中确定是哪个阶段产生的数据反压
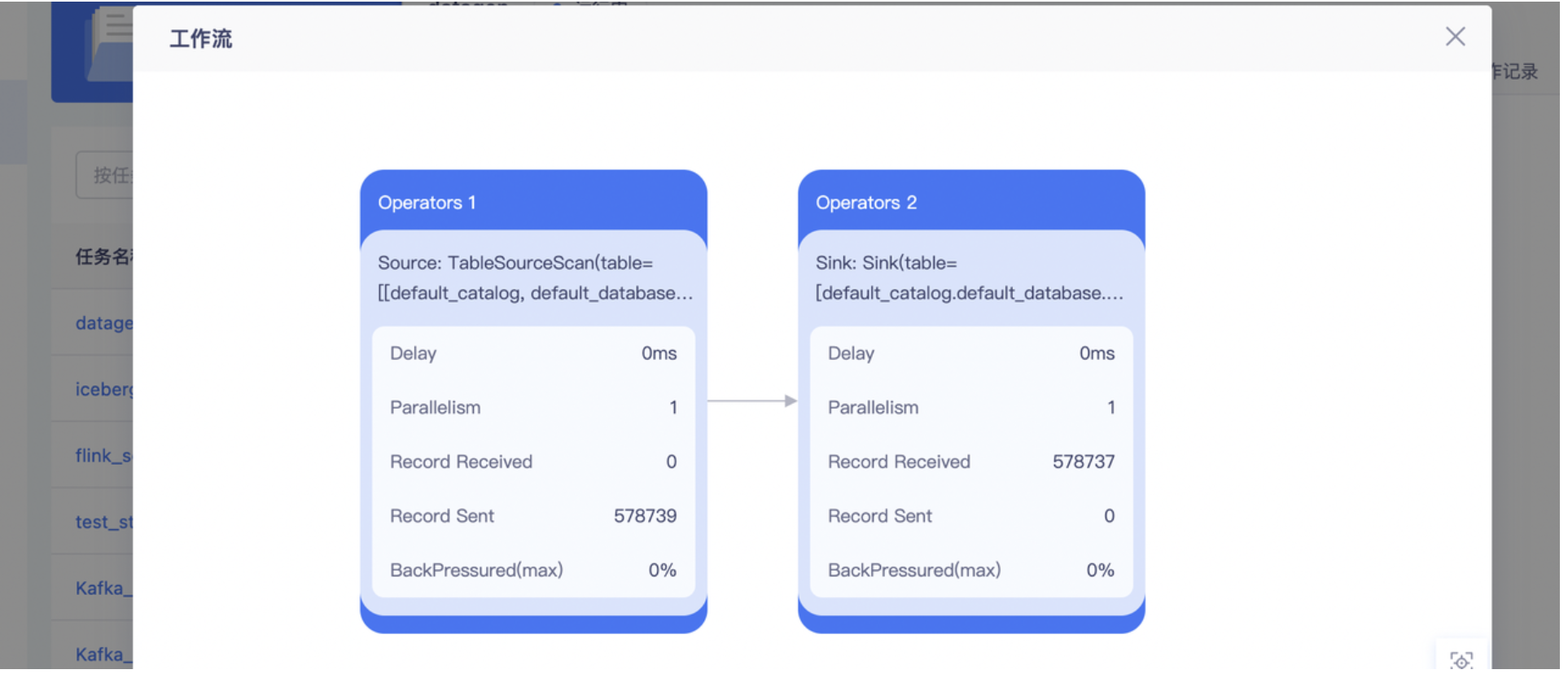
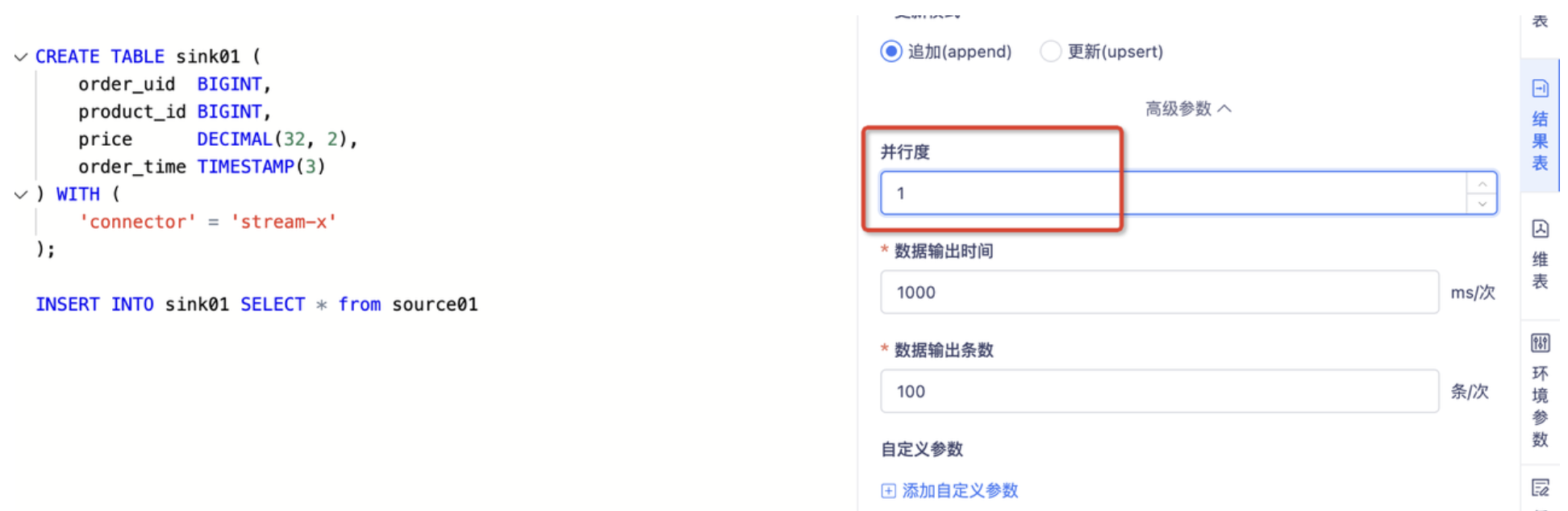
- 在任务开发中调高产生反压表相对应的并行度,具体可根据反压情况选择调大的数量
脏数据比例
概念
在数据库技术中,脏数据在临时更新脏读中产生。事务A更新了某个数据项X,但是由于某种原因,事务A出现了问题,于是要把A回滚。但是在回滚之前,另一个事务B读取了数据项X的值(A更新后),A回滚了事务,数据项恢复了原值。事务B读取的就是数据项X的就是一个“临时”的值,就是脏数据
产生
通俗的讲,当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
- 问题详情:
脏数据比例过高导致的健康分扣除
- 解决方案:
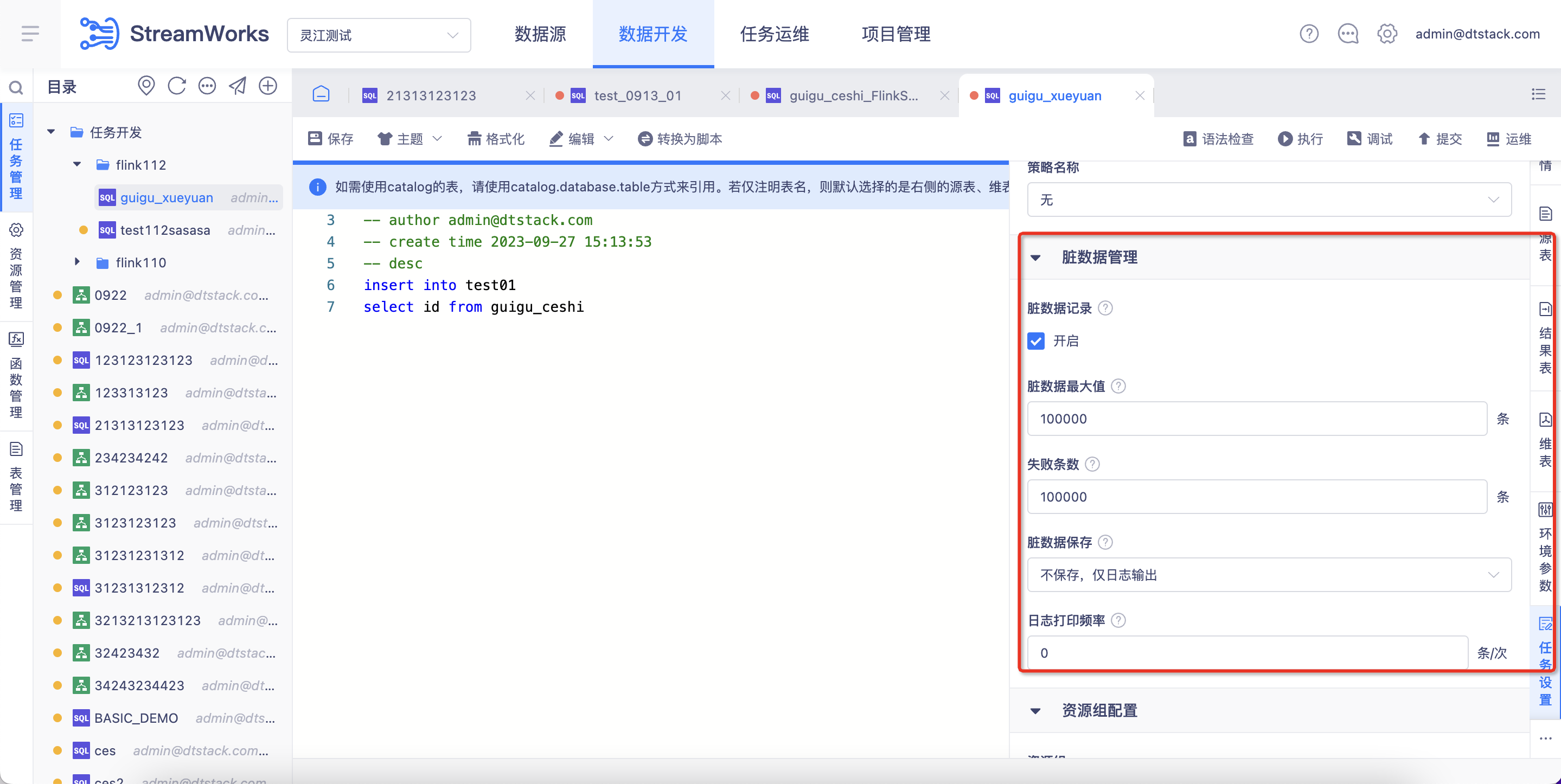
在创建任务时,任务设置》脏数据管理中开启脏数据管理
管理逻辑:当该任务产生脏数据时,会讲脏数据写入日志或者写入设定好的mysql,解决任务脏数据问题
TM内存使用率和TM CPU Load
- 问题详情:TM内存使用率不超过10%和TM CPU Load平均负载小于5%
- 产生原因:TM内存及CPI负载设置太大
- 解决方案:例:TM的内存是2G,实际上只用了100M,这是去调整TM的内存为200M这时就能提高TM内存使用率,提高健康分,TM CPu Load同理
生成报告
点击「生成报告」按钮,系统会将当前统计页面生成PDF文件,供线下运维汇报、运维存档等场景使用。