StreamWorks 6.1.4更新日志
发布时间:2023-12-30
新增
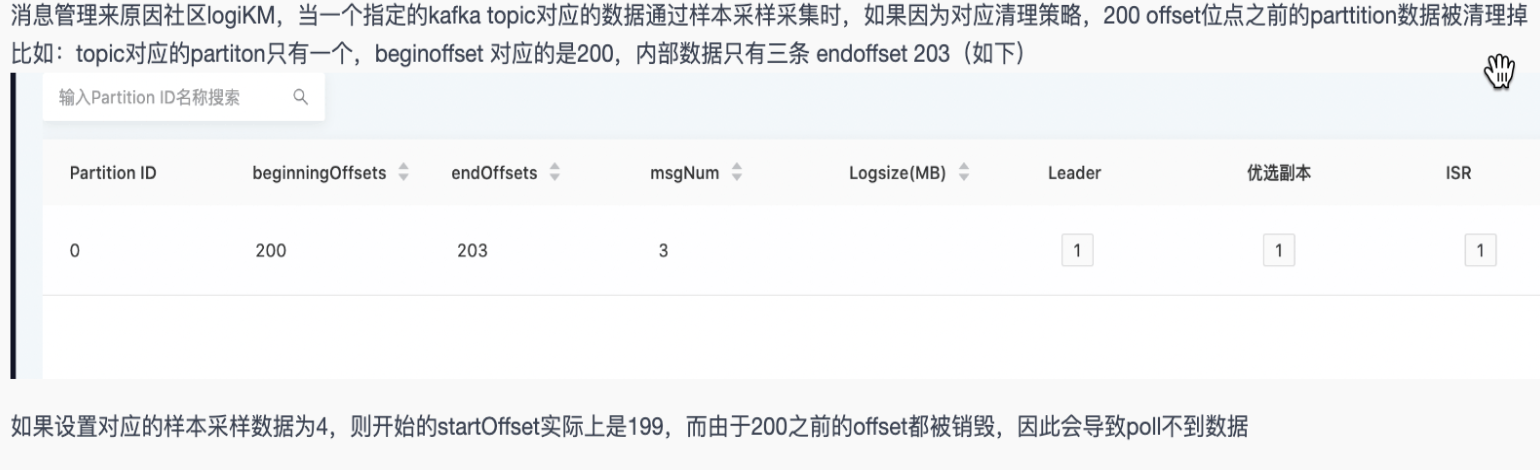
kafka管理最大采样条数大于当前分区offset数时,采样无数据返回【5.3】
- 背景: kafka管理最大采样条数大于当前分区offset数时,采样无数据返回
- 说明: 修复已知Kafka管理最大采样条数问题
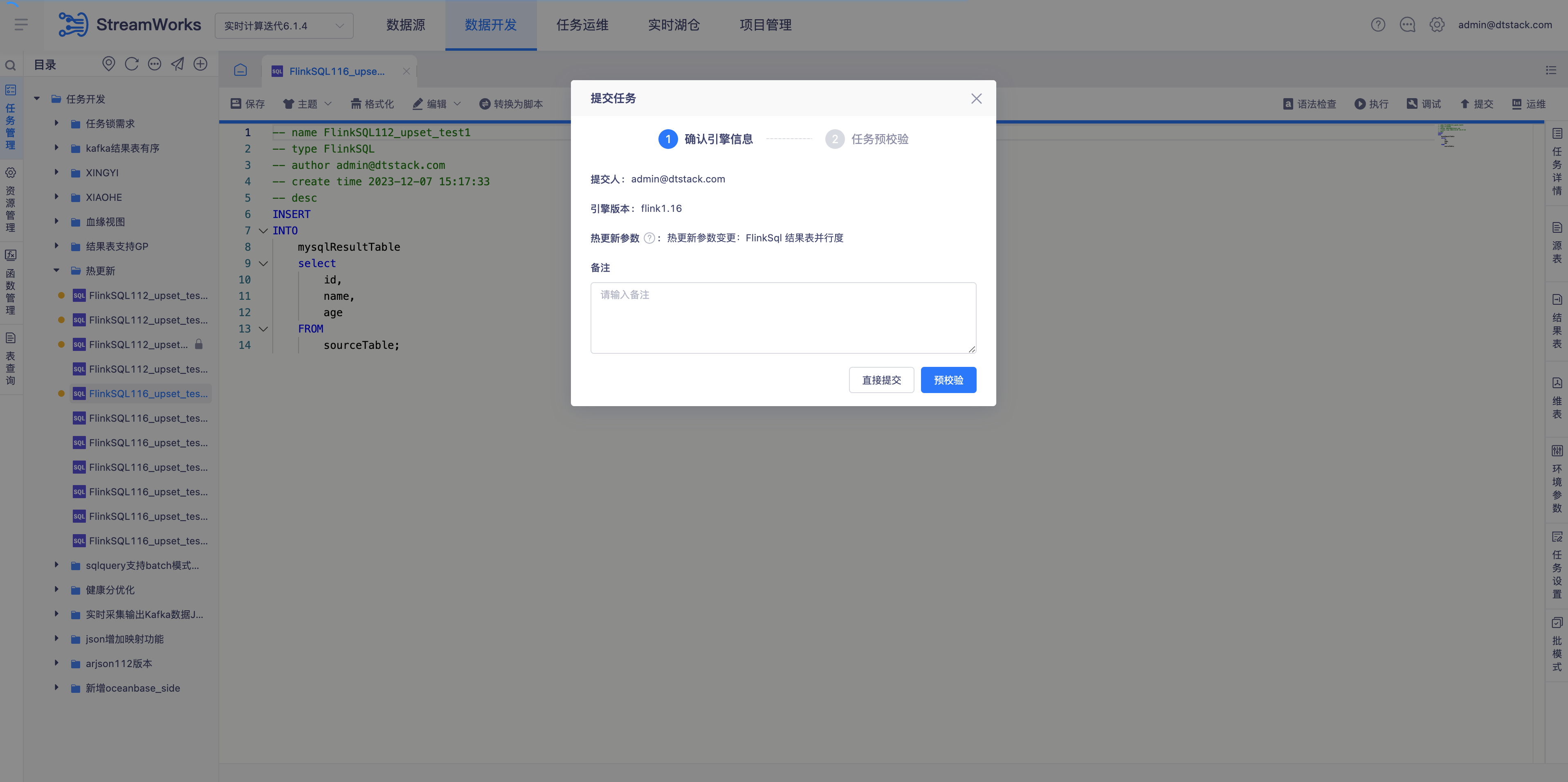
任务运维实时任务并行度修改的热更新【6.0】
- 背景: 在修改环境参数中的任务并行度参数后,为保证尽快生效平台会自动停止任务后重启,这让实时任务有了一个停止时间,重启耗时可能会比较久
- 说明: 在修改任务并行度参数后,不需要停止任务,提交后可直接生效,需要引擎出方案修改;
- 支持热更新的参数如下:
- FlinkSQL插件参数:维表all改为lru、查询超时时间
- flink参数:并行度、checkPoint参数
- 支持热更新的参数如下:
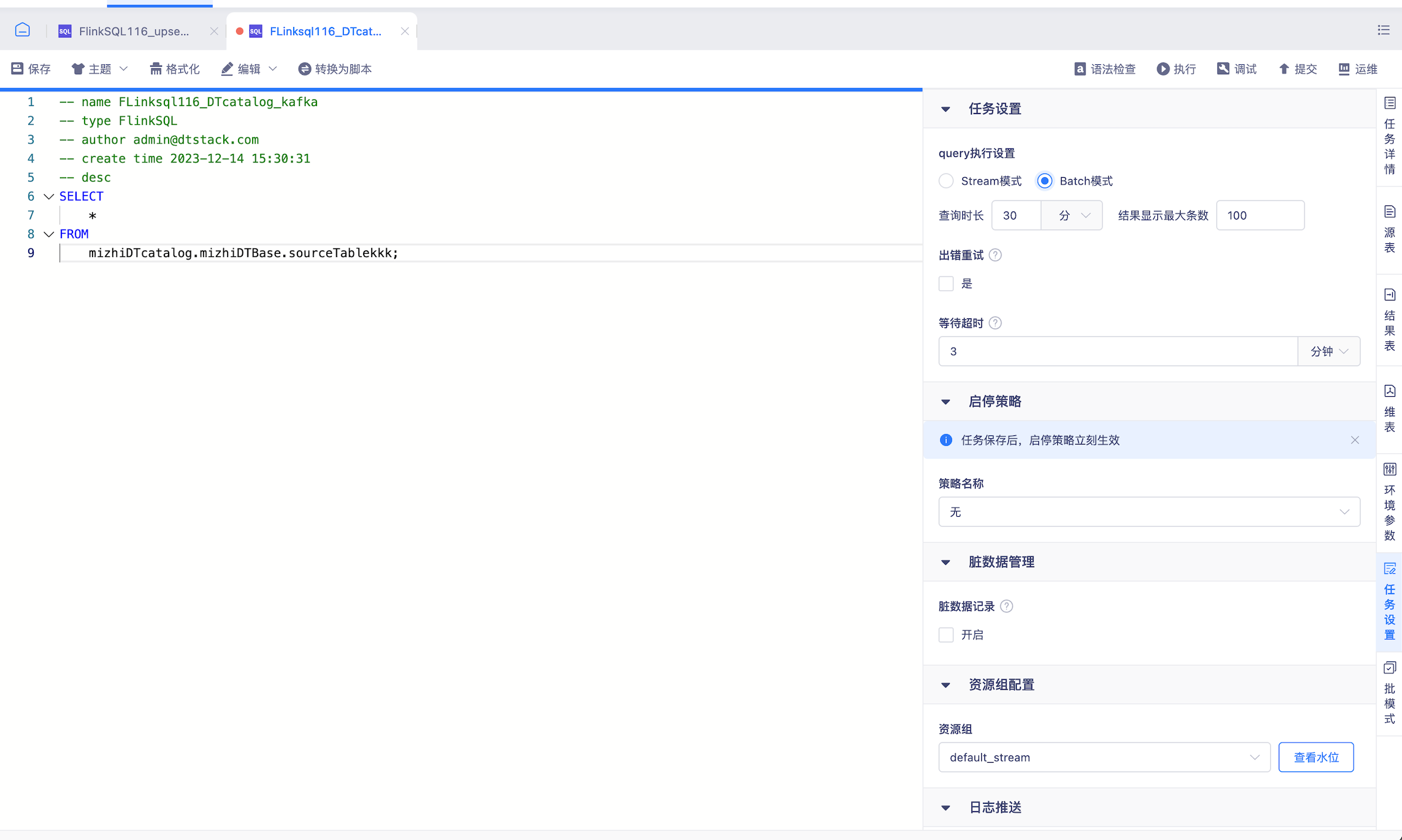
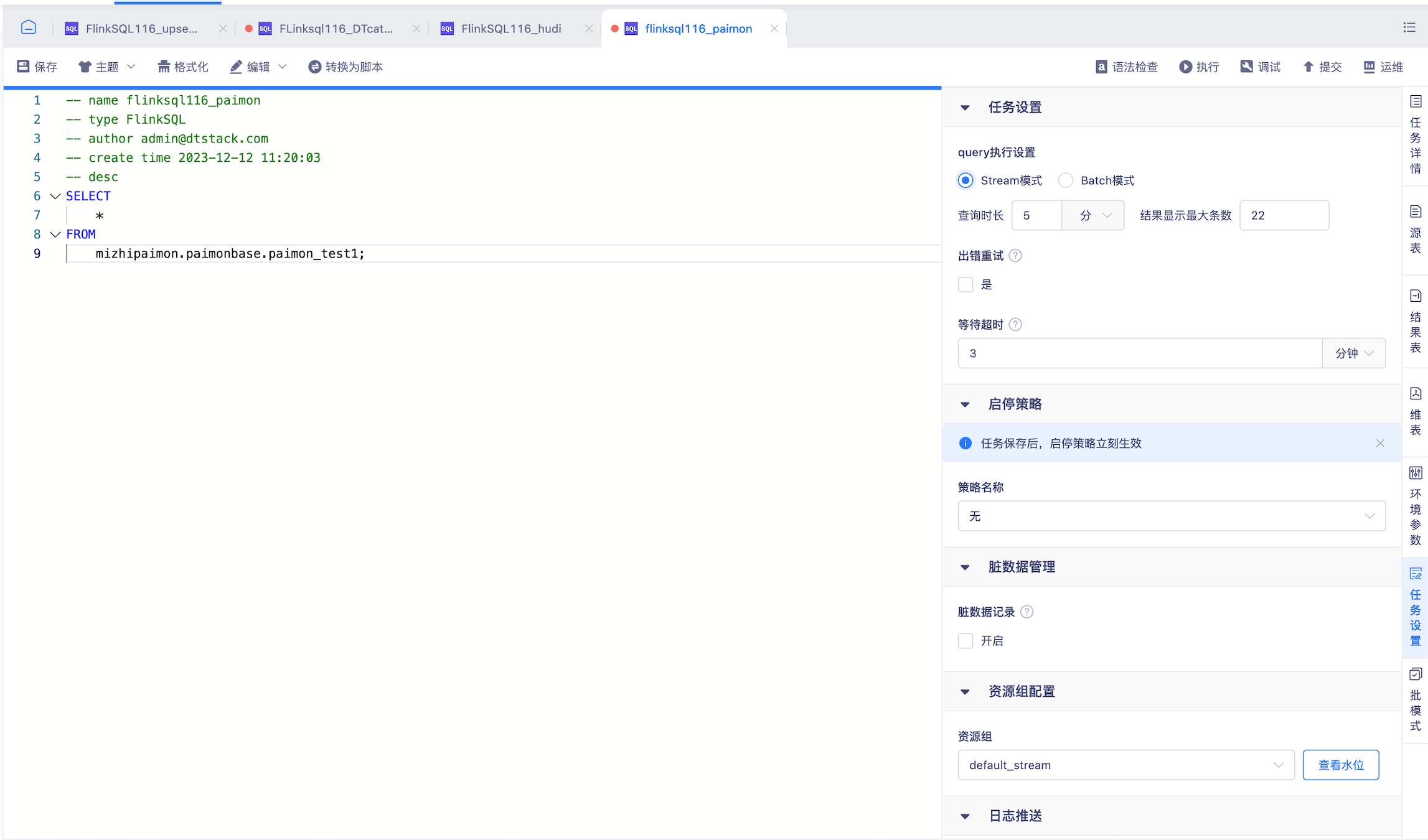
数据开发sql query支持streaming、batch模式选择【6.0】
- 背景: 需求支持sql query支持流批模式查询,原只支持streaming模式
- 说明: 针对FlinkSQL任务(1.16),任务设置中支持query执行设置,可选择执行方式为流模式或者批模式
- 【Stream模式】
- 任务以流模式查数据
- 查询时长:以任务开始在flink引擎上执行作为计算起点,当查询时间达到此处设置上限时自动停止查询
- 结果最大显示条数:即当查询到的数据条数满足设置值时数据总量不再增加,新的数据覆盖最早的数据
- 支持数据源: kafka、mysql、oracle、湖表iceberg、hudi、paimon
- 【Batch模式】
- 任务以批模式查数据,数据查完后暂存,一次性返回至平台展示,支持结果下载,下载功能同stream模式
- 查询时长:查询时间达到此处设置上限时自动停止查询,若在此时间内数据返回结束则打印结果,否则结果为空
- 结果最大显示条数:查询/下载结果上限为此处设置的条数
- 支持数据源: kafka、mysql、oracle、湖表iceberg、hudi、paimon
- 【Stream模式】
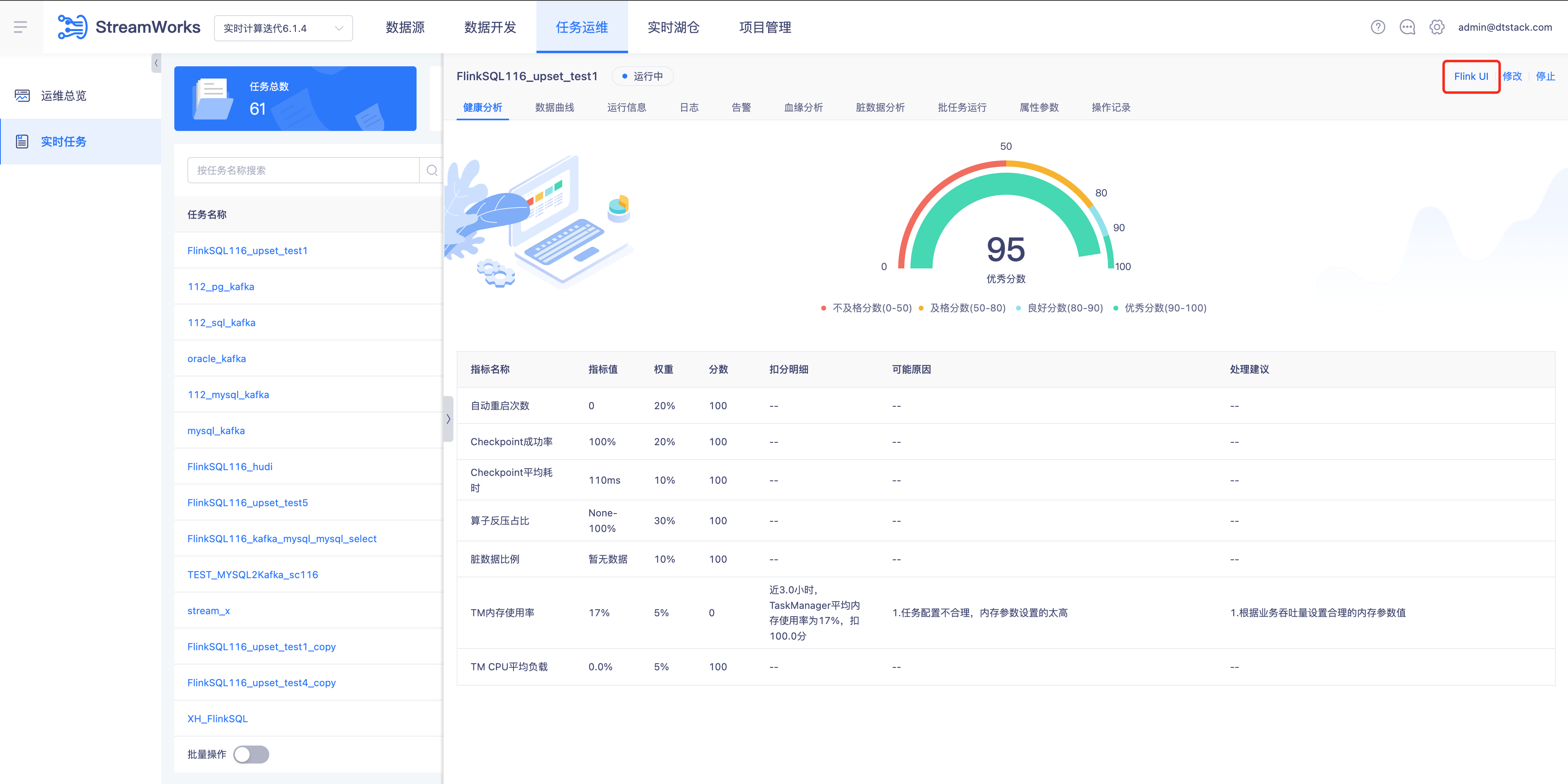
任务运维任务支持跳转FlinkUI【6.0】
- 背景: Flink Dashboard展示了一些平台没有展示的运行及日志等信息,对有经验的数据开发来说更方便排查问题
- 说明: 实时计算所有“运行中”状态(实际非application运行中,需要job运行中才能跳转成功)的任务的运维页面在下图位置显示FlinkUI跳转入口
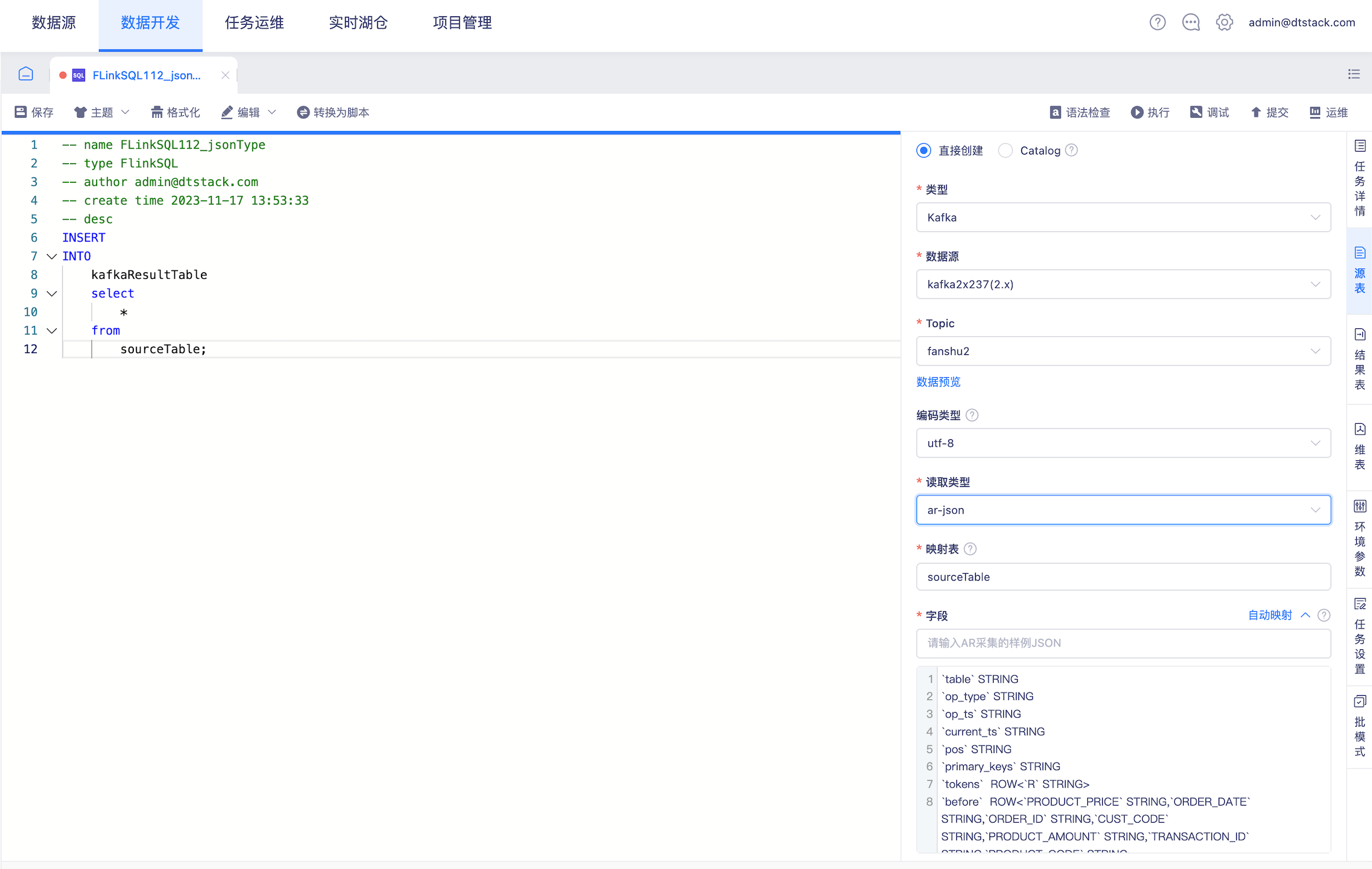
数据开发kafka格式新增attunity json 【6.0】
- 背景: 支持基于attunity json的读取类型采集/输入样例数据,自动映射Flink表
- 说明: json平铺解析的方式用json增加自动映射的功能满足
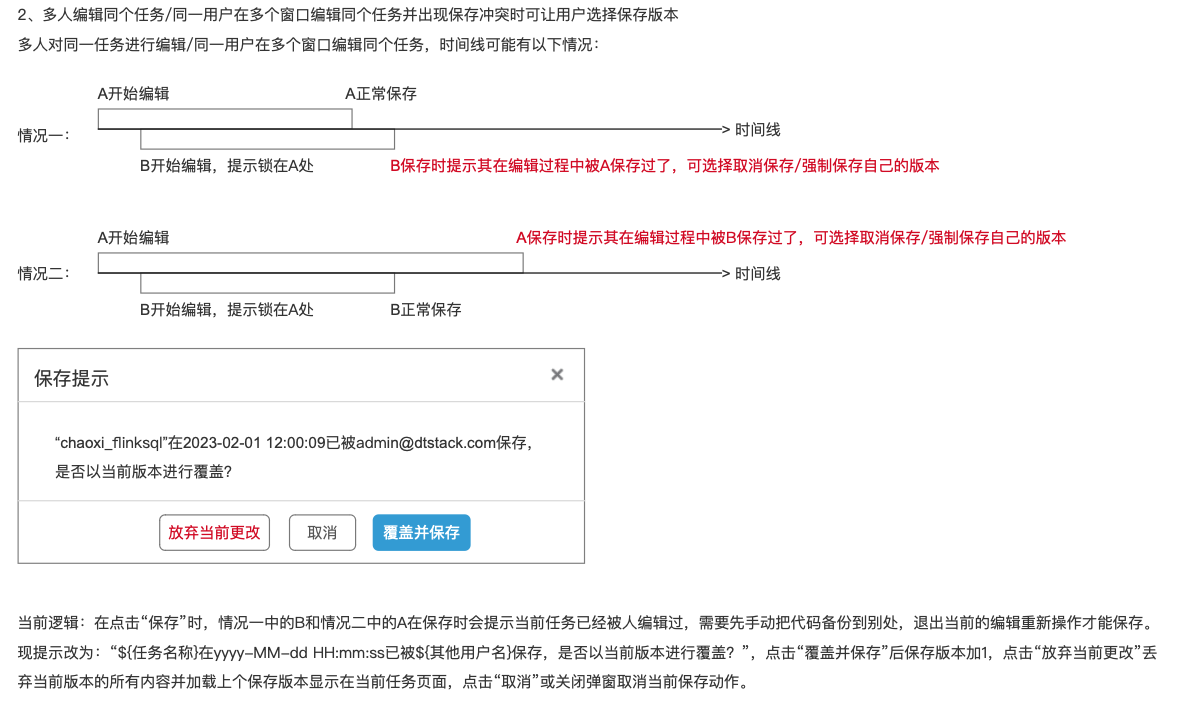
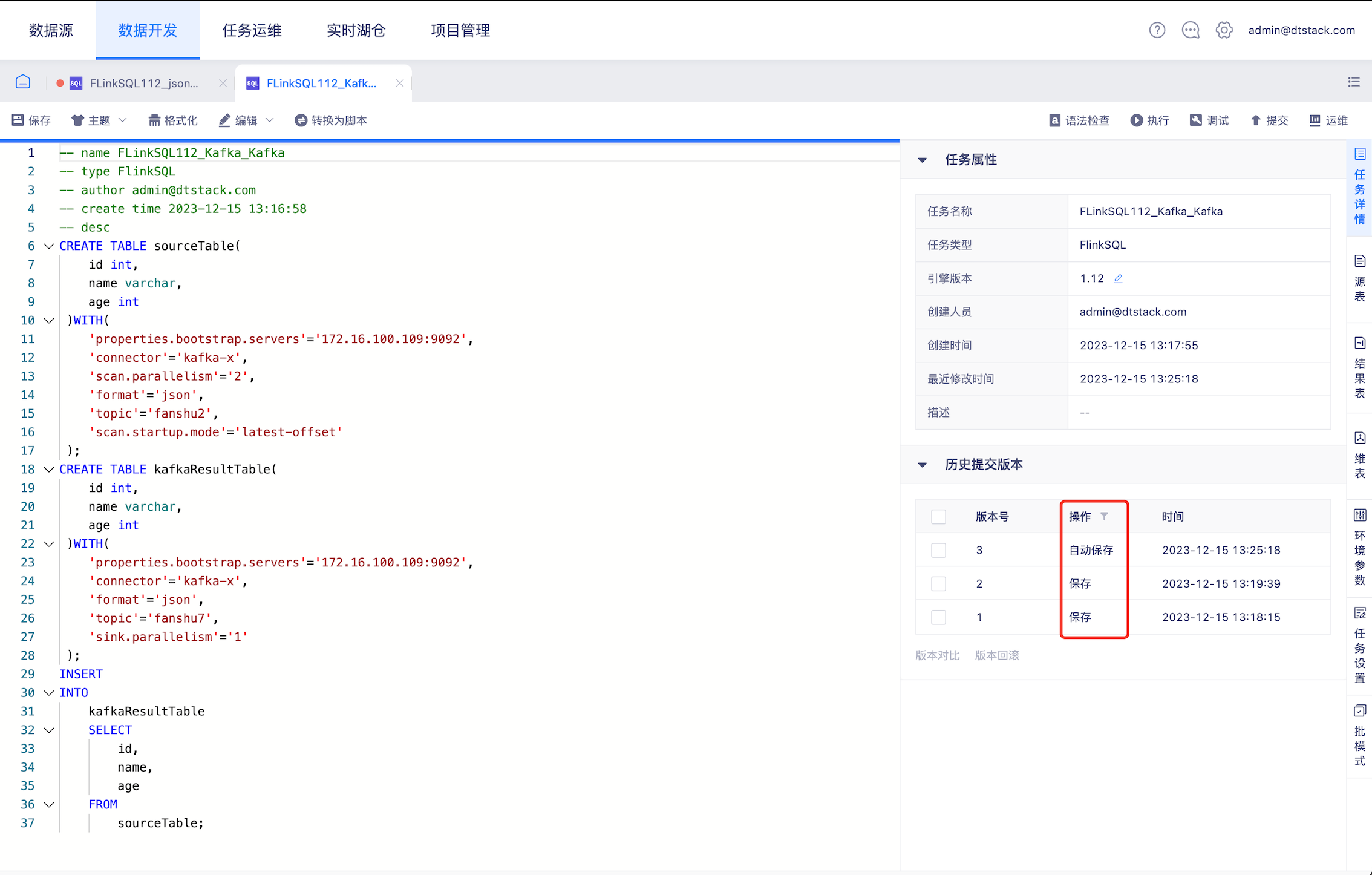
数据开发任务锁覆盖逻辑优化【6.0】
- 背景: 目前同一用户在两个窗口同时编辑任务时,A窗口先保存,B窗口再次保存时,覆盖逻辑默认A覆盖B,会导致后保存版本内容丢失。
- 说明: 任务锁覆盖逻辑优化
- 版本记录增加保存版本,平台异常登出时自动保存任务
- 多人编辑同个任务/同一用户在多个窗口编辑同个任务并出现保存冲突时可让用户选择保存版本
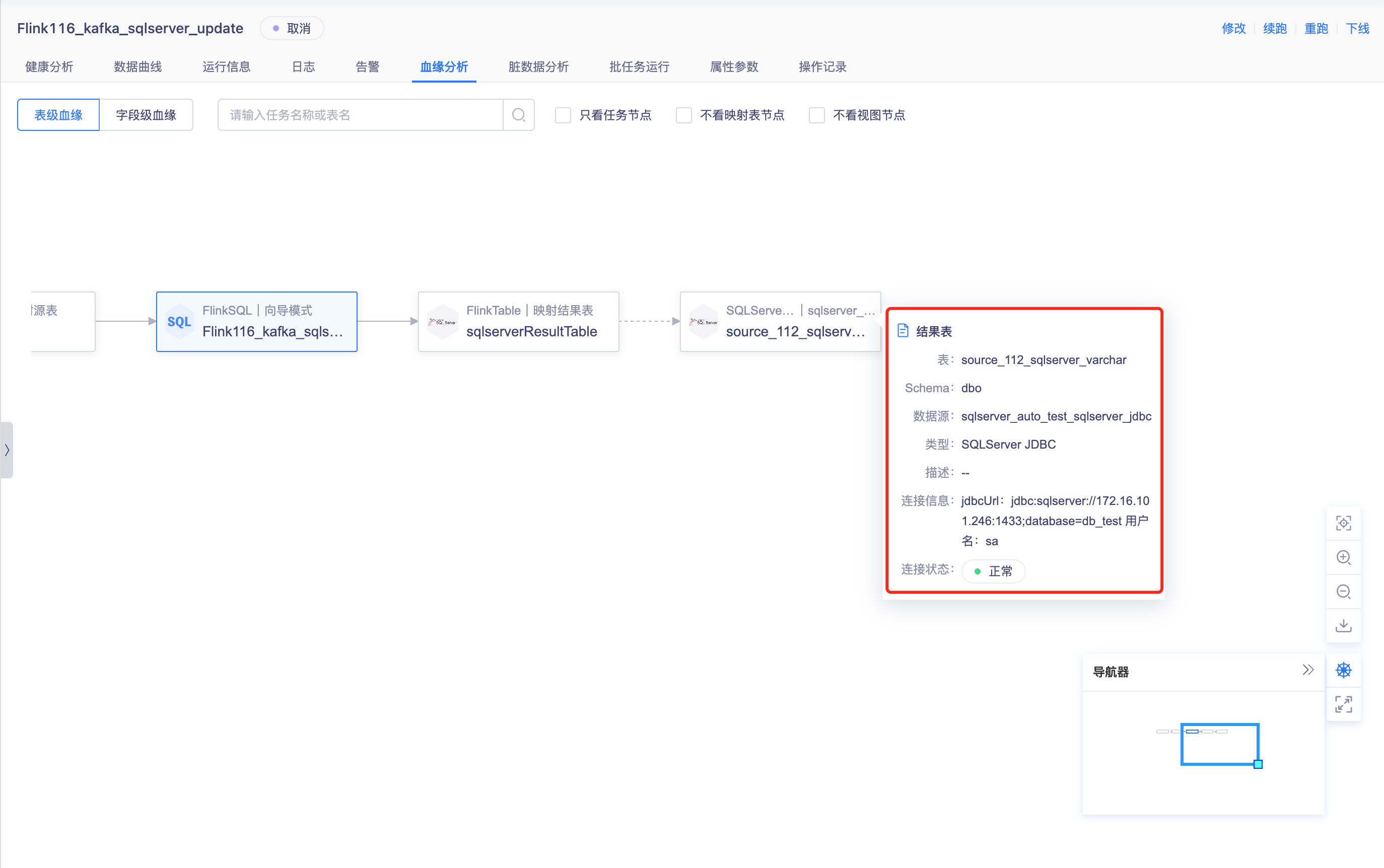
任务运维血缘节点信息优化【6.0】
- 背景: 血缘图的数据源节点上展示数据源归属业务信息
- 说明: 针对FlinkSQL和实时采集任务,表级血缘图中的源表、维表与结果表的节点,点击时显示数据源信息,交互与任务的详细浮窗一致
实时采集现在实时采集打到Kafka的数据,json数据乱序【6.0】
- 背景: 实时计算实时采集到Kafka数据写入Json数据乱序排列
- 说明: 提高Json数据可读性将采集写入Kafka进行数据修正

实时开发预校验报错信息不全【5.3】
- 背景: 实时开发预校验报错信息不全导致报错信息查看失败
- 说明: 前端修复已知报错信息展示不全问题
实时开发 on k8s kafka作为sink端,修复numwriter相关指标【6.0】
- 背景: Kafka作为sink端一些numwrite指标补充
- 说明: kafka sink之前用的是原生kafka的一些逻辑,numwrite的指标是chunjun的,需要修改源码补充
实时开发选择资源时直接根据任务类型限制能选择的资源类型范围【5.3】
- 背景: 每种需要资源创建的任务类型在创建时有校验资源类型是否选择正确,而不是在选择资源时直接根据当前任务类型进行可选资源范围过滤,错误提示滞后,增加用户误操作成本
- 说明: 选择资源时直接根据任务类型限制可选范围,其余不可选的资源类型在下拉时置灰无法选中:
- Flink可选范围为jar文件
- PyFlink可选范围为py文件
实时开发任务下线后可选择清理checkpoint、savepoint信息,任务异常状态清理zk信息【6.0】
- 背景:
- 某个任务由于业务变更需要修改逻辑或在较长的一段时间内不需要执行时,在任务运维列表中还持续存在会造成信息干扰,需要一个下线的操作,和提交形成逆向的操作闭环
- 任务下线后可能隔断时间会重新提交,也可能很长一段时间内不会再次提交,目前所有任务的cp sp信息都保留可能会导致无用文件的堆积;任务删除时任务相关的信息更要完整删除
- on k8s的任务下在jobgraph创建之前任务被取消或者任务异常失败是不会被清理的。正常结束或者jobgraph调度之后再被取消,会正常清理;on yarn的任务,如果任务cancel会删除数据,但是如果直接kill application不会删除zk数据,同样导致无用文件堆积
- 说明:
- 任务下线时可选择清理运维记录及日志数据;任务删除时自动删除运维记录及日志数据
- 任务信息清理;
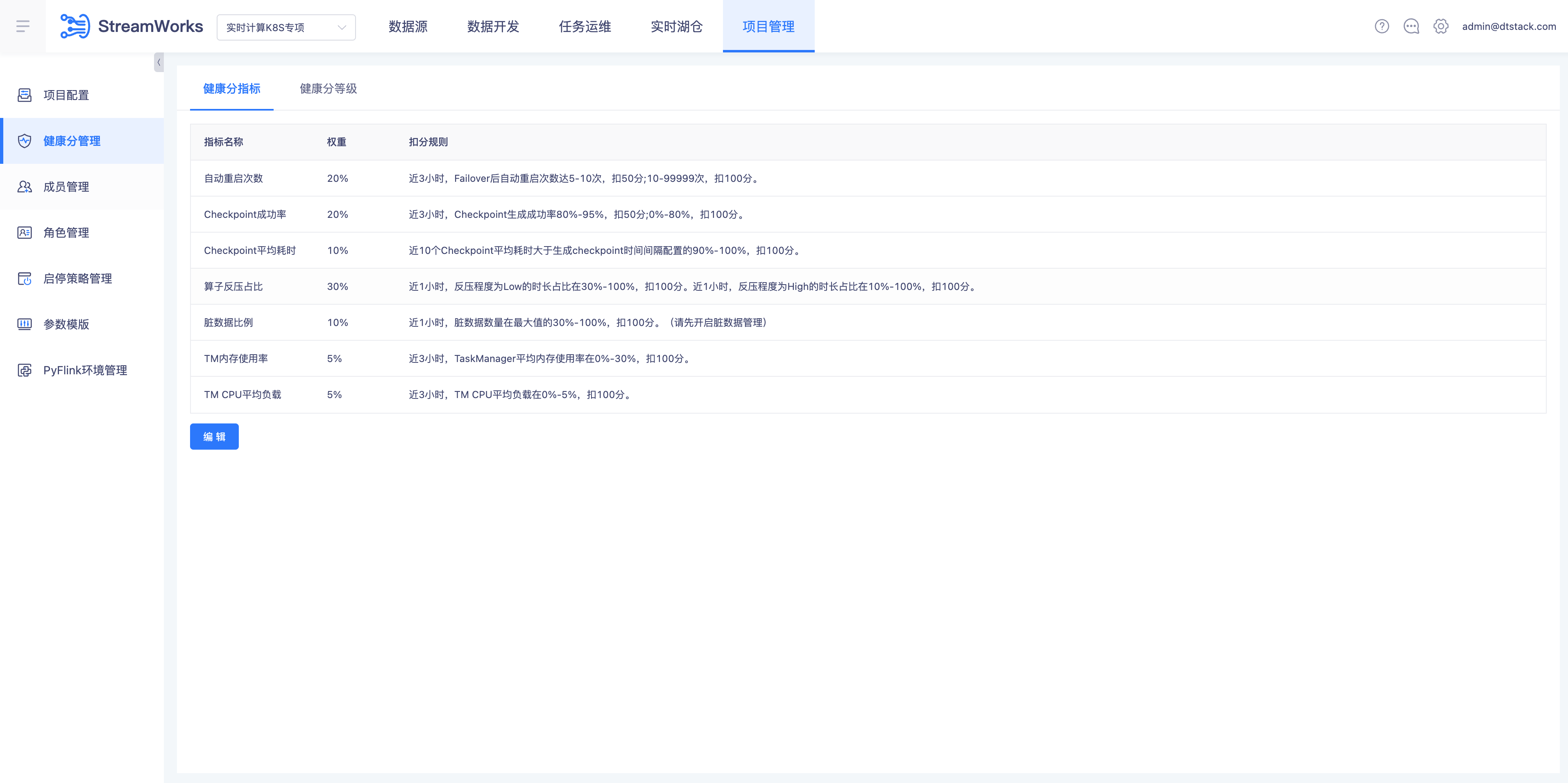
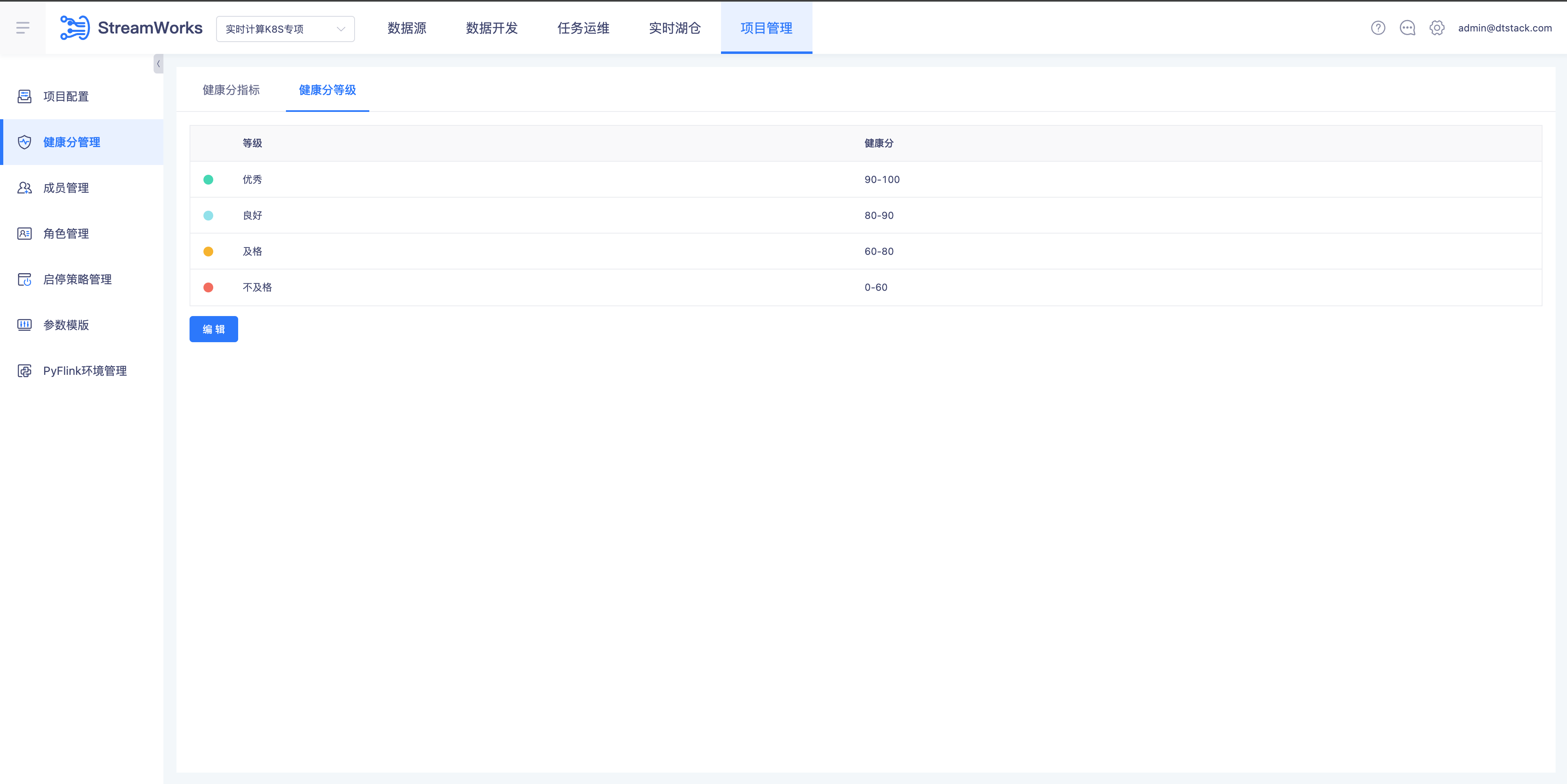
健康分优化【6.0】
- 背景:
- 指标权重可自定义
- 目前设置的资源占用是从是否浪费的角度,客户关心的是否不够的角度
- 按健康发告警时需要考虑告警分值自定义、告警时需要说明分值对应的健康状态
- 说明:
- 项目管理导航栏下新增“健康分管理”子页面,里面分为“健康分指标”(默认展示)和“健康分等级”两个tab
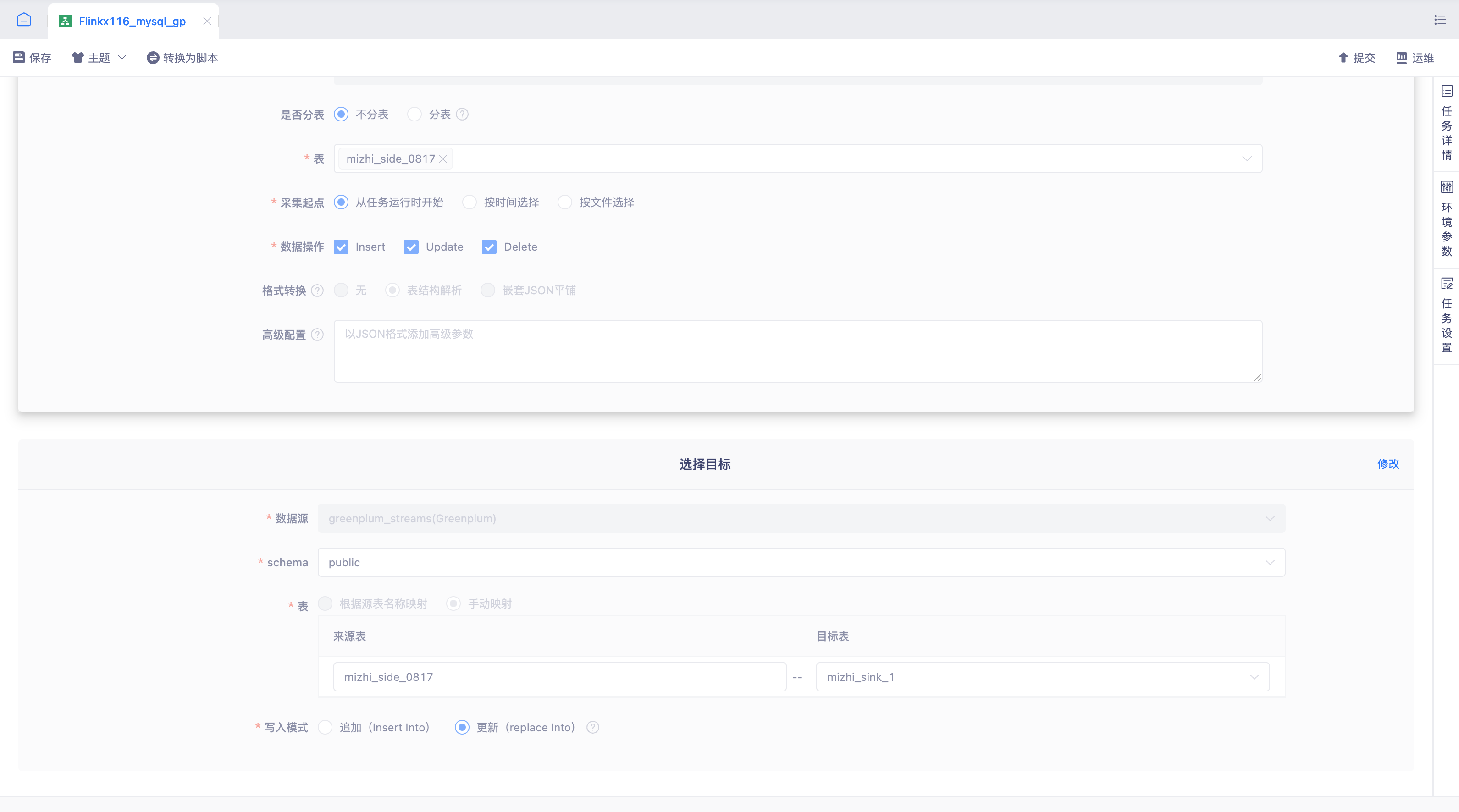
实时采集向导模式结果端支持gp【5.3】
- 背景: 交付需求实时采集1.12&1.16支持Greenplum目标表写入能力
- 说明: 实时采集1.12&1.16版本对Greenplum目标表表的支持,为用户提供了更加灵活和高效的数据处理能力
修复重跑选择指定位offset点进行重跑,点击确定后会进行重跑【5.3】
- 背景: 重跑选择选择了指定位offset点进行重跑,点击确定后会进行重跑,如不支持则不能点击确认后进行重跑操作,显示的没有问题
- 说明: 后端修复已知重跑选择指定位offset点进行重跑问题
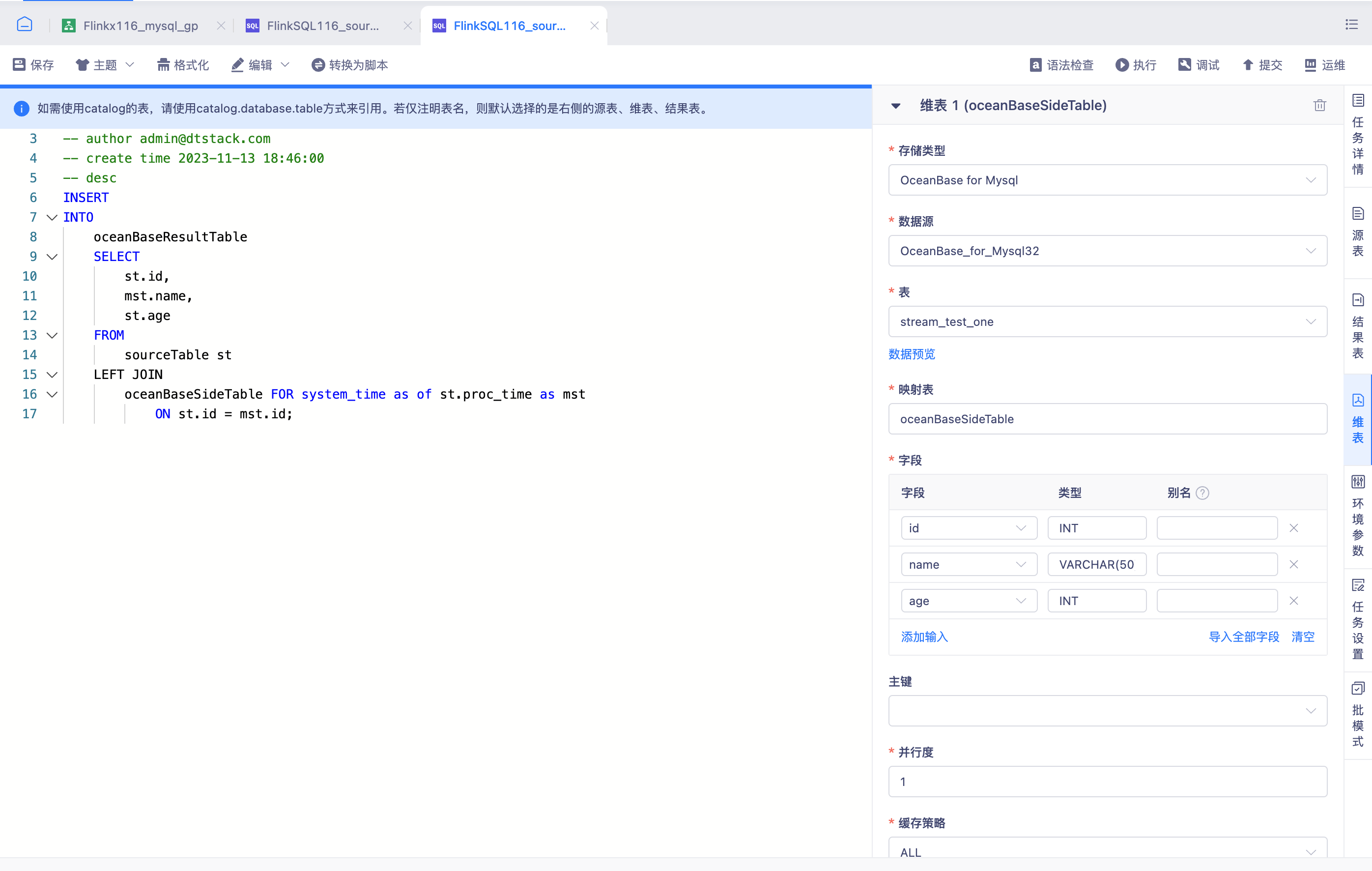
FlinkSQL维表支持OceanBase【6.0】
- 背景: 交付需求FlinkSQL1.16支持OceanBase维表读取能力
- 说明: FlinkSQL1.16版本对OceanBase维表的支持,为用户提供了更加灵活和高效的数据处理能力
前端改造React Router 升级 v3.x 到 v6.x【6.0】
- 背景: 前端改造React Router 升级 v3.x 到 v6.x
- 说明: 目前数栈产品,react 相关工具版本普遍较低,其中 react router 版本为 3.x。而最新的 react router 已经到了 6.x 版本
前端易用性性能改造【6.0】
- 背景: 前端易用性性能改造
- 说明: 改进首屏性能,通过易测做量化,改进 FPS 场景任务