Flink CDC
应用场景
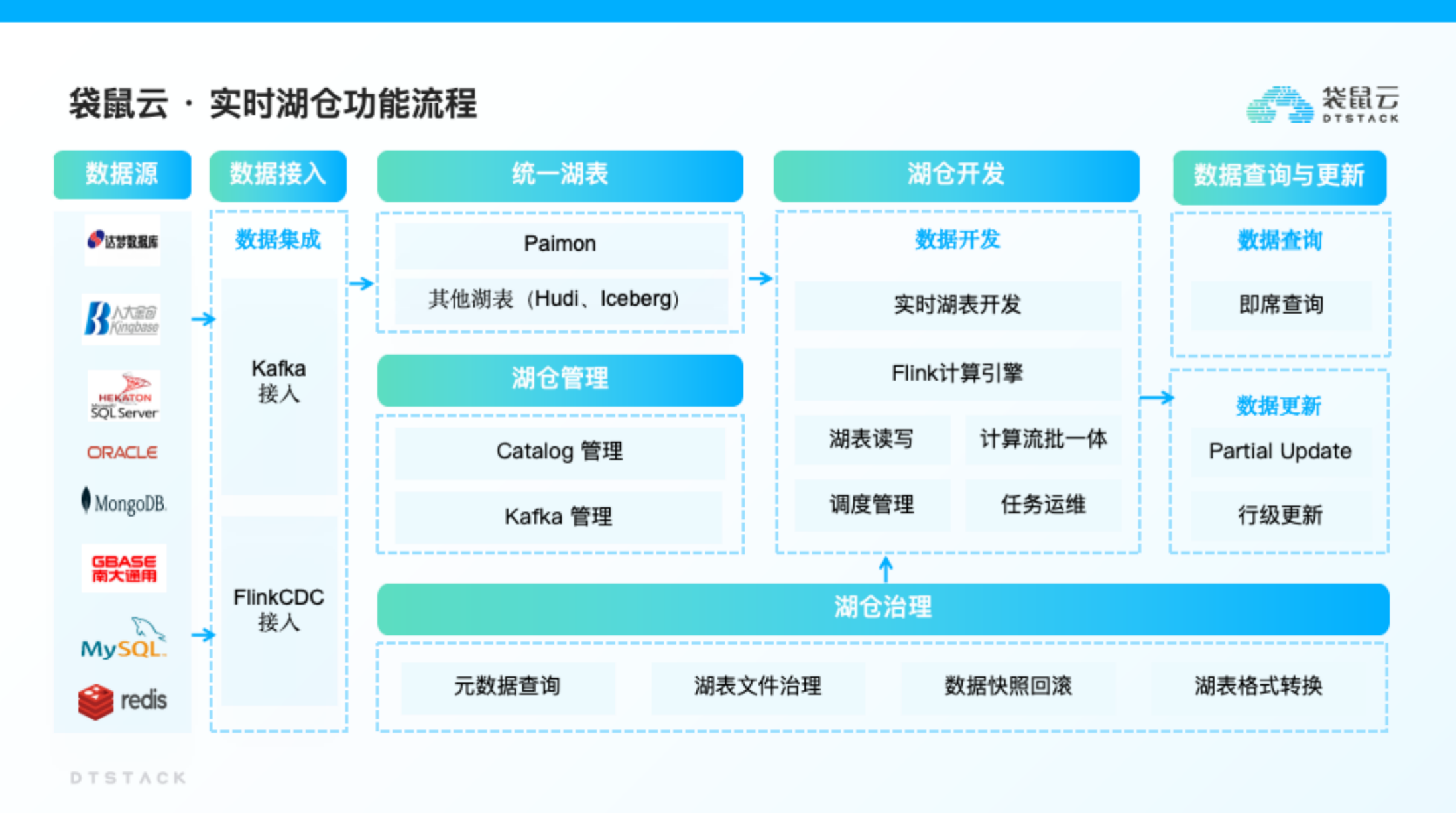
Flink CDC(Change Data Capture)是由Apache Flink提供的一个流数据集成工具,它允许用户通过YAML文件优雅地定义ETL(Extract, Transform, Load)流程,并自动生成定制化的Flink算子和提交Flink作业。Flink CDC的核心特性包括:端到端数据集成框架、易于构建作业的API、多表支持、整库同步精确一次语义、增量快照算法等诸多特性。Chunjun融合FlinkCDC能够更好支持数据的入湖入仓。
融合FLinKCDC给ChunJun带来那些变化:
- 高吞吐、低延迟:Flink CDC 能够以高吞吐量和低延迟的方式捕获和传输数据库的变更。
- 全增量一体化:Flink CDC 支持全量数据和增量数据的同步,无需手动操作即可实现全量快照与增量日志的自动衔接。
- 支持异构数据源:Flink CDC 支持多种数据源,可以轻松实现异构数据源的集成,通过 Flink SQL 定义不同类型的CDC 表,实现数据融合。
- 实时性:支持近实时的数据同步,满足对数据时效性要求高的场景。
- 链路短组件少:Flink CDC 的架构设计使得整个数据捕获和处理的链路更加简洁,涉及的组件数量有限。这不仅降低了系统的复杂性,也减少了学习和运维的成本。
Flink CDC的应用场景:
- Mysql一键入湖Paimon等湖表。
- 批流一体的采集任务,支持一个任务完成存量数据同步,并无缝衔接增量数据还原。
实时目前支持FLinkCDC版本
- 3.2 Release
支持的数据源类型
该功能仅旗舰版支持
| 采集的数据源 | 采集任务类型 | 开发模式 | 采集范围 | 写入的目标表 | 连接器connectors | 实时版本 |
|---|---|---|---|---|---|---|
| MySQL | 实时采集 | 向导模式+脚本模式 | 增量、全量+增量 | Paimon | Pipeline Connectors | 6.0及以上(1.16) |
| MySQL | 实时采集 | 向导模式+脚本模式 | 增量、全量+增量 | Starrocks3.x | Pipeline Connectors | 6.2及以上(1.16) |
| MySQL | 实时采集 | 向导模式+脚本模式 | 增量、全量+增量 | Doris2.x | Pipeline Connectors | 6.2及以上(1.16) |
MySQL—>Paimon FLinkCDC采集任务(增量|全量+增量)内部实践案例
任务配置
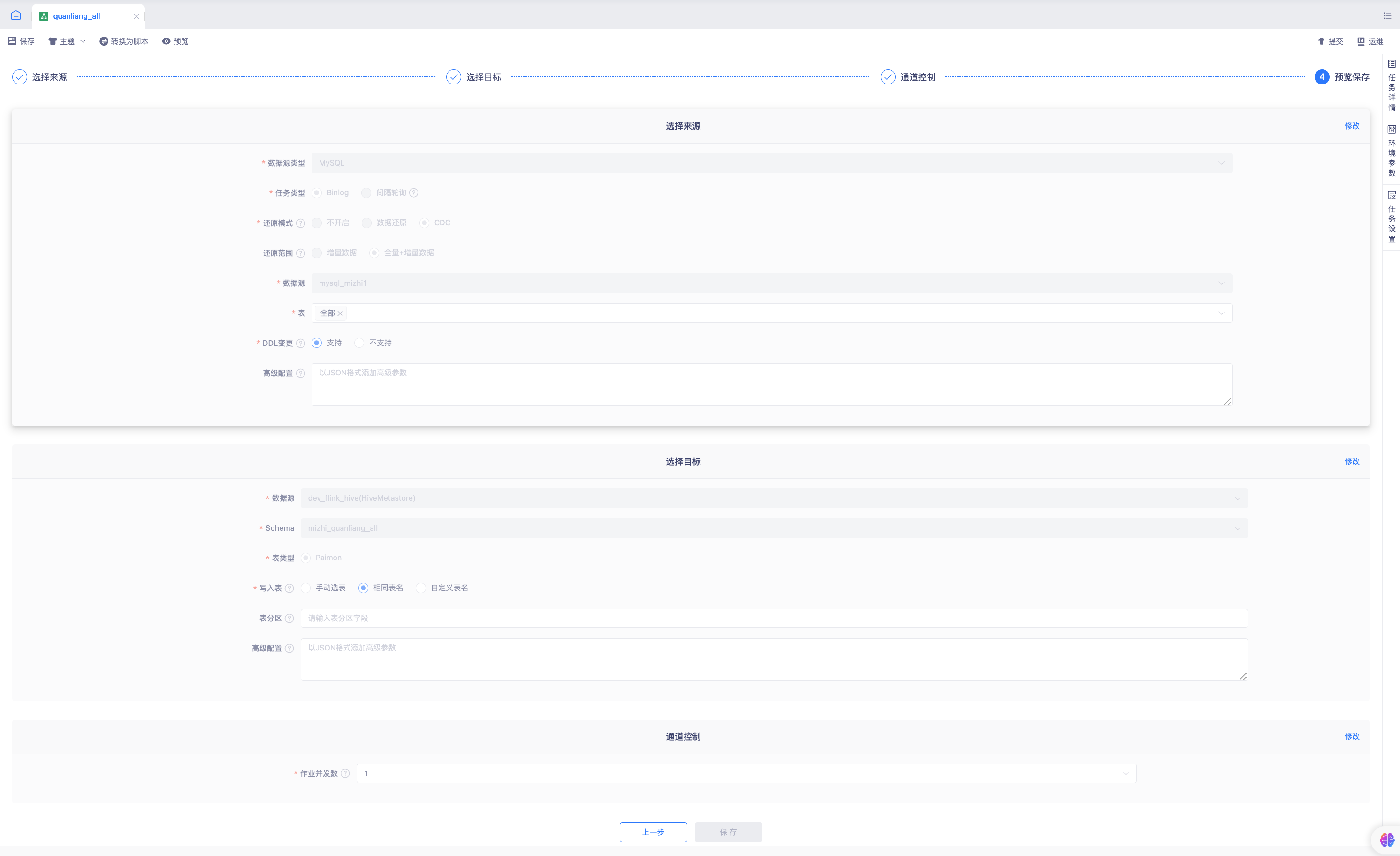
- 操作页面截图:
- 操作步骤:
Flink1.16版本及以上实时采集任务支持CDC,数据源类型选择MySQL,任务类型选择Binlog。
还原模式配置项选择必选项:CDC。
a. 还原模式未开启-对应历史任务中,Binlog增量数据采集模式
b. 还原模式选择数据还原-对应历史任务中,数据还原增量|全量+增量数据采集模式
c. 还原模式CDC-对应FlinkCDC采集任务
勾选数据模式CDC模式后,需要选择数据还原范围。
a. 增量数据:采集并还原从采集起点开始,源表产生的DDL和DML日志
b. 全量+增量数据:先同步源表历史全量数据,完成后自动采集并还原从任务开始运行时产生的新增日志信息
选择Mysql数据源和表
a. 数据源列表中选择数据源中心授权給项目的Mysql数据源
b. 选表方式支持手动选表|正则选表
手动选表:表的选择支持整库、多表、单表
正则选表:支持Regex正则表达式,输入正则后右侧预览按钮预览匹配到的表,正则选表返回的表只能作为当时查询数据库匹配到的表,实际还是以FlinkX提交运行任务时匹配到的表为准。
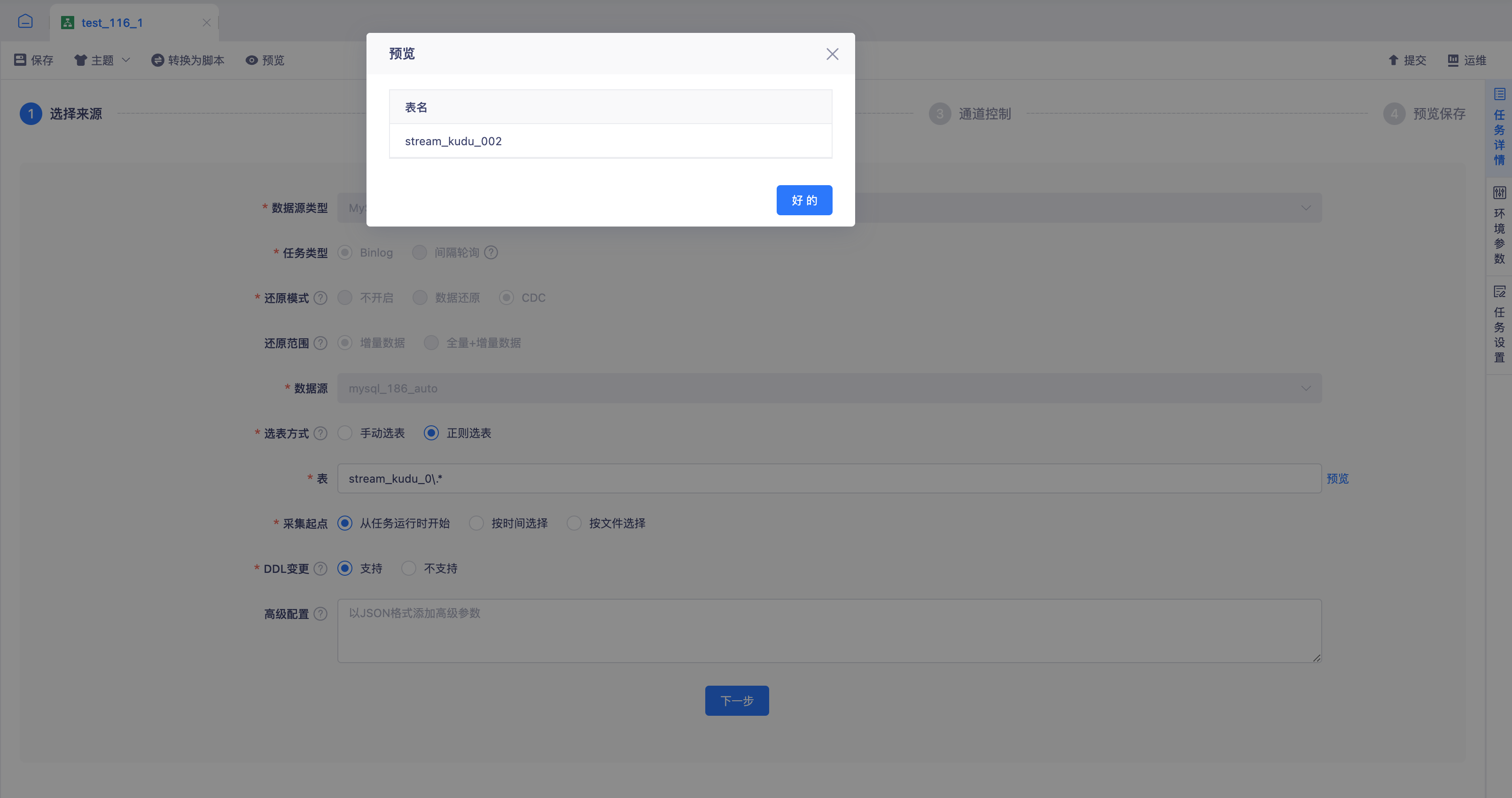
c. 脚本模式支持分库分表选择方式
DDL变更选择支持
a. DDL变更-选择支持: 下游自动执行DDL
b. DDL变更-选择不支持: 下游不支持DDL抛出执行DDL异常,需要用户手动执行DDL
c. DDL执行范围: 仅支持 create table、addColumn、 dropColumn、renameColumn、 alterColumn 变更操作
目标端选择HiveMetaStore数据源表类型选择Paimon。
a. 目标端数据源选择HiveMetaStore数据源、选择对应Schema
b. 目标端表类型当前仅支持Paimon表
目标端写入表三种方式
a. 手动选表: 选对下游目标对应的表,支持选择多选名,作为采集还原的写入表,支持来源多表写入单目标表。
b. 相同表名: 目标端自动创建和源表相同的表,表名为来源表。
b. 自定义表名: 目标端自动创建自定义的源表,目标端的表名可有常量+变量组成,例如表示该表是从mysql同步过来的,则自定义表名:mysql_${tableName}。其中变量支持: ${tableName} —— 自动获取源端表名。该变量为必填项。
tip手动选表:来源选择多表时,目标写入单表时,请保证表结构保持一致
表分区:写入表方式为相同表名、自定义表名时,通过来源表的字段,在自动建表时将来源表主键字段作为目标表的分区字段格式为:目标库名.目标表名:字段名(多个分区字段通过英文逗号间隔,来源表字段必须是主键)
配置通道控制
a. 作业并发数支持用户根据业务需求和集群资源手动设定。全量阶段支持多并发读取写入;增量阶段仅支持多并非写入,不支持多并发读取。
入湖数据如何快速查询
- FlinkSQL执行SQL Query流批一体查询:
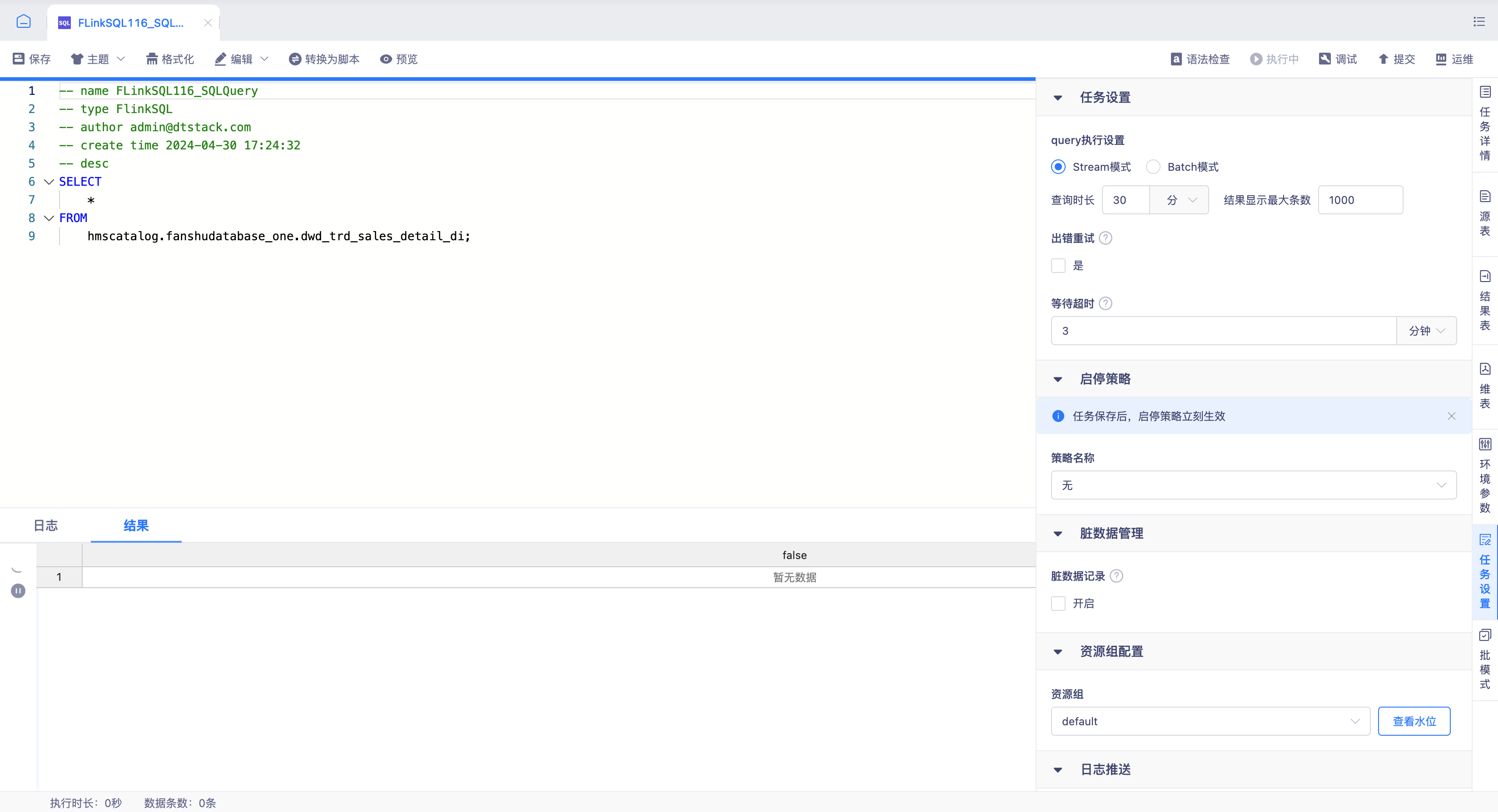
通过实时平台FLinkSQL任务提供的查询Paimon表插入数据,FLinkSQL SqlQuery功能构建Select查询语句使用执行方式,通过流模式实时查询Paimon表采集插入数据情况。