表管理
该功能专业版、旗舰版支持
功能介绍
表管理与Catalog管理为上下级管理,Catalog管理针对Catalog、Database做管理,表管理主要针对HMCatalog、DTCatalog下的Table进行管理,支持对表的新增、编辑、删除、查看等功能。
配置湖表
Paimon
Paimon配置完成后,您就可以在作业中引用Paimon表信息,作为源表、结果表和维表时,无需在声明表的DDL。 SQL命令方式中,您可以直接使用Paimon表名称的完整格式HMSCatalog.Database.Table
创建Paimon表
当前支持脚本模式创建Paimon表,平台给出建表Demo可在Demo基础上修改,with参数中不定义connector则默认使用Catalog中配置的湖表类型。
Paimon建表Demo
CREATE TABLE Paimon_test
(
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh)
WITH(
'bucket' = '2',
'bucket-key' = 'user_id'
);WITH参数
更加详细的介绍请参见Apache Paimon官方文档
| 参数 | 说明 | 数据类型 | 是否必填 | 默认值 | 备注 |
|---|---|---|---|---|---|
| connector | 表类型 | String | False | 无 | 不指定则使用Catalog管理中的湖表类型 |
| path | 表存储路径 | String | False | 无 | 无需填写,FLink默认组装 |
| auto-create | 创建Paimon临时表时,若指定路径不存在Paimon表文件,是否自动创建文件 | Boolean | False | True | 参数取值如下:false(默认):如果指定路径不存在Paimon表文件,则报错。true:如果指定路径不存在,则Flink系统自动创建Paimon表文件。 |
| bucket | 每个分区的分桶数 | Integer | False | 1 | 写入Paimon表的数据将按bucket-key打散至每个bucket中 |
| bucket-key | 分桶关键列 | String | False | 无 | 指定将写入Paimon表的数据按哪些列的值打散至不同的Bucket中。 列名之间用英文逗号(,)分隔,例如'bucket-key' = 'order_id,cust_id'会将数据按order_id列和cust_id列的值进行打散。如果该参数未填写,则按primary key进行打散。如果Paimon表未指定primary key,则按所有列的值进行打散。 |
| changelog-producer | 增量数据产生机制 | String | False | none | Paimon可以为任意输入数据流产生完整的增量数据(所有的update_after数据都有对应的update_before数据),方便下游消费者。增量数据产生机制的可选值如下:none(默认值):不额外产生增量数据。下游仍然可以流读Paimon表,但读到的增量数据是不完整的(只有update_after数据,没有对应的update_before数据)。 input:将输入数据流双写至增量数据文件中,作为增量数据。 full-compaction:每次Full Compaction产生完整的增量数据。 lookup:每次commit snapshot前产生完整的增量数据。 |
| full-compaction.delta-commits | Full Compaction最大间隔 | Integer | False | 无 | 该参数指定了每commit snapshot多少次之后,一定会进行一次Full Compaction |
| lookup.cache-max-memory-size | Paimon维表的内存缓存大小 | String | False | 256 MB | 该参数值会同时影响维表缓存大小和lookup changelog-producer的缓存大小,两个机制的缓存大小都由该参数配置 |
| merge-engine | 相同primary key数据的合并机制 | String | False | deduplicate | 参数取值如下:deduplicate:仅保留最新一条。partial-update:用最新数据中非null的列更新相同primary key的现有数据,其它列保持不变。 aggregation:通过指定聚合函数进行预聚合。 |
| partial-update.ignore-delete | 在partial-update合并机制中,是否忽略delete消息 | Boolean | False | false | 参数取值如下: true:忽略delete消息。 false:碰到delete消息,Flink系统会报错。 |
| partition.default-name | 分区默认名称 | String | False | DEFAULT_PARTITION | 如果分区列的值为null或空字符串,将会采用该默认名称作为分区名。 |
| partition.expiration-check-interval | 多久检查一次分区过期 | String | False | 1h | 无 |
| partition.expiration-time | 分区的过期时长 | String | False | 无 | 当一个分区的存活时长超过该值时,该分区将会过期,默认永不过期。 一个分区的存活时长由该分区的分区值计算而来 |
| partition.timestamp-formatter | 将时间字符串转换为时间戳的格式串 | String | False | 无 | 设置从分区值提取分区存活时长的格式 |
| partition.timestamp-pattern | 将分区值转换为时间字符串的格式串 | String | False | 无 | 设置从分区值提取分区存活时长的格式 |
| scan.bounded.watermark | 当Paimon源表产生的数据的watermark超过该值时,Paimon源表将会结束产生数据。 | Long | False | 无 | 详情请参见Paimon源表消费点位设置 |
| scan.mode | 指定Paimon源表的消费位点。 | String | False | default | 详情请参见Paimon源表消费点位设置 |
| scan.snapshot-id | 指定Paimon源表的消费位点。 | Integer | False | 无 | 详情请参见Paimon源表消费点位设置 |
| scan.timestamp-millis | 指定Paimon源表从哪个时间点开始消费。 | Integer | False | 无 | 详情请参见Paimon源表消费点位设置 |
| write-mode | Paimon表的写入模式。 | String | False | change-log | 参数取值如下:change-log:Paimon表支持根据primary key进行数据的插入、删除和更新。 append-only:Paimon表只接受数据的插入,且不支持primary key。该模式比change-log模式更加高效。 |
| scan.parallelism | Paimon源表的并发度。 | Integer | False | 无 | 无 |
| sink.parallelism | Paimon结果表的并发度 | Integer | False | 无 | 无 |
- Paimon源表消费点位设置
您可以通过scan.mode参数设置Paimon源表的消费位点。scan.mode参数的可选值以及行为如下,更加详细的介绍请参见Apache Paimon官方文档
| 参数值 | 批读 | 流读 |
|---|---|---|
| latest-full | 产出表的最新snapshot。 | 作业启动时,首先产出表的最新snapshot,之后持续产出增量数据。 |
| compacted-full | 产出表最近一次compact后的snapshot。 | 作业启动时,首先产出表最近一次compact后的snapshot,之后持续产出增量数据。 |
| latest | 与latest-full相同。 | 作业启动时不产出表的最新snapshot,之后持续产出增量数据。 |
| from-timestamp | 产出表在scan.timestamp-millis之前(含)的最新snapshot。 | 作业启动时不产出snapshot,之后持续产出从scan.timestamp-millis开始(含)的增量数据 |
| from-snapshot | 产出表的snapshot,snapshot编号由scan.snapshot-id指定。 | 作业启动时不产出snapshot,之后持续产出从scan.snapshot-id开始(含)的增量数据。 |
| from-snapshot-full | 与from-snapshot相同。 | 作业启动时产出表的snapshot,snapshot编号由scan.snapshot-id指定,之后持续产出从scan.snapshot-id开始(不含)的增量数据。 |
- Paimon结果表数据新鲜度与一致性保证
Paimon结果表使用两阶段提交协议,在每次Flink作业的checkpoint期间提交写入的数据,因此数据新鲜度即为Flink作业的checkpoint间隔。每次提交将会产生至多两个snapshot。
当两个Flink作业同时写入一张Paimon表时,如果两个作业的数据没有写入同一个分桶,则能保证serializable级别的一致性。如果两个作业的数据写入了同一个分桶,则只能保证snapshot isolation级别的一致性。也就是说,表中的数据可能混合了两个作业的结果,但不会有数据丢失。
- Paimon结果表数据合并机制
当Paimon结果表收到多条具有相同primary key的数据时,为了保持primary key的唯一性,Paimon结果表会将这些数据合并成一条数据。通过指定merge-engine参数,您可以指定数据合并的具体行为。数据合并机制详情如下表所示。
| 合并机制 | 详情 |
|---|---|
| 去重(Deduplicate) | 去重机制(deduplicate)是默认的数据合并机制。对于多条具有相同primary key的数据,Paimon结果表仅会保留最新一条数据,并丢弃其它具有primary key的数据。说明 :如果最新一条数据是一条delete消息,所有具有该primary key的数据都将被丢弃。 |
| 部分更新(Partial Update) | 通过指定部分更新机制(partial-update),您可以通过多条消息对数据进行逐步更新,并最终得到完整的数据。具体来说,具有相同primary key的新数据将会覆盖原来的数据,但值为null的列不会进行覆盖。 例如,假设Paimon结果表按顺序收到了以下三条数据:<1, 23.0, 10, NULL><1, NULL, NULL, 'This is a book'><1, 25.2, NULL, NULL>第一列是primary key,则最终结果为<1, 25.2, 10, 'This is a book'>。 说明 :如果需要流读partial-update的结果,必须将changelog-producer参数设置为lookup或full-compaction。 partial-update无法处理delete消息。您可以设置partial-update.ignore-delete参数以忽略delete消息。 |
| 预聚合(Aggregation) | 部分场景下,可能只关心聚合后的值。预聚合机制(aggregation)将具有相同primary key的数据根据您指定的聚合函数进行聚合。对于不属于primary key的每一列,都需要通过fields.<field-name>.aggregate-function指定一个聚合函数,否则该列将默认使用last_non_null_value聚合函数。例如,考虑以下Paimon表的定义。price列将会根据max函数进行聚合,而sales列将会根据sum函数进行聚合。给定两条输入数据 <1, 23.0, 15>和 <1, 30.2, 20>,最终结果为<1, 30.2, 35>。当前支持的聚合函数与对应的数据类型如下:sum:支持DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT和DOUBLE。min和max:支持DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP和TIMESTAMP_LTZ。last_value和last_non_null_value:支持所有数据类型。listagg:支持STRING。 bool_and和bool_or:支持BOOLEAN。 说明: 只有sum函数支持回撤与删除数据,其它聚合函数不支持回撤与删除。如果您需要某些列忽略回撤与删除消息,可以设置'fields.${field_name}.ignore-retract'='true'。 如果需要流读aggregation的结果,必须将changelog-producer参数设置为lookup或full-compaction。 |
- Paimon支持查询系统表
表指定的系统表包含有关每个表的元数据和信息,例如创建的快照和正在使用的选项。用户可以使用批量查询访问系统表。
在某些情况下,表名需要用反引号引起来以避免语法解析冲突,例如三重访问模式: SELECT * FROM my_catalog.my_db.my_table$snapshots;
实时计算内部执行需要用Catalog.Database.table的方式。
| 支持查询系统表 | 查询语法 | 描述 |
|---|---|---|
| Snapshots Table | SELECT * FROM my_table$snapshots; | 通过快照表可以查询表的快照历史信息,包括快照发生的记录数。 |
| Schemas Table | SELECT * FROM my_table$schemas; | 通过schemas表查询表的历史模式。 |
| Options Table | SELECT * FROM my_table$options; | 通过 options 表可以查询 DDL 中指定的表的选项信息,未显示的选项将为默认值。 |
| Audit log Table | SELECT * FROM my_table$audit_log; | 如果需要审计表的changelog,可以使用audit_log系统表,通过audit_logtable可以获取到rowkind表的增量数据时的列,可以利用该列进行过滤等操作,完成审计。 |
| Files Table | SELECT * FROM my_table$files; | 可以查询具有特定快照的表的文件。 |
| Tags Table | SELECT * FROM my_table$tags; | 通过 tags 表可以查询该表的标签历史信息,包括标签所基于的快照以及快照的一些历史信息。还可以获取所有标签名称以及通过名称追溯到特定标签的数据。 |
| Consumers Table | SELECT * FROM my_table$consumers; | 您可以查询包含下一个快照的所有消费者。 |
| Manifests Table | SELECT * FROM my_table$manifests; | 可以查询当前表的最新快照或指定快照包含的所有清单文件。 |
| Aggregation fields Table | SELECT * FROM my_table$aggregation_fields; | 可以通过聚合字段表查询表的历史聚合情况。 |
| Partitions Table | SELECT * FROM my_table$partitions; | 可以查询该表的分区文件。 |
Iceberg
Iceberg配置完成后,您就可以在作业中引用Iceberg表信息,作为源表、结果表和维表时,无需在声明表的DDL。 SQL命令方式中,您可以直接使用Iceberg表名称的完整格式HMSCatalog.Database.Table
创建Iceberg表
当前支持脚本模式创建Iceberg表,平台给出建表Demo可在Demo基础上修改,with参数中不定义connector则默认使用Catalog中配置的湖表类型。
Iceberg建表Demo
CREATE TABLE iceberg_test
(
order_uid string PRIMARY KEY NOT ENFORCED COMMENT '订单uid'
, real_price bigint COMMENT '实付金额'
, order_channel bigint COMMENT '订单渠道'
, create_time timestamp(3) COMMENT '创建时间'
, update_time timestamp(3) COMMENT '更新时间'
)
COMMENT '订单表'
PARTITIONED BY (order_channel)
WITH (
'connector' = 'iceberg',
'write-format' = 'parquet',
'upsert-enabled'='true'
);
- WITH参数
更加详细的介绍请参见Apache Iceberg官方文档
| 参数 | 说明 | 备注 |
|---|---|---|
| connector | 表类型 | 不指定则使用Catalog管理中的湖表类型 |
| path | 表存储路径 | 无需填写 |
| write-format | 写入格式 | 此写入操作使用的文件格式;parquet、avro 或 orc |
| target-file-size-bytes | 目标文件大小字节 | 覆盖此表的 write.target-file-size-bytes |
| upsert-enabled | 启用 upsert | 覆盖此表的 write.upsert.enabled |
| overwrite-enabled | 启用覆盖 | 覆盖表的数据,配置使用 UPSERT 数据流时不应启用覆盖模式 |
| distribution-mode | 分配模式 | 覆盖此表的 write.distribution-mode |
| compression-codec | 压缩编解码器 | 覆盖此表的压缩编解码器以进行此写入 |
| compression-level | 压缩级别 | 覆盖此表的 Parquet 和 Avro 表的压缩级别以进行此写入 |
| compression-strategy | 压缩策略 | 针对此写入覆盖此表的 ORC 表的压缩策略 |
| write-parallelism | 写并行 | 覆盖写入器并行性 |
Hudi
Hudi配置完成后,您就可以在作业中引用Hudi表信息,作为源表、结果表和维表时,无需在声明表的DDL。 SQL命令方式中,您可以直接使用Hudi表名称的完整格式HMSCatalog.Database.Table
创建Hudi表
当前支持脚本模式创建Hudi表,平台给出建表Demo可在Demo基础上修改,with参数中不定义connector则默认使用Catalog中配置的湖表类型。
Hudi建表Demo
CREATE TABLE hudi_test
(
order_uid string PRIMARY KEY NOT ENFORCED COMMENT '订单uid'
, real_price bigint COMMENT '实付金额'
, order_channel bigint COMMENT '订单渠道'
, create_time timestamp(3) COMMENT '创建时间'
, update_time timestamp(3) COMMENT '更新时间'
)
COMMENT '订单表'
PARTITIONED BY (order_channel)
WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'write.operation' = 'upsert'
);
- WITH参数 hudi-flink 模块为 hudi source 和 sink 定义了 Flink SQL 连接器。sink 表有多种选项可用:
更加详细的介绍请参见Apache Hudi官方文档
| 参数 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| connector | 表类型 | Hudi | 不指定则使用Catalog管理中的湖表类型 |
| path | 表存储路径 | 无 | 无需填写,FLink默认组装 |
| table.type | 表类型 | COPY_ON_WRITE | 要写入的表的类型。COPY_ON_WRITE(或)MERGE_ON_READ |
| write.operation | 写操作 | upsert | 本次写入应该执行的写入操作(支持插入或更新插入) |
| write.precombine.field | 写入预合并字段 | ts | 实际写入之前预合并中使用的字段。当两个记录具有相同的键值时,我们将选择具有最大值的记录作为预合并字段,由 Object.compareTo(..) 确定 |
| write.payload.class | 写入payload类 | OverwriteWithLatestAvroPayload.class | 使用的 Payload 类。如果您希望在更新/插入时采用自己的合并逻辑,请覆盖此项。这将使为该选项设置的任何值无效 |
| write.insert.drop.duplicates | 写入插入删除重复项 | false | 标记是否在插入时删除重复项。默认情况下,插入将接受重复项,以获得额外的性能 |
| write.ignore.failed | 写入忽略失败 | true | 标记是否忽略检查点批次内的任何非异常错误(例如 writestatus 错误)。默认情况下为 true(有利于流式传输而不是数据完整性) |
| hoodie.datasource.write.recordkey.field | hoodie数据源写入记录键字段 | uuid | 记录关键字段。用作 的recordKey组件的值HoodieKey。实际值将通过对字段值调用 .toString() 来获取。可以使用点符号指定嵌套字段,例如:a.b.c |
| hoodie.datasource.write.keygenerator.class | hoodie密钥生成器类 | SimpleAvroKeyGenerator.class | 密钥生成器类,实现将从传入记录中提取密钥 |
| write.tasks | 并行度 | 4 | 执行实际写入的任务的并行度,默认值为 4 |
| write.batch.size.MB | 写入批次大小 | 128 | 用于将数据刷新到底层文件系统的批处理缓冲区大小(以 MB 为单位) |
如果表类型为MERGE_ON_READ,还可以通过options指定异步compaction策略:
| 参数 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| compaction.async.enabled | 压缩异步启用 | true | 异步压缩,MOR 默认启用 |
| compaction.trigger.strategy | 压缩触发策略 | num_commits | 触发压缩的策略,选项为 'num_commits':达到 N 个增量提交时触发压缩;'time_elapsed':自上次压缩以来经过的时间 > N 秒时触发压缩;'num_and_time':当同时满足 NUM_COMMITS 和 TIME_ELAPSED 时触发压缩;'num_or_time':当满足 NUM_COMMITS 或 TIME_ELAPSED 时触发压缩。默认值为 'num_commits' |
| compaction.delta_commits | 压缩delta_commits | 5 | 触发压缩所需的最大增量提交,默认为 5 次提交 |
| compaction.delta_seconds | 压缩delta_seconds | 3600 | 触发压缩所需的最大增量秒数,默认 1 小时 |
配置映射表
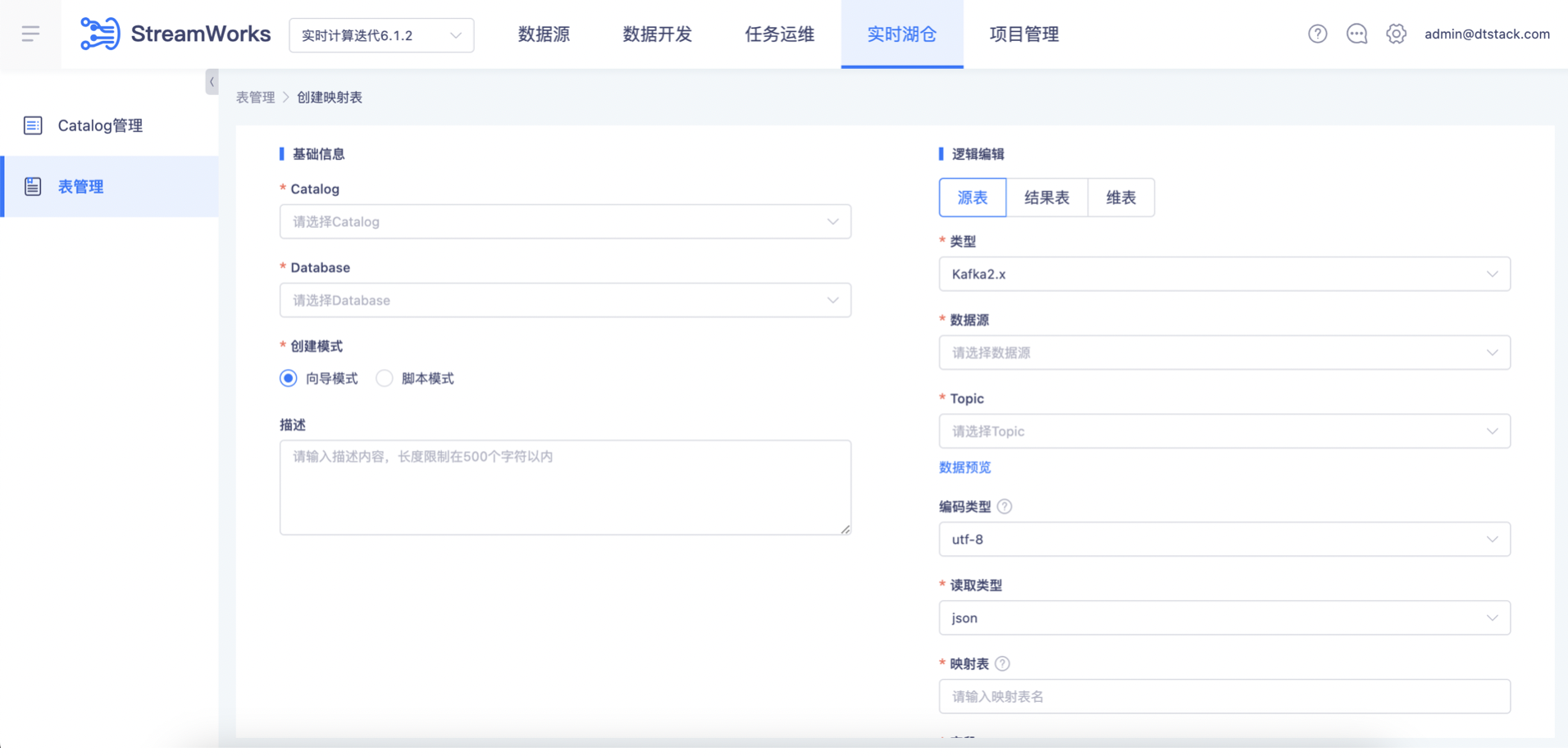
源表
源表配置完成后,您就可以在作业中引用源表信息,作为源表时,无需在声明表的DDL。 SQL命令方式中,您可以直接使用源表名称的完整格式DTCatalog.Database.Table。
- 源表支持范围:Kafka、HW-Kafka
- 配置Kafka源表Demo
-- dtcatalog 代表Catalog层名称
-- dtdatabase 代表Database层名称
-- souceTable 代表Table层表名称
CREATE TABLE dtcatalog.dtdatabase.sourceTable (
id INT,
name VARCHAR(2147483647),
age INT,
proc_time AS PROCTIME()
) WITH (
'format' = 'json',
'scan.startup.mode' = 'latest-offset',
'properties.bootstrap.servers' = '172.16.100.109:9092',
'connector' = 'kafka-x',
'scan.parallelism' = '1',
'topic' = 'dtstream_one'
)
维表
维表配置完成后,您就可以在作业中引用维表信息,作为维表时,无需在声明表的DDL。 SQL命令方式中,您可以直接使用维表名称的完整格式DTCatalog.Database.Table。
维表支持范围:Mysql、Oracle、ES7
配置Mysql维表Demo
-- dtcatalog 代表Catalog层名称
-- dtdatabase 代表Database层名称
-- mysqlSideTable 代表Table层表名称
CREATE TABLE dtcatalog.dtdatabase.mysqlSideTable (
sink_id INT NOT NULL,
sink_name VARCHAR(2147483647),
sink_start_time TIME(0),
sink_school VARCHAR(2147483647),
sink_message VARCHAR(2147483647),
sink_end_time TIMESTAMP(6),
CONSTRAINT PK_2094638694 PRIMARY KEY (sink_id) NOT ENFORCED
) WITH (
'lookup.cache.max-rows' = '10000',
'password' = '******',
'url' = 'jdbc:mysql://172.16.100.186:3306/automation',
'connector' = 'mysql-x',
'lookup.cache-type' = 'LRU',
'lookup.parallelism' = '1',
'vertx.worker-pool-size' = '5',
'lookup.cache.ttl' = '60000',
'table-name' = '4tablejoin_resulttable',
'username' = 'drpeco'
)
结果表
结果表支持范围:Kafka、HW-Kafka、Mysql、Oracle
结果表配置完成后,您就可以在作业中引用结果表信息,作为结果表时,无需在声明表的DDL。 SQL命令方式中,您可以直接使用结果表名称的完整格式DTCatalog.Database.Table。
结果表支持范围:Mysql、Oracle、ES7
配置Mysql结果表Demo
-- dtcatalog 代表Catalog层名称
-- dtdatabase 代表Database层名称
-- mysqlSideTable 代表Table层表名称
CREATE TABLE dtcatalog.dtdatabase.mysqlResultTable (
id INT NOT NULL,
name VARCHAR(255),
start_time TIMESTAMP(6),
end_time TIMESTAMP(6),
CONSTRAINT PK_3386 PRIMARY KEY (id) NOT ENFORCED
) WITH (
'sink.buffer-flush.interval' = '1000',
'sink.buffer-flush.max-rows' = '100',
'url' = 'jdbc:mysql://172.16.100.186:3306/automation',
'password' = '******',
'connector' = 'mysql-x',
'sink.all-replace' = 'false',
'table-name' = '4tablejoin_sidetwo',
'sink.parallelism' = '1',
'username' = 'drpeco'
)
表详情
展示表的基础信息例如表类型、表目录、创建用户(仅平台内创建才有,其他平台构建的表不存在)、创建时间、映射源(Catalog.Database)、描述
建表逻辑
展示表的构建逻辑语句,目前以脚本模式展示
应用任务
展示表与FlinkSQL任务被应用的关系,同时表应用中展示了表的状态信息,例如:开发中、等待提交、提交中、提交失败、等待运行、运行中、取消、超时取消、运行失败等
湖仓开发与表管理
在【数据开发-表管理】中,可以查看在【实时湖仓】中创建的内容。
然后在IDE中根据实际需要,通过Catalog.database.table的方式进行引用。无需在右侧的表配置中重复定义。
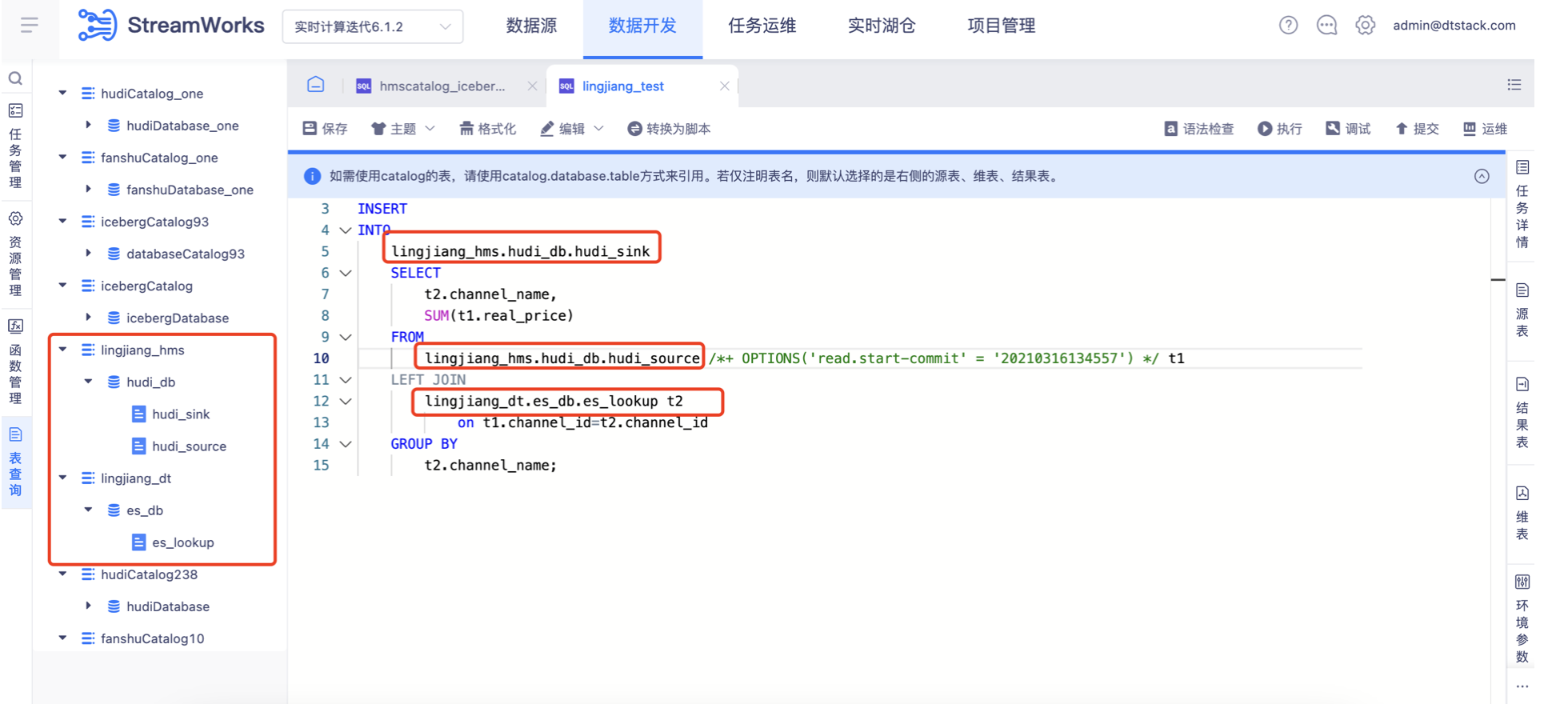
在引用表的时候,如果某个参数在定义表的时候没有维护,可以通过挂载Hints的方式进行补充。比如,最常见的场景:
某张湖表在定义时,仅维护了基础的表结构。但是在读取时,往往需要指定query起点,这时候就可以在表名后挂载Hints,指定具体的commit信息。当然,每种湖表的参数定义均不一致,详情可以参考下面的链接: Flink Hints的用法:https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/sql/queries/hints/
数据开发-支持通过后端配置项控制表操作的范围,当前默认支持操作三种湖表,另支持操作其他非湖表类型的表。 IDE执行时超出表的操作范围时提示权限不足。
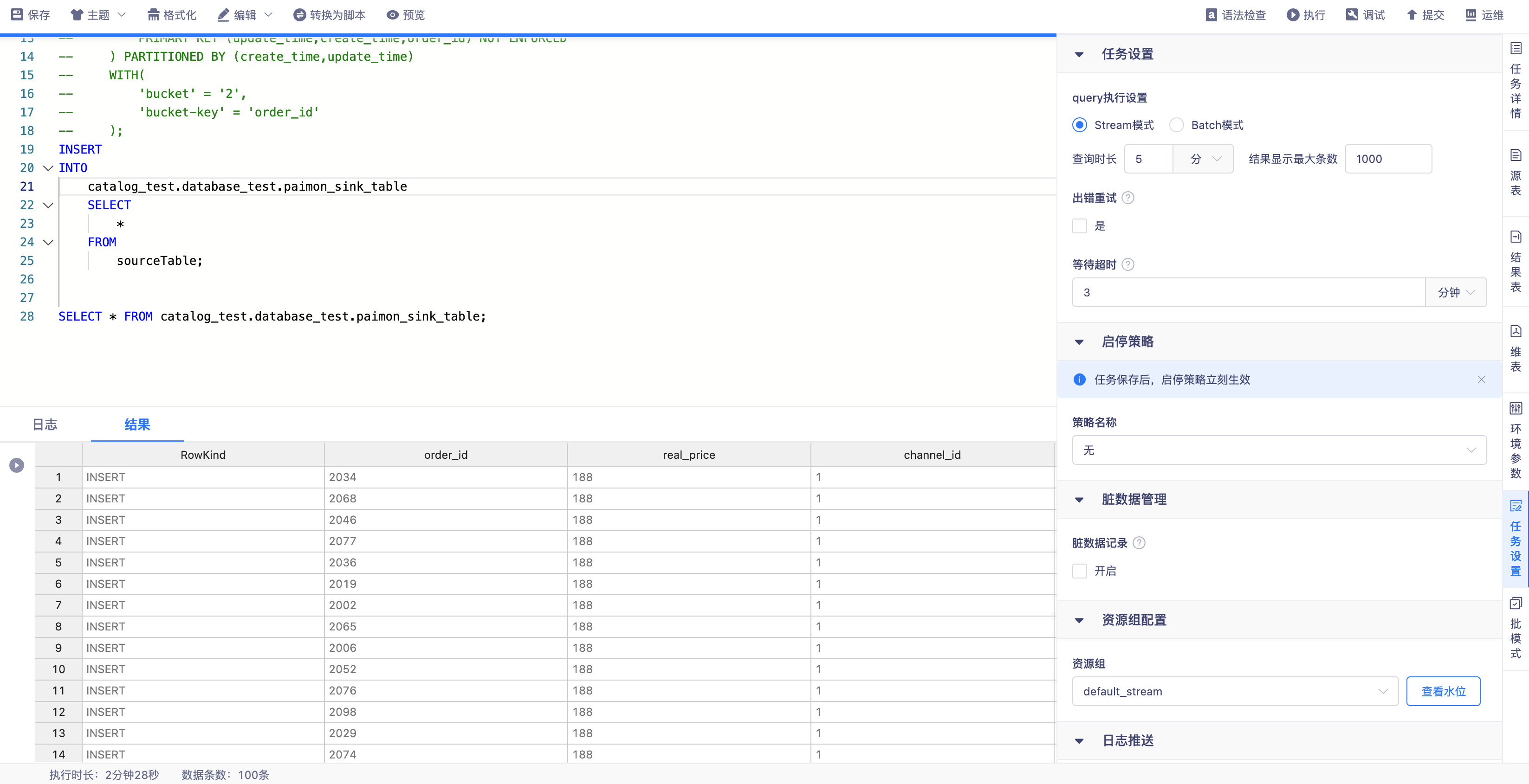
SQL Query 查询数据
在【数据开发】任务设置中支持SQL Query执行配置,支持配置流批模式查数据。
- 【Stream模式】
- 任务以流模式查数据
- 查询时长:以任务开始在flink引擎上执行作为计算起点,当查询时间达到此处设置上限时自动停止查询
- 结果最大显示条数:即当查询到的数据条数满足设置值时数据总量不再增加,新的数据覆盖最早的数据
- 支持数据源:
- 映射表:kafka、mysql、oracle
- 湖表:iceberg、hudi、paimon
- 【Batch模式】
- 任务以批模式查数据,数据查完后暂存,一次性返回至平台展示,支持结果下载,下载功能同stream模式
- 查询时长:查询时间达到此处设置上限时自动停止查询,若在此时间内数据返回结束则打印结果,否则结果为空
- 结果最大显示条数:查询/下载结果上限为此处设置的条数
- 支持数据源:
- 映射表:kafka、mysql、oracle
- 湖表:iceberg、hudi、paimon
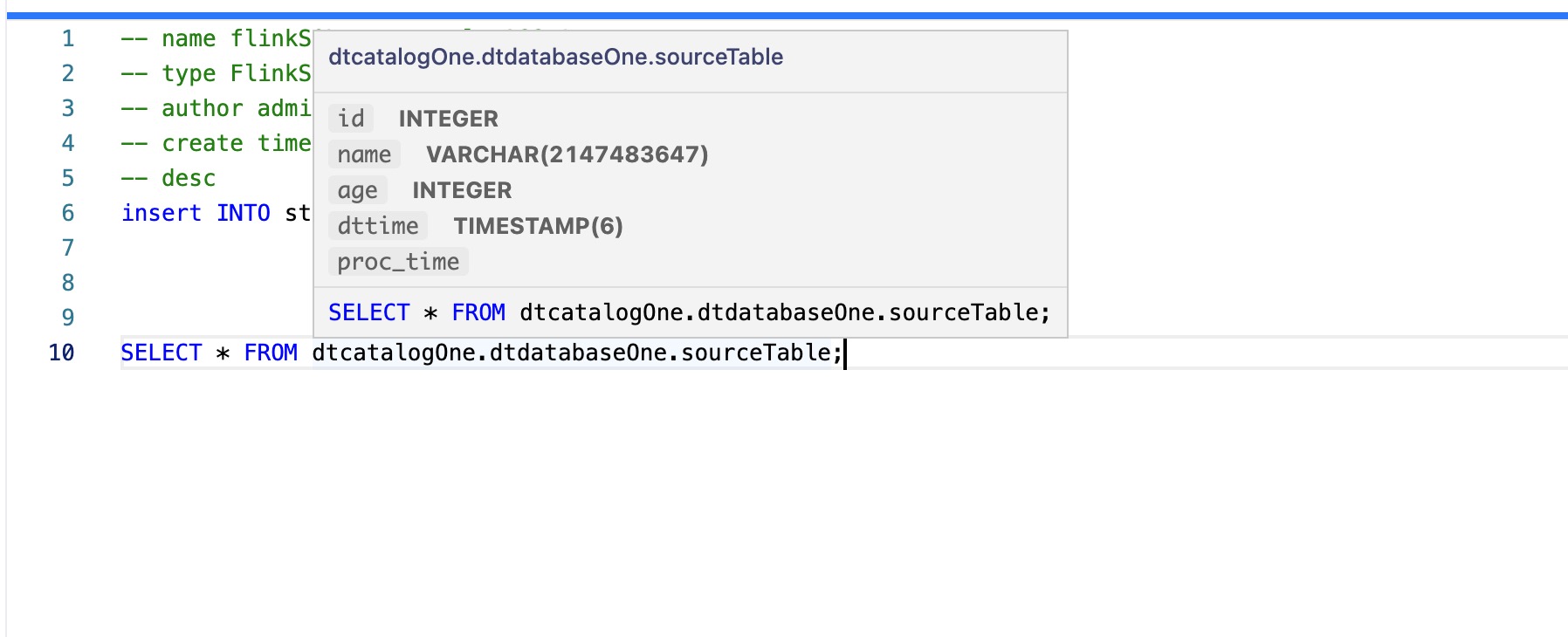
IDEA 编辑器
数据开发在FLinkSQL开发过程中支持通过Catalog.Database.Table的方式显示DTCatalog、HMSCatalog移入表名时返回表字段、字段类型信息,更加快捷高效的开发SQL。
参考文档
Paimon湖表:
所有参数——https://paimon.apache.org/docs/master/maintenance/configurations/
Hudi湖表:
常用参数——https://hudi.apache.org/docs/basic_configurations#FLINK_SQL
所有参数——https://hudi.apache.org/docs/configurations#Flink-Options
Iceberg湖表:
常用参数——https://iceberg.apache.org/docs/latest/flink-queries/
所有参数——https://iceberg.apache.org/docs/latest/flink-configuration/#read-options