项目管理
「项目」组成了离线开发的基本单元,一个项目是一组资源的集合,例如为了统计某个APP的活跃用户情况,需要多位开发人员根据业务需求创建不同的离线任务,那么这组用户、由这组用户创建的任务等等资源,可以理解为一个"项目"。
每个项目之间是彼此独立的,不同项目间的数据是隔离的
一个项目内包含的内容包括:
- 一个项目对接到底层引擎的一个Schema
- 一组用户
- 一组任务/脚本,及其配置
- 这些任务相关的任务实例、告警配置等信息
项目与Database/Schema的关系
不同数据库的Database和Schema有明显的概念区分,这里以Hive的Database做举例,对于MySQL或其他引擎,一个项目对接的是一个Database下的Schema,读者需按情况区分。
离线开发已支持对接到Hive、Impala等不同类型的引擎,用户在新建项目时,需指定所连接的底层引擎的Schema,一个项目会连接一个Schema,且创建之后不可变更。从这个角度上,可以理解为"一个项目就是一个Schema"。
这种映射模式与数据开发过程中的操作过程是类似的,都是从Schema->表的视角,在后续的运维环节与这里的项目概念相一致,一次维护一个Schema中的表的数据。
支持的计算引擎
| 计算引擎 | 元数据获取 | 存储过程调用 | 存储过程管理(创建、编辑及删除) | UDF注册 | 数据管理 | 数据权限 |
|---|---|---|---|---|---|---|
| Spark | SparkThriftServer/HiveServer | - | 否 | 是 | 是 | 由离线开发控制 |
| Hive | SparkThriftServer/HiveServer | - | 否 | 是 | 是 | 由离线开发控制 |
| Impala SQL | SparkThriftServer/HiveServer | - | 否 | 否 | 是 | 由离线开发控制 |
| Inceptor SQL | SparkThriftServer/HiveServer | 是 | 否 | 否 | 是 | 数据库控制 |
| Flink(同步任务引擎) | - | - | - | - | - | - |
| GaussDB SQL | JDBC | 否 | 否 | 否 | 否 | 数据库控制 |
| Oracle SQL | JDBC | 是 | 否 | 否 | 否 | 数据库控制 |
| TiDB SQL | JDBC | 否 | 否 | 否 | 是 | 数据库控制 |
| Greenplum SQL | JDBC | 是 | 是 | 是 | 是 | 数据库控制 |
| Trino SQL | JDBC | 否 | 否 | 否 | 否 | 数据库控制 |
| MySQL | JDBC | 否 | 否 | 否 | 否 | 数据库控制 |
| SQL Server | JDBC | 是 | 否 | 否 | 否 | 数据库控制 |
| Hana SQL | JDBC | 否 | 否 | 否 | 否 | 数据库控制 |
| AnalyticDB PostgreSQL | JDBC | 否 | 否 | 是 | 是 | 数据库控制 |
| StarRocks SQL | JDBC | 是 | 是 | 是 | 是 | 数据库控制 |
| HashData SQL | JDBC | 是 | 是 | 是 | 是 | 数据库控制 |
| Doris SQL | JDBC | 否 | 否 | 是 | 是 | 数据库控制 |
项目总览
有2种查看项目的方式:
- 用户登录成功后停留的页面,可查看其置顶的各个项目,同时可进入任意一个项目操作。
- 在任意页面,点击产品页面左上角的LOGO,页面跳转至离线开发首页,点击”
项目列表“后可以浏览当前用户管理、参与的所有项目。
创建项目
创建项目有2种方式,第一是创建一个新的Schema,另一种是对接到已存在的Schema上,点击「项目列表」页面,点击「创建项目」按钮,进入创建项目页面
项目基本信息
- 项目标识:不超过64个字符,由字母、数字和下划线组成,且只能由英文字母开头
- 项目名称:在项目选择等页面的显示名称,可填写中文、字母、数字等字符
- 项目类目:项目比较多的时候,可以通过建立多级项目类目,直观管理项目
- 项目所有者:需指配一个用户作为项目所有者
- 项目描述:不超过200字符,字符类型不限制
高级配置
启动周期调度:开启后,本项目每天会定期生成周期实例,默认开启;
下载SELECT结果:开启后,用户可在数据开发模块中,运行临时的SQL查询时,可下载查询结果;
计算引擎配置
离线开发可支持哪些计算引擎,可参考[离线开发支持的计算引擎]
- Spark Thrift Server:离线开发对接Spark Thrift Server,通过Spark Thrift Server的jdbc来获取元数据,并使用Hive Metastore存储元数据。
- Oracle、TiDB、Greenplum:这几种引擎比较类似,均通过jdbc直接获取元数据信息;
- 创建Schema:根据用户填写的项目标识,创建一个新的Schema;
- 对接已有Schema:选择某个现存的Schema,本项目直接对接此Schema,可将已有表的元数据导入本平台进行管理,原系统内的数据本身不会移动或改变,在导入进行过程中,请勿执行表结构变更操作。
项目的初始化
创建项目后,系统会进行项目配置的初始化工作。初始化是一种过渡状态,通常较为短暂。根据选择创建Schema或对接Schema的不同,初始化阶段的主要工作略有差异:
- 创建Schema
- 在数据库中,创建用户指定的Schema;
- 初始化数据(初始化demo任务、数据源、相关目录、系统函数、内置角色等)
- 对接已有Schema
- 连接用户指定的Schema;
- 读取Schema内的全部表信息,包括表名、表名comment、字段、字段comment等信息
- 初始化数据(初始化demo任务、数据源、相关目录、系统函数、内置角色等)
2种初始化场景中,对接已有Schema可能消耗的时间更长,其时间与Schema内已有的表数量高度相关。如果某项目长期处于"初始化"状态,可能在进行元数据同步,若明显超出合理范围,请联系技术支持解决,或需要查看后台运行日志。
数据源的初始化
在创建项目时,系统会根据本项目对接的引擎,自动在「数据源」菜单中创建一个默认数据源,方便用户进行初始化阶段的数据同步。系统默认创建的数据源,在数据源名称后会有  的标识
的标识
项目的状态
当用户在创建项目时,由于初始化工作比较复杂,项目可能会进入不同的状态。
项目可能会存在多种状态:
- 初始化:如果某项目长期处于"
初始化"状态,可能后台在进行元数据同步。 - 正常:项目初始化成功后,会进入正常状态。
- 失败:项目初始化失败,会进入失败状态。
项目删除
在项目列表中,可以对项目进行删除操作。
创建失败的项目,可以直接进行删除。
创建成功的项目,若项目作为测试项目或生产项目,需要解除测试生产项目的绑定才能进行删除。解除绑定后,数据源、自定义参数、资源组等映射关系将会解除。
其他情况下,需要输入项目名称校验完成,可进行删除动作,如下图。
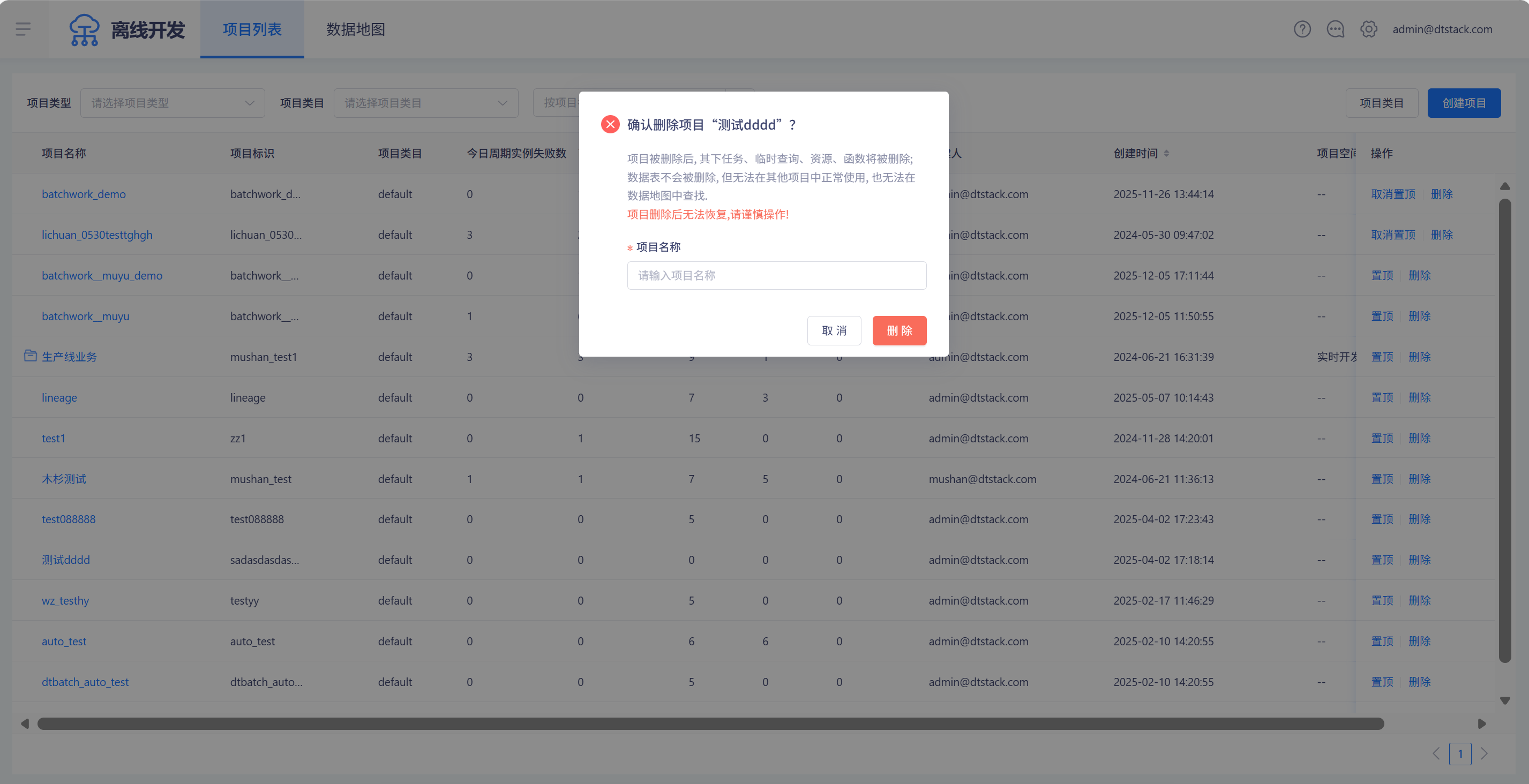
租户管理员、租户所有者、超级管理员才可以创建项目、删除项目。
项目管理
项目角色
每个项目内置6种角色,其功能权限如下表所示:
| 角色名称 | 功能权限描述 |
|---|---|
| 租户所有者 | 本项目内的全部权限,具有本租户内的最高权限。 |
| 项目所有者 | 项目空间的创建者,拥有项目空间内的最高权限,可对该项目空间的基本属性、数据源、当前项目空间的全部资源和项目成员等进行管理,并为项目成员赋予项目管理员、开发、运维、访客角色。 |
| 项目管理员 | 项目空间的管理者,可对该项目空间的基本属性、数据源、当前项目空间的全部资源和项目成员等进行管理,并为项目成员赋予项目管理员、开发、运维、访客角色。项目管理员不能对项目所有者操作。 |
| 数据开发 | 能够创建任务、脚本、资源等,新建/删除表,但不能执行发布操作,不能管理数据源。 |
| 运维 | 由项目管理员分配运维权限;拥有发布任务、运维任务的操作权限,没有数据开发的操作权限。 |
| 访客 | 只具备查看权限,没有权限进行编辑任务、运维等操作。 |
项目成员
项目除了将各类资源集中进行管理与操作外,通常还会有多位用户共同来完成不同的职能。
- 创建项目的用户为"
项目所有者",此外还有项目管理员和普通项目成员,这3类角色都可以创建任务,并管理项目内的资源。 - 每个项目只有一个项目所有者,可以有多位项目管理员,多位普通成员。
- 每个用户可以同时参与多个项目。
- 添加项目成员
项目所有者或项目管理员希望其他用户加入本项目,共同创建、维护任务时,需要将其他用户加入本项目。
- 进入「项目管理→成员管理」
- 点击「添加成员」,输入成员账号进行搜索,并在搜索结果中选择一个或多个用户,为其设定角色,点击「确定」即可
- 移除项目成员
项目所有者/项目管理员认为某用户无需在本项目中继续操作时,可将其移出本项目。
- 进入「项目管理-成员管理」
- 在项目成员列表中点击「移出项目」。某成员被移出项目后,不能在本项目中进行任何操作,但其已创建的任务、已上传的资源不会被删除。
- 改变项目成员的角色
项目所有者想将普通成员置为项目管理员,与其一起管理项目组内的其他成员时,可将其"置为管理员"。相对的,也可以将项目管理员置为普通成员。
- 进入「项目管理-成员管理」
- 在项目成员列表中,分别点击「置为管理员」或「置为普通用户」。
- 管理项目成员的权限
只有项目所有者和项目管理员才可以进行项目成员的管理,普通项目成员没有项目成员管理的权限。
任一项目中,除了项目创建者外,最多有其他2位项目管理员
项目配置
- 启动周期调度:开启后,本项目将会每天生成周期实例。本功能常用于测试/生产环境区分的场景中,在开启了发布模式前提下,测试项目可以关闭周期实例生成功能,节约集群计算资源。
- 下载SELECT结果:开启后,用户在"
数据开发"模块中,通过SQL查询的结果集可以下载到本地,当项目管理员认为本项目需要较高程度的数据安全保护时,可以关闭下载功能,任何用户无法从SQL查询结果集中下载项目数据。 - 发送任务运行情况报告:开启后,用户可设置每天固定时间点通过邮件、短信和钉钉接收到项目级的任务运行情况报告,报告内容包含今天计划的总任务实例数、截止设置的发送时间点运行成功的任务实例、未运行任务实例、失败任务实例、当前总表数和占用总存储数;
- 代码同步:离线可对接代码远端仓库进行代码备份和同步
- 允许ddl操作:开启后,SQL中允许填写DDL语句。
- 同步任务脏数据:数据同步任务中默认脏数据容忍条数和脏数据比例配置
- 自定义目录排序:开启后,任务目录可以自定义拖动排序。关闭后,恢复默认排序(按名称排序),目前仅旗舰版支持该功能
- SQL规范性检查:可在资产配置SQL规范性内容,在离线开启后,任务运行、提交时将会检查SQL内容,目前仅旗舰版支持该功能
元数据同步
在项目创建的初始化阶段,系统会自动同步元数据,若后续用户一直在离线开发内操作,则「数据地图」模块内的表信息会与源库保持一致。若用户绕过离线开发平台,直接操作源库,会造成系统保存的元数据与源库不一致,此时需要进行元数据同步操作。 元数据同步操作入口位于「数据源」菜单,在数据源列表中寻找包含「meta」标识的项目默认数据源(参考[创建项目]),点击「同步元数据」,在打开的页面中观察未同步的元数据信息。
 选择所属类目,设置生命周期,并点击「同步元数据」按钮,完成元数据的同步。元数据同步完成后,用户即可在数据地图中查看已同步过的元数据信息。
选择所属类目,设置生命周期,并点击「同步元数据」按钮,完成元数据的同步。元数据同步完成后,用户即可在数据地图中查看已同步过的元数据信息。
项目级任务运行情况报告
开启项目级任务运行情况报告
在「项目管理->项目设置->操作设置」中点击勾选「发送任务运行情况报告」,就可每日定时通过固定通道发送任务运行整体情况和异常信息,如下图
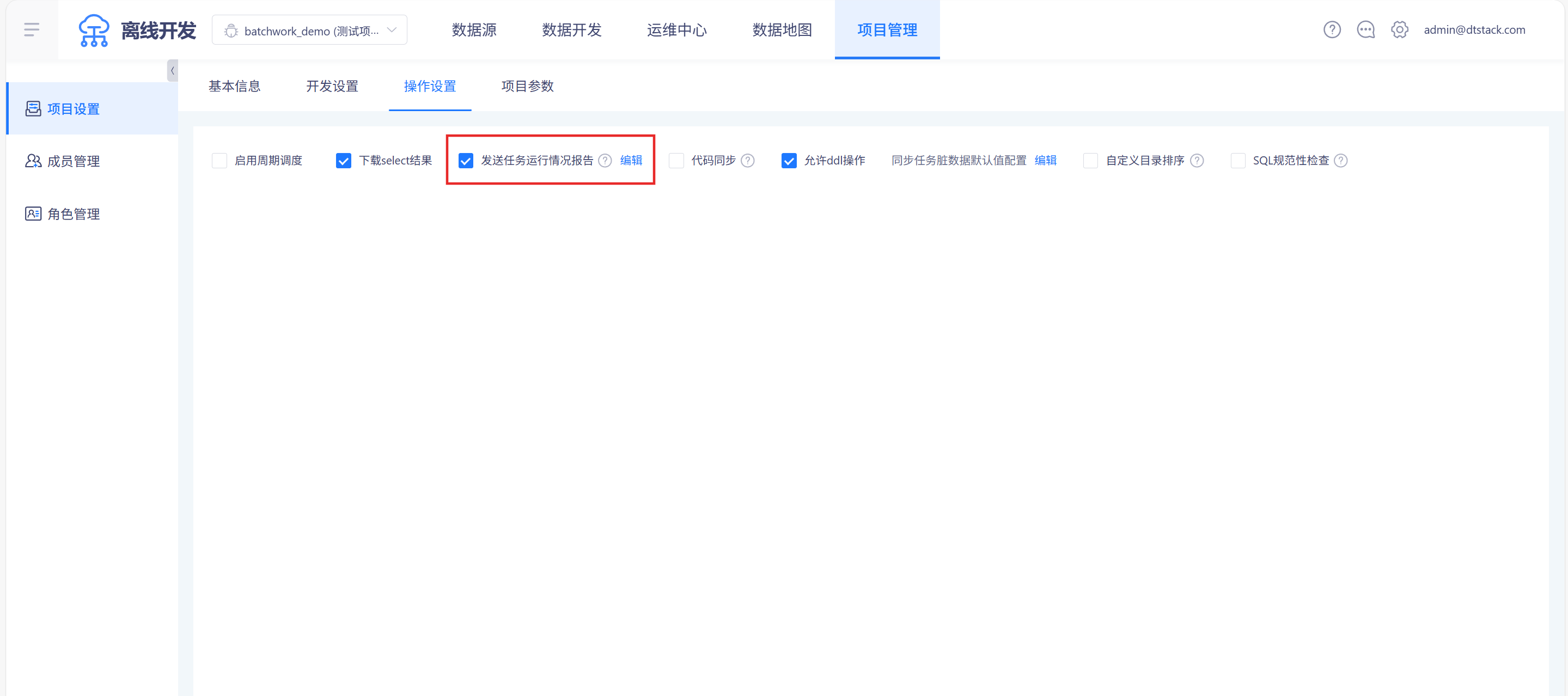
项目级任务运行情况报告配置
点击「发送任务运行情况报告」选项旁的「编辑」按钮,可以对发送时间、接受方式、接收人等信息进行编辑,如下图
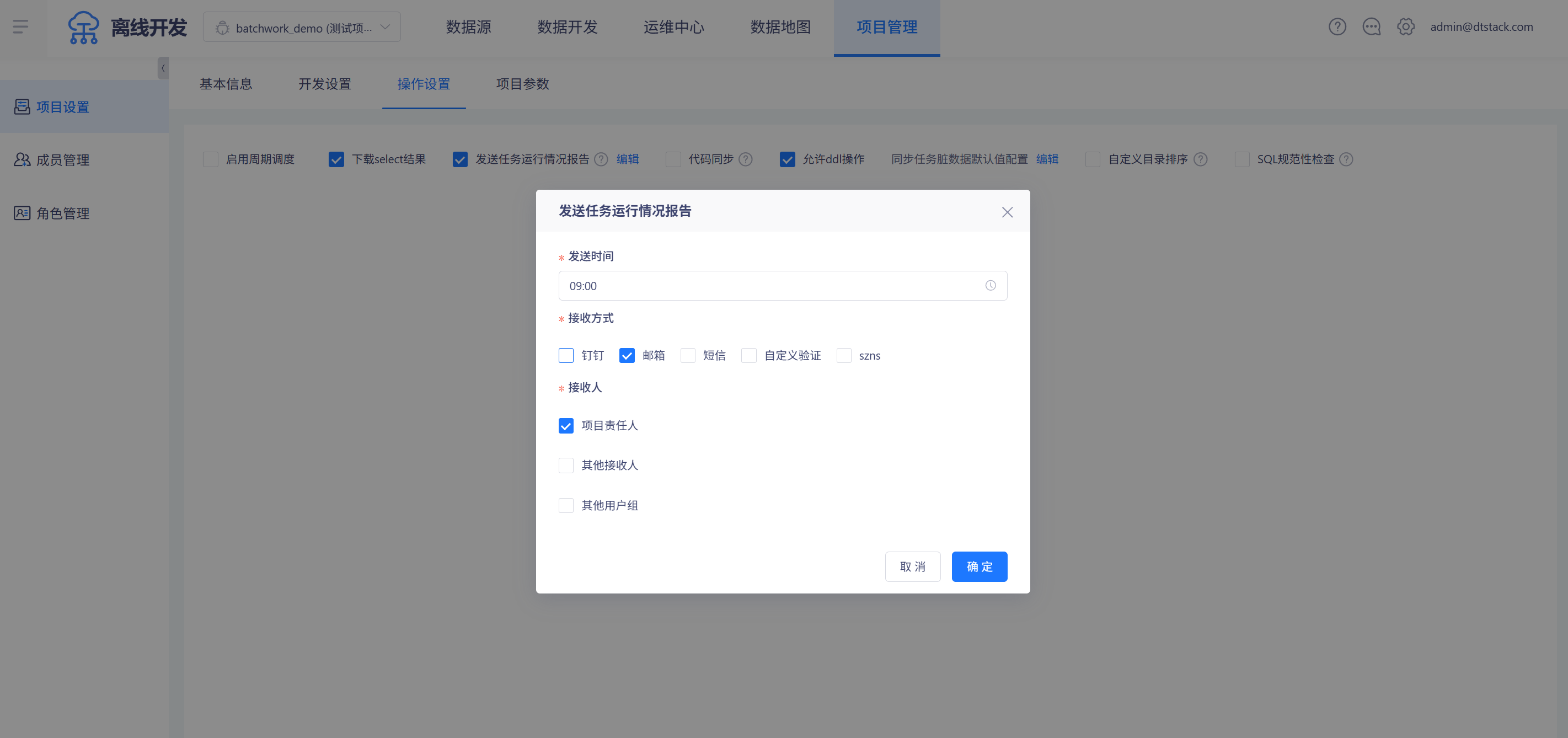
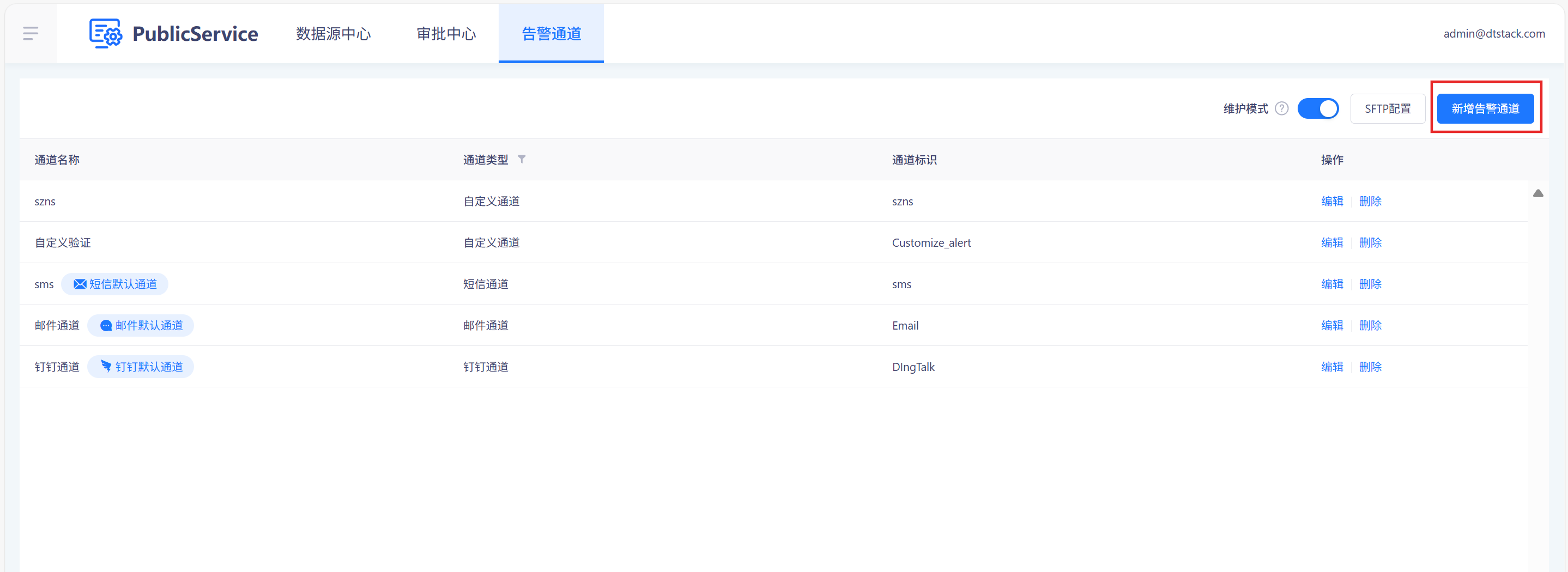
项目级任务运行情况运行报告的接收方式的配置和告警配置的接收方式的配置一致,要在「公共管理->告警通道」中进行配置。如下图
项目及任务运行情况报告模版
【2021年8月11日“项目名称”周期实例运行情况报告】
一、基本信息 项目名称:xxx 所属分类:xxx 所属租户:xxx
项目总表数:100 占用总存储:10GB
项目下所有进数据地图中的表
二、统计时间
2021-08-11 00:00:00 ~ 09:00:00
统计时间:当天0点到报告发送时间点
三、周期实例运行情况
总实例数 1000
未运行 20(2%)
失败 20(2%)
运行中 20(2%)
成功 800(80%)
冻结/取消 10(1%)
四、关键指标明细
失败实例明细
| 任务名称 | 任务类型 | 计划时间 | 责任人 | 状态 |
|---|---|---|---|---|
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 提交失败 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 提交失败 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 提交失败 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 提交失败 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 提交失败 |
列出报告发送时间点所有失败实例(运行失败和提交失败)
运行时长排行
| 任务名称 | 任务类型 | 计划时间 | 责任人 | 运行时长 |
|---|---|---|---|---|
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 10小时20分钟32秒 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 10小时20分钟32秒 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 10小时20分钟32秒 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 10小时20分钟32秒 |
| sparksql | sparksql | 2021-12-01 12:00:00 | cx | 10小时20分钟32秒 |
列出截止报告发生时间点运行时间最久的前10个实例
文件数量最多的前10张表
| 表 | 文件数量 | 占用存储 | 责任人 |
|---|---|---|---|
| table1 | 10000000 | 50T | cx |
| table2 | 1000000 | 50G | cx |
| table3 | 10000 | 50MB | cx |
| table4 | 100 | 50KB | cx |
| table5 | 10 | 50KB | cx |
个人账号的kerberos认证
平台支持对用户或用户组绑定kerberos证书,并支持以用户级/用户组级kerberos账号进行任务提交。
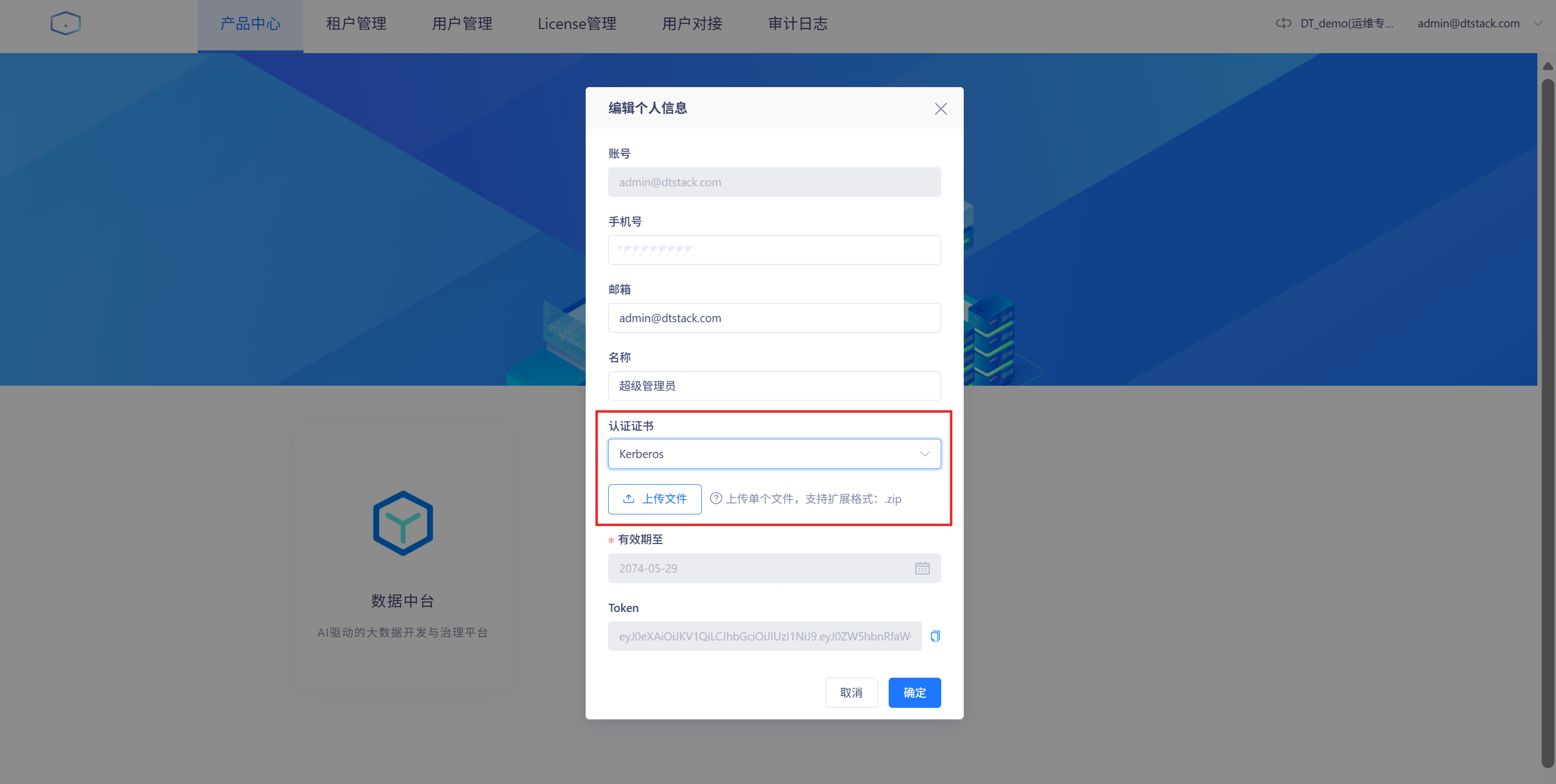
绑定个人账号kerberos认证证书
在「用户中心-个人信息」中,可以上传个人账号的kerberos认证证书,如图所示
绑定用户组kerberos认证证书
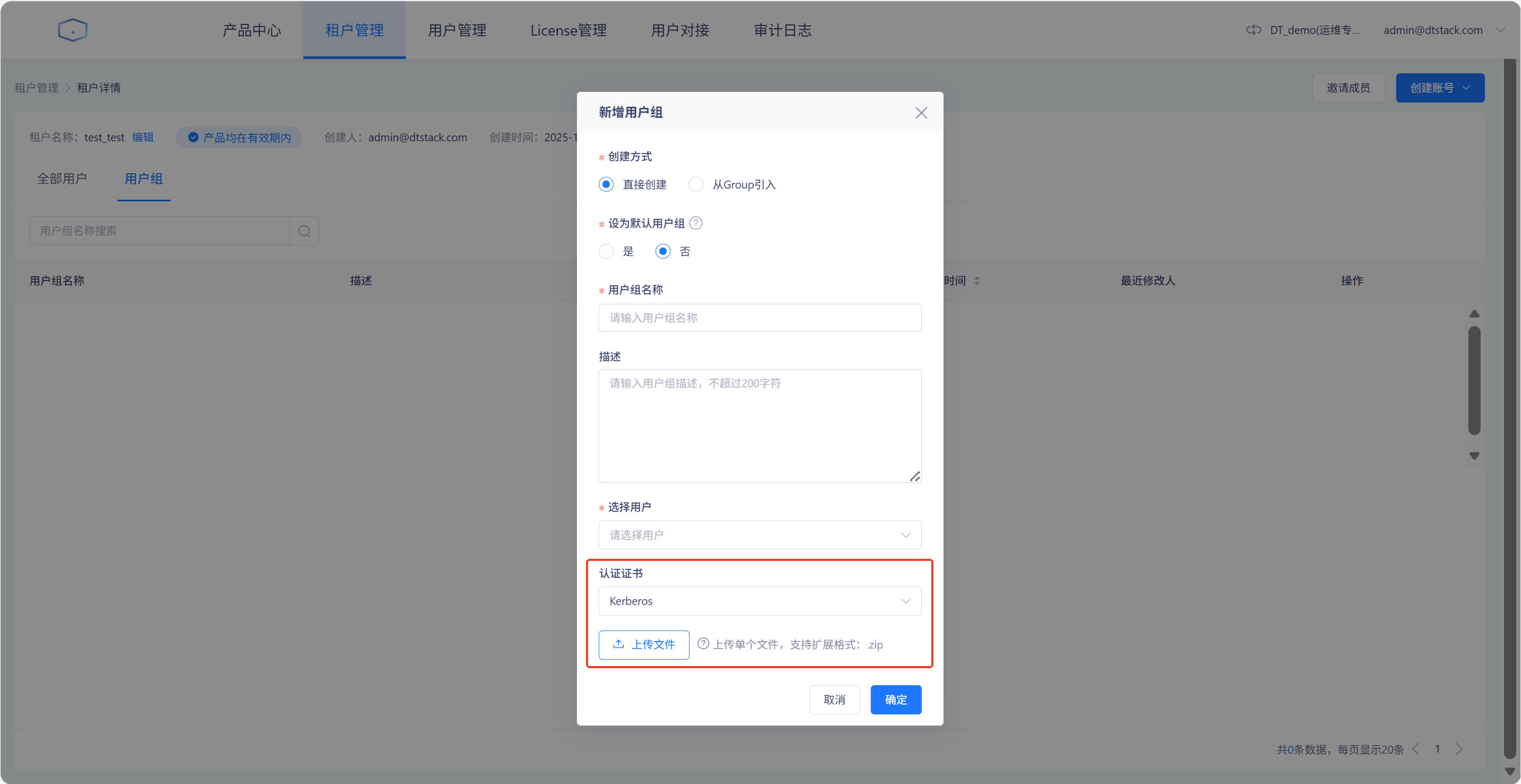
在「用户中心-租户管理-任一租户-用户组」中,可以上传用户组kerberos认证证书,如图所示
绑定个人账号/用户组kerberos认证证书的影响
提交任务后,可通过kerberos的principal用户明确用户级的提交主体,当用户、用户组、项目、集群的kerberos认证均存在时,优先级为:用户 > 用户组 > 项目 > 集群。涉及到的任务类型有Spark SQL、Spark、PySpark、Shell、Python、Impala SQL、Hive SQL、Inceptor SQL、数据同步。
代码与外部仓库同步
概述
离线可对接代码远端仓库进行代码备份和同步
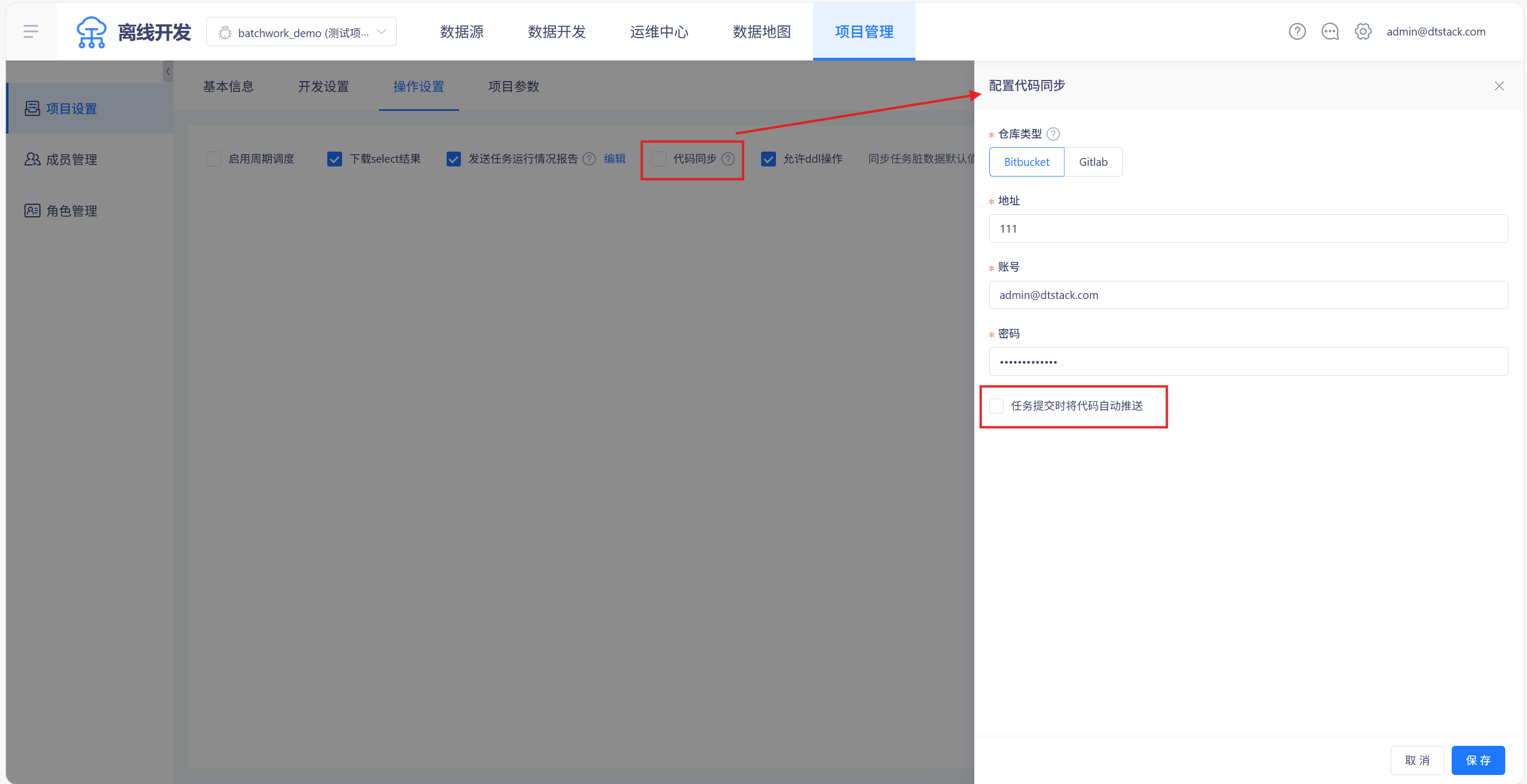
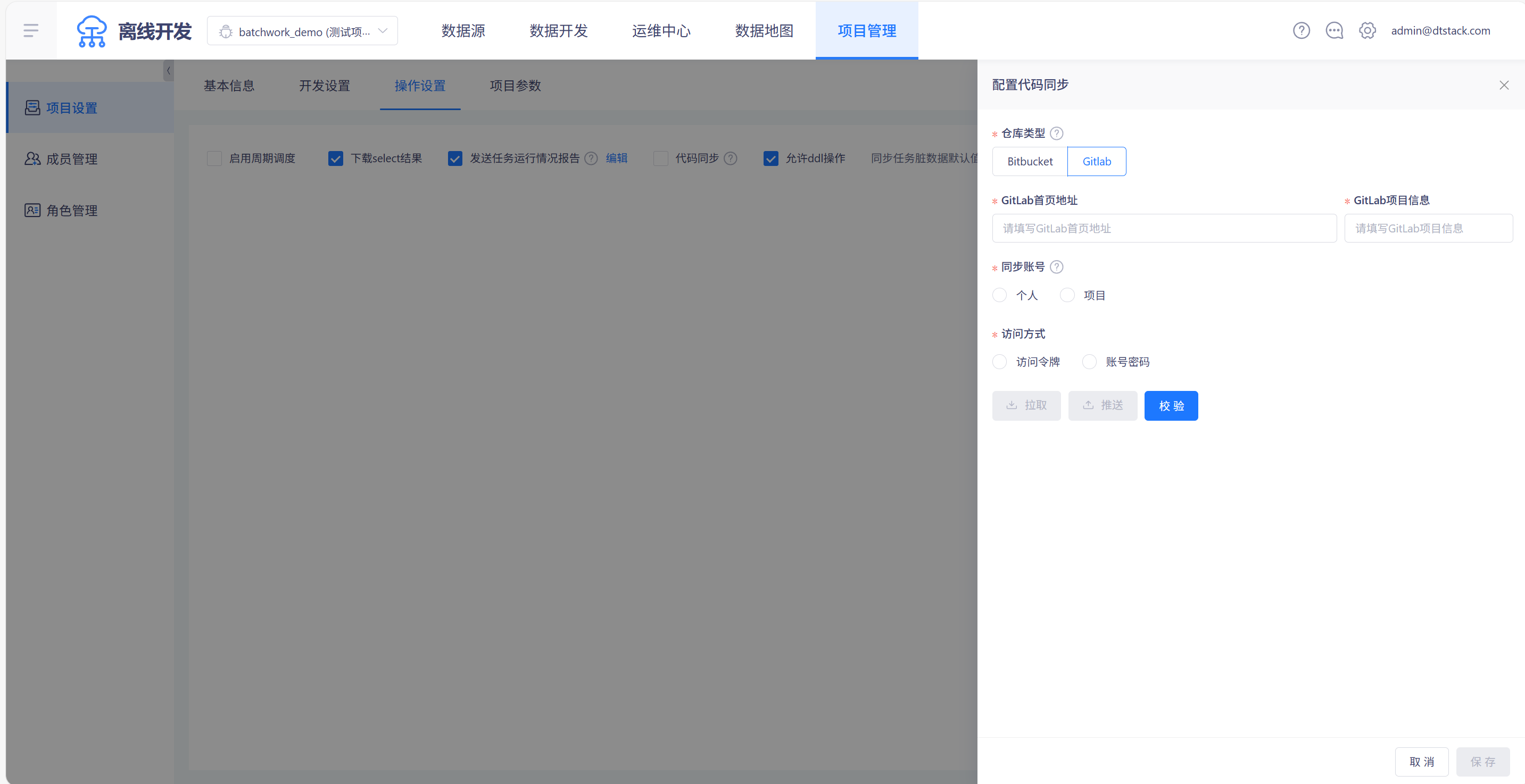
远端仓库配置
在「项目管理->项目设置->操作设置」中,选中「代码同步」后,可配置代码仓库地址和用户,目前支持Bitbucket和Gitlab两种仓库类型,如下图所示,若配置仓库为Bitbucket,则勾选「任务提交时将代码自动推送」,将会在代码提交时自动同步至外部仓库
代码同步
远端代码配置完成后,在数据开发IDE中进行开发时,可进行代码拉取和推送,如图所示
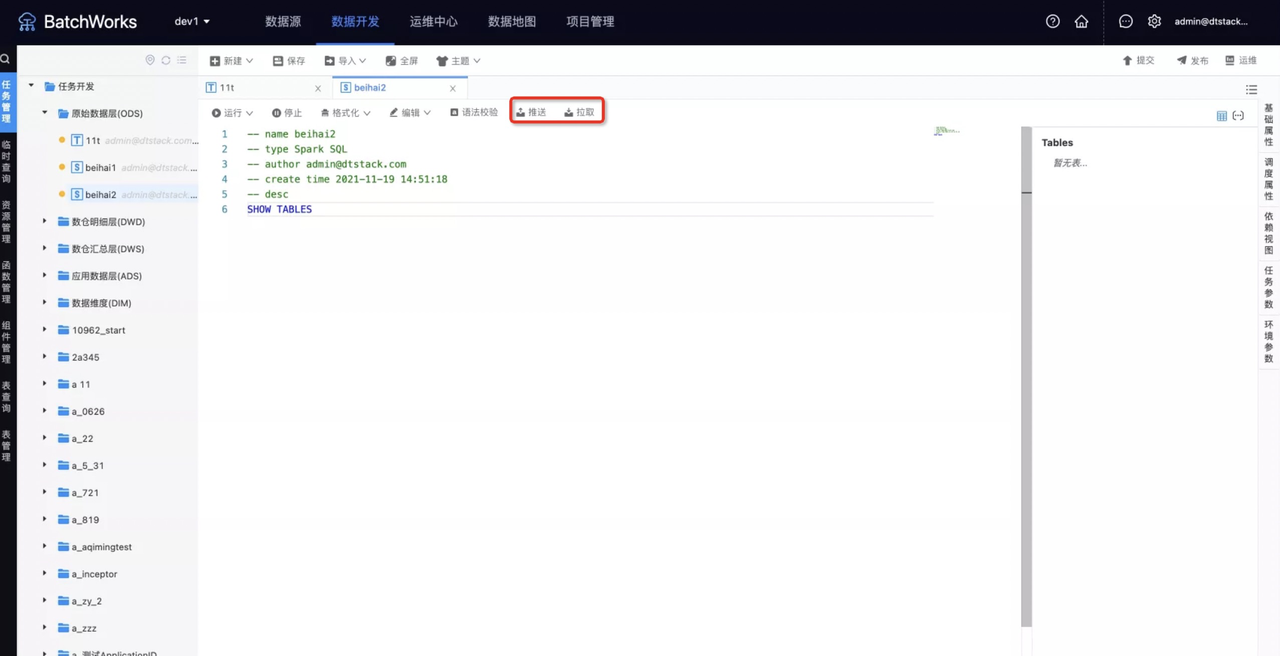
推送与拉取的实现方式

代码拉取:
1、离线任务点击拉取,将bitbucket上对应任务代码拉至离线的IDE
2、将临时存储的代码覆盖IDE中的代码
3、保存后将IDE的代码写入离线存储代码的MySQL库
代码推送:
1、离线打开任务代码时从离线存储代码的MySQL库中读取
2、离线任务点击推送,将代码以文件格式推至临时存储
3、有冲突则提交失败,需要人工在bitbucket上解决。