2023年3月更新日志
上线时间:2023-03-09
功能
数据源
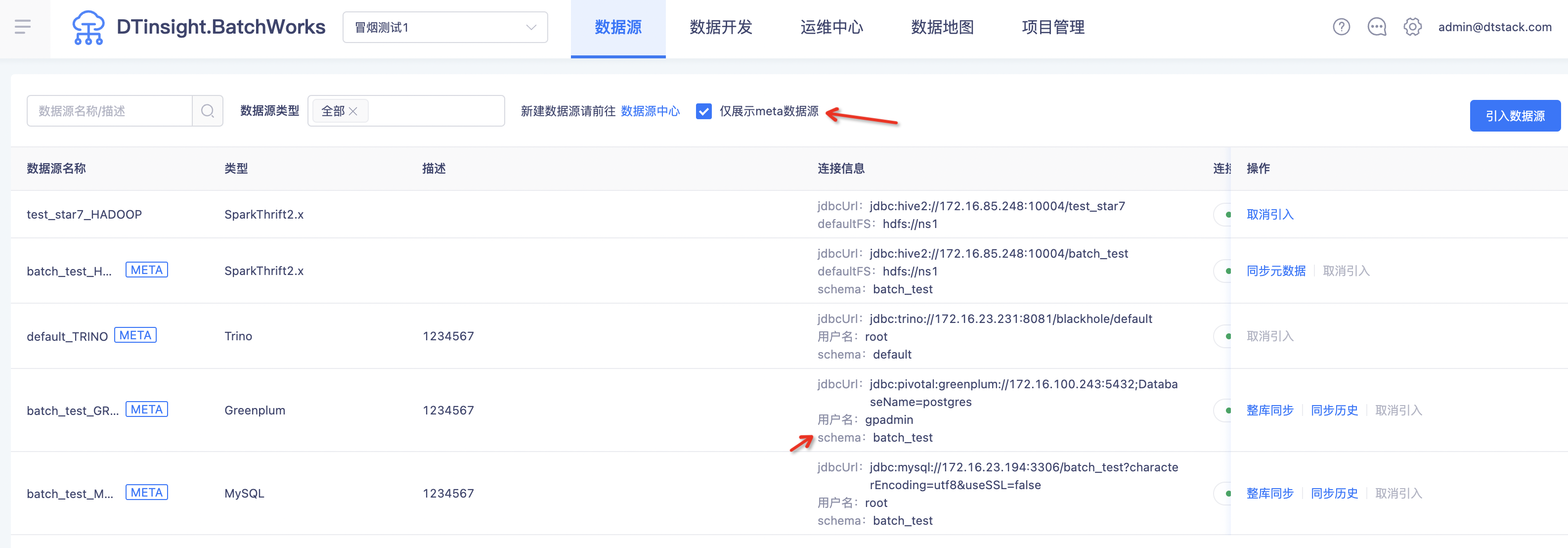
数据源页面展示当前项目的schema名称,以及能做meta schema的快捷查找(上线版本:V5.3)
背景:目前在数据源页面中查看meta数据源的schema,只能在jdbc url中查看,对于用户来说不方便。
功能:新增meta schema 的筛选项,并将meta schema作为单独的字段进行展示。
适配高可用配置Hive集群地址(上线版本:V5.3)
功能:若控制台配置hiveserver和inceptor采用的是zk连接模式,离线端支持获取数据源信息。
数据开发
hive sql支持语法提示、表联想(上线版本:V5.3)
范围:周期任务 手动任务 组件
功能:hive sql 执行临时运行时,展示执行进度并实时打印日志,日志包含执行的map、reduce的情况。
hive sql运行日志支持实时打印、展示任务运行进度、支持任务停止(上线版本:V5.3)
范围:周期任务 手动任务 组件
功能:hive sql 执行临时运行时,展示执行进度并实时打印日志,日志包含执行的map、reduce的情况。任务运行过程中,支持停止运行。
inceptor sql新增临时查询(上线版本:V5.3)
HashData SQL、StarRocks SQL任务开发(上线版本:V5.3)
功能:离线新增两种任务类型HashData SQL、StarRocks SQL,支持表查询、语法提示等功能。
新建工作流任务类型带上“工作流”选项(上线版本:V6.0)
功能:此前新建工作流任务类型时,默认展示还是“数据同步”任务,现优化默认选中“工作流”选择。
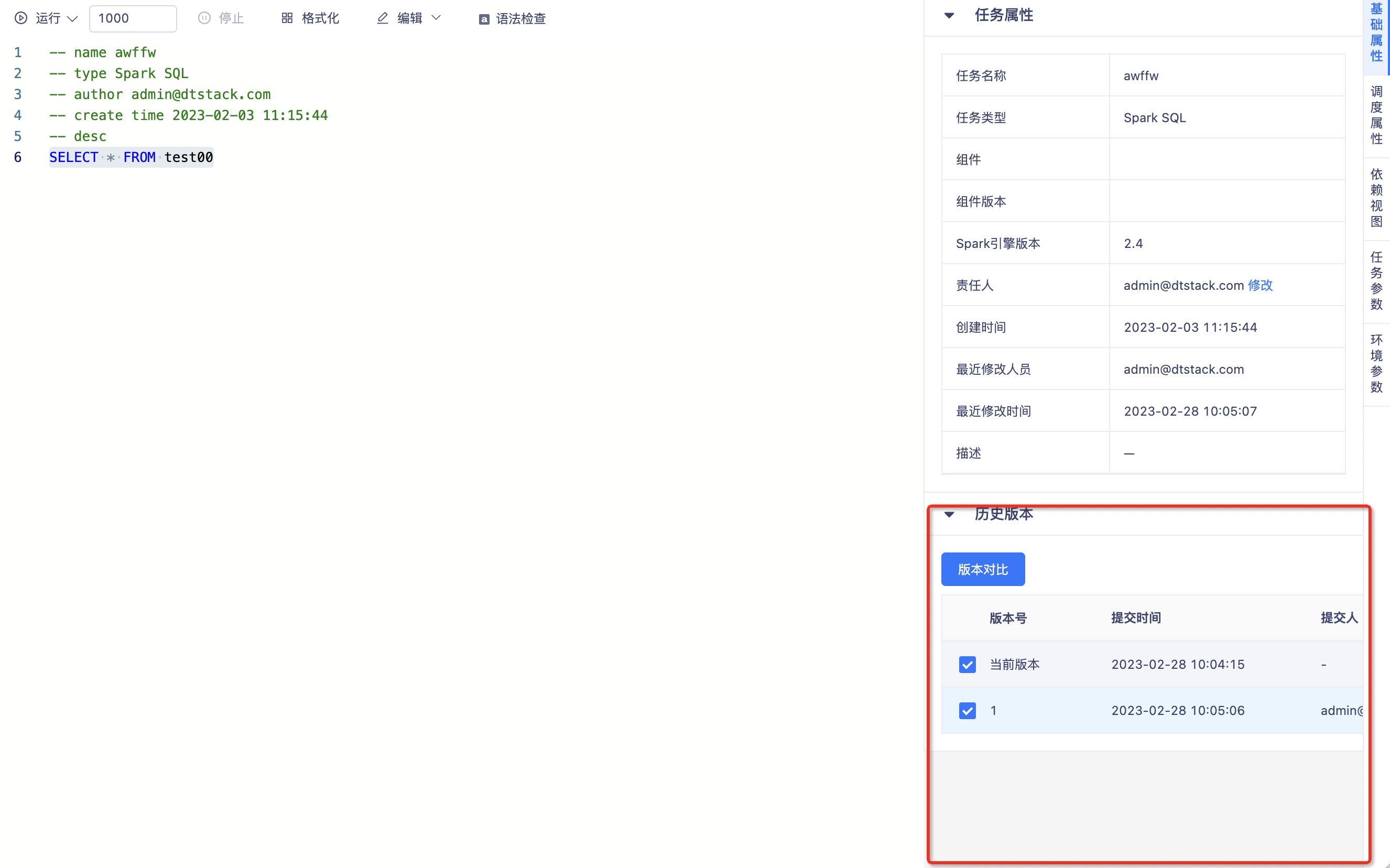
所有代码任务支持版本回滚(上线版本:V6.0)
功能:Impala SQL、Oracle SQL、Greenplum SQL、AnalyticDB PostgreSQL、MySQL、SQL Server、TiDB SQL、GaussDB SQL、Trino SQL、HANA SQL、HashData SQL、StarRocks SQL任务支持版本对比和版本回滚(目前所有代码任务均支持了版本对比和版本回滚)
数据权限管理方式按集群隔离(上线版本:V5.3)
背景:目前我们的数据权限管理方式是平台级的,只要一个集群开了ranger,那么整套数栈所有集群都不走web方式。在客户侧可能不会存在问题,因为对于客户来说,一般仅存在一套管理方式。但是对于我们产研来说可能会存在资源的浪费,因为离线的这种限制,测试同学可能需要部署两套数栈(一套web、一套ranger)进行验证。
解决方案:将一套数栈一种数据管理方式进行拆分,拆分为一种集群一种管理方式
任务默认运行方式调整(上线版本:V6.0)
范围:临时查询、周期任务、手动任务和组件的临时运行
默认分段运行:GaussDB SQL、Oracle SQL、TiDB SQL、Trino SQL、MySQL、SQL Server、Hana SQL、ADB SQL、HashData SQL、StarRocks SQL、Inceptor SQL、Impala SQL
默认整段运行:Hive SQL、Spark SQL、Greenplum SQL
(一般情况任务都是要整段提交,RDB这样处理的原因是RDB任务不会提交到yarn上运行,而是通过JDBC直连的,直接进行整段运行可能会导致结果无法及时返回,任务超时报错)
任务提交时,等待运行动作拆分(上线版本:V6.0)
背景:目前在任务提交时,会存在较长时间的“等待运行”状态,“等待运行”的过程中实际上做了语法检查、与数据地图进行交互等动作。如果“等待运行”时间过长,影响了用户体验,所以对“等待运行”进行拆解,展示具体动作。例如“语法检查开始”“语法检查结束”,内容都异步进行展示。
查询结果字段名可复制(上线版本:V5.3)
本地文件导入到hive表支持xlxs文件格式(上线版本:V5.3)
功能:本地数据导入支持.xlsx格式文件(07版本)、xls格式文件(03版本)。
数据同步
HashData、StarRocks数据同步读写(上线版本:V5.3)
功能:
1、HashData支持作为数据同步的源端和目标端,支持源端时支持自定义SQL、数据过滤、切分键填写(并发读写)、断点续传、增量同步;作为目标端时支持导入前准备语句、导入后准备语句、一键生成目标表、主键冲突时支持insert和update。支持作为整库同步的目标端和源端。
2、StarRocks支持作为数据同步的源端和目标端,支持源端时支持自定义SQL、不支持数据过滤、不支持切分键填写(StarRocks flinkx是用streamload同步的,不需要指定切分键,只要指定并发数,sql的执行计划里就会按对应的并发自己拆分出来多通道同步)、不支持断点续传、不支持增量同步;作为目标端时不支持导入前准备语句、不支持导入后准备语句、支持一键生成目标表、主键冲突时仅支持update。支持作为整库同步的目标端和源端。支持作为整库同步的目标端和源端。
TDengine数据同步读取(上线版本:V5.3)
功能:TDengine支持作为数据同步的源端,支持源端时支持自定义SQL、数据过滤、切分键填写(并发读取)、断点续传、增量同步。支持作为整库同步的源端。
数据同步任务中仅可选择项目对接的schema(上线版本:V5.1)
功能:数据同步时选择当前项目的meta数据源,只能选择当前项目的meta schema。数据同步时选择引入其他项目的meta数据源,只能选择引入数据源的meta schema。
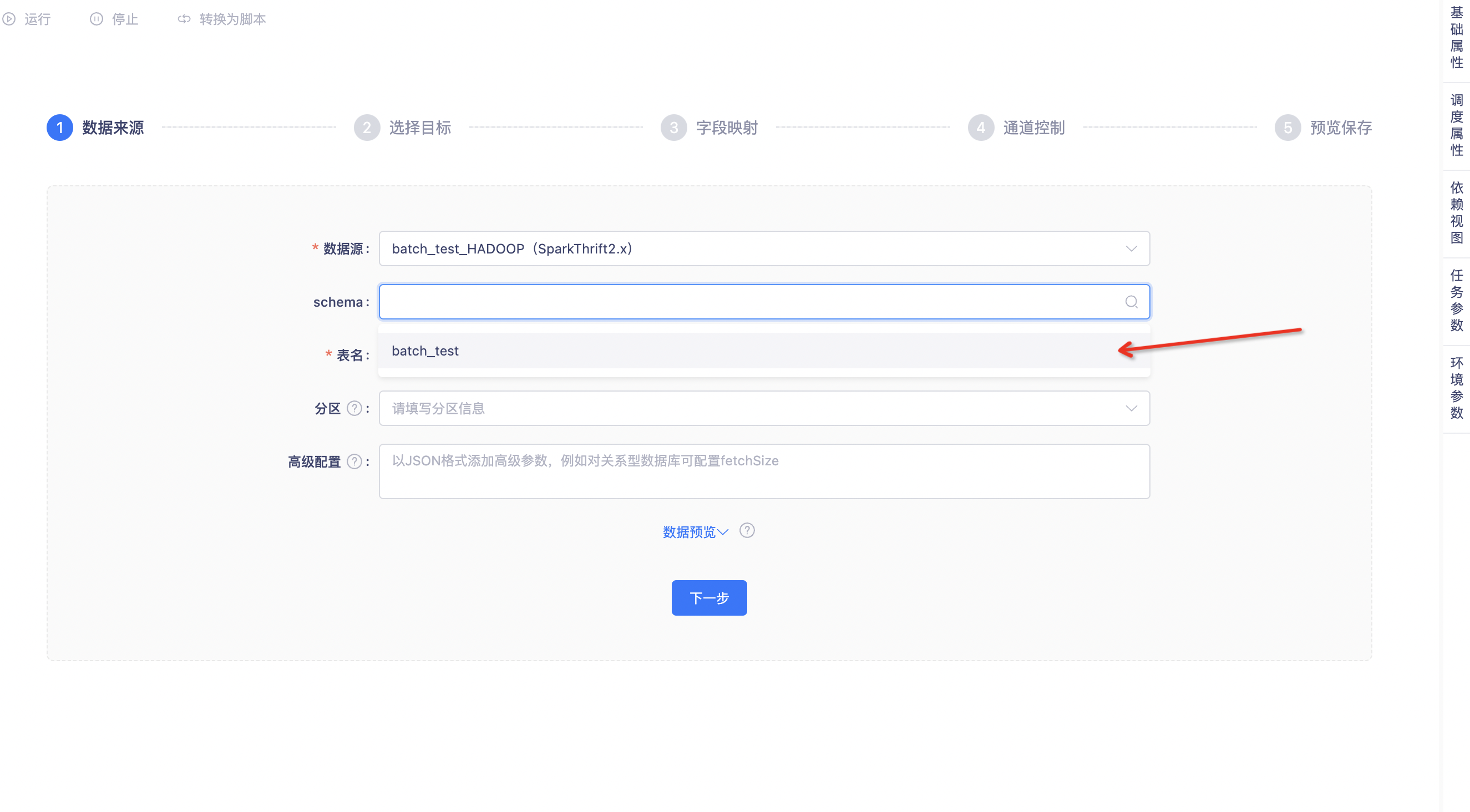
es作为目标数据源时,支持指定主键字段构成(上线版本:V5.3)
背景:在ES作为数据同步目标端的任务中,默认将所有字段都作为主键字段,会导致主键值过长,使任务失败。因此需要离线侧进行优化,不要默认将所有字段都作为主键字段
功能:在字段映射时,支持指定主键包含的字段。
数据源信息同步变更后需要同步至调度(第三批)(上线版本:V5.2)
第三批优化的范围:opentsdb、clickhouse、gaussdb、人大金仓、gbase。
数据同步任务时,字段映射添加常量默认字段类型适配兼容(第二批)(上线版本:V5.2)
第二批优化范围:clickhouse、gbase、vertica、impala、influxdb、opentsdb、oracle、oracle9、polardb、starrocks、sybase、elasticsearch7、tidb、inceptor。
数据同步常量列的值支持修改(上线版本:V5.3)
datasourceX适配加密区的读取,可读取加密区的数据(上线版本:V5.3)
背景:数栈开启数据安全对接自己的ranger/对接客户的ranger时,脏数据读取datasourcex未适配,会导致脏数据无法解析和查看
解决方案:支持对接ranger情况下的脏数据读取
运维中心
支持对hive sql实例进行运行过程的资源使用情况展示,并对于实例进行资源监控并配置告警(上线版本:V5.3)
背景:目前对hivesql任务的运行支持比较薄弱,例如没有打印出yarn上的日志,一旦任务开始执行便无法中止,比较影响数据开发用户的调试。客户期望对效率低、占用资源高的任务进行识别和及时管控。
功能:
1、hive sql实例的「实例详情->运行记录」中展示任务资源使用走势图
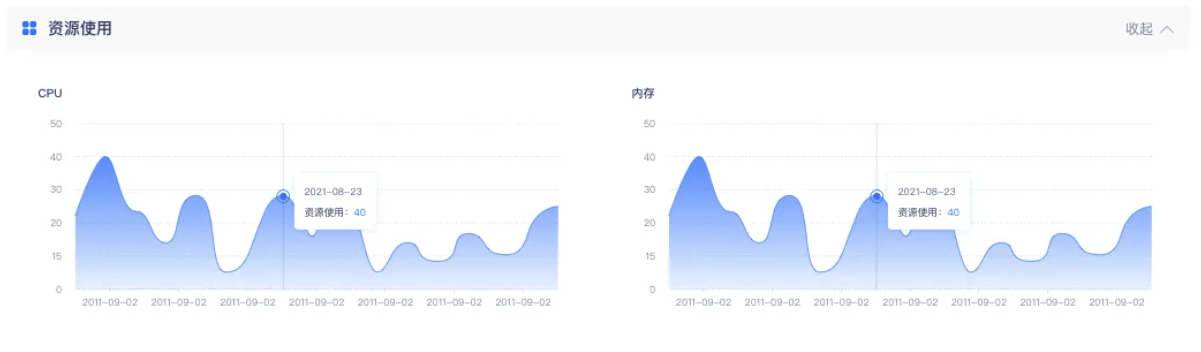
2、创建告警规则时,支持对hive sql资源占用情况进行监控。
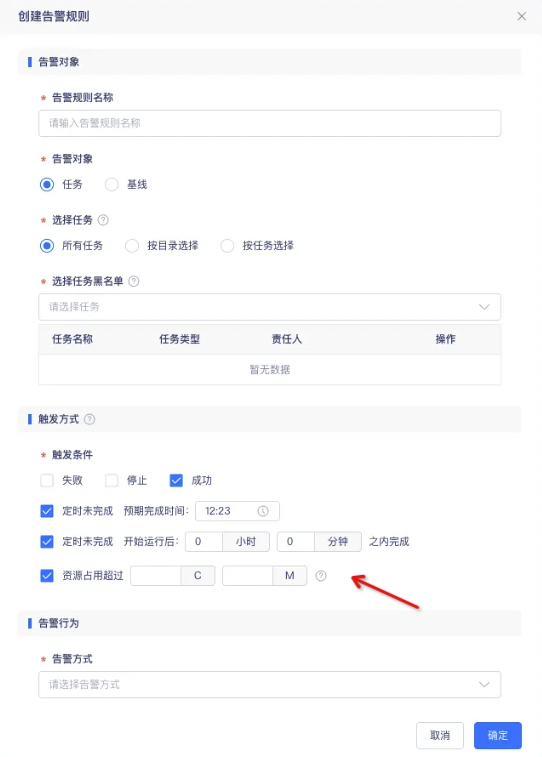
任务补数据支持配置告警规则(上线版本:V5.3)
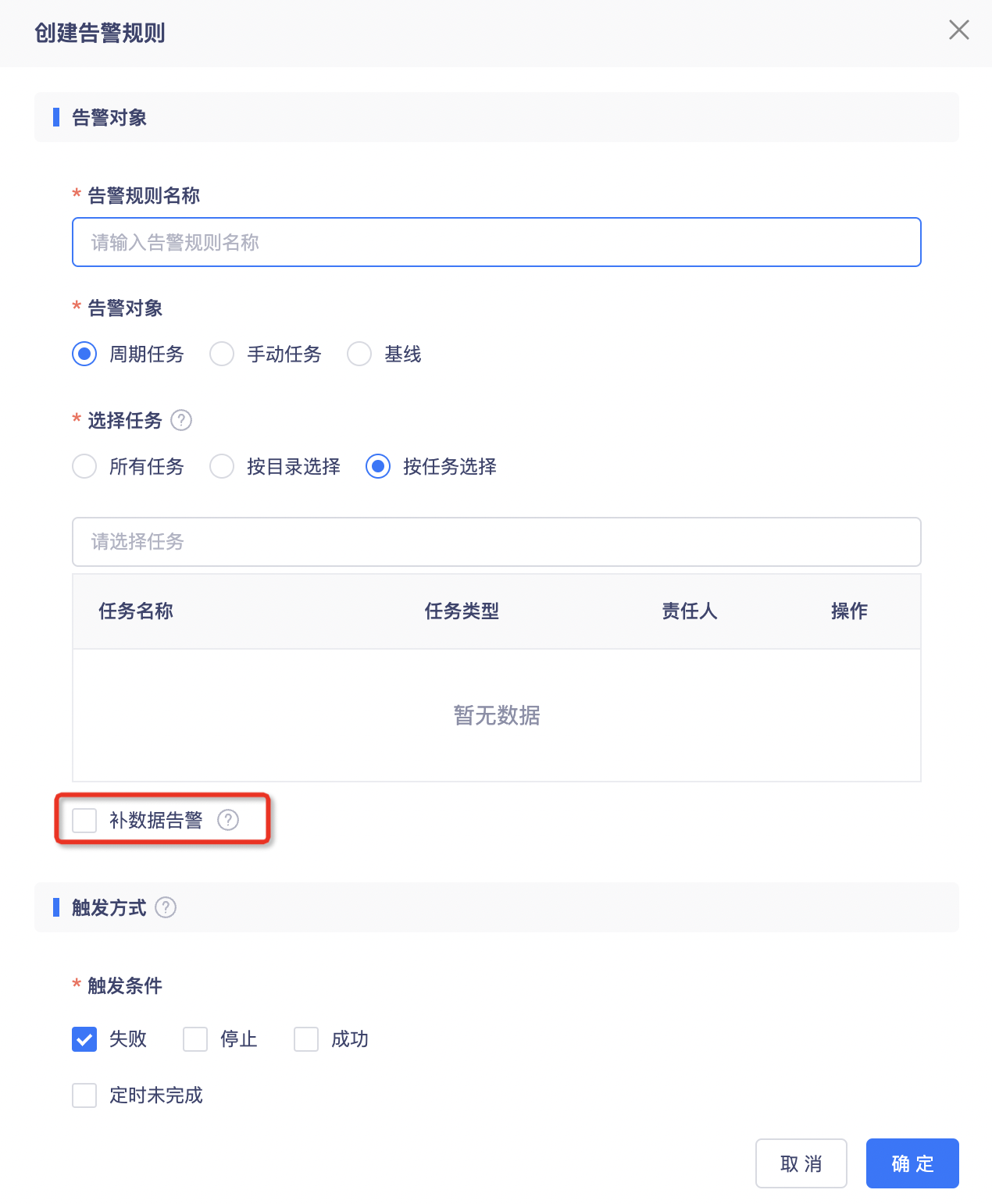
告警配置中勾选任务责任人,只有自己作为责任人的任务报错时,才会给任务责任人发送告警信息(上线版本:V5.2)
发布
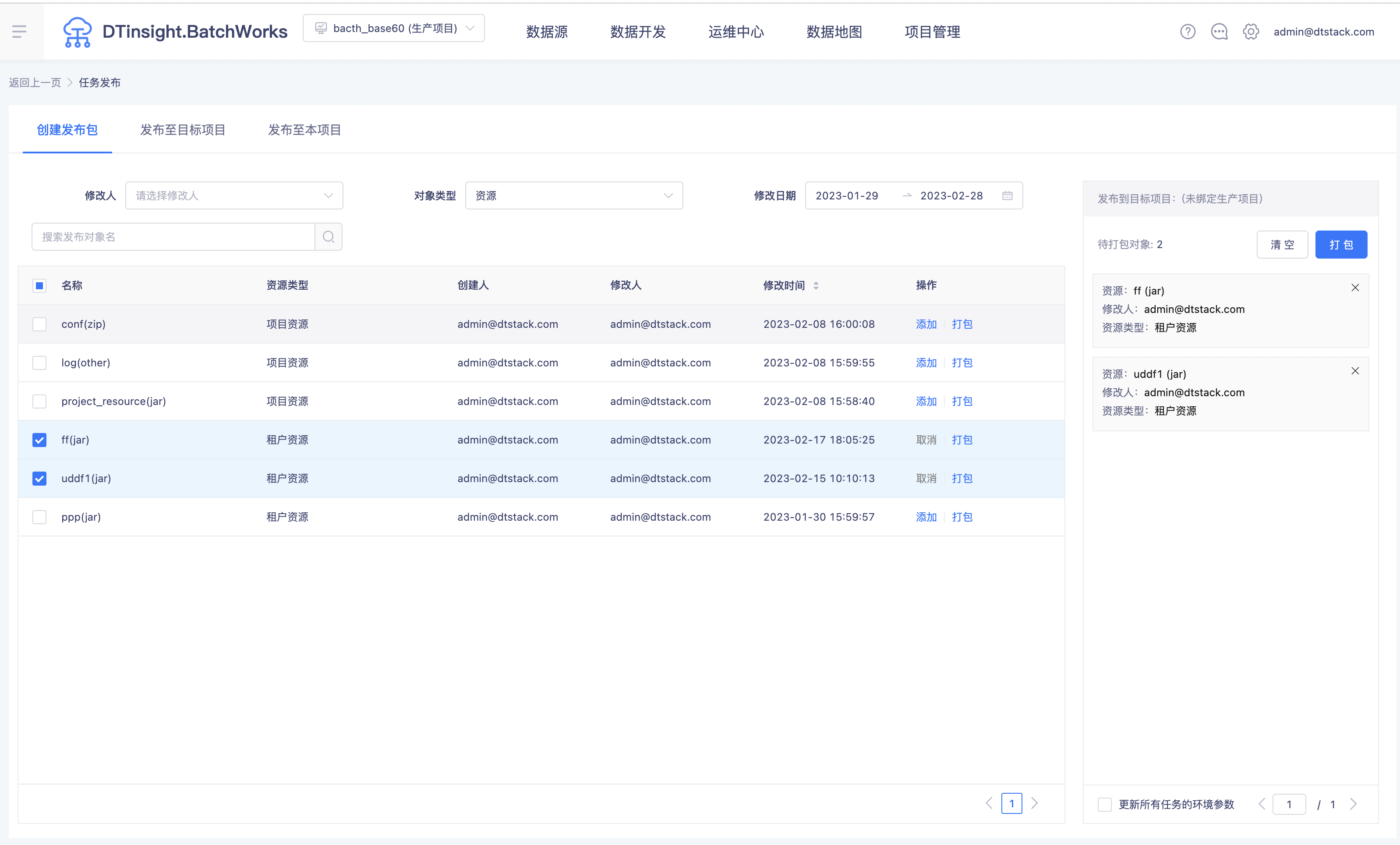
发布功能优化(上线版本:V6.0)
背景:当前发布流程有很多校验内容,包括任务上游、函数、资源、资源组映射、数据源映射等,发布的时候可能会有内容缺漏非常容易造成发布失败,平台需要把缺漏的内容流程化一次性提示给用户,且需要能够支持一些内容的修改替换,以优化发布体验。
功能:发布时,会在发布包中校验引擎、数据源、资源组、任务、上游依赖、资源、函数、组件、表及责任人,并展示校验结果。针对发布失败的校验项,会给出优化提示。

租户资源支持发布(上线版本:V6.0)
项目管理
创建项目时,报错提示优化(上线版本:V6.0)
功能:项目新建失败是由数据源导致时,会明确提示信息:数据源名称、数据源类型、错误原因。
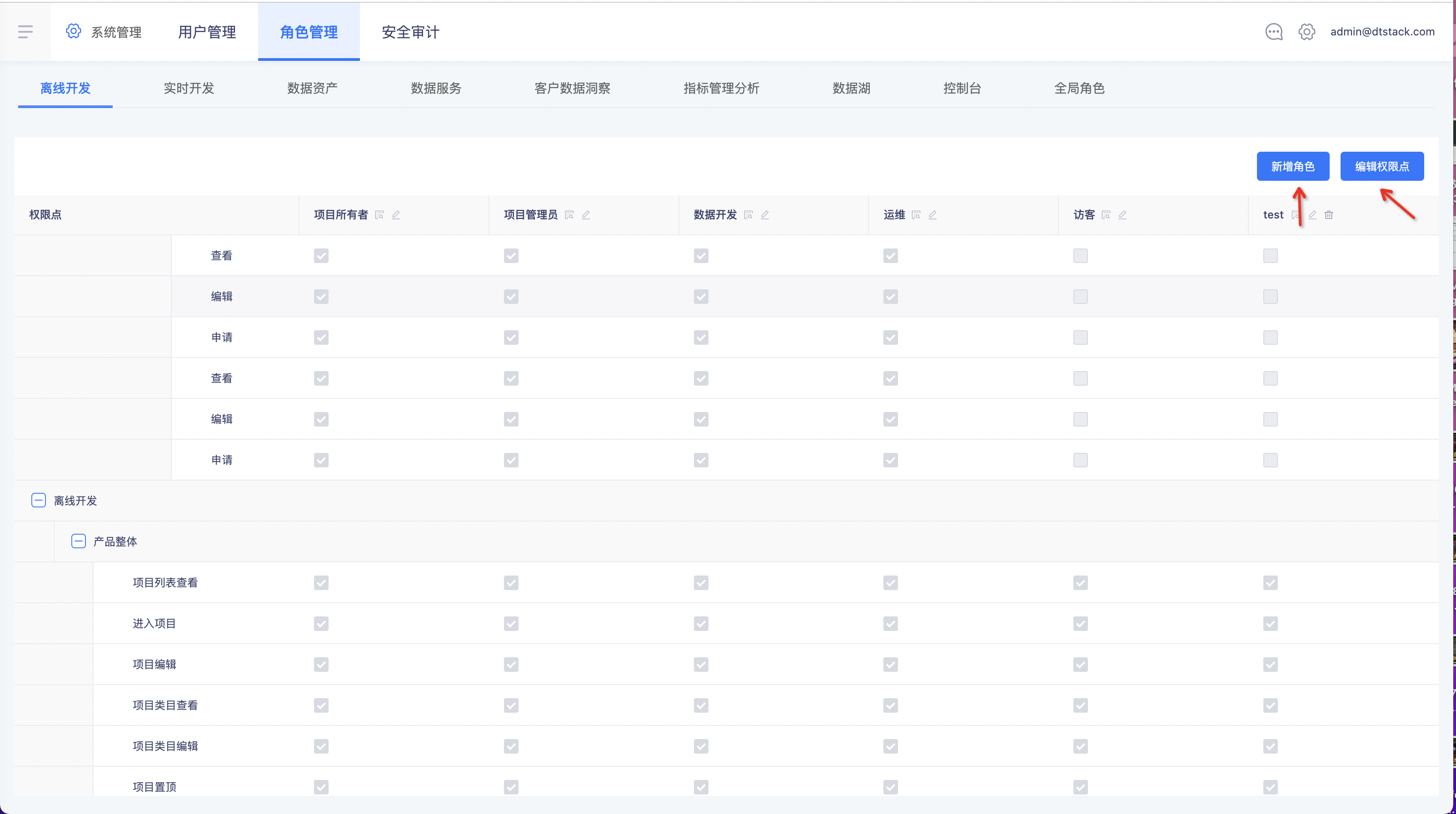
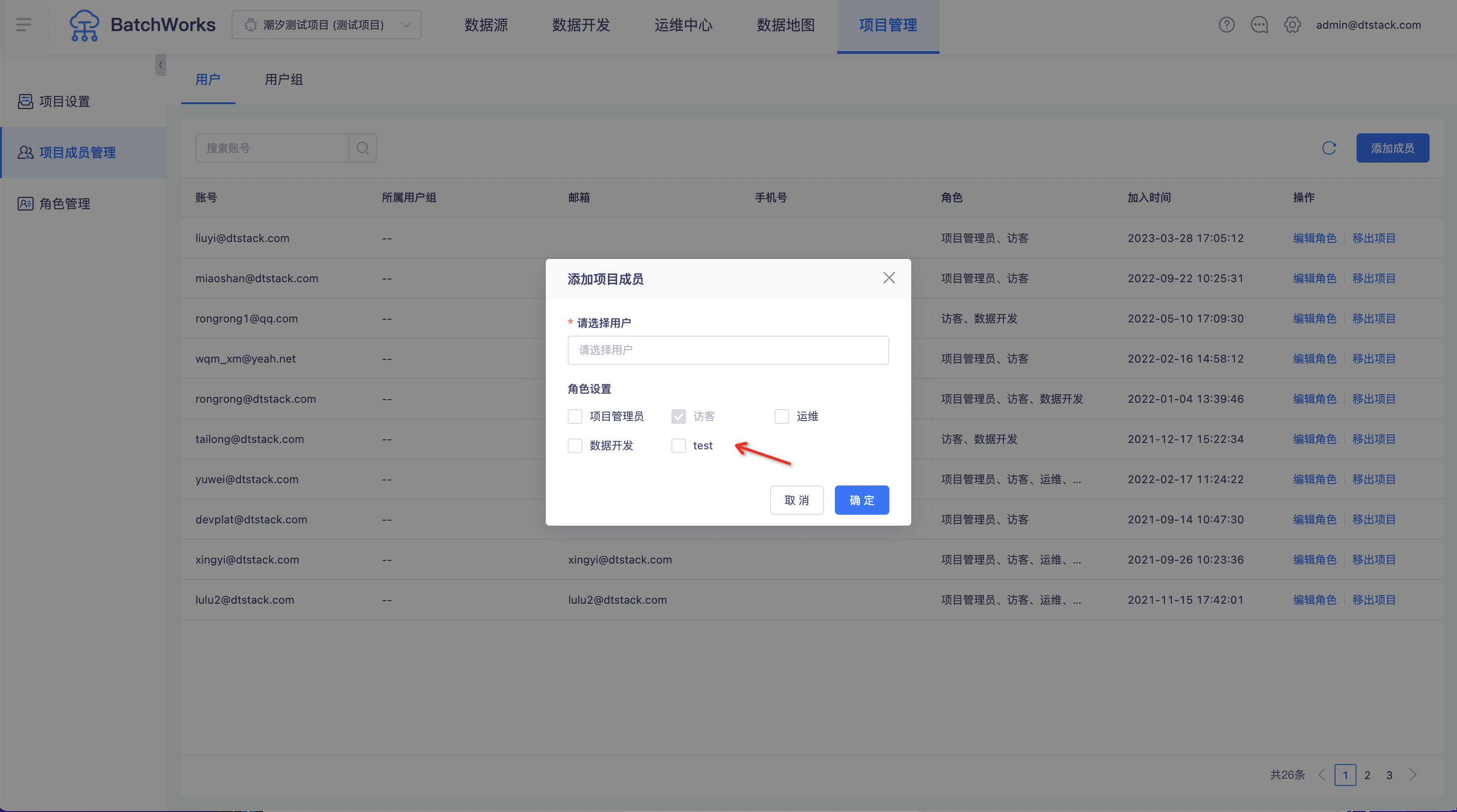
离线支持自定义角色创建
功能:在「角色管理->离线开发」中支持新增自定义角色和编辑权限点。在「项目管理->项目成员管理」往项目里引入用户时,可以设置自定义角色。
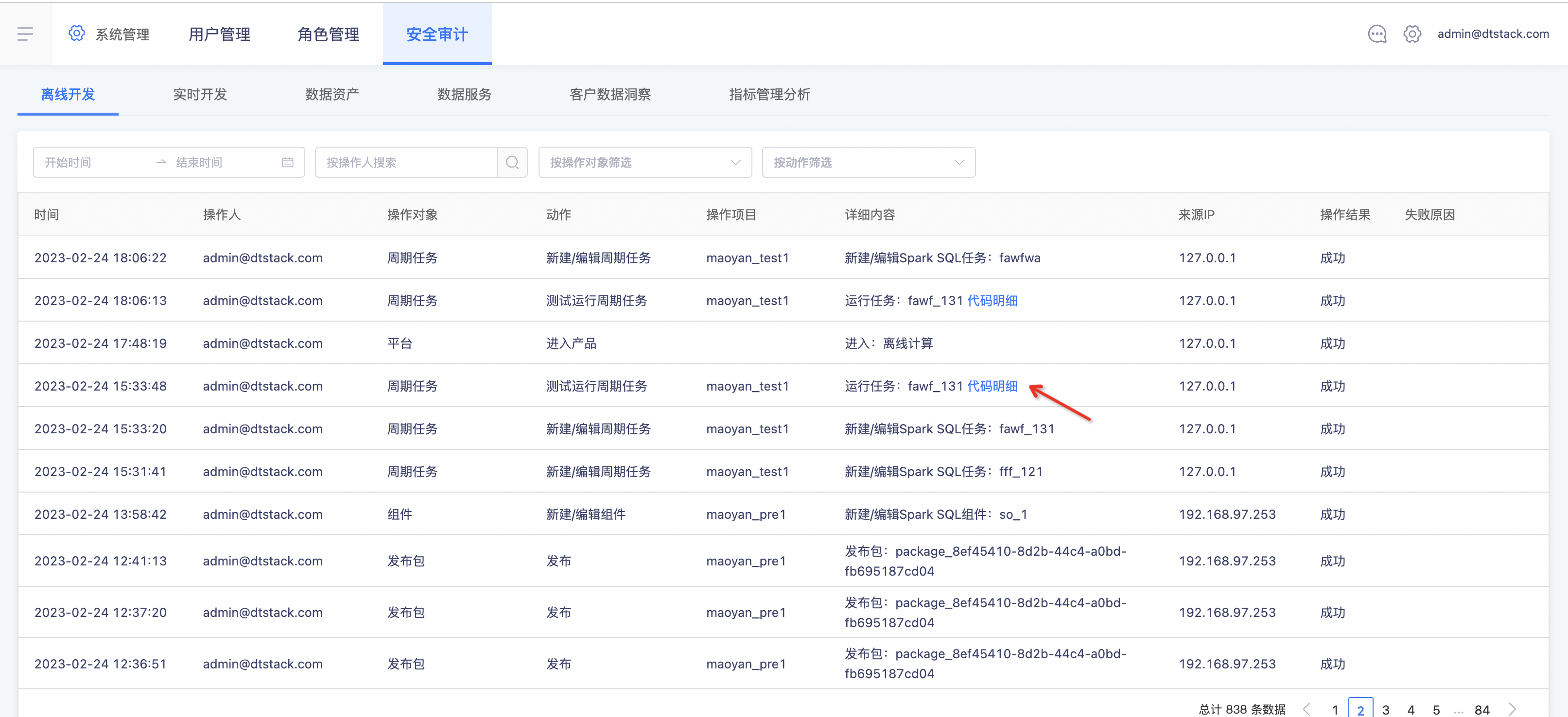
安全审计
任务、临时查询的临时运行审计内容增加代码明细(上线版本:V5.3)
Bugfix&代码优化
监控规则展示任务与实际任务数量不符BUG修复(上线版本:V5.3)