数据小文件治理
该功能仅专业版、旗舰版支持
什么是小文件?
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。文件的大小远小于HDFS上块(dfs.block.size)大小的文件,称为小文件。
为什么需要小文件治理?
大量的小文件会给Hadoop集群的扩展性和性能带来严重的影响。NameNode在内存中维护整个文件系统的元数据镜像、用户HDFS的管理;其中每个HDFS文件元信息(位置,大小,分块等)对象约占150字节,如果小文件过多,会占用大量内存,直接影响NameNode的性能。相对地,HDFS读写小文件也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立连接。如果NameNode在宕机中恢复,也需要更多的时间从元数据文件中加载。也会给Spark SQL等查询引擎造成查询性能的损耗。大量的数据分片信息以及对应产生的Task元信息也会给Spark Driver的内存造成压力,带来单点问题。此外,入库操作最后的commit job操作,在Spark Driver端单点做,很容易出现单点的性能问题。
离线开发中的小文件治理的做法
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。块的大小默认为128MB,当文件大小为128时,Hadoop集群的计算效率最高。因此对非分区表按表进行数据文件合并,使表/分区数据文件的大小接近128M。在数栈中实现小文件治理功能的原理是,把小文件拷到一个临时目录下,这个目录下的小文件合并完成以后覆盖到原目录。
如何操作
拥有操作权限的角色:超级管理员、租户所有者、租户管理员、项目所有者、项目管理员在「数据地图」模块下的「数据文件治理」中可以进行小文件治理的创建。
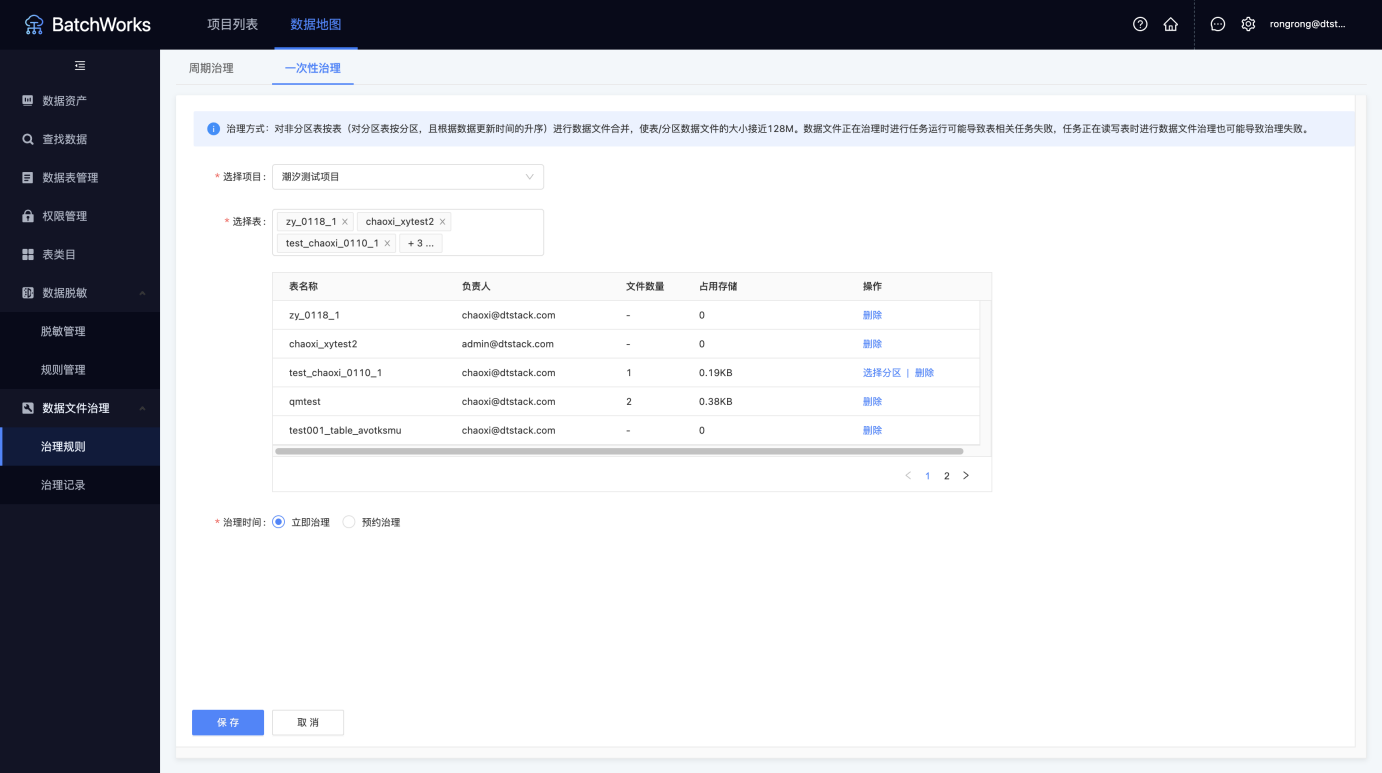
一次性治理
即一次性的治理任务,用户可以直接指定项目下的表、分区和执行时间,在设置的时间下使指定的分区/表进行数据文件的合并。
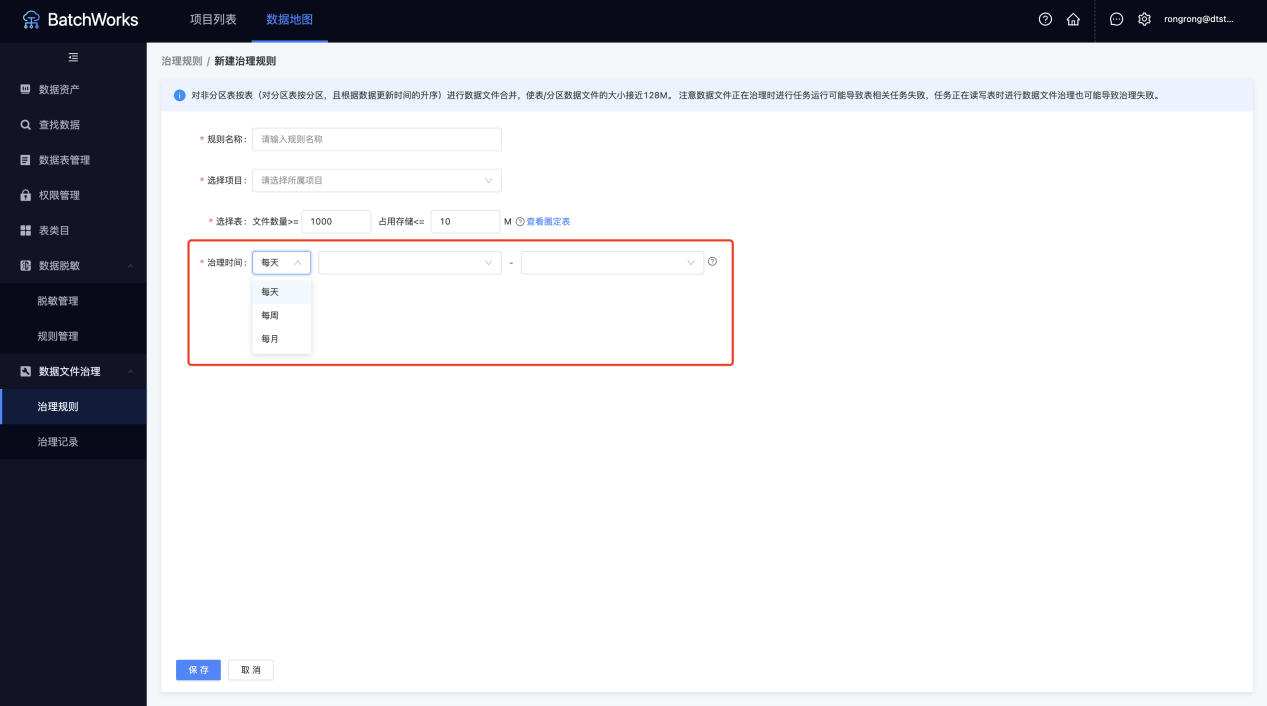
周期治理
即支持按每天、每周、每月为维度对指定项目下对符合圈定条件的所有非分区表或分区进行周期治理。
对于非分区表和分区表,此处的筛选条件分别应用于表和分区。应用于分区时,实际圈定的是满足该条件的分区所属的表,实际治理的是这些这些表中满足条件的分区
周期治理规则由创建后的从第二日的零点开始生效,且之后每天0点自动生成当天的治理记录
治理规则时间应避开任务对表/对应分区的读写时段,否则可能导致读写失败或数据丢失。如果出现失败或数据丢失,将任务重跑即可