周期任务依赖
上下游依赖
为什么要配置调度依赖
一些任务的数据加工依赖其他任务的数据产出。在离线开发中支持自动依赖、手动依赖两种依赖配置方式。
任务依赖配置
自动依赖
该功能仅专业版、旗舰版支持
对于SparkSQL、HiveSQL、ImpalaSQL任务,可自动解析用户SQL代码,并自动推荐上游任务,其基本逻辑如下:
假设A任务代码:
INSERT INTO ta
SELECT * FROM t
假设B任务代码:
INSERT INTO tb
SELECT * FROM ta
应该配置A为B任务的上游,则当A任务已经提交当前提下,在B任务的「调度属性」的「任务间依赖」模块选中依赖方式为「自动依赖」按钮,将在依赖列表中显示A任务。
选择自动依赖时,会根据当前IDE的代码的血缘解析结果(通过解析create as , insert into as, insert overwrite into as等语句)把当前任务所有来源表的产出任务解析在列表中。
依赖生成方式从自动依赖切换成手动依赖时,自动依赖解析得到的上游任务保留,不自动删除。
依赖生成方式从手动依赖切换成自动依赖是,手动依赖添加的任务将被全量覆盖。
手动依赖
手动依赖的添加方式可选择手动添加或依赖推荐,依赖推荐目前仅支持三种任务类型的解析:SparkSQL、HiveSQL、ImpalaSQL
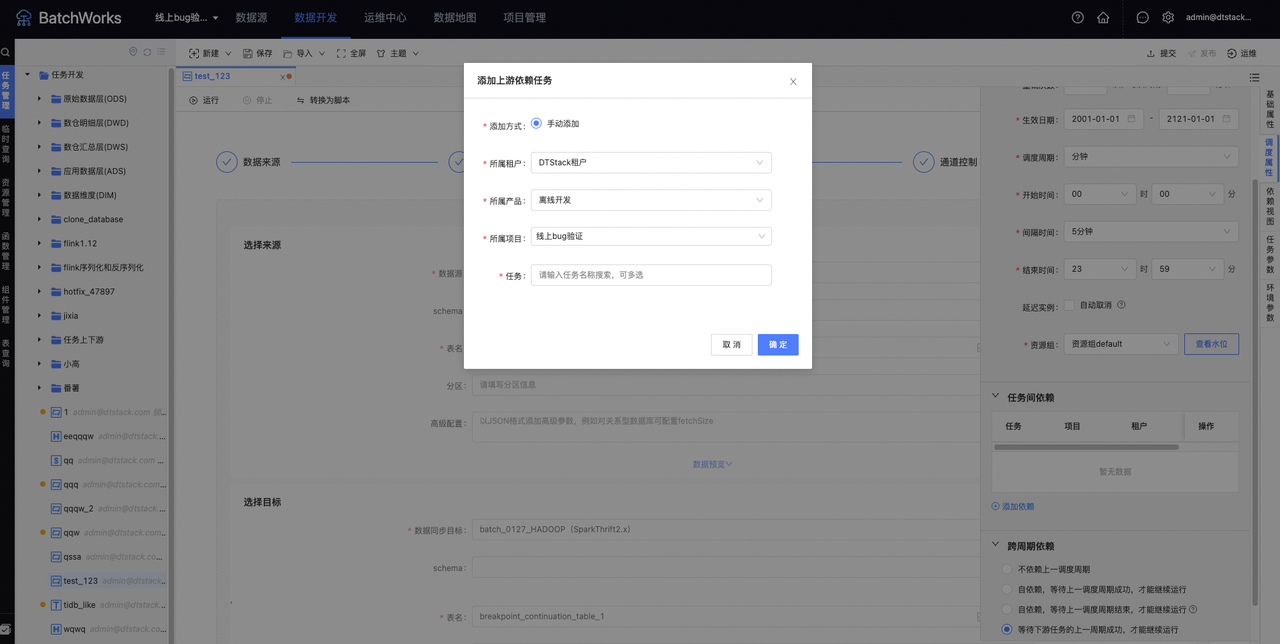
若某任务B必须在任务A完成后运行,则A为B的上游任务,这种依赖关系可通过如下方式配置:在「调度依赖」面板中的「任务间依赖」模块选中依赖方式为「手动依赖」按钮,点击「添加依赖」,在弹窗中选择添加方式为「手动添加」,选择相应的租户、产品(离线开发、指标管理、智能标签)、项目,并输入上游任务的名称,在搜索的下拉结果中选择需要依赖的上游任务。
只要是在一套平台内,任务可实现跨集群、租户、产品、项目实现依赖
依赖属性为非必填项,当下游任务需依赖上游任务产出数据,建议配置依赖关系
上游任务失败后,下游任务不会运行,且下游任务的状态会保持「等待提交」
当在弹窗中选择添加方式为「依赖推荐」时,和「自动依赖」的逻辑一致,会根据当前IDE的代码的血缘解析结果(通过解析create as , insert into as, insert overwrite into as等语句)当前任务所有来源表的产出任务将会解析在「选择任务」列表,列表中还会展示类型、项目、产品、责任人、关联内容(当前任务与上游任务的关联表,以schema.table的方式展示)等字段。选中任务后点击「确认」,可与选中任务建立上下游依赖关系。「依赖推荐」和「自动依赖」一样,都是专业版、旗舰版才具有的功能
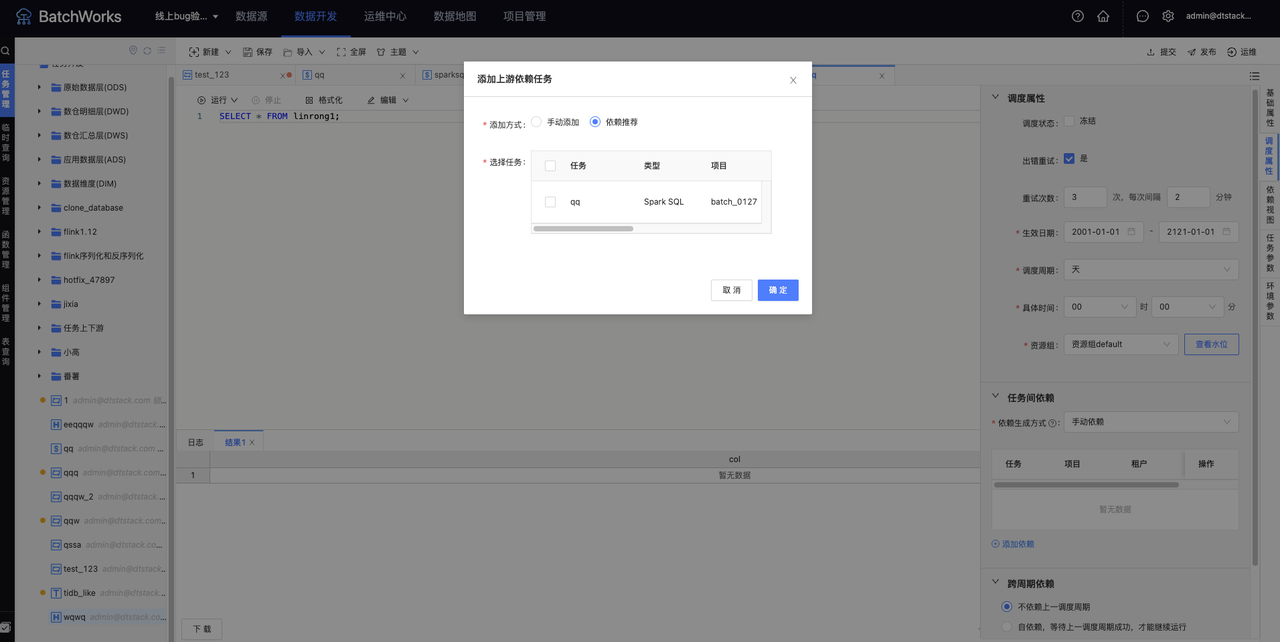
除SparkSQL、HiveSQL、ImpalaSQL任务外,任务间依赖方式默认为「手动依赖」,且不存在「依赖推荐」。
当选择自动依赖时,默认会和所有血缘关系的任务建立依赖关系,无法修改。
当选中推荐依赖时,可以在所有推荐的血缘关系的任务中,选择合适的任务建立依赖关系。
跨周期依赖
基本配置
跨周期依赖比较典型的场景是:昨天的实例必须先执行成功,今天的实例才可以调度起来,跨周期依赖的选项有4种,结合实例来看,假设A任务每天01:00运行,分析3月2日、3日的实例,不同的跨周期依赖的效果如下:
- 不依赖上一调度周期,无论2日的实例运行情况如何,3日的实例会正常运行
- 自依赖,等待上一调度周期成功,才能继续运行,2日的实例必须运行成功,3日的实例才具备运行的条件,若2日的实例未处于成功状态,则3日的实例会处于「等待提交」的状态
- 自依赖,等待上一调度周期结束,才能继续运行,与上一种情况类似,但不要求2日的实例必须成功,只需要2日的实例运行结束(成功、失败、取消、自动取消)即可
结束状态包括成功、失败、取消、自动取消
依赖属性配置的调度依赖是同周期依赖和跨周期依赖不冲突。任务A可以配置依赖属性依赖任务B,也可以配置跨周期依赖依赖B,如此任务A既依赖任务B,本周期也依赖任务B上周期。
高级配置
跨周期依赖配置中还有另外2种配置:
- 等待下游任务的上一周期成功,才能继续运行
- 等待下游任务的上一周期结束,才能继续运行
这2种情况使用的情况较少,主要场景是:本周期该任务是否运行,取决于下游任务上一周期的运行情况。如果下游任务的上一周期运行成功/结束,本周期的任务才能开始运行,例如:
A任务、B任务:
- 调度周期:均为10分钟
- A为B的上游
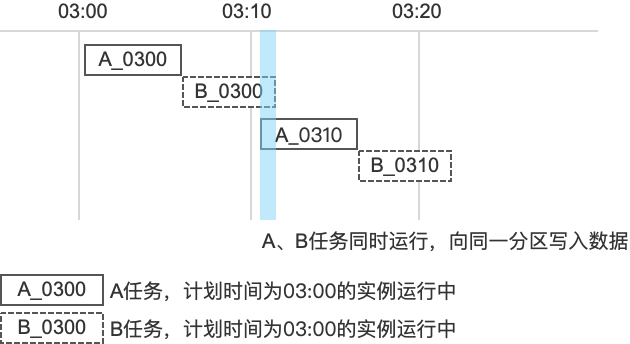
- A、B的结果表是同一个,均向表t的天分区写入数据,代码如下:
INSERT INTO t partition (ds = 20200303) SELECT * FROM …… - 当A与B任务同时运行时,会出现二者同时向同一个分区写入数据的情况(无论A、B是否配置自依赖,均会发生2个任务向同一分区写数据的情况),会造成数据错乱或任务失败,如下图所示:
在这种场景下,需要等待B任务的上个周期实例完成运行,A任务才能启动运行,应形成如下的依赖关系:
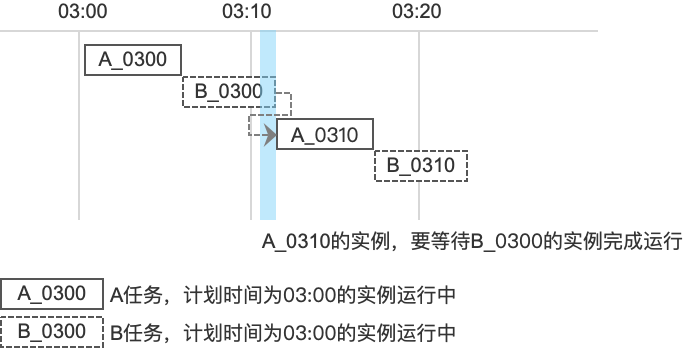
A任务的跨周期依赖应配置为:等待下游任务的上一周期结束/成功,才能继续运行
对小时、分钟任务等高频率调度的任务,建议将依赖设置为不依赖,或者等待XX结束,防止中间某个实例失败造成下游的大面积延误或失败
几种典型场景
非分钟小时任务之间的依赖
假设A、B、C任务均为天任务,依赖关系为:A→B→C,3个任务的计划时间分别为:A(01:00)、B(03:00)、C(02:00)。在资源十分充足的条件下,会产生如下的运行情况:
- A:01:00开始运行
- B:03:00开始运行
- C:在当天的天任务中寻找上游依赖,则判定依赖B任务03:00的实例,C任务会在B任务03:00运行结束后才具备运行条件,C可能会在03:10开始运行
当任务不是分钟任务或小时任务时(cron和自定义调度周期需每天<1个实例),会在当天的实例中,寻找上游任务的实例
短依赖长
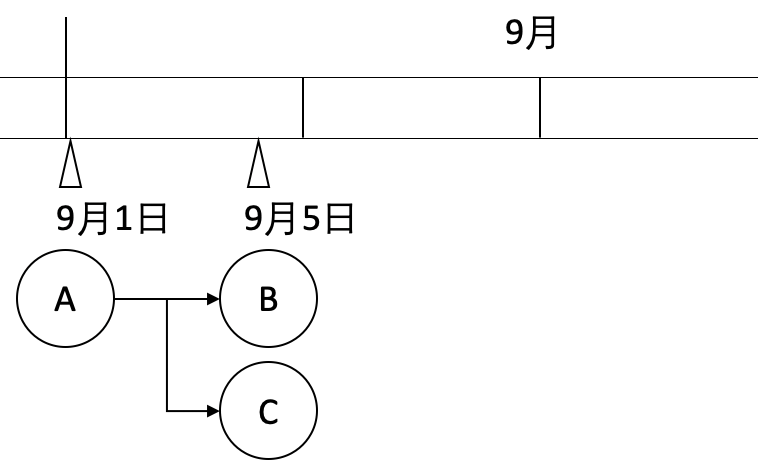
以天依赖月为例,A为月任务,B、C为天任务,依赖关系为:A→B/C
3个任务的计划时间为:
- A:每月1日,01:00
- B:每天,01:30
- C:每天,03:00
下面以9月5日为例:B、C任务寻找的最近的一个A任务的实例,为9月1日 01:00(计划时间)的实例,则会形成如下图的依赖关系:
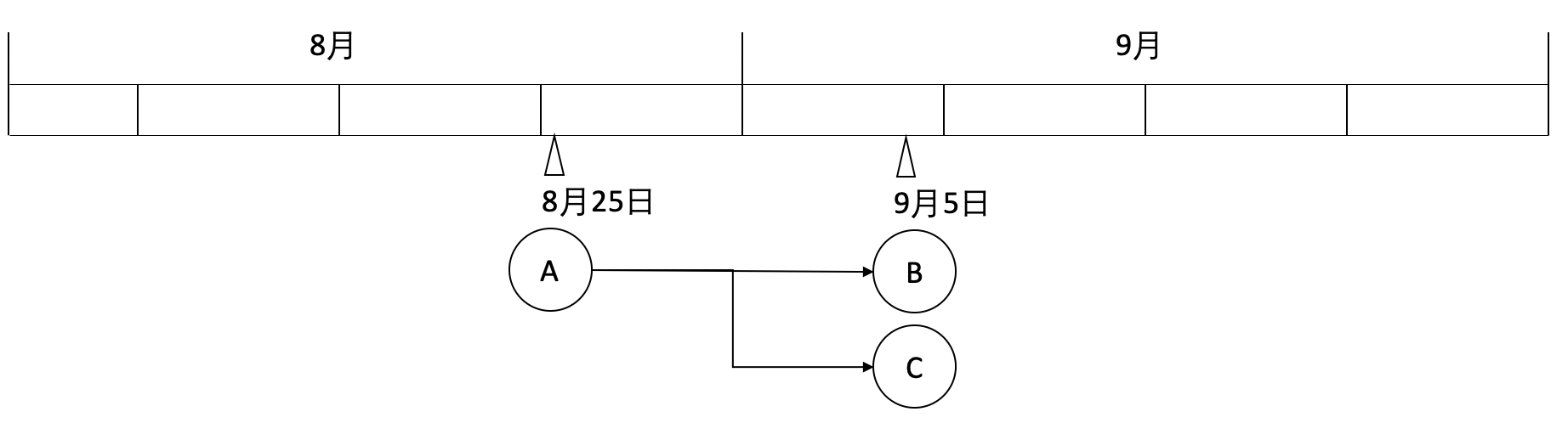
假设3个任务的计划时间变更为:
- A:每月25日,01:00
- B:每天,01:30
- C:每天,03:00
依然以9月5日为例:B、C任务寻找的最近的一个A任务的实例,为8月25日 01:00(计划时间)的实例,则会形成如下图的依赖关系:
长依赖短
以天依赖小时为例,A为小时任务,B、C为天任务,依赖关系为:A→B/C
3个任务的计划时间为:
- A:每天,每隔1小时运行一次,计划时间分别为:00:00、01:00……
- B:每天,01:00
- C:每天,03:30
依然以9月5日为例:B、C任务寻找的最近的一个A任务的实例,则会形成如下图的依赖关系:
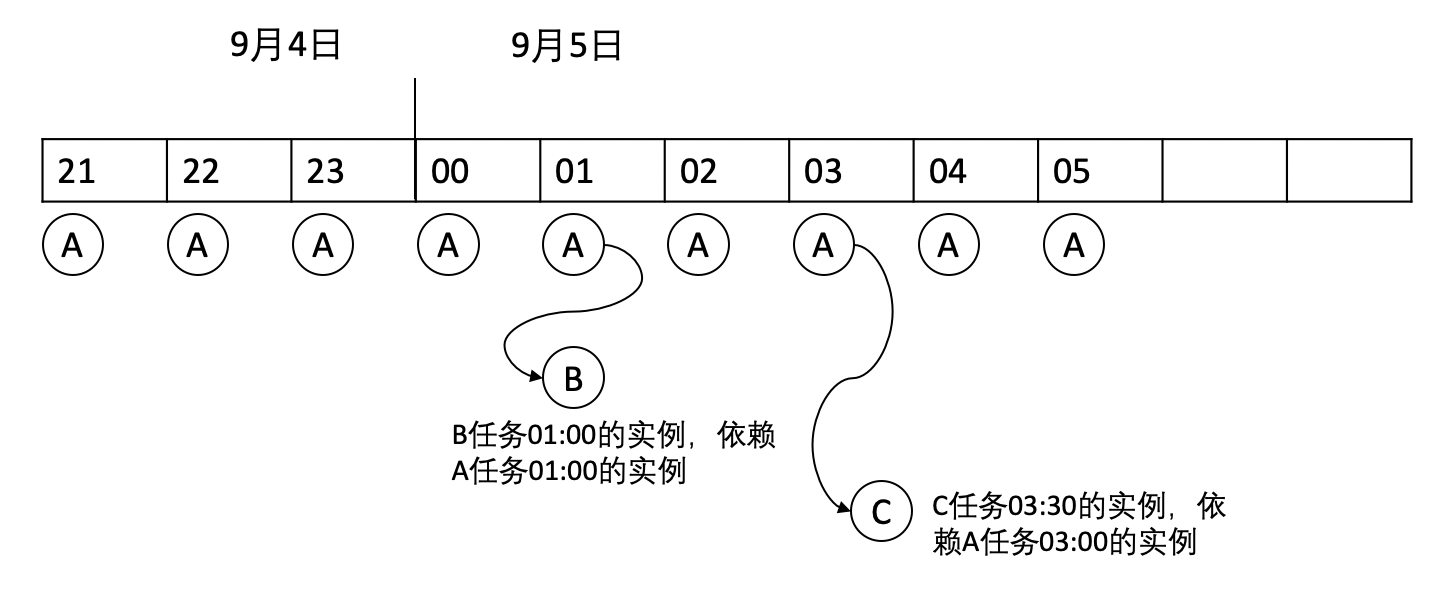
当前实例或上游实例是小时分钟实例时(cron和自定义调度周期需每天>1个实例),永远会去寻找一个与其计划时间相等,或之前的实例,不会去寻找未来时间的实例
月被依赖的特殊处理
当月任务被依赖时,会对月任务的实例做一次特殊处理,场景如下:
假设在9月5日新建了一个月任务A,计划时间是每月1日,并设置了2个天任务B、C作为A任务的下游,按上文的依赖判断原则,B、C任务应依赖于A任务9月1日的实例,但A任务5日才被创建,不存在1日的实例,这种场景下调度系统会做特殊处理:
A由于首月创建时间较晚,实例还不存在时,B、C任务依然可以运行
A任务可以通过补数据来生成9月1日的实例,但实例不会在补数据实例中寻找上游,仅会在周期实例中寻找上游
自定义依赖实例周期
概述
目前调度系统中的依赖方式为天任务默认依赖上游任务当天的实例,小时分钟任务默认依赖上游任务最近的实例。
但实际的应用场景中,单一的实例依赖方式无法满足客户的场景,例如下图
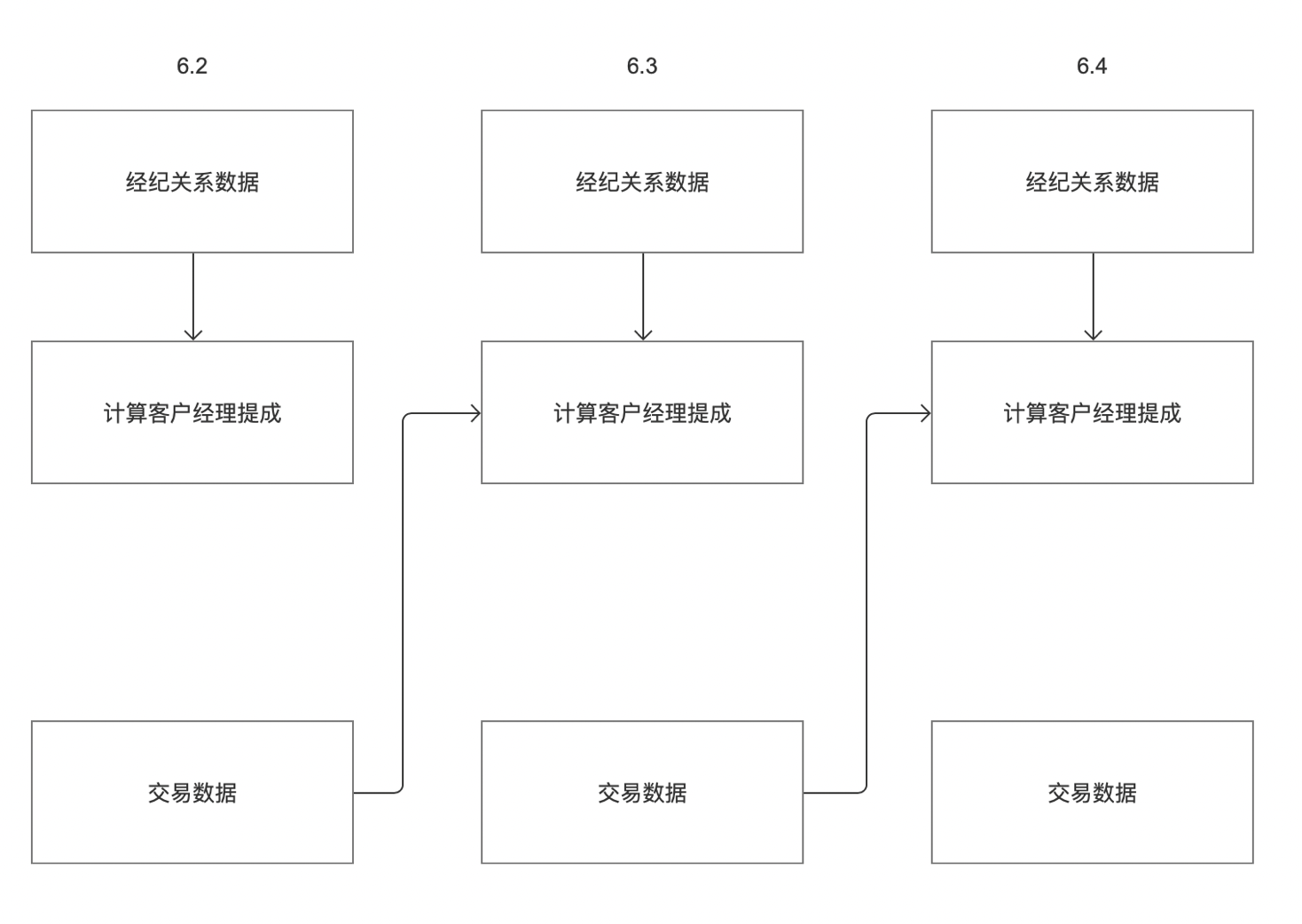
例如客户存在两个业务系统「经纪关系数据」和「交易数据」,客户6.3日的提成需要分别依赖于「经纪关系数据」和「交易数据」计算得出。如图所示,6.2日的「经纪关系数据」业务系统数据产出时间是6.3日。6.2日的「交易数据」业务系统数据产出时间是6.2日晚。按照目前离线的上下游依赖逻辑,「计算客户经理提成」任务只能取到6.3日的任务,无法获取到6.2日的任务。
为了满足客户场景中各种灵活的实例依赖方式,我们支持了自定义依赖实例周期,可以灵活配置依赖上游任务的当前周期实例、上一周期实例、下一周期实例、上上周期实例等等