数据源连接说明
数据源管理是对外部存储单元访问参数的管理,数据集成模块需要与[数据开发]配合起来才能发挥作用,实际是由定时任务来执行数据传输的。
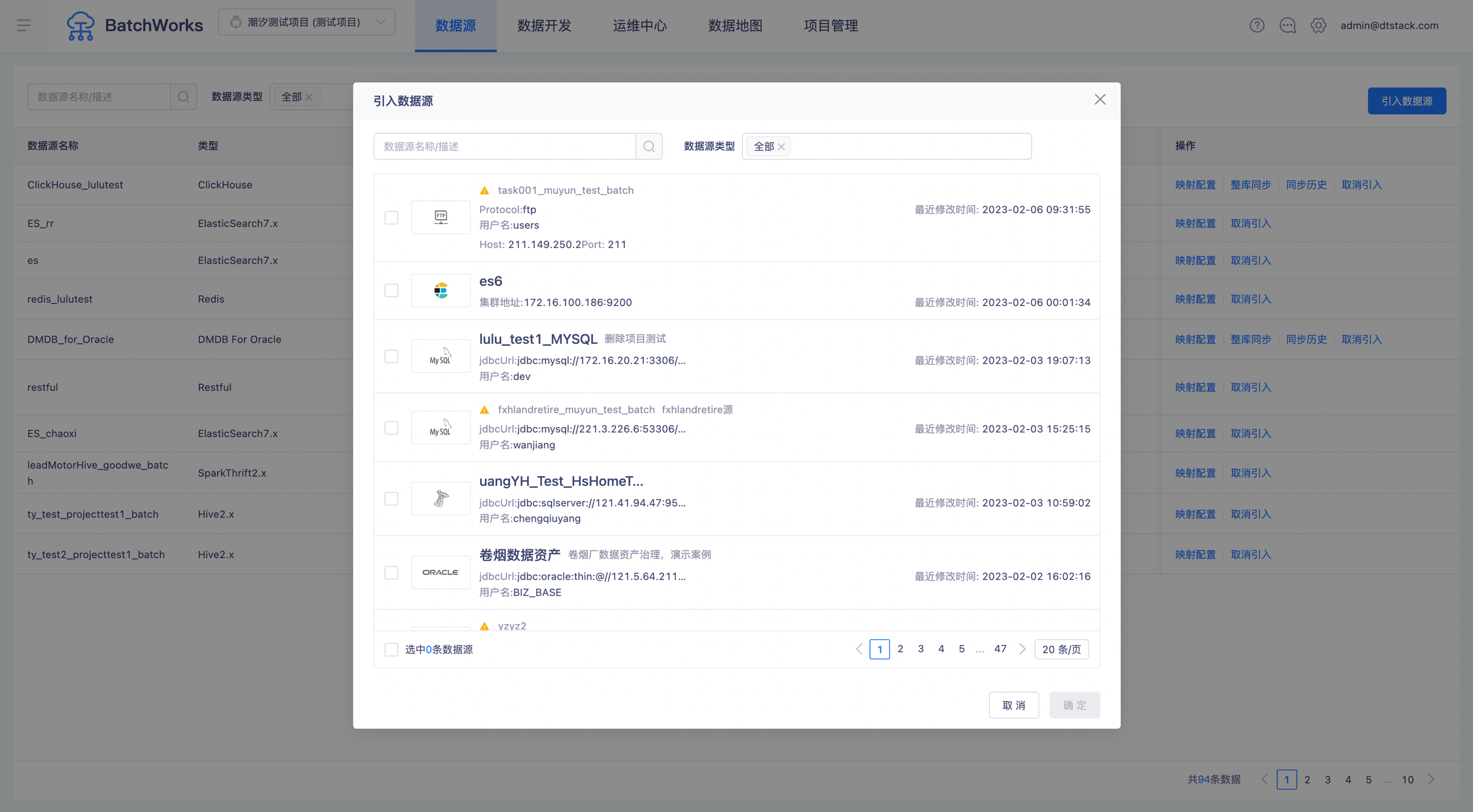
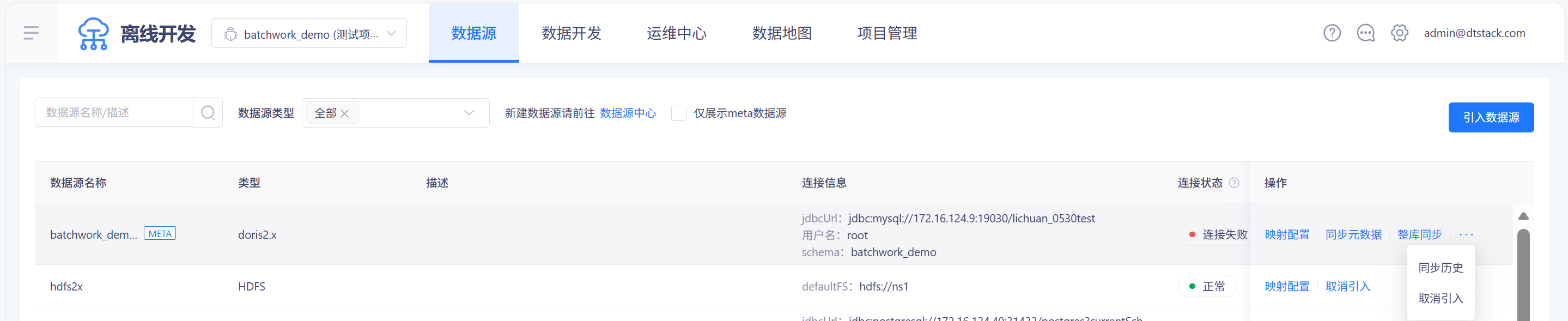
点击上方的「数据源」菜单,进入数据源管理页面,可看到目前已经配置的数据源列表,用户可执行编辑、删除等操作,如下图所示:
配置数据源的步骤可分为三步。
步骤一:点击数据源下的"新建数据源请前往数据源中心",进入数据源中心页面,在数据源中心“新增数据源”,进入数据源配置窗口。
步骤二:配置数据源连接信息,填写数据库连接地址,用户名,密码等。
步骤三:在数据源中心配置完成后,返回离线开发-数据源页面,点击“引入数据源”,进入数据源选择窗口,选择需要引入的数据源后,单击“引入数据源”按键即可。
数据源配置
关系型数据库
关系型数据库数据源的配置基本是类似的,下面的描述适用于:MySQL、PolarDB for MySQL8、Oracle、SQLServer、PostgreSQL、DB2、DMDB(达梦)、KingbaseES8、SQLServer JDBC
参数说明
这里以MySQL数据源为例 * JDBC URL: 访问MySQL数据库的连接地址,JDBC URL格式如:
jdbc:mysql://jdbc:mysql://192.168.1.1:3306/testdb?useUnicode=true&characterEncoding=utf8
- host:MySQL的host名或ip地址
- port:MySQL的访问端口
- dbname:•MySQL的数据库名,用户后续配置API时,可选择库内的数据表。
- 用户名:访问数据库的用户名
- 密码:访问数据库的密码
- 连接参数:demo中是通过 useUnicode=true&characterEncoding=utf8 来指定字符集为UTF8
每个数据源必须指定一个MySQL,如果需要从多个库中获取数据,可配置多个数据源
Oracle通过用户名来标识Schema,其含义是类似的。在同步任务配置时,如果需要同步其他Schema下的数据,则不能在下拉列表中选择表,而是直接输入schemaName.tableName,可同步其他Schema的数据
支持Oracle高可用JDBC连接,格式示例:
jdbc:oracle:thin:@(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.16.8.178)(PORT = 1521))(CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME = xe)))
大数据存储
下面的描述包含:Hive1.x、Hive2.x、Hive3.x、SparkThrift、MaxCompute、HDFS、HBase
参数说明
Hive1.x
这里以Hive1.x数据源为例,下面描述适用于Hive1.x、Hive2.x、Hive3.x、SparkThrift * JDBC URL: 访问Hive的连接地址,JDBC URL格式如:
jdbc:hive2://host:port/dbName
- host:Hive的host名或ip地址
- port:Hive的访问端口
- dbName:Hive的数据库名,默认情况下,可填写默认的数据库名,此数据库名与当前项目的名称相同,您需要点击:项目管理-项目配置,数据库名即列表中的第一行项目名称,注意这里不是项目显示名称。如果您知晓此数据库名可直接填写。
- 用户名:访问数据库的用户名
- 密码:访问数据库的密码
- DefaultFS:默认情况下,此参数配置为:
hdfs://ns1,如果您在Hadoop配置文件中修改了此配置,可以在*/hadoop/etc/hadoop路径下的hdfs-site.xml文件中,找到dfs.nameservices参数对应的值。如下图所示:

在此配置文件中,找到 dfs.nameservices 参数对应的值:

- 高可用配置:补充高可用配置参数,可以使离线开发访问高可用模式下的Hive数据源,高可用配置的示例如下:
{
"dfs.nameservices": "testDfs",
"dfs.ha.namenodes.testDfs": "namenode1,namenode2",
"dfs.namenode.rpc-address.testDfs.namenode1": "",
"dfs.namenode.rpc-address.testDfs.namenode2": "",
"dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
关于HDFS高可用的更多信息可参考 Hadoop官方文档
FlinkX读写Hive表的原理
FlinkX对Hive表的读写,不是单纯通过jdbc做读写,而是通过直接操作HDFS文件实现。在配置关于Hive表的数据同步后,系统可读取到源表(或目标表)对应在HDFS上的路径信息和文件格式,当同步任务执行时,系统直接从相应的HDFS读取文件(或写入文件)并解析其文件格式,完成数据同步。相比通过jdbc的模式,这种直接操作文件的方式效率更高。 基于以上原理:基于FilnkX进行Hive表读写,具有以下几种限制:
- 配置Hive、Impala数据源时,除了填写jdbc之外,还需填写defaultFS信息
- 仅支持普通Hive表,支持分区表,但不支持读取视图
- 文件格式可支持Textfile、ORC、Parquet,暂不支持其他文件格式
Hive1.x与Hive2.x的区别
Hive 1.x与Hive2.x的区别是在Textfile、ORC和Parquet 3种文件格式上有所区别,在配置数据源时需注意区分,在使用、参数配置方面是没有区别的
MaxCompute
- AccessId: 阿里云账号或RAM用户的AccessKey ID。
- AccessKey:AccessKey ID对应的AccessKey Secret。
- Project Name:访问的目标MaxCompute项目名称。
- End Point:MaxCompute服务的连接地址。格式如:
http://service.hangzhou.maxcompute.shuzhan.com/api
HDFS
- DefaultFS:即HDFS的namenode的节点地址,格式如:
hdfs://ServerIP:Port - 高可用配置:补充高可用配置参数,可以本平台访问高可用模式下的HDFS数据源,请参考[Hive的高可用配置]
HBase
- Zookeeper集群地址:
- 必填,多个地址间用逗号分割。例如:
IP1:Port, IP2:Port, IP3:Port/子目录。默认是localhost,在伪分布式模式时使用。若在完全分布式的情况下使用则需要修改。如果在hbase-env.sh设置了HBASEMANAGESZK, 这些ZooKeeper节点就会和HBase一起启动。 - Port: ZooKeeper的zoo.conf中的配置。客户端连接的端口, 默认2181。
- 子目录:HBase在ZooKeeper中配置的子目录。
- 必填,多个地址间用逗号分割。例如:
- 其他参数:以JSON方式传入其他参数,例如:
"hbaseConfig": {
"hbase.rootdir": "hdfs: //ip:9000/hbase",
"hbase.cluster.distributed": "true",
"hbase.zookeeper.quorum": "***"
}
测试连通性
在添加/编辑数据源时,完成参数填写后,需主动测试数据源的连通性,只有数据源连接正常的情况下才可以被添加/编辑。
网络策略上,由于FlinkX的分布式特性,同步任务可能运行在集群内的任一计算节点上,需将离线开发集群的每个节点的网络都与数据源做打通
此处的连通性检测只是表示本平台的WEB服务器与数据库是连通的,实际执行同步任务时,是本平台底层的Flink集群与被访问数据库进行数据交换,因此此处的连通性成功或失败,并不一定表示底层的连通性。
数据源的修改与任务提交
某个数据源已经应用在同步任务中,这些任务已正常运行,若此时修改数据源的连接参数,则相关的任务无需重新提交即可生效。同步任务在每次运行之前,会读取最新的连接参数。
其他配置与信息
默认数据源
在数据源列表中,标记 icon的为本项目的默认数据源,是在项目初始化阶段,根据计算引擎的配置自动生成的数据源连接,默认数据源可以编辑,不能删除,详情请参考 [默认数据源]。
icon的为本项目的默认数据源,是在项目初始化阶段,根据计算引擎的配置自动生成的数据源连接,默认数据源可以编辑,不能删除,详情请参考 [默认数据源]。
映射配置
映射配置分为「未配置」和「已配置」2种状态,映射配置的目的是为了在生产项目和测试项目进行发布时,实现数据源连接信息的替换,详细信息请参考发布管理一节。
应用状态
应用状态记录了本数据源应用在了哪些同步任务中,本数据源可能在同步任务中作为源或者目标,均为被记录为已应用,已应用的数据源目前不支持删除,需先将同步任务修改后才能删除本数据源。
连接状态
为了保证系统与数据源之间的网络连通性,系统每隔10分钟会尝试连接一次数据源,如果无法连通,则会显示为连接失败的状态。若连续3次为连接失败状态,则系统自动发出一条告警信息(暂时不支持关闭)。 当数据源连接处于失败状态时,应及时检查连接信息、网络连通性等因素,否则会影响与本数据源相关的同步任务正常运行。
数据源连接不成功的原因,如果数据源连接不成功,可能的原因和解决方式如下:
1、数据库没有启动,请确认已经正常启动;
2、无法访问数据库所在网络,请确认网络已连通;
3、数据库所在的网络防火墙禁止平台访问,请在数据库中添加白名单;
4、无法正确解析数据库域名,请确认可以正确解析域名访问
Kerberous认证
参考 [项目管理]一节的描述
整库同步
参考 [整库同步]一节的描述
数据源引入对接审批中心
当数据源引入对接审批中心后,项目管理员及以上角色可以拥有权限的离线项目申请对应数据源的权限。经过租户管理员及以上角色权限的用户审批通过后,才会在离线的「引入数据源」弹窗中展现