任务类型
离线开发支持多种计算引擎,不同的计算引擎可以支持不同的任务类型,下面按引擎类型分别说明。
| 引擎与任务的对应关系 |
|---|
<<<<<<< HEAD | 类型 | 引擎 | 支持的引擎/驱动版本 | 任务类型 | | Hadoop引擎 | Flink(on YARN) | 支持引擎版本:1.10、1.12 | 数据同步、Flink |
| | Flink(on Standalone) | | 数据同步 |
| 类型 | 引擎 | 支持的引擎/驱动版本 | 任务 | | Hadoop引擎 | Flink(on YARN) | 支持引擎版本:1.12 | 数据同步、Flink | | | Flink(on Standalone) | 支持引擎版本:1.12 | 数据同步 |
test_6.2.x_publicservice | | Spark | 支持引擎版本:2.1、2.4、3.2 | Spark SQL、PySpark、Spark | | | Hive Server | 支持引擎版本:1、2、3 | Hive SQL | | | Impala | 适配Impala驱动版本:2.6.23-rc1 | Impala SQL | | | inceptor | 适配Inceptor驱动版本:6.0.2 | inceptor SQL | | | | | Shell | | | | | Python | | | | | HadoopMR | | 其他引擎 | Oracle SQL | 适配Oracle驱动版本:12.2.0.1 | Oracle SQL | | | Greenplum SQL | 支持引擎版本:6 | Greenplum SQL | | | DtScript Agent | | Shell on Agent | | | AnalyticDB PostgreSQL | 适配Pg驱动版本:42.2.2 | AnalyticDB PostgreSQL | | | MySQL | 支持引擎版本:5、8 | MySQL | | | SQL Server | 适配SQLServer驱动版本:jdbc:7.2.2.jre8 | SQL Server | | | TiDB SQL | 适配MySQl驱动版本:5.1.46 | TiDB SQL | | | GaussDB SQL | 适配Pg驱动版本:42.2.2 | GaussDB SQL | | | Trino SQL | 支持引擎版本:359 | Trino SQL | | | SAP HANA | 支持引擎版本:1、2 | HANA SQL | | | StarRocks SQL | 适配MySQl驱动版本:5.1.46 | StarRocks SQL | | | HashData SQL | 适配Pg驱动版本:42.2.2 | HashData SQL | | | Doris SQL | 2.x | Doris SQL | | 不需要依赖任何引擎 | | | 工作流 | | | | | 虚节点 | | | | | 事件任务 | | | | | 条件任务 | | | | | Filecopy(文件拷贝) | | | | | Python on Agent | | | | | Shell on Agent |
SparkSQL
SparkSQL是基本的SQL类任务,用户在页面运行SparkSQL时,有如下特殊处理:
- DDL:执行建表、删表、查询元数据等操作时,系统直连Spark Thrift Server进行操作;
- DML:当进行INSERT / SELECT 等操作时,从系统稳定性考虑,不会直连Spark Thrift Server进行查询,而是经由后台调度系统封装为YARN任务进行操作。因此用户感官上会认为这类任务比直连Spark Thrift Server较慢。
SELECT * FROM t的特殊处理:为提高响应速度,当执行这类SQL时,系统不会提交至调度系统,而是根据此表所在的HDFS目录,直接读取HDFS中的文件。
离线开发默认不允许用户绕过平台,直连Spark Thrift Server进行操作,直连操作(尤其是数据量较大时)可能会导致服务不稳定
::tips
Spark 2.1/2.4 不支持inceptor事务表
:::
默认环境参数
HiveSQL
HiveSQL的处理逻辑与SparkSQL类似,不再赘述。
默认环境参数
hive3的开源版本和cdp版本5.0以上,可以支持事务表
ImpalaSQL
ImpalaSQL会通过页面连接JDBC进行查询
Spark
Spark任务,需用户在本地基于Spark的MapReduce编程接口(Java API或Scala API),并打为Jar包,提前将资源包通过「资源管理」模块上传至平台,之后创建Spark任务时引用此资源。
离线开发底层集成的Spark版本为2.1,需按照此版本的Spark API编写代码Spark类型任务支持编写Java或Scala代码
任务创建
- 资源
Spark任务需引用的资源包,需提前经「资源管理」上传至平台。一个任务只能引用一个资源包。
在进行代码打包时,为了缩小包的大小,Spark自带的包无需打包,Spark原生Jar包目录请参考Spark原生Jar包
- mainClass
Jar包的入口类,格式为: org.apache.hadoop.examples 需填写完整类名
- 参数
传参方式与命令行传参形式一致,多个参数用空格隔开,支持填写系统参数或自定义参数(参考 [参数配置](./3_variable.md),例如:
//函数的传参,与命令行方式一致的参数列表【输入路径和输出路径】,例如
/user/hive/tb_user /user/hive/tb_prod/pt=${bdp.system.bizdate}
SHELLCopied!
示例代码
以下为Scala代码示例:
package com.host.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object WordCount {
val LOG = LoggerFactory.getLogger("ScalaWordCount")
def main(args: Array[String]): Unit = {
//创建一个Config
val conf = new SparkConf()
.setAppName("ScalaWordCount")
//创建SparkContext对象
val sc = new SparkContext(conf)
val value1 = args(0)
//WordCount
val value: RDD[(String, Int)] = sc.textFile(value1)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.repartition(1)
.sortBy(_._2, false)
value.foreach(v =>{
print(v._1,v._2)
})
print(value1)
//停止SparkContext对象
sc.stop()
}
}
SCALACopied!
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>wordcount</artifactId>
<groupId>com.host.wordcount</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>SparkWordCount</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>compile</id>
<goals>
<goal>compile</goal>
</goals>
<phase>compile</phase>
</execution>
<execution>
<id>testCompile</id>
<goals>
<goal>testCompile</goal>
</goals>
<phase>test</phase>
</execution>
<execution>
<phase>process-resources</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<compilerVersion>1.7</compilerVersion>
</configuration>
</plugin>
</plugins>
</build>
</project>
XMLCopied!
PySpark
Python任务用于在Spark的Python编程接口(Python API)基础上实现的数据处理程序的周期运行,详细的编码规则请参考 Spark Python API官方文档。完全按照Spark官方的编程接口,您可以将代码打包,并以资源文件的形式上传到本平台中,然后配置Python任务。
HadoopMR
HadoopMapReduce(HadoopMR)任务,需用户在本地基于Hadoop MapReduce API写好Java代码并打为Jar包,提前将Jar包通过「资源管理」模块上传至平台,之后创建HadoopMR任务时引用此资源。
任务创建
- 资源
HadoopMR任务需引用的Jar包,需提前经「资源管理」上传至平台。一个任务只能引用一个Jar包。
- mainClass
Jar包的入口类,格式为: org.apache.hadoop.examples 需填写完整类名。
- 任务参数
传参方式与命令行传参形式一致,多个参数用空格隔开,支持填写系统参数或自定义参数(参考 [参数配置](./3_variable.md),例如:
//函数的传参,与命令行方式一致的参数列表【输入路径和输出路径】,例如
/user/hive/tb_user /user/hive/tb_prod/pt=${bdp.system.bizdate}
SHELLCopied!
示例代码
main函数参数列表第一位必须为Configuration
package org.apache.hadoop.examples.Mapreduce.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount
{
//conf值由{product_name_cn}平台管理
//job.submit 提交后需要返回jobId,返回类型为String
public static String main(Configuration conf,String[] args) throws Exception
{
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));
job.submit();
return job.getJobID().toString();
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
JAVACopied!
已有任务集成
Step1:修改pom.xml文件
首先把pom.xml文件导入
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-examples</artifactId>
<version>2.7.3</version>
<description>Apache Hadoop MapReduce Examples</description>
<name>Apache Hadoop MapReduce Examples</name>
<packaging>jar</packaging>
<properties>
<mr.examples.basedir>${basedir}</mr.examples.basedir>
<project.version>2.7.3</project.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${project.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>utf-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>org.apache.hadoop.examples.Mapreduce.mr.WordCount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
XMLCopied!
Step2:调整代码
Step2.1:修改main方法列表,代码中使用参数列表中的conf 修改前
/*********** 修改前 ***********/
public static void main(String[] args) throws Exception
{
Configuration conf =new Configuration();
}
JAVACopied!
修改后
/*********** 修改后 ***********/
public static String main(Configuration conf,String[] args) throws Exception
{
}
JAVACopied!
Step2.2:job.submit 并返回 jobId 修改前:
System.exit(job.waitForCompletion(true) ? 0 : 1);
JAVACopied!
修改后:
job.submit();
return job.getJobID().toString();
JAVACopied!
数据同步
数据同步任务主要完成数据在不同存储单元之间的迁移,详细的数据同步任务配置规范请参考 数据同步模块。
Python
目前支持Python2、Python3的代码,由平台提交运行,支持在页面中直接运行Python代码或打包上传运行,可以与平台中的其他任务配合形成调度依赖关系。 默认安装的Python版本为2.7和3.6,且默认安装Miniconda,若用户需要其他Python包,需要在服务器上通过pip工具安装pymysql依赖。
Python任务支持依赖资源和引用任务
Pythonl类型任务创建时支持依赖资源和引用任务,在编写Python任务时通过import package_name/task_name的方式来引用资源或已提交的Shell任务和Python任务
Python Zip包形式的使用
当Python代码中包含多个py文件之间的依赖、或配置文件的引用时(例如,可将数据库的连接信息、账号、密码以加密的形式放入配置文件,并在正式代码中获取密码),可使用zip包的形式将一组Python文件打包在一起,下面是具体示例:
Python Zip包形式使用时,其入口文件必须为 __main.py__,否则将会报错找不到main入口。
文件结构及代码
📃__main__.py
📂core
📃basic.py
__main__.py文件
# __main__.py
from datetime import datetime
import core.basic # 引入core文件夹下的basic.py文件
import sys
def main (argv): #入参的获取
print('argv[0]='+argv[0])
print('argv[1]='+argv[1])
print('argv[2]='+argv[2])
print('argv[3]='+argv[3])
print('this command is from core.basic.execute_basic:'+core.basic.execute_basic('中文输入'))
if __name__ == '__main__':
main(sys.argv)
basic.py文件
# basic.py
def execute_basic(input) :
print('input='+input)
return input
压缩及上传
将文件、文件夹压缩为zip包,并上传至离线开发平台「资源管理」模块中。
创建任务、传参及运行
点击「数据开发-创建任务」,选择Python类型后,选择Python版本、资源上传模式、选定刚刚上传的资源,并填写入参。
入参的规则
- 多个入参以空格隔开。
- 入参支持填写系统变量,例如
${bdp.system.bizdate}等。
入参的获取
在上文的main函数中,可通过 argv 来获取这里填写的入参,平台在运行此代码时,会自动将系统参数进行替换。
def main (argv): #入参的获取
print('argv[0]='+argv[0])
print('argv[1]='+argv[1])
……
……
注意,argv 获取参数时,argv[0] 用于Python本身,示例中仅传入3个参数,分别通过 argv[1]~argv[3]来获取。
运行任务
目前Python Zip包的任务不支持页面直接点击运行,只能通过「提交-补数据」的方式运行,可在补数据页面通过下载日志来查看具体输出(目前仅支持下载查看详细日志)。
若运行日期为2022-03-20,则上述代码的核心输出如下:
Container: container_e95_1661428381270_56969_01_000002 on node-datanode-014_33927
====================================================================================
LogType:task.out
LogLength:166
Log Contents:
argv[0]=16_py_test_muyun_main_test_py.zip
argv[1]=muyun
argv[2]=中文
argv[3]=20220319
input=中文输入
this command is from core.basic.execute_basic:中文输入
End of LogType:task.out
Shell
Shell类型任务支持标准的Shell语法,不支持交互式语法,运行在YARN上
Shell任务支持依赖资源和引用任务
Shell类型任务创建时支持依赖资源和引用任务,在编写Shell任务时通过./taskname或者sh taskname的方式来引用资源或已提交的Shell任务和Python任务
Shell on Agent
Shell on Agent 与 shell on yarn的区别
在对「Shell on Agent」任务进行配置时,用户可以在节点标签(label)下部署多台服务器,在「Shell on Agent」任务被创建后,用户可以指定节点标签去运行。任务会被随机分配到节点标签下的任一服务器去运行,不会占用固定的资源,可以满足大批量shell任务运行的场景。「shell on yarn」任务是运行在yarn上,占用固定内存和核数,无法满足大批量shell任务运行的场景。
一、在EM上安装DTSheller
操作系统:CentOS7.4-7.6
- 添加主机
在EM页面的“集群管理”下,用sudo免密账号接入EM agent ,可以指定主机运行「Shell on Agent」任务。
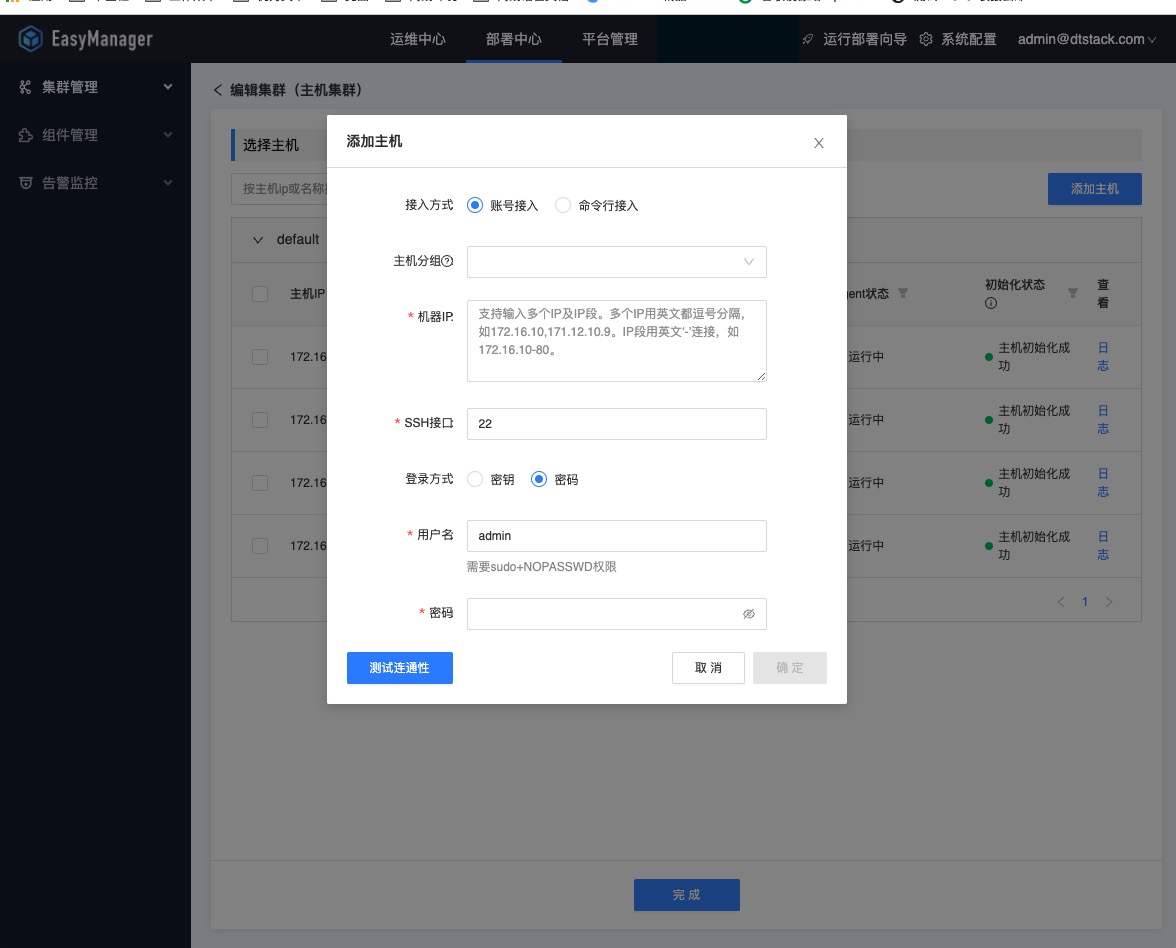
如果需要指定用户执行脚本任务,那么添加主机时,需要使用root用户启动;如果不需要指定用户执行「Shell on Agent」任务,用sudo账号登陆即可。
- 从运维处获取获取DTSheller和DTBase的安装包
- 安装MySQL
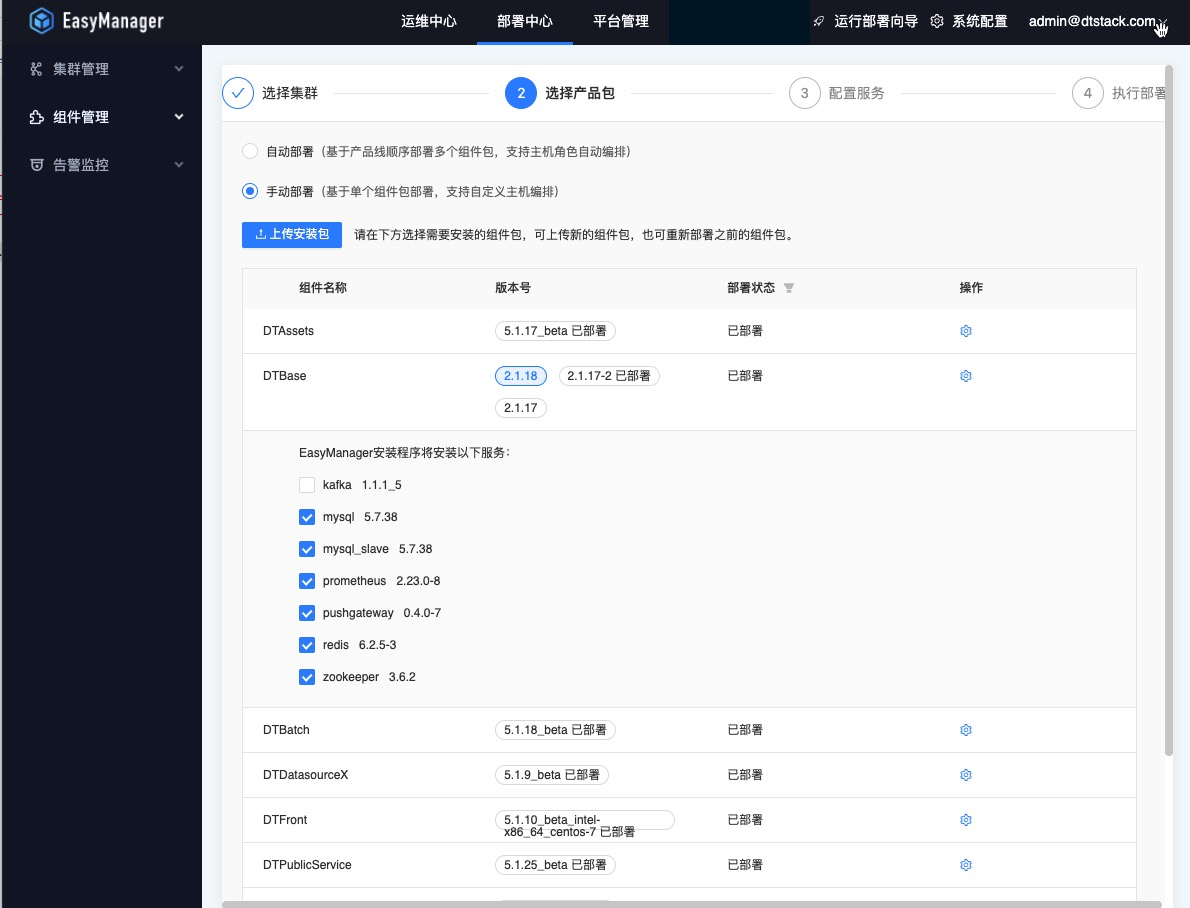
打开EM,在“部署中心->组件管理”页面上传DTBase产品包并安装MySQL
- 安装DTSheller
(1)
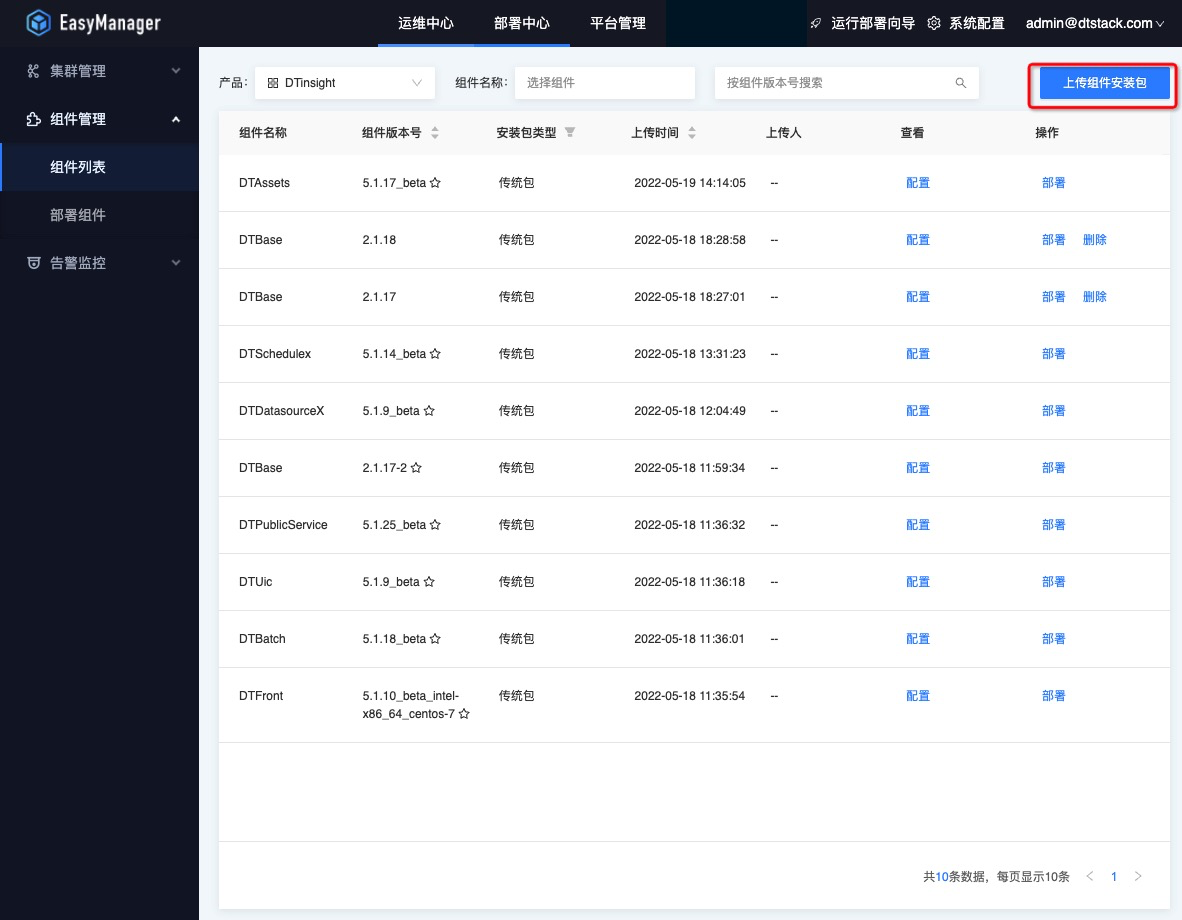
登陆EM,在“部署中心->组件管理”页面点击“上传组件安装包”或调接口上传DTSheller产品包
(2)开始部署DTSheller产品包,主机编排要求如下:
- agentServer组件部署一台或者多台主机,若需要支持高可用则部署多台
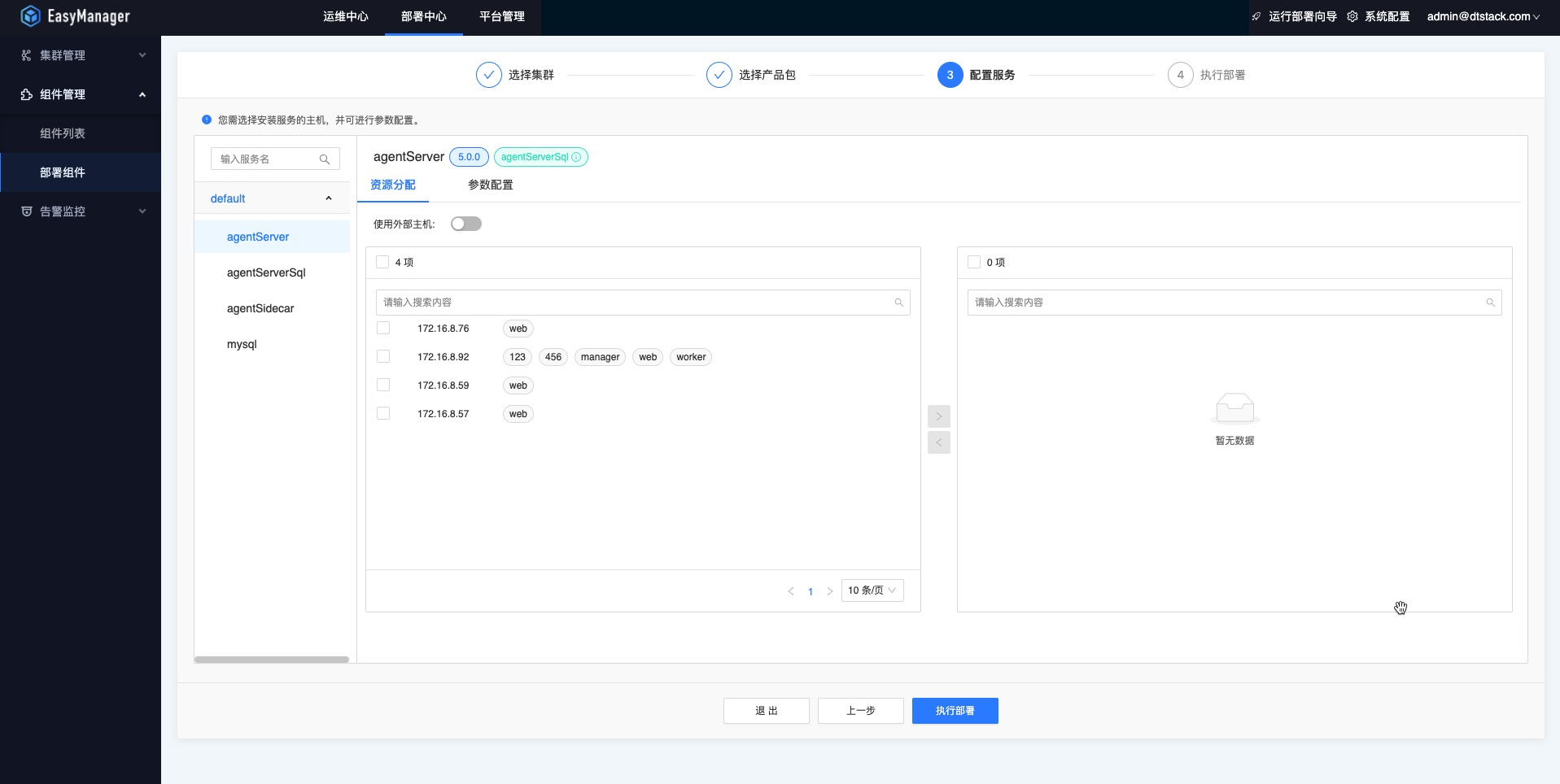
- agentServerSql组件部署在MySQL服务部署的机器上
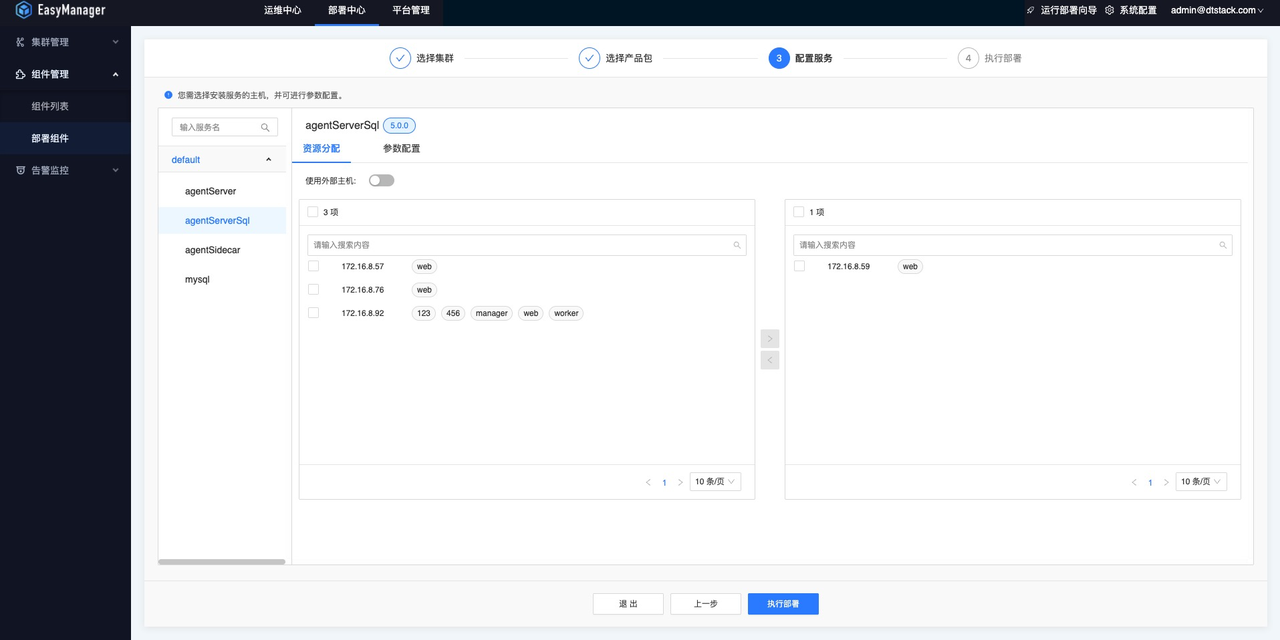
- agentSidecar组件部署在需要执行shell脚本的客户机器上
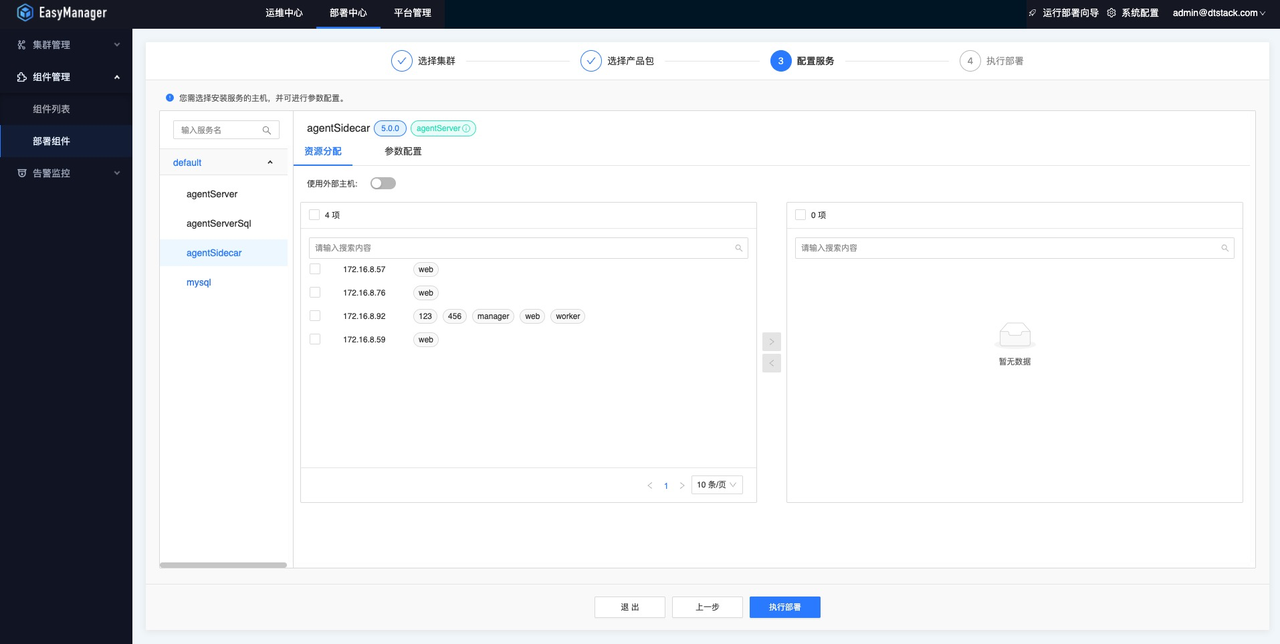
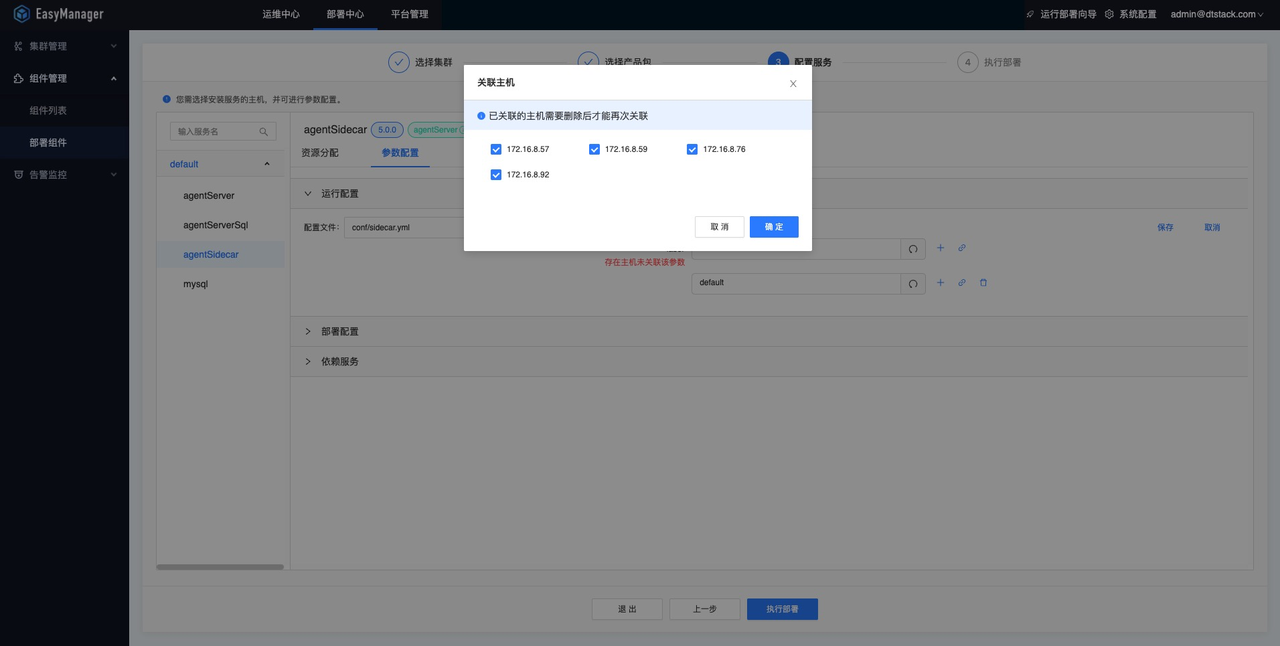
初始状态下,默认存在一个节点标签(label)。如有需求修改部署easyagent-sidecar机器的节点标签(label),可以在运行参数处修改,一个节点标签下可以部署多台服务器。当「Shell on Agent」任务被指定在某节点标签下运行时,会被随机分配至该节点标签下的随机服务器上运行。
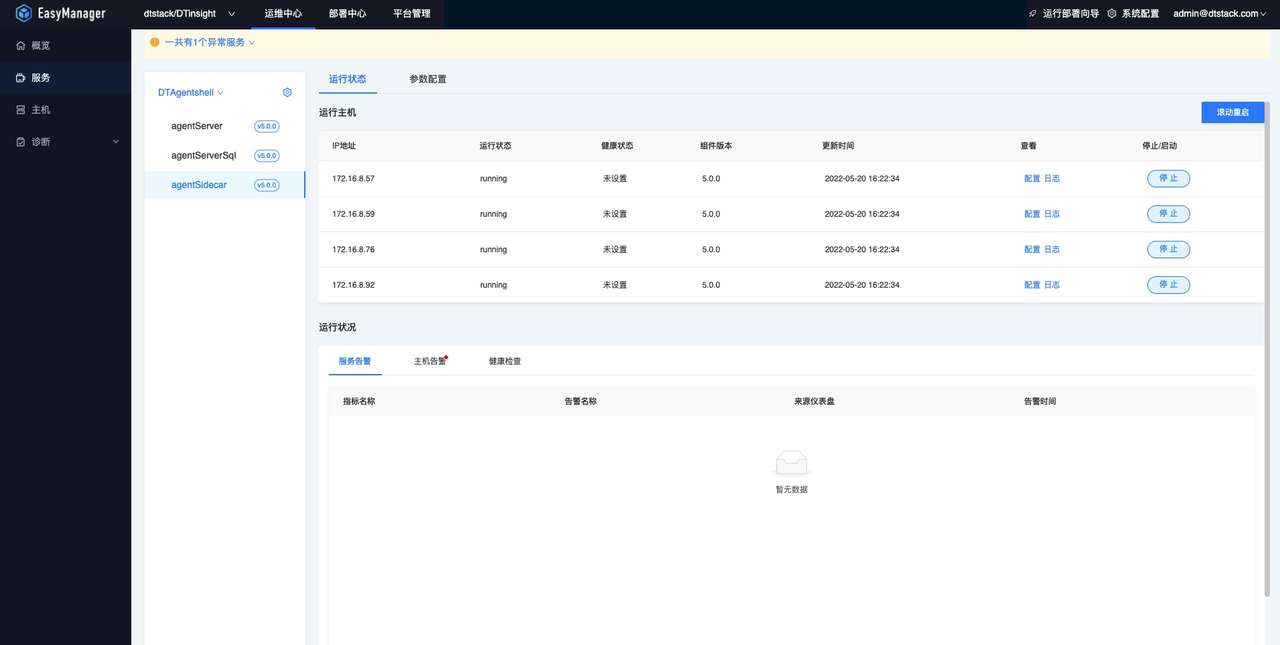
(3)部署完成后,在EM的“运维中心->服务”页面,可以查看部署的实例状态:
二、配置DtScript Agent组件
在控制台的“多集群管理”页面下,选中租户所对应的集群进入“集群配置”页面,切换至“计算组件”功能区,选中「DtScript Agent」计算组件,开始配置。
在「agentAddress」后填写在EM上配置的agentServer的运行主机IP,这样就完成了DtScript Agent组件配置
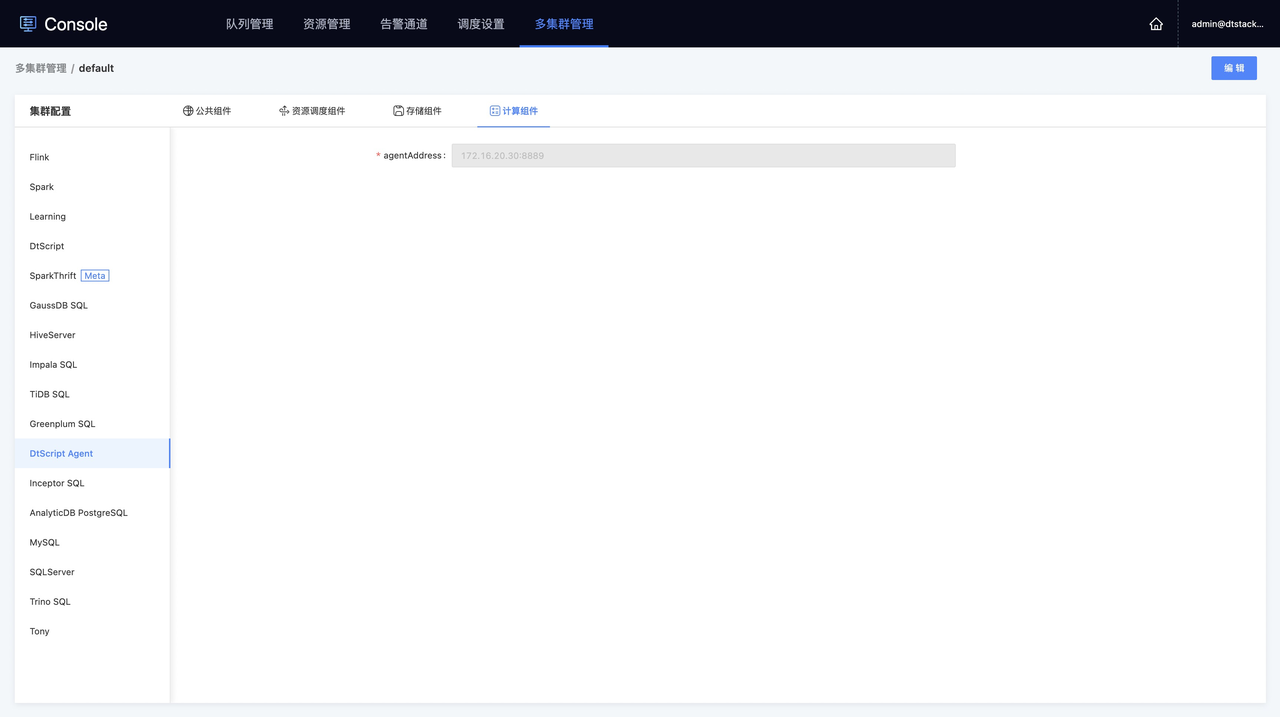
点击「查看节点标签和IP对应关系」按钮,可以查看在EM上agentSidecar配置的节点标签(label)和服务器的对应关系。还可以进行默认节点标签的设置,在离线上新建的「Shell on Agent」任务默认是运行在默认节点标签下的服务器上。
在此处添加的服务器用户名和密码,必须是当前节点标签下多台服务器同时存在的用户,这样做只为了任务被分发至任一服务器时,能正常运行。
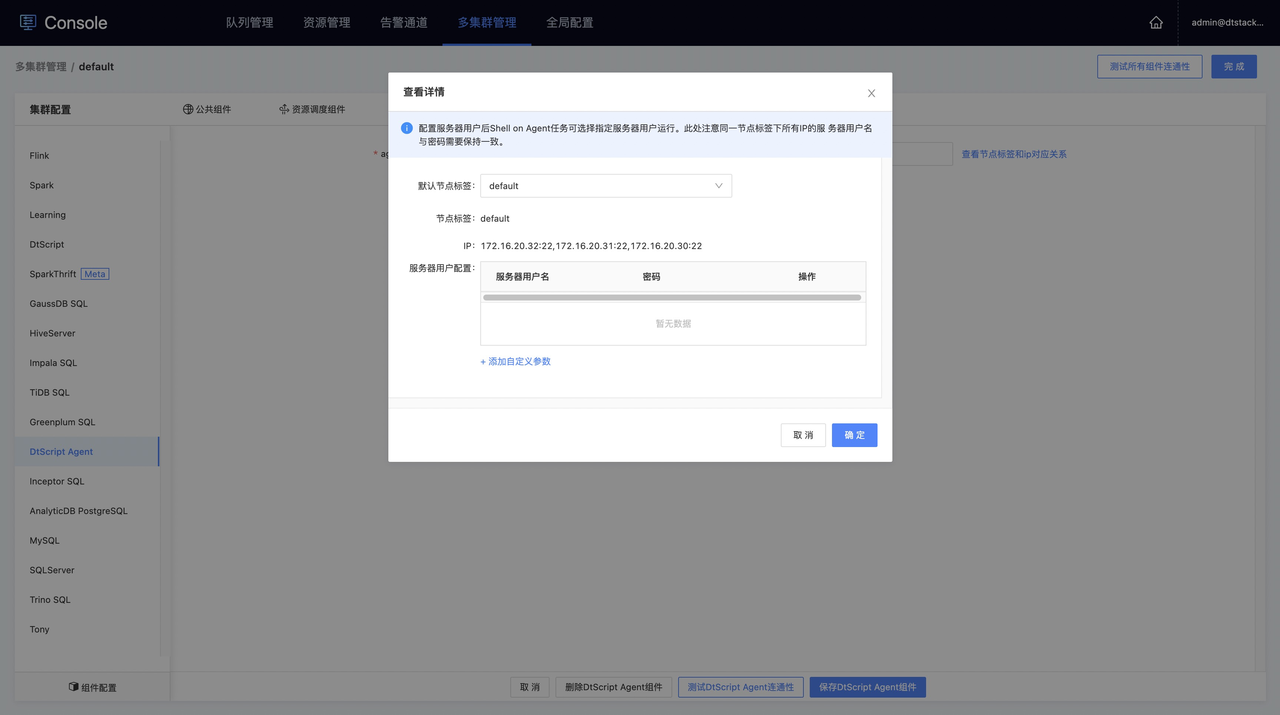
三、在离线平台创建任务
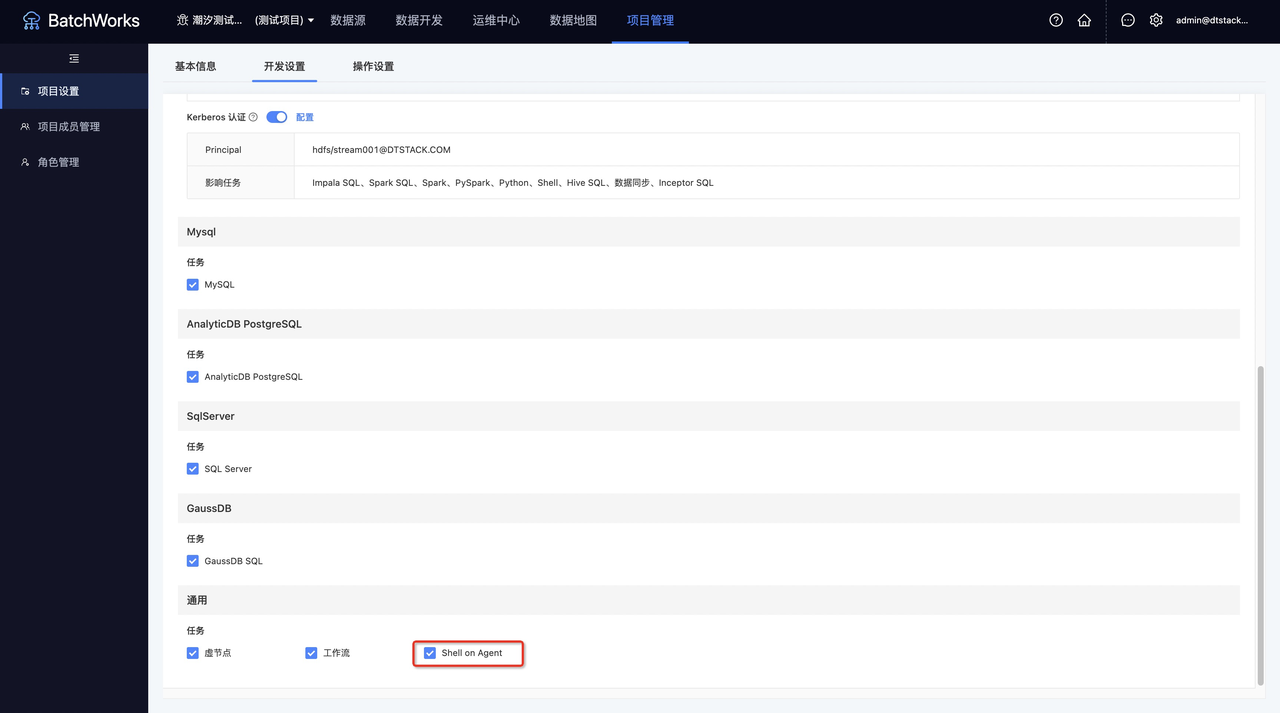
在“项目管理->项目设置”菜单下,切换至开发设置tab页,在通用任务下,勾选「Shell on Agent」任务。
切换回数据开发页面,即可新建「Shell on Agent」任务。
在环境参数中,可以选择在EM上配置的节点标签(label)以及配置在控制台上用来运行「Shell on Agent」的服务器用户。
任务运行时,发送到指定的节点标签下的随机一台服务器下运行,任务不指定机器用户时,实际使用admin账号运行。
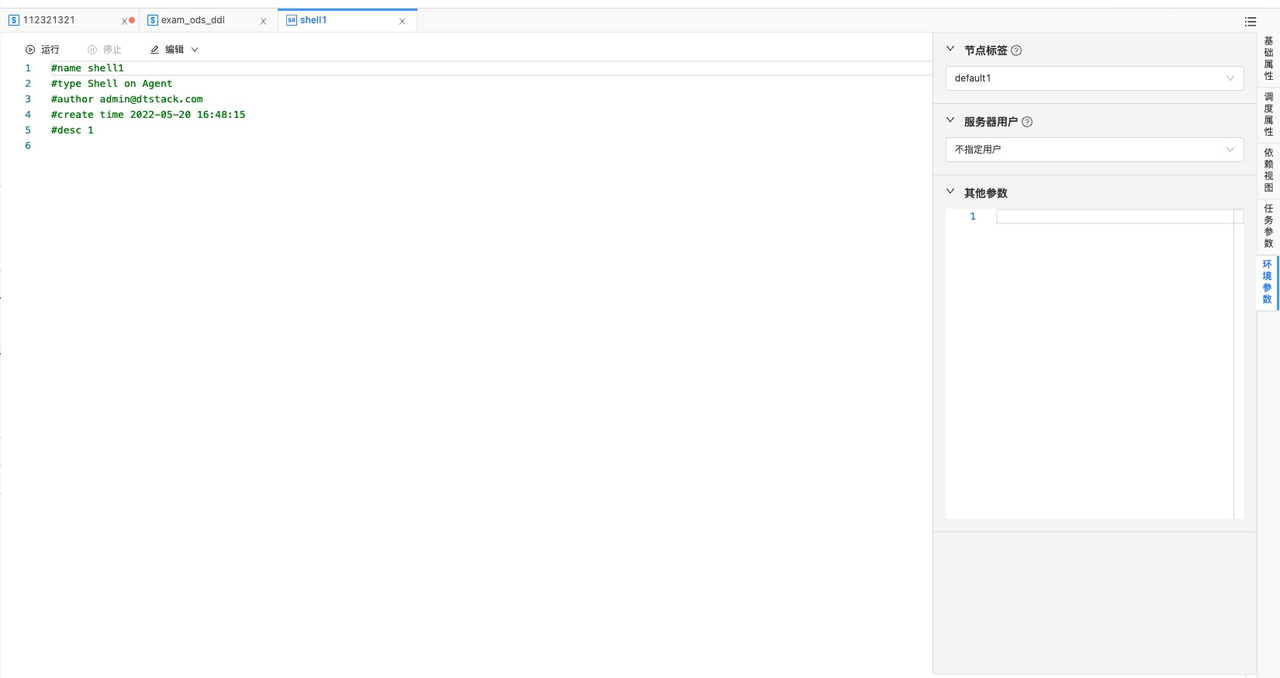
Python on Agent的配置方式和操作方式和Shell on Agent一致。
Inceptor SQL
SQL语法可参考官网。
工作流
工什么是工作流任务
工作流任务满足根据业务视角来组织数据开发任务的需求,可以将某一业务数据开发流程,在工作流中进行统一管理。
工作流任务相当于一个「白板」,里面可以包含若干「节点」,每个节点相当于一个任务。用户可以自由组织节点之间关系,搭建符合业务场景的工作流。
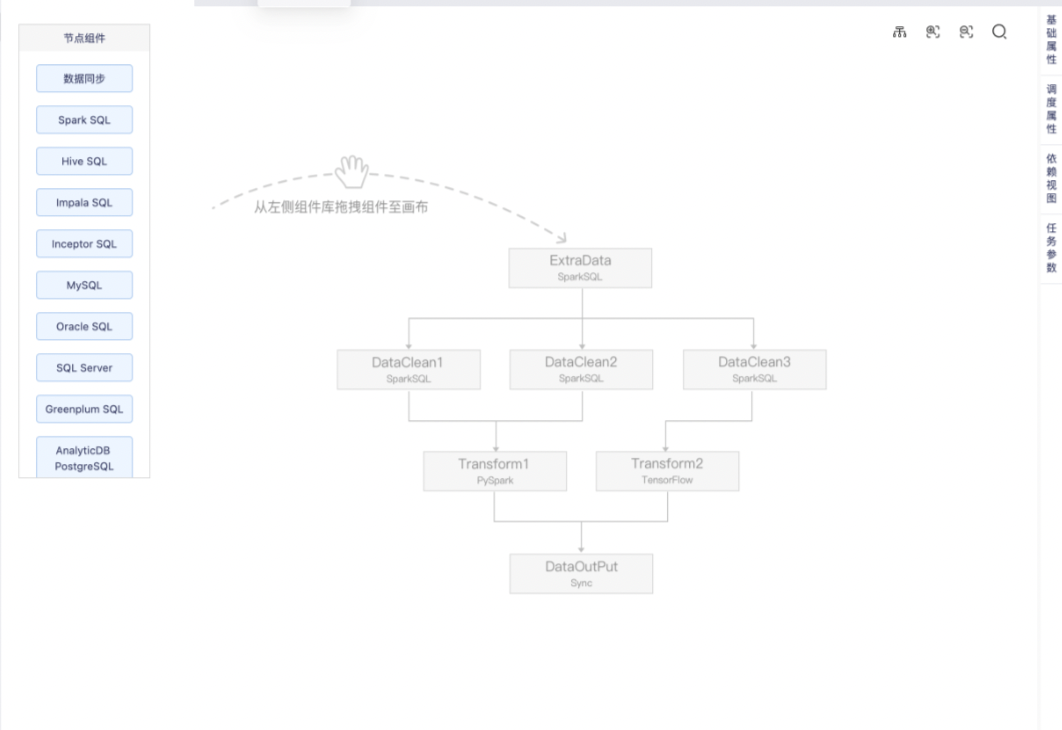
与普通任务的异同点
| 对比项 | 普通任务 | 工作流 |
|---|---|---|
| 任务命名 | 项目内唯一 | 工作流,及工作流内部的每个节点都必须在项目内唯一 |
| 依赖配置 | 依赖配置较为灵活 | 整个工作流必须作为一个整体,作为其他任务的上游或下游,不支持将依赖关系指定到工作流内部的节点 |
| 调度配置 | 调度配置较为灵活 | 所有工作流子节点的调度配置和工作流父节点统一,不支持修改 |
| 运行参数 | 支持输入参数、输出参数、项目参数、全局参数、自定义参数、基于全局参数的偏移 | 子节点支持输入参数、输出参数、项目参数、全局参数、自定义参数、基于全局参数的偏移、工作流参数。父节点支持创建工作流参数,子节点引用。 |
| 运维操作 | 可灵活进行重跑、杀死、补数据等操作 | 一般是工作流整体进行重跑、杀死、补数据等操作,也可以对部分节点进行操作,但操作入口较深 |
工作流任务新建与操作
创建工作流任务
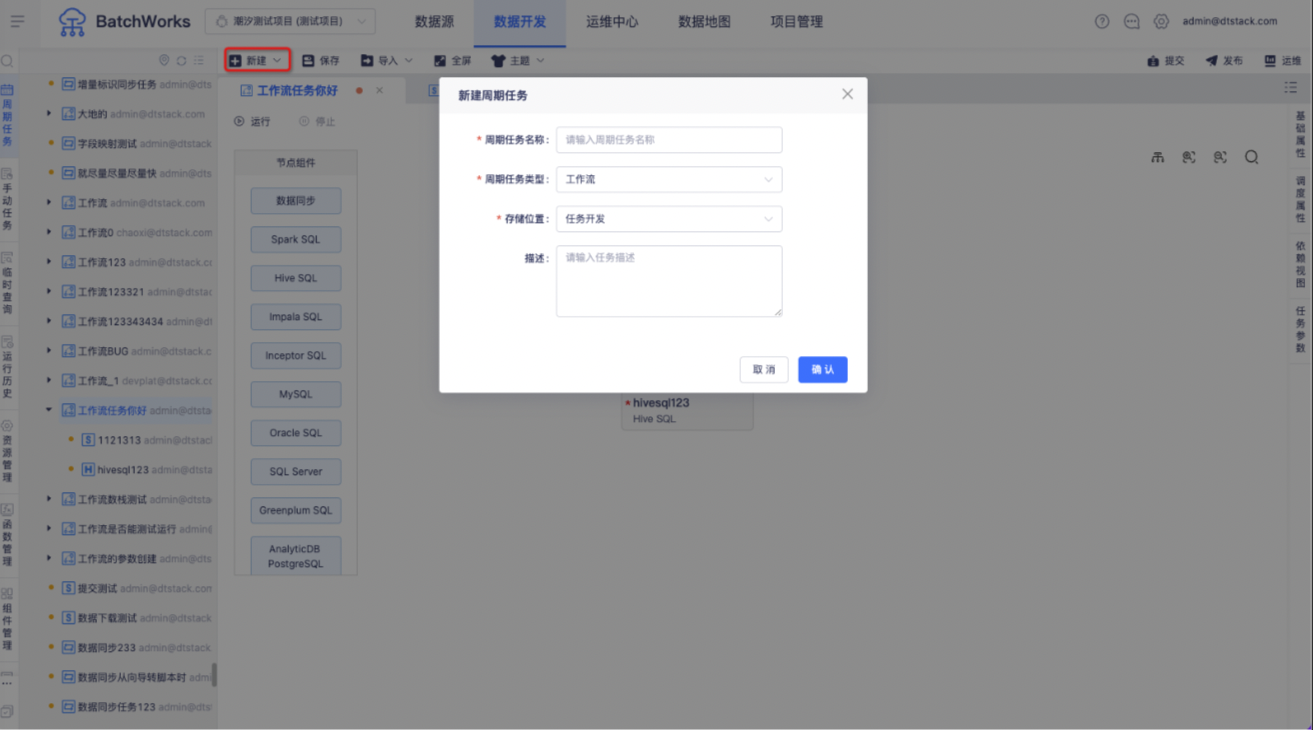
在「离线开发->数据开发」中,单击「新建」按钮,打开新建任务弹窗。选择任务类型为“工作流”,并在输入框中填写任务名称和描述,单击确认后完成新建。
创建工作流子节点
从左侧「节点组件」中,拖拽节点至画布,在弹窗中补充相关信息可建立节点。
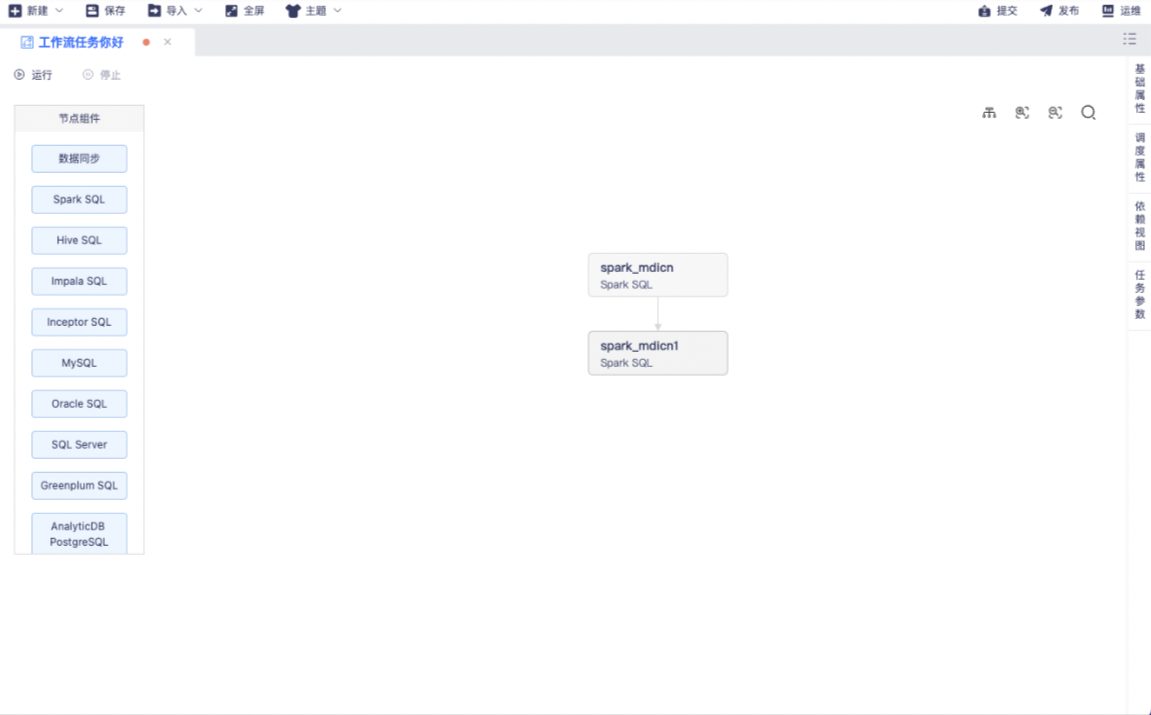
子节点建立上下游关系
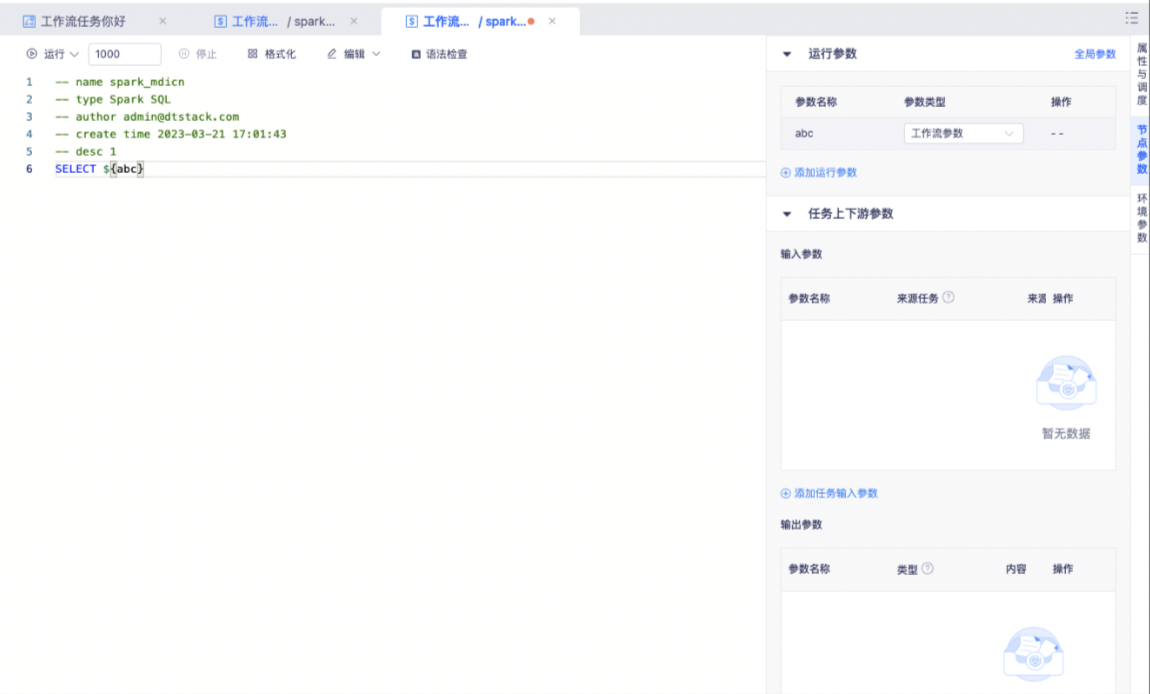
在两个子节点间,可以建立连线,任务将按连线的上下游依赖关系运行。箭头的子节点为下游,箭尾的子节点为上游。如图所示,“spark_mdicn”为“spark_mdicn1”的上游。
工作流参数配置
工作流参数
工作流参数是作用域为当前工作流的参数,仅在当前工作流生效。在父节点创建工作流参数后,可以在子节点通过${参数名称}的方式进行引用。
其他参数
工作流子节点除了支持工作流参数外,支持的其他参数配置和普通任务一致。可以参考帮助文档的「参数配置」一栏。
工作流临时运行
工作流临时运行支持以下六种运行方式
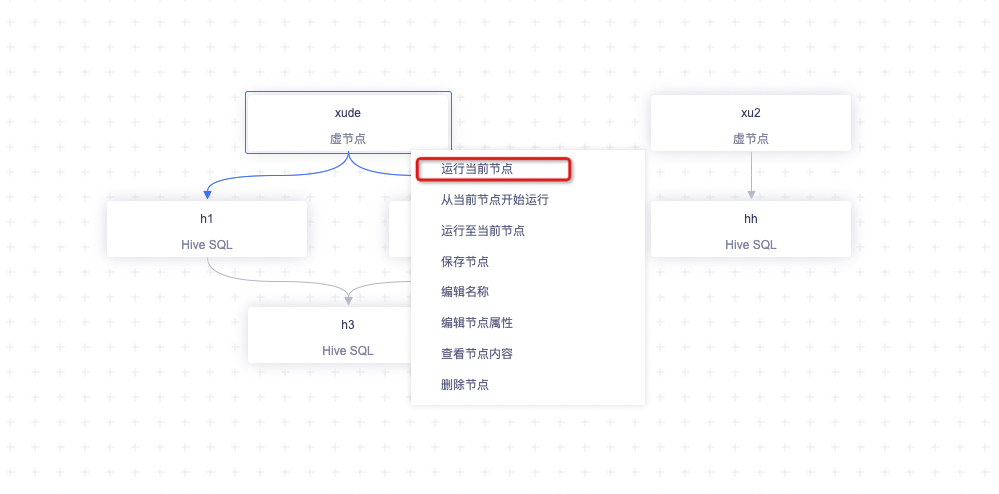
运行当前节点
右键子节点可以选中「运行当前节点」
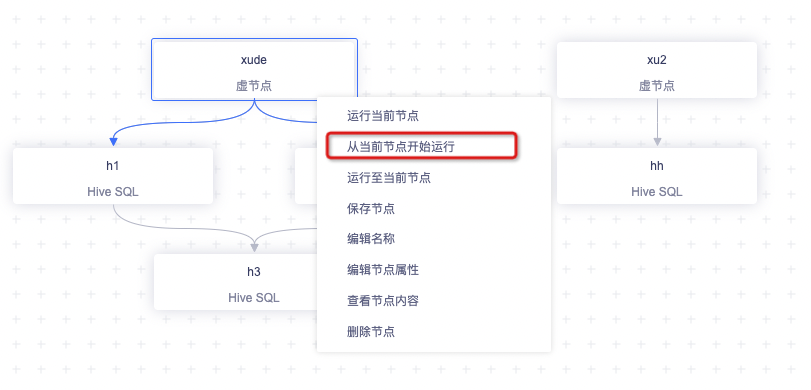
从当前节点开始运行
右键子节点可以选中「从当前节点开始运行」
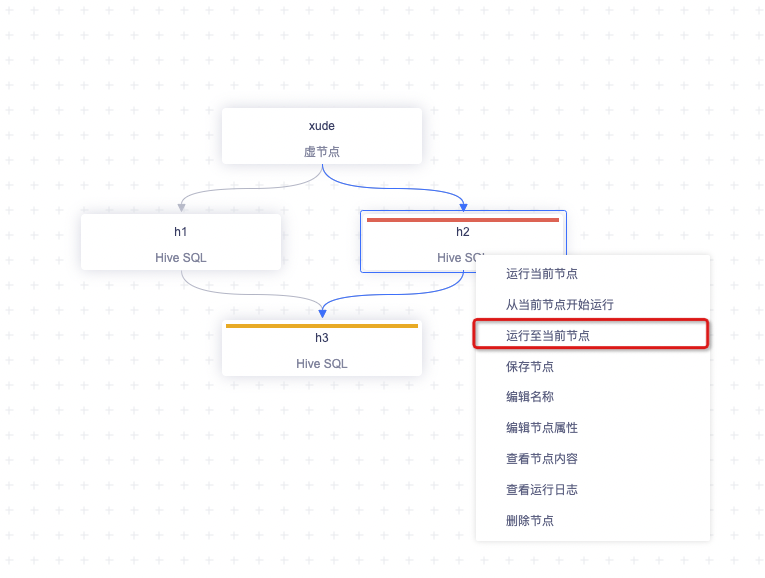
运行至当前节点
右键子节点可以选中「运行至当前节点」
整体临时运行
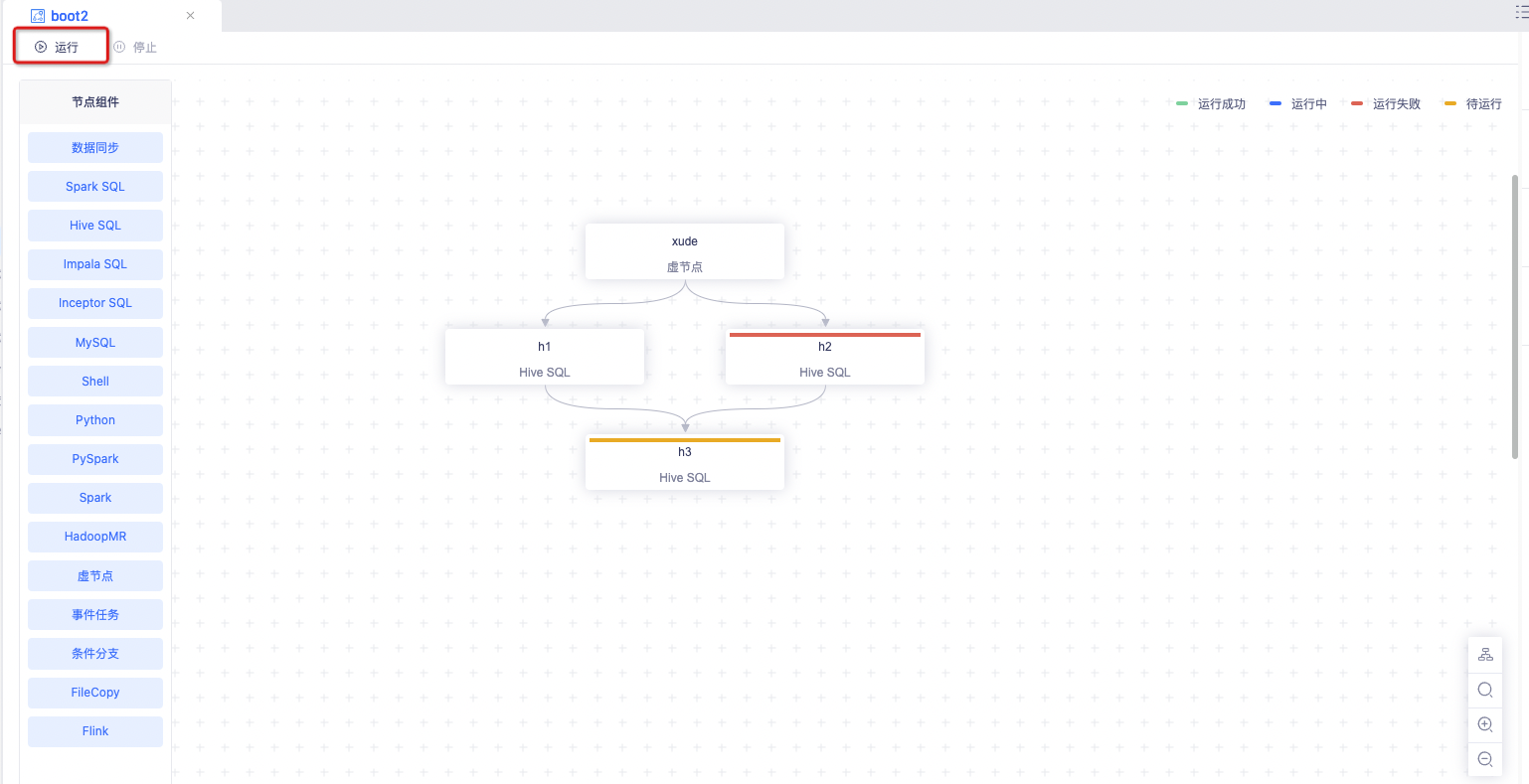
运行至选中节点
批量框选子节点可以选中「运行至当前节点」
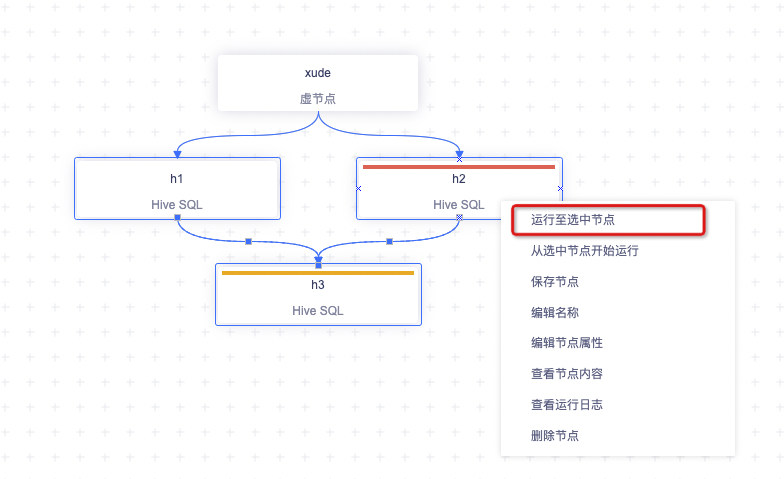
从选中节点开始运行
批量框选子节点可以选中「从选中节点开始运行」
画布操作
- 拖拽:可从左侧拖拽节至画布,在弹窗中补充相关信息可建立节点
- 多选:左键长按圈选或通过ctrl/command选中,可以选择多个子节点执行操作
- 画布操作:支持自动整理、放大、缩小、搜索操作,自动整理时可能会发生连线重叠的情况,单击某个节点可高亮相关连线
- 节点连线:hover在某个节点的下部,按住左键可进行节点间的连线。任务将按连线的上下依赖关系运行,上游任务成功后,下游任务才具备运行条件
- 双击节点:进入节点信息编辑页面,例如双击SparkSQL类型的节点,进入SQL编辑页面
- 节点操作:右键单击节点,弹出右键菜单
- 保存节点:保存当前节点的所有信息
- 编辑名称:编辑当前节点的名称
- 编辑节点属性:编辑当前节点的属性信息,例如Spark Jar类型的节点,编辑的弹窗与新建节点的弹窗是一样的,可通过这种方式执行替换Jar包等操作
- 查看节点内容:与双击节点相同
- 删除节点:删除本节点及相关的连线(此操作不可撤销)
- 删除连线:右键单击连线,可删除此连线
- 节点依赖要求:
- 需设置一个唯一的起点,整个工作流不能有多个起点
- 工作流内部依赖可以有分支,但不能成环
- 提交: 工作流需要将每个节点的配置信息分别保存后才可以提交
- 调度与依赖配置:工作流作为一个整体,可以配置调度依赖、上下游依赖等信息。工作流内部的每个节点,可以单独设置是否冻结、重试配置和起调时间
- 起调时间:工作流整体有启动运行的时间,所有子节点的起调时间和父节点统一,不支持修改。
- 节点参数、环境参数:每个节点单独配置,与普通任务相同
虚节点
虚拟节点属于控制类型任务,是不产生任何数据的空跑任务,常用于多个任务统筹的上游任务(例如作为工作流的初始节点)。假设:输出表由3个数据同步任务导入的源表经过SQL任务加工产出,这3个数据同步任务没有依赖关系,SQL任务需要依赖3个同步任务,则任务依赖关系如下图所示:
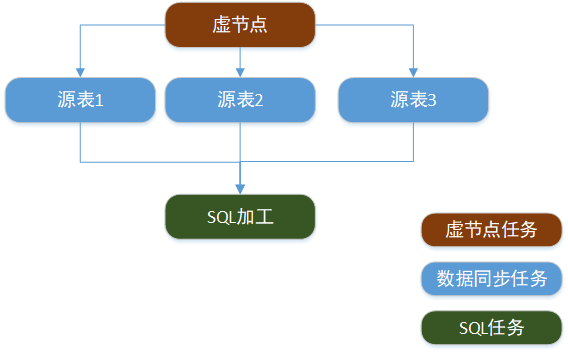
用一个虚节点任务作为起始根节点,3个数据同步任务依赖虚节点,SQL加工任务依赖3个同步任务。
虚节点任务不会真正的执行,虚节点具备运行条件时,将直接被置为成功,所以虚节点没有日志信息
事件任务
概述
事件任务的本质是可接受外部http触发信号,通过调用事件任务的接口,链接到平台。
在日常的客户场景中,可能存在不止一套调度系统。在使用平台前,客户可能已经在使用另一套调度系统,需要将任务从原调度系统上迁移到本平台,但因任务依赖链路比较长且复杂,涉及生产使用,无法一次性全部迁移完成需要逐批迁移(存在一棵依赖树先迁移部分到本平台,剩下部分还在原调度系统的情况),这个过程中需要本平台与原调度系统进行任务依赖,全部迁移完成后跨系统依赖场景消失。
如下图,A、B、C、D、E、F存在于同一条依赖链路上,D、E、F已迁移至本平台调度系统上,但A、B、C还在原调度系统上,则C任务就无法唤起D任务运行,这时就需要「事件任务」来进行衔接。
当外部任务和本平台任务的调度周期不一致时,事件任务与上游外部依赖任务的调度周期及计划时间需要完全一致。
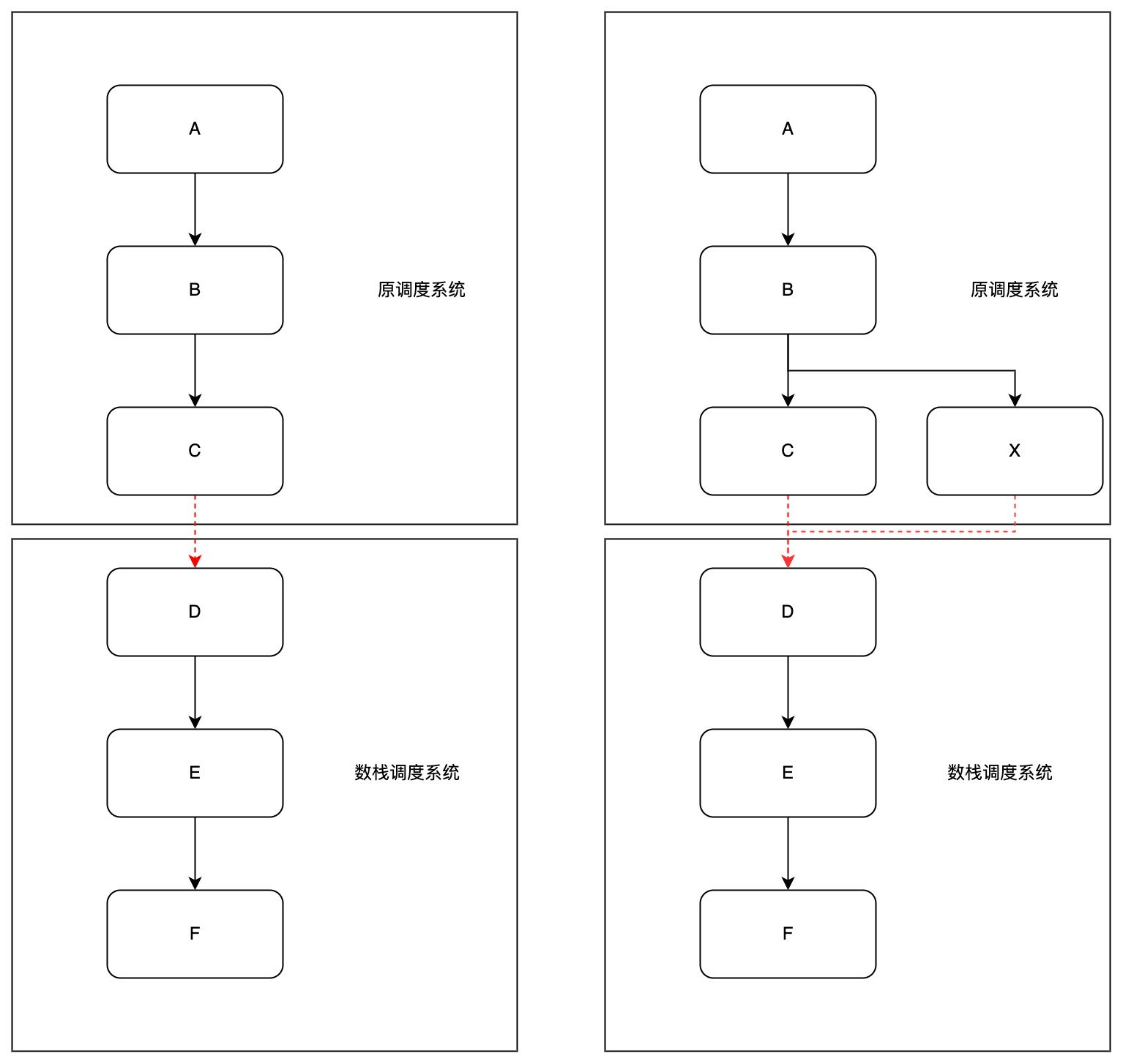
事件任务就可以满足这种场景,外部调度系统通过一个触发任务,调用本平台事件任务中的接口来完成触发,让离线任务可以依赖外部调度系统的结果运行。
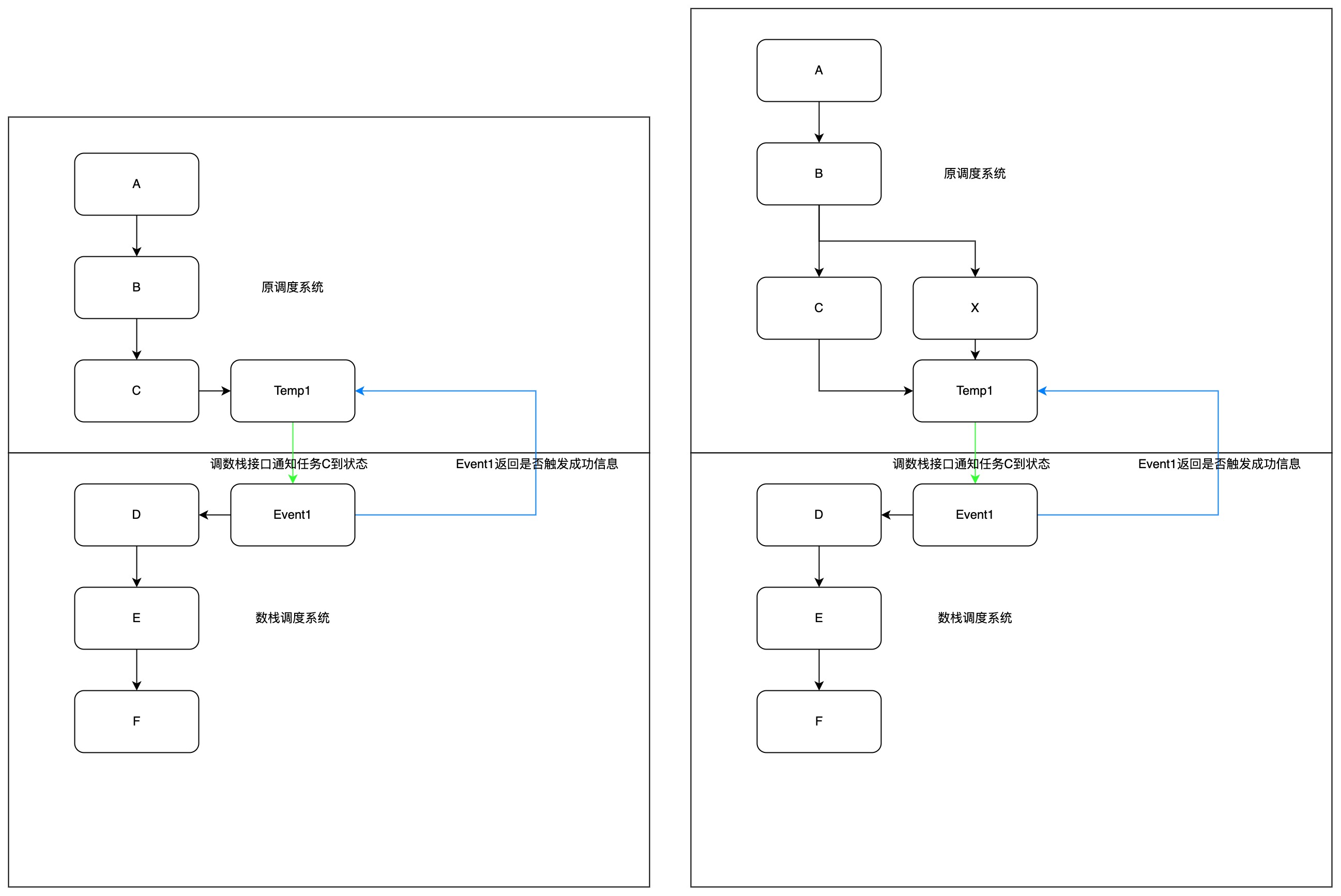
当断点处有多个任务依赖的情况下时,Temp1需要获取C和X的任务状态通知给Event1。
创建事件任务
在「项目管理->开发设置->通用」中可勾选「事件任务」,如图所示
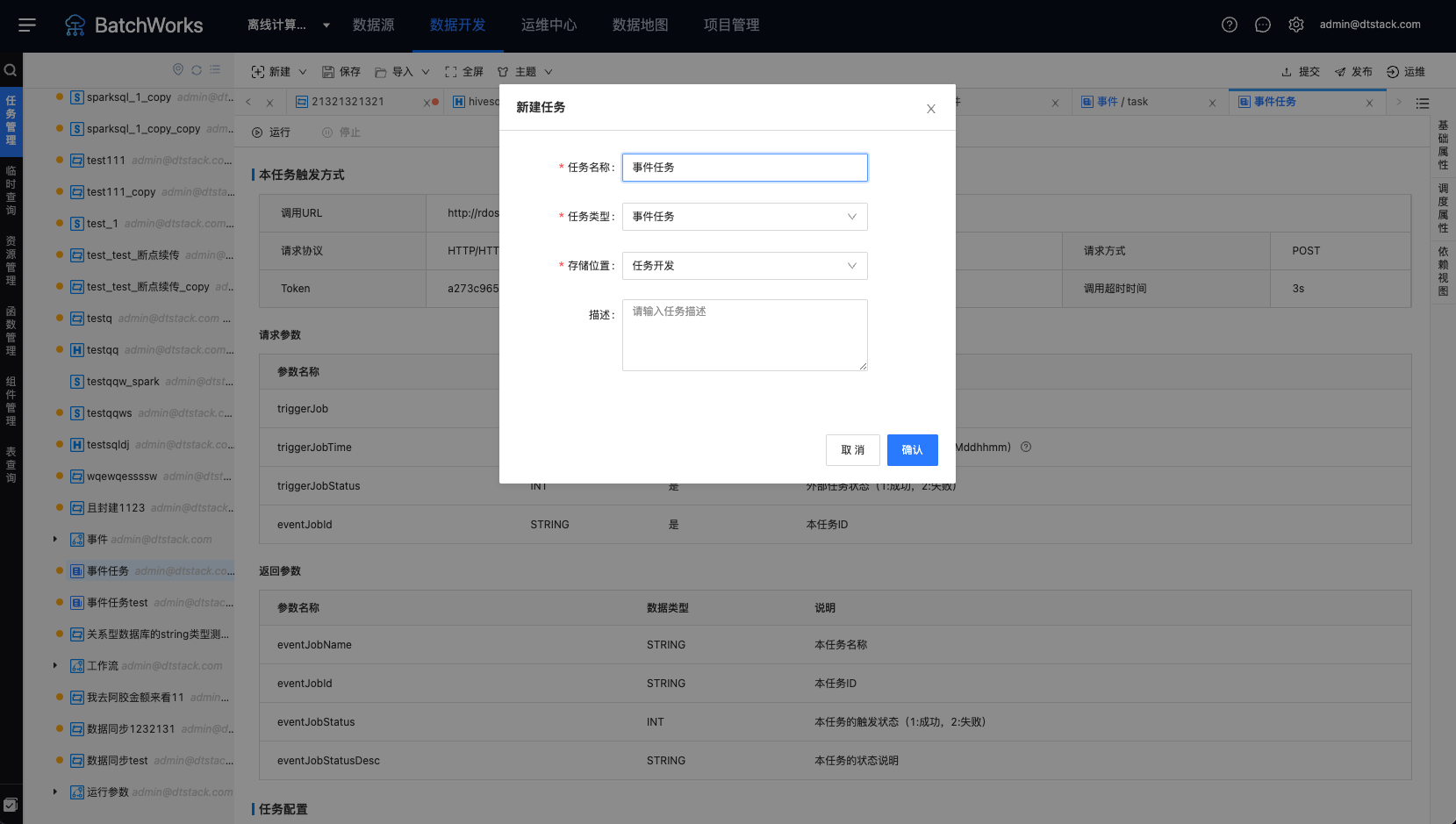
可在「数据开发->新建任务」创建「事件任务」,如图所示
使用事件任务
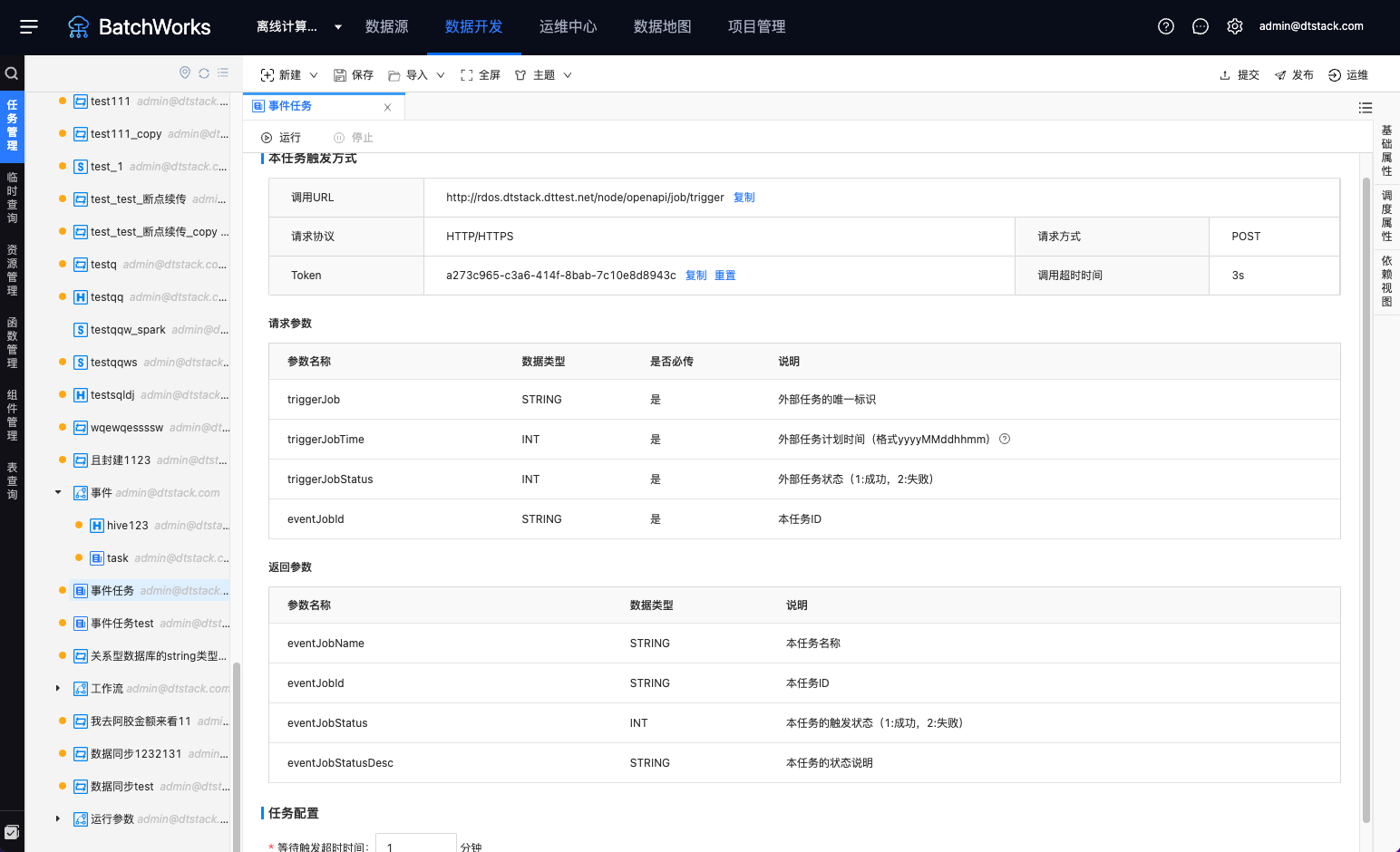
事件任务创建成功后,如下图所示,展示任务触发方式、请求参数、返回参数、任务配置等信息。事件任务除额外能接收外部触发信号外,其他调度周期、本平台内任务依赖配置等周期任务相关的一些配置内容都跟普通任务一样
本任务触发方式:事件任务URL、请求方式和Token等信息
请求参数:调用事件任务,需要填写的请求参数信息
返回参数:调用事件任务后,事件任务返回参数信息
任务配置:事件任务开始运行后,最长等待触发时间
事件任务的工作原理如下
外部调度系统新建shell/python任务Temp1,获取任务C状态
调事件任务Event1提供的接口将任务C的状态通知给Event1
调用curl格式如下
curl --location --request POST 'http://127.0.0.1:8090/node/openapi/job/trigger' \
--header 'token: ced64f5385a040a4aaf08790fc100ef0' \
--header 'Content-Type: application/json' \
--data-raw '{
"eventJobId":58453,
"appType":1,
"triggerJobStatus":1,
"triggerJob":"test http trigger event",
"triggerJobTime":"000000000000"
}'
得到任务C状态后,返回给任务Temp1调用成功/调用失败信息
当Event1时间任务获取Temp1成功信息且达到计划运行时间,则Event1任务状态将会变为运行成功
当Event1运行成功后,下游任务D开始运行
临时运行进行调试时,外部任务计划时间应该填写为:000000000000
对事件任务进行补数据、重跑等操作时,以事件任务为分界点,需要在两个调度系统里分别操作
重跑:事件任务开始重跑,等待被触发;外部调度系统任务进行重跑
补数据:对事件任务进行补数据时,事件任务将直接置成功
事件任务在IDE中配置完成后,可以点击「运行」按钮,事件任务将监听来自外部任务的触发,可以测试是否和外部系统打通。
运行结果有4种情况:
1)外部任务调离线任务接口触发成功,外部主任务状态为成功,日志打印如A
2)外部任务调离线任务接口触发成功,外部主任务状态为失败,日志打印如B
3)外部任务超时未触发或对本任务接口调用失败,日志打印如C
4)本事件任务停止,日志打印如D

条件任务
概述
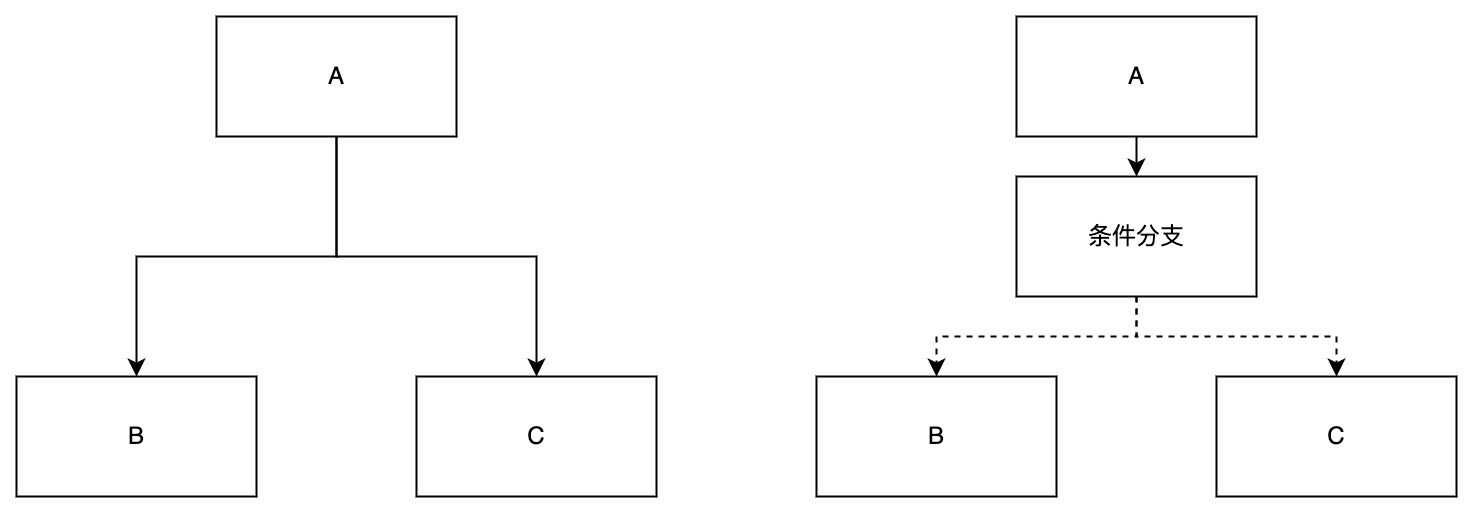
在日常开发过程中,存在需要根据上游任务的计算结果来选择下游任务的执行路径的场景,如下图所示:任务A是任务B、任务C的上游,现在想要根据任务A的运行结果来决定下游任务是执行任务B和任务C。此时可以引入条件分支任务,条件分支任务可以根据执行任务A的输出参数结果进行判断,来选择执行下游任务。
创建
在「项目管理->项目设置->开发设置」中勾选「条件分支」任务,即可在「数据开发」中新建「条件分支」任务,如下图
使用
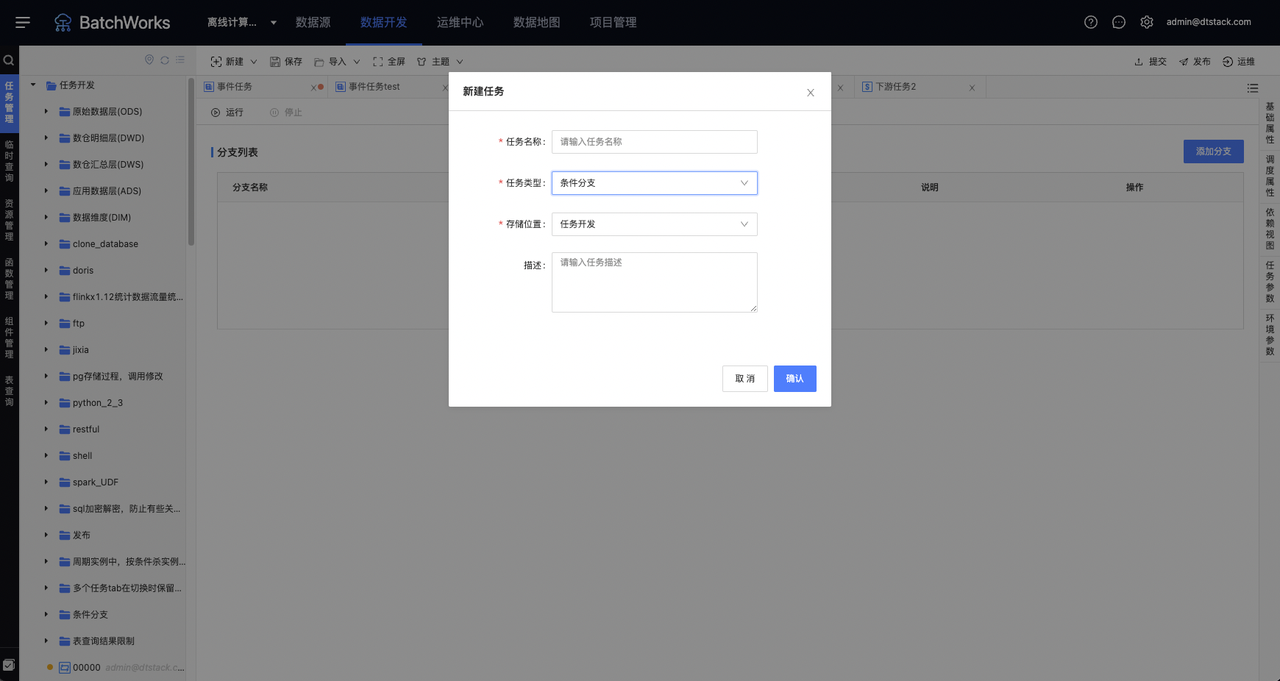
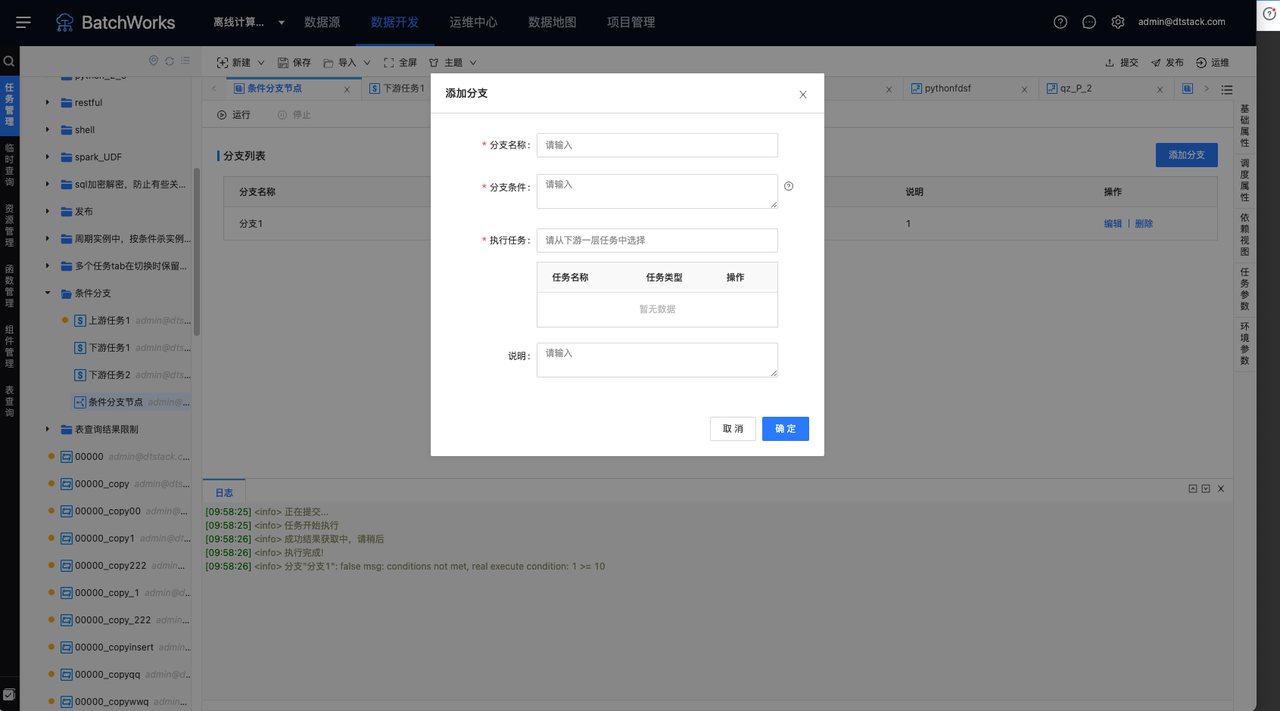
新建分支任务成功后。需要给分支任务配置上下游依赖,并完善分支任务所需的输入参数和运行参数。点击「添加分支」按钮,打开如图所示弹窗。
分支条件:分支条件参数来源于当前任务的运行参数和直接上游依赖任务的输出参数,按SpringEL语法(参考文档:http://itmyhome.com/spring/expressions.html)填写,例如“ #a >= 6 and #b>= 20 ”,调用运行参数和输入参数可直接使用 #参数名称。
执行任务:从分支任务的下游一层任务中选择,当满足分支条件时,将会运行选中的任务。
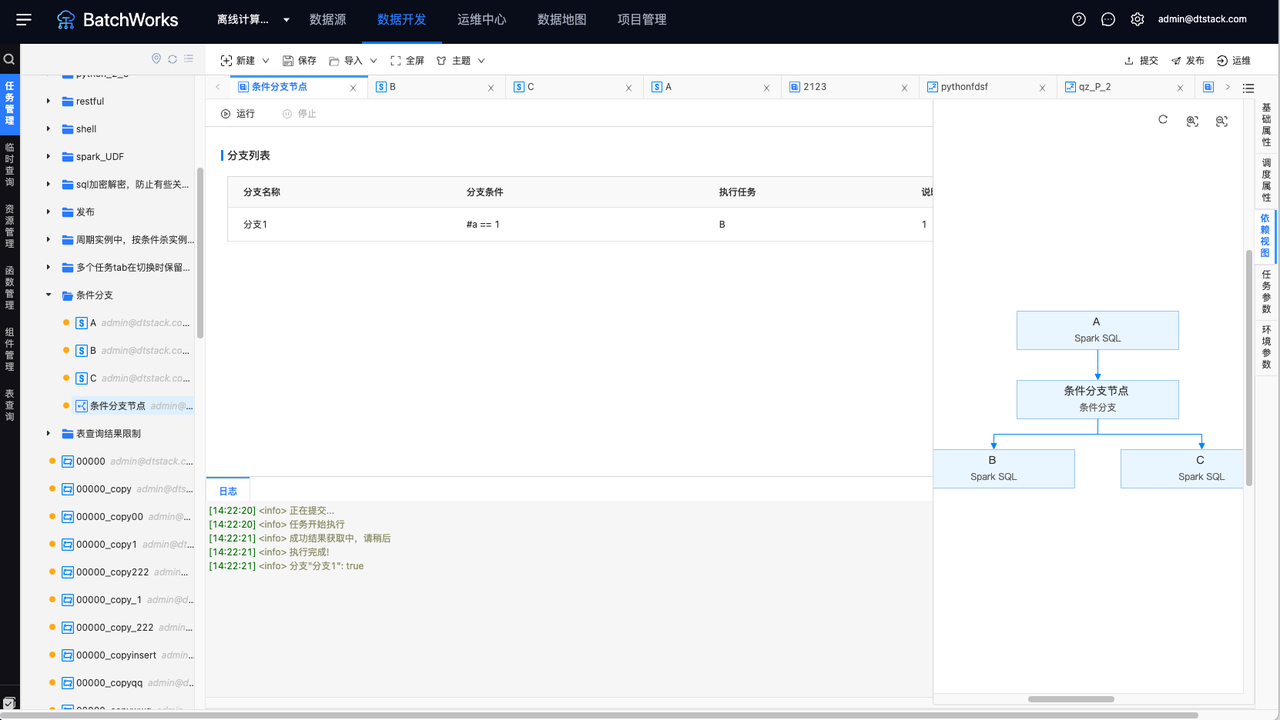
以下图为例子,新建任务A、B、C,A是B、C的上游,但现在需要通过条件分支节点来判断下游任务运行B还是C,因此在A与B、C间引入了条件分支节点。如图所示,A作为条件分支的上游,B、C作为条件分支的下游。
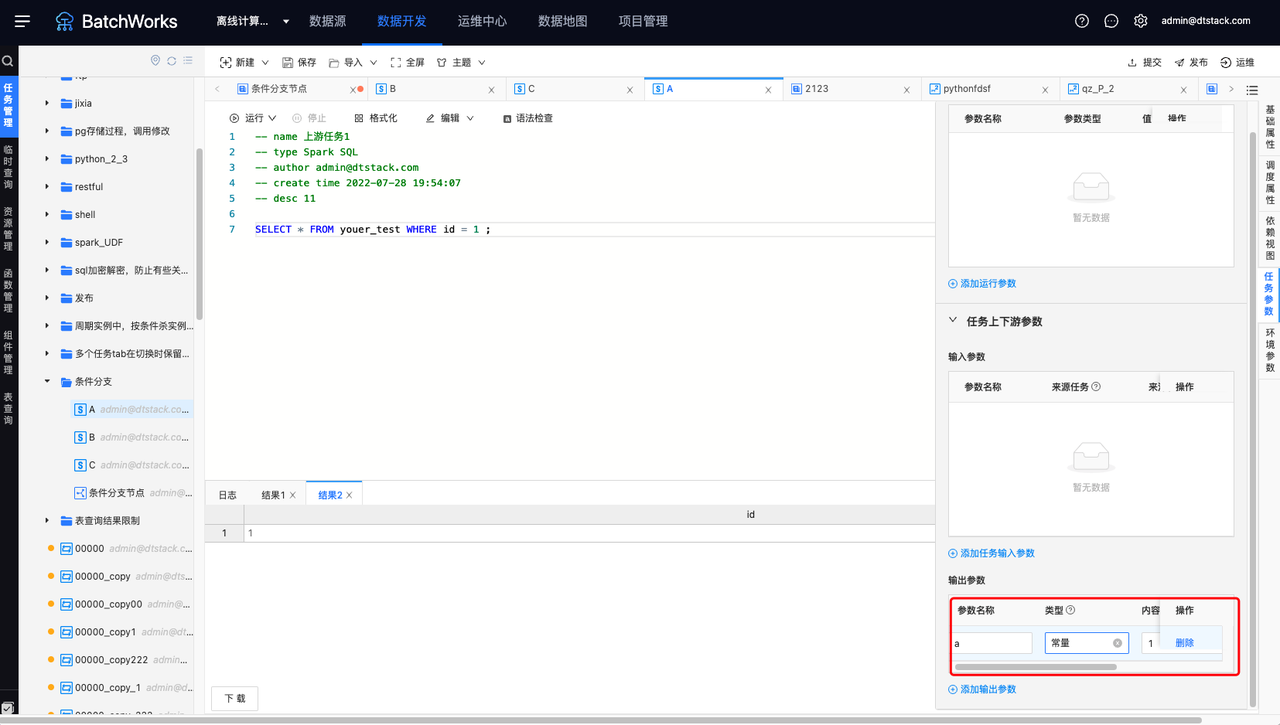
在A中存在输出参数a,在条件分支中作为输入参数引入。
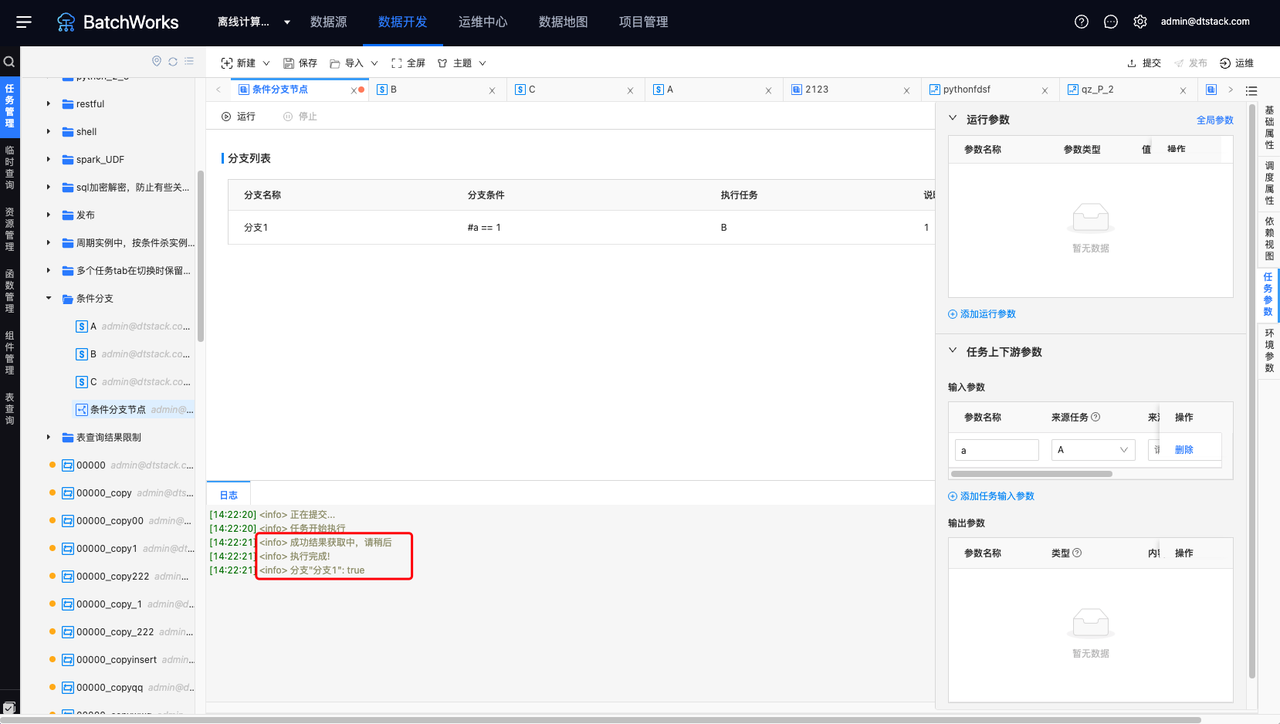
在条件分支中添加分支,并将#a == 1 作为判断条件,若满足条件,则执行任务B。临时运行条件分支后如图所示,在日志中会打印判断结果。若任务提交在调度系统上,就会以根据条件分支的判断情况实际运行下游任务。未被命中的任务状态将变更为自动取消。
举例:根据温度判断天气等级,执行不同的应急预案。其中:24小时最高温度为35(包含)-37摄氏度为“高温黄色预警”、37(包含)-39摄氏度为“高温橙色预警”、39摄氏度及其以上称“高温红色预警”。
分支节点的上游:随机生成温度
1、创建一个 Python 作业,随机生成一个温度。
-*- coding: UTF-8 -*-
import random
import string
# 随机生成温度:
a = random.randint(35,42)
print a
2、将温度通过赋值参数 outputs,传递给下游的分支节点,作为分支节点的判断依据。
3、根据温度等级的定义,配置三个分支。
建立 Python 作业「高温黄色预警」,依赖上游分支节点的黄色预警分支。
# -*- coding: UTF-8 -*-
print "高温黄色预警!各单位注意,执行高温黄色预警预案。"建立 Python 作业「高温橙色预警」,依赖上游分支节点的橙色预警分支。
# -*- coding: UTF-8 -*-
print "高温橙色预警!!各单位注意,执行高温橙色预警预案。"
建立 Python 作业「高温红色预警」,依赖上游分支节点的红色预警分支。
# -*- coding: UTF-8 -*-
print "高温红色预警!!!各单位注意,执行高温红色预警预案。"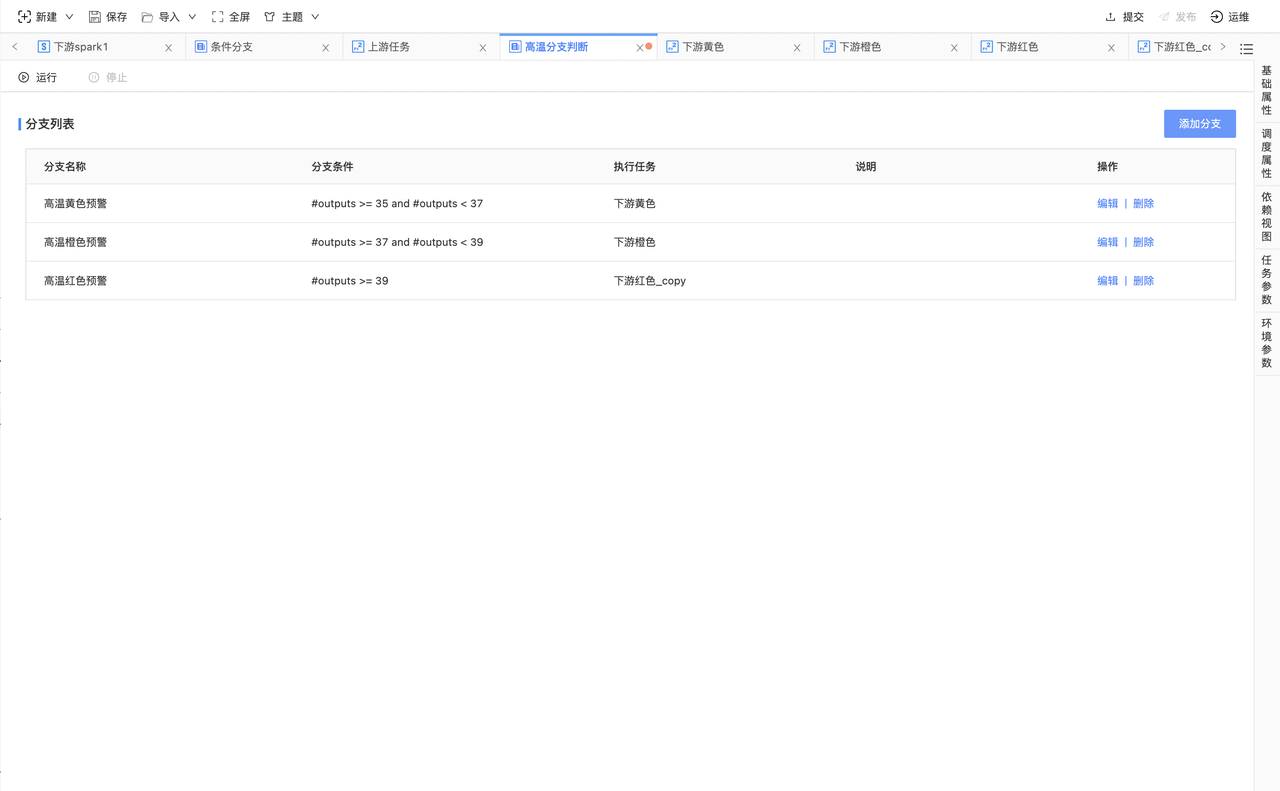
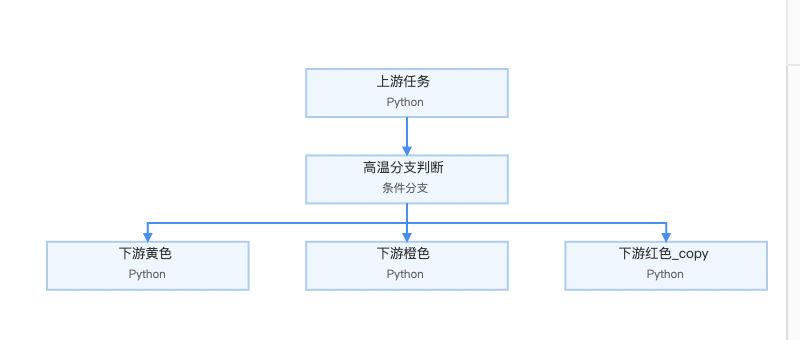
临时运行的日志分为成功日志和失败日志,成功日志将会打印分支条件是否成功,根据命中情况分为0、1、2等,如下图所示“分支‘分支1’:true”;失败日志将打印Spring执行错误日志。
分支条件表达式错误:打印失败日志
上游输出参数未找到:输出参数均为空,分支无命中,全部为false,将会打印
“
分支‘分支1’:false msg:错误原因
”
无命中分支:输出参数有值,分支无命中,全部为false,将会打印
“
分支‘分支1’:false msg:错误原因
”
命中一个分支、多个分支、所有分支:被命中的分支标记为true,未命中的分支标记false,将会打印
“
分支‘分支1’:true
分支‘分支2’:false msg:错误原因
”
文件拷贝任务
文件拷贝是通过shell脚本将文件在hive和ftp间进行快速迁移的任务,相比于数据同步任务优势在于:无需进行数据处理,更加方便快捷。但文件拷贝对于计算节点有着较高的配置门槛和要求。
计算节点要求
Hive -> FTP
- 存在以下路径,或者运行用户有权限新建文件夹,文件夹路径:/data/gtpBak/Upload
- 计算节点可以执行hdfs命令,举例: hdfs dfs -getmerge
- 计算节点和ftp服务器网络相通,可以直接直接使用scp命令将文件拷贝到ftp服务器上
- 计算节点存在expect软件,可以执行spawn、expect命令
- 表文件数据不能被压缩,不然hdfs dfs -getmerge 下载出来的文件会出问题
- 目标ftp服务器需要放开ssh、scp命令
- ftp数据源认证方式必须是密码方式,不能支持密钥方式
hive - ftp 的本质是使用hdfs dfs -getmerge,将hive表的数据文件下载到本地
FTP -> Hive
计算节点要求:
- 存在以下路径,或者运行用户有权限新建文件夹,文件夹路径:/data/gtpBak/Download
- hdfs存在以下文件夹或者可以创建以下文件夹,文件夹路径: hdfs://ns1/dtInsight/data/gtpBak/Download
- 可以执行unzip命令
- 可以执行beeline命令
- 计算节点存在expect软件,可以执行spawn、expect命令
- 计算节点和ftp服务器网络相通
- ftp数据源认证方式必须是密码方式,不能支持密钥方式
ftp - hive 的本质是使用hive自带的load命令将文件加载到表中,需要保证数据文件没有问题
两种拷贝方式所选择的hive数据源必须是集群配置的hadoop集群,并且文件拷贝的表尽量都选择textfile格式,其他格式可能会出现脚本不兼容问题。
使用
新建
「项目管理->开发设置->Hadoop」勾选FlieCopy任务后,在「数据开发」中可以新建FileCopy任务,如下图:
配置
数据源:
支持选择hive2.x版本数据源和FTP数据源。文件拷贝数据源和数据同步数据源一致,需要先在数据源中心配置后再引入至离线项目授权使用。
写入目标:
数据同步目标当数据源选择为hive2.x 时,此处仅可选择ftp数据源;当数据源选择为ftp时,此处仅可选择hive2.x 数据源。
临时文件扩展名:
支持指定文件下载或上传过程中的文件临时扩展名
映射关系:
将ftp和hive数据源中的路径做匹配,将数据源路径下的文件内容拷贝到目标路径下。支持配置200组映射关系,支持「覆盖」和「追加」两种写入模式。
hive映射关系填写
分区填写时会判断用户选中的表是否有分区,若存在分区,则自动读取分区字段,并按照“year=/month=/day=”的形式拼接;若任务运行时,分区不存在,则会自动创建分区;
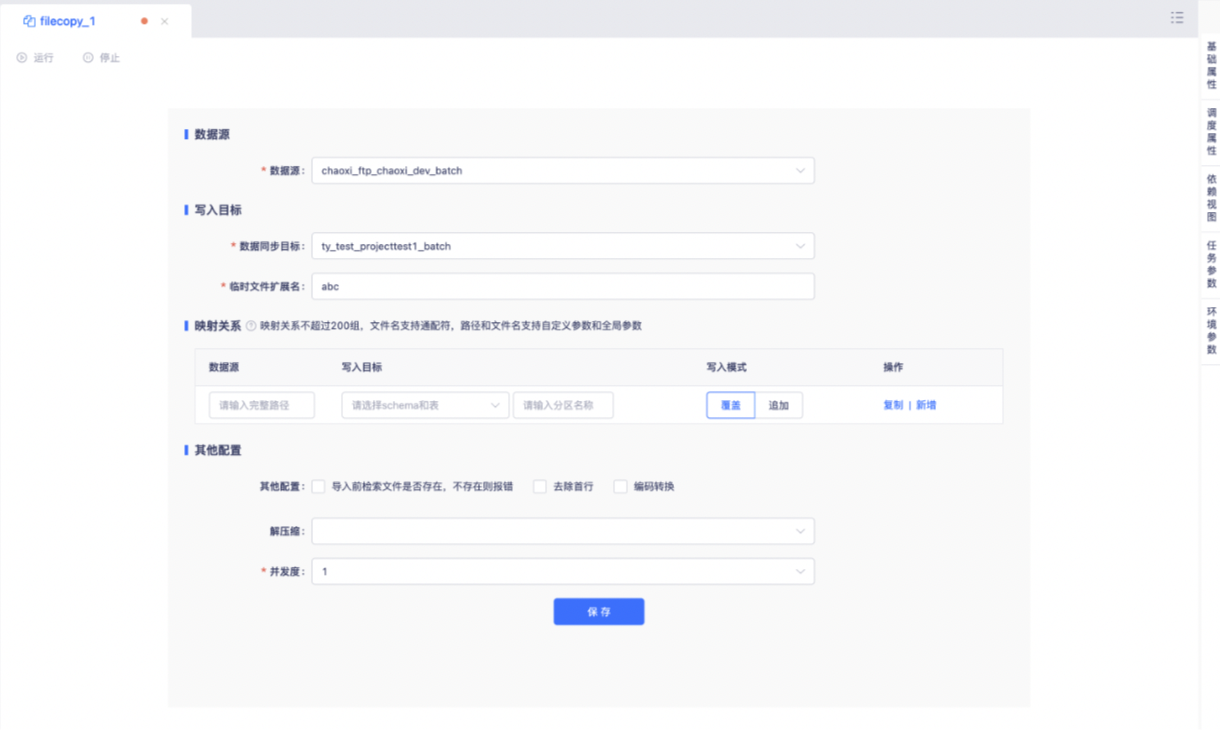
ftp映射关系填写
需要填写完整路径,文件名支持和 ?通配符(号代表多字符,?代表单字符),文件名和路径支持自定义参数、全局参数;
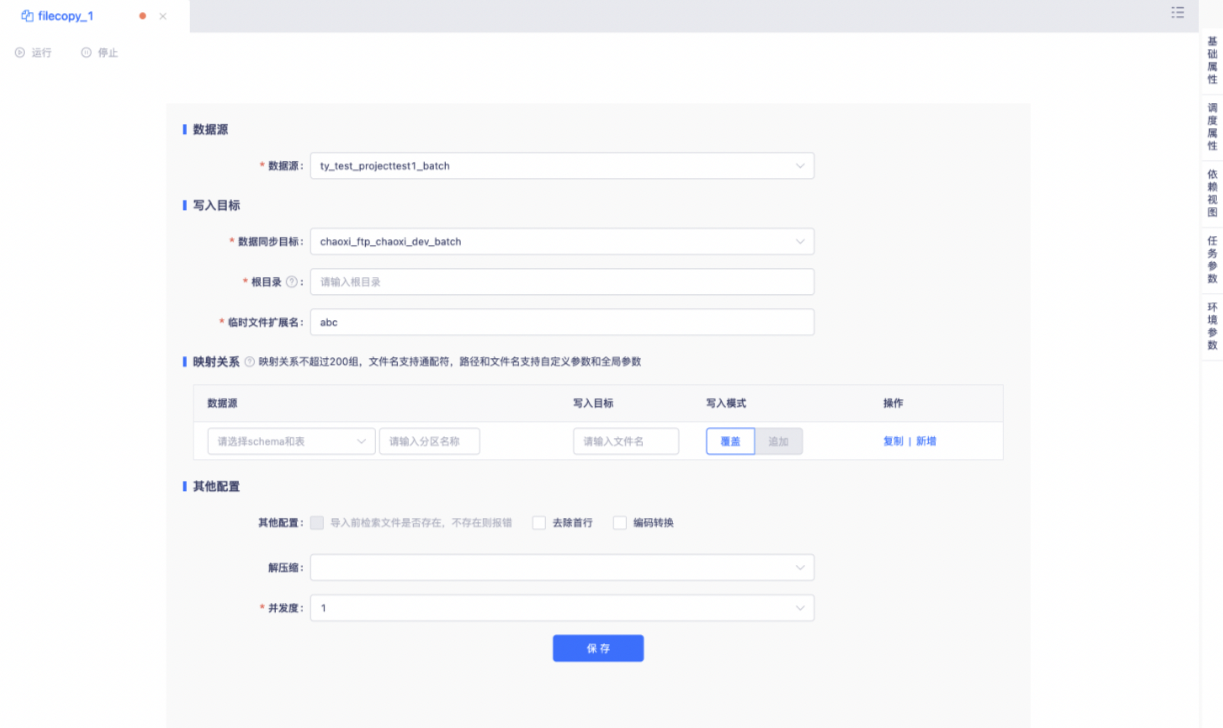
写入模式
从hive - > ftp时,目前仅支持覆盖;ftp - > hive时,目前支持覆盖和追加。
其他配置
导入前检索文件是否存在,不存在报错:当ftp作为数据源时支持选中,用于判断ftp目录是否为空。
去除首行:选中后,写入目标中时,去除首行标题
编码转换:支持对数据内容进行编码转换,支持GBK和UTF-8编码间相互转换
是否为压缩文件:目前支持解压缩zip文件
并发**度:**可以设置1~5并发度设置