脏数据记录
脏数据记录
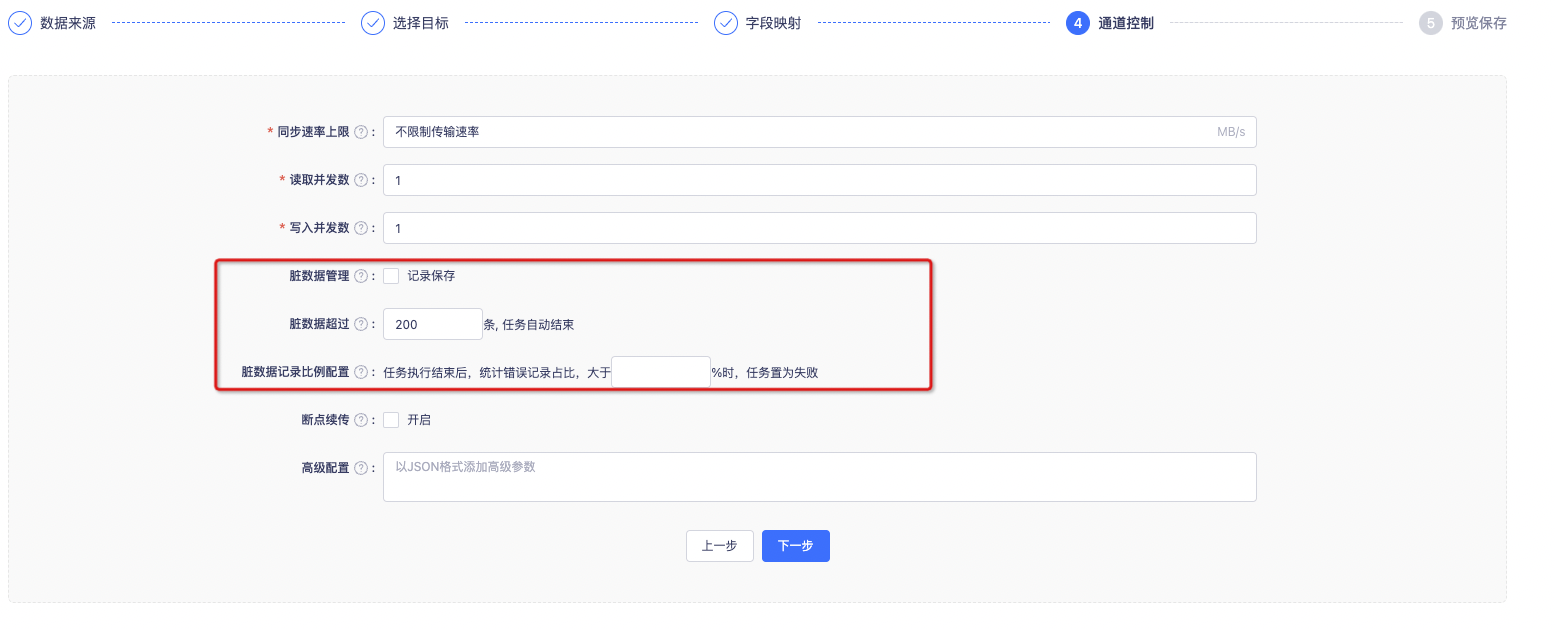
脏数据管理
在数据同步任务中,可开启错误记录管理,开启后,任务会将数据同步过程中的错误数据写入指定的Hive表(可指定表名、生命周期)。在数据同步任务的周期执行过程中,每个实例都会将脏数据写入一个分区,每个实例一个分区。脏数据表采用二级分区形式,第一级为任务名称、第二级为同步时间(Unix时间戳格式),用户可在「运维中心-脏数据管理」模块查看表内的数据和原因。
目前临时运行、周期调度、补数据操作中都会将脏数据写入Hive表。 用户在页面点击运行时,可能会发现脏数据不为0的情况,需通过执行补数据才能查看脏数据的值与报错原因。
脏数据表根据不同的作业类型会存在不同的命名规则,便于客户区分:
脏数据表的命名规则:dirty_任务iD
脏数据临时运行分区的命名规则:task_name=任务ID_test_instance/time=时间戳 脏数据周期实例分区的命名规则:task_name=任务ID_scheduled_instance/time=时间戳 脏数据手动实例分区的命名规则:task_name=任务ID_manual_instance/time=时间戳 脏数据补数据实例分区的命名规则:task_name=任务ID_temporary_instance/time=时间戳
脏数据数量控制
支持对于脏数据的自定义监控和告警,包括对脏数据最大记录数阈值,当传输过程出现的脏数据大于指定的数量,则报错退出。如果不填,脏数据将打印在日志中,限制条数为0;如果填写0,脏数据会记录在脏数据表(需要配置脏数据表),限制条数为0;如果填写-1,脏数据记录在脏数据表(需要配置脏数据表),不限制条数
支持对于脏数据记录比例的配置,当任务执行结束后系统才会统计脏数据占总的同步数据的占比,超过阈值将任务置为失败。
错误记录占比是数据同步实际执行结束后统计的,并不会在任务同步过程中统计。