周期任务管理
当任务被提交至调度系统后,可以在「运维中心->周期任务->周期任务管理」模块查看已提交的任务列表,包含任务的基本信息。常见的操作包括补数据、查看依赖视图、运行报告等
- 任务管理中仅列出任务,不包含实例信息
- 任务一旦被提交,将会立即显示在任务管理列表中,目前尚不支持任务下线功能
任务列表
点击「运维中心→离线开发→任务管理」菜单,进入任务列表,包括任务名称、提交时间、任务类型、责任人等信息
基本功能
列表支持如下基本操作:
- 任务名称搜索:默认为模糊搜索,点击搜索栏右侧的icon,可在「精确匹配」/「头部匹配」/「尾部匹配」3种模式中切换
- 基本过滤:包含任务责任人、是否是我的任务(即责任人为本人的任务)、今日修改、已冻结等条件
- 表头过滤:支持按照任务类型、调度周期进行过滤
冻结与解冻
已冻结的任务,将会在任务名称后标注「已冻结」,可对单个任务执行「冻结/解冻」操作,或在列表多选任务批量进行「冻结/解冻」
冻结与解冻操作是立即生效的,尚未提交至引擎的实例,将会被立即冻结/解冻。关于实例冻结的处理,请参考实例的生命周期一节的描述
工作流的冻结操作比较特殊,请参考下节内容
工作流
工作流是一种较为特殊的任务类型,在任务列表中,工作流会以多行的形式列出,工作流名称是一行,其内部每个节点是单独的一行,不区分节点间的上下游关系。
- 对列表进行搜索或过滤时,若未指定任务类型,若搜索结果中包含工作流内部节点,则搜索结果中会将工作流自动展开,列出命中搜索结果的内部节点。点击「收缩」icon时,会将工作流内部节点收缩起来,再次点击时,会将内部所有节点全部展示出来,而非刚才的搜索结果
- 对列表进行搜索或过滤时,若指定了任务类型,则搜索结果中将按照指定的任务类型展现,每次执行「收缩/展开」操作时,将会显示稳定的搜索结果,不会将工作流所有节点全部展示出来
- 若单独指定任务类型为「工作流」,则搜索结果仅会展现出工作流名称,点击展开时,不会显示内部的节点列表
工作流的冻结:
- 若只对工作流根节点执行冻结,子节点也会被冻结
补数据
周期任务开发完成并提交发布后,任务会按照调度配置定时运行。当业务变更、数据计算口径变更需要对历史数据进行重刷时,可以使用补数据功能。典型场景举例如下:
- 修改了某个任务的代码,需要将本月的数据按照新的代码重新跑一遍
- 新开发了一个任务,需要尽快输出今年的统计数据
补数据功能用于在指定日期范围内运行周期任务,支持补当前节点及其下游节点,可以在补数据实例页面查看实例的运行状态,以及对补数据实例进行终止、重跑和解冻等操作。离线开发中支持按单任务补数据、多任务补数据(按条件批量筛选任务:任务名称、类型、所属项目、责任人等方式)、批量选择补数据。
基本原理
补数据的基本原理是「系统参数替换」,但在进行参数替换之前,还需在表结构设计和代码设计上进行配合,下面举例说明:
- 有如下3张表,均包含
id、name2个字段,均为分区表(分区字段为ds)。3张表的血缘关系为t2+t3→t1
-- t1、t2、t3建表语句雷同
create table if not exists t1 (
id string
,name string
)
PARTITIONED BY (ds string);
SQLCopied!
- 这3张表对应的加工任务如下:
-- 注意在分区指定时,需要使用系统参数,而不是写死一个分区名称
INSERT OVERWRITE TABLE t1 PARTITION(ds = '${bdp.system.bizdate}')
select
t2.id
, t2.name
from t2 join t3 on t2.id = t3.id
where t2.ds = '${bdp.system.bizdate}'
and t3.ds= '${bdp.system.bizdate}';
SQLCopied!
假设业务日期为 2020-03-05 ,则系统自动完成参数替换,将执行如下代码:
INSERT OVERWRITE TABLE t1 PARTITION(ds = '20200305')
select
t2.id
, t2.name
from t2 join t3 on t2.id = t3.id
where t2.ds = '20200305'
and t3.ds= '20200305';
SQLCopied!
在上述加工代码中,有如下几点注意事项:
- 结果表需按分区写入,写入模式必须为覆盖,不能为追加(
INSERT OVERWRITE TABLE t1),以这种方式来保证代码可以反复多次执行,每次执行的输出结果是相同的 - 源表、目标表按分区读写
- 分区名填写系统变量,而不是写死分区名(
${bdp.system.bizdate}),这样仅需一次编码,每天运行时,自动完成参数替换,无需人工干预
在执行补数据时,用户需指定目标任务、业务日期起止范围,系统根据业务日期范围自动完成参数替换,实现历史数据的重刷,例如:对上述任务执行补数据,业务日期选择20200305~20200307,则自动生成3个实例,分别重刷了20200305、20200306和20200307分区的数据,实现了历史数据的重刷。
三种补数据方式
一、单任务补数据
用户对选中的当前任务执行补数据操作,如下图所示。
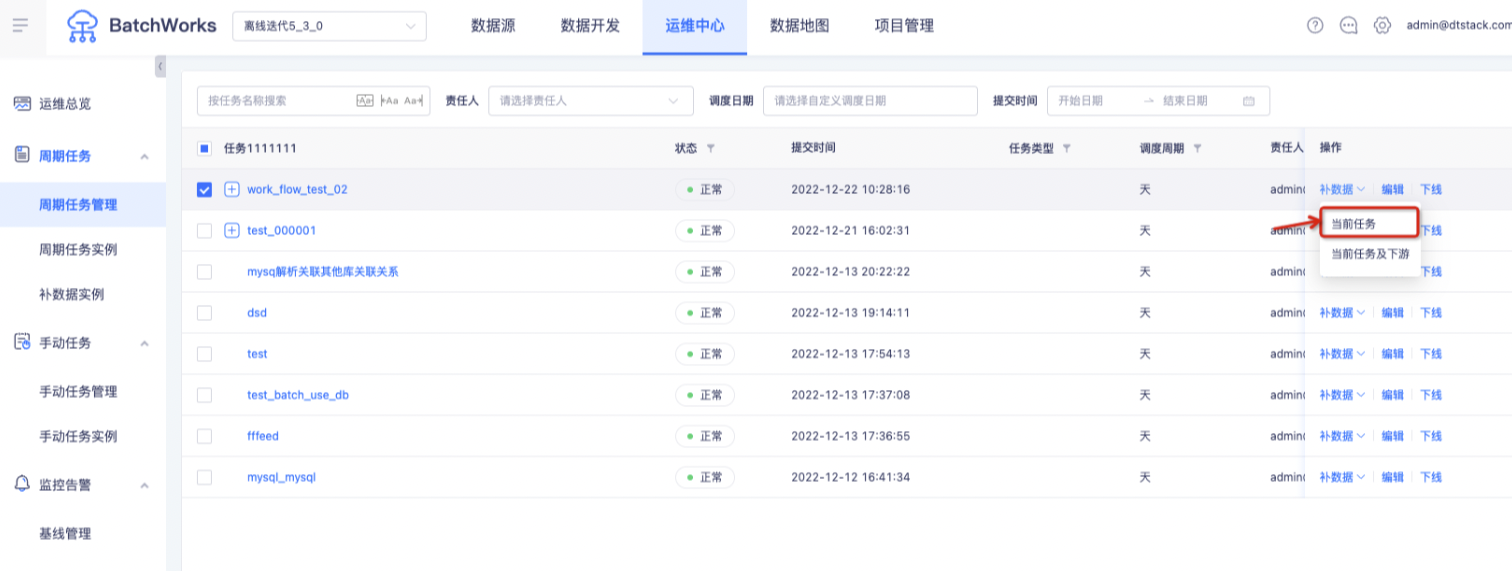
「周期任务管理->操作->补数据->当前任务」打开单任务补数据弹窗,如下图所示
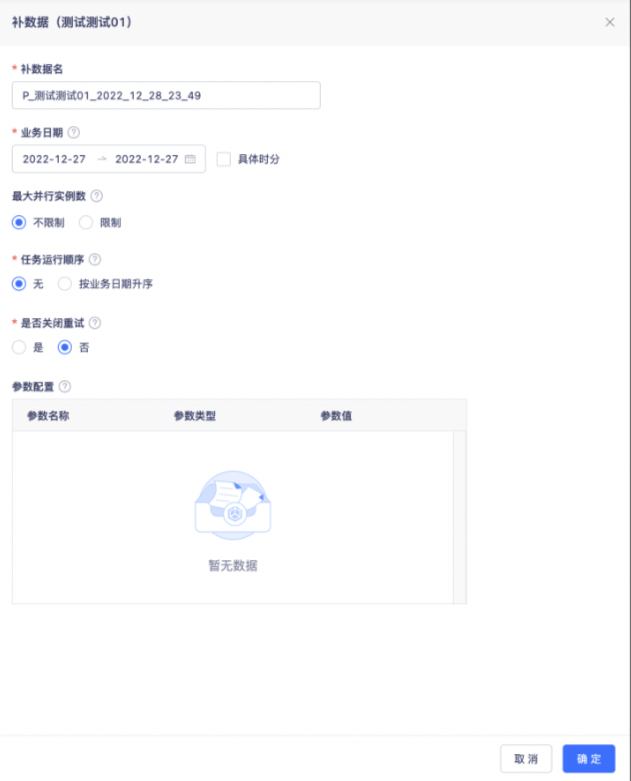
补数据名:**默认生成名称:P任务名称创建时间,支持用户自定义**
业务日期:支持历史和未来的任一时间区间
若勾选「业务日期」后的’具体时分‘复选框,在后方展示「具体时间」字段。
具体时间:产生指定的业务日期内,指定的时间范围内计划开始运行的实例。
例如: 业务日期:2019-01-01~2019-01-03 具体时间:01:30~03:00 表示:2019-01-01~2019-01-03期间内,每天的01:30~03:00开始运行的实例,时间范围为闭区间,时间范围选择了23:59后,计划23:59开始运行的实例也会产生。
最大并行实例数:可选择无限制和自定义并行实例数。无限制是在资源允许的情况下全部提交到yarn上运行。若选择限制,则最大并行数上限为100。
任务执行顺序:
选择“无”时,在任务没有配置跨周期自依赖的情况下,所有实例并发运行。
选择“按业务日期升序”时,在任务没有配置跨周期自依赖的情况下,对于当前任务会按业务日期(包括时分)升序运行,例如9.1的实例运行结束(成功或失败均可),9.2实例才会开始运行。
选择按业务日期升序/降序运行时,同一任务的上个实例运行结束后下个实例才会运行
是否关闭重试:
选择“是”时,任务本身所配置的失败重试策略失效,实例一旦失败不再重试。
选择“否”时,任务本身所配置的失败重试策略仍有效。
参数配置:
补数据时支持对任务中的所有运行参数类型进行重新赋值。
二、批量任务补数据
支持在「周期任务管理」列表按责任人、提交时间、任务类型对任务管理列表中的任务进行筛选后批量选中任务进行补数据,可以避免无依赖关系任务补数据的重复操作。「补数据」按钮在下图所示位置
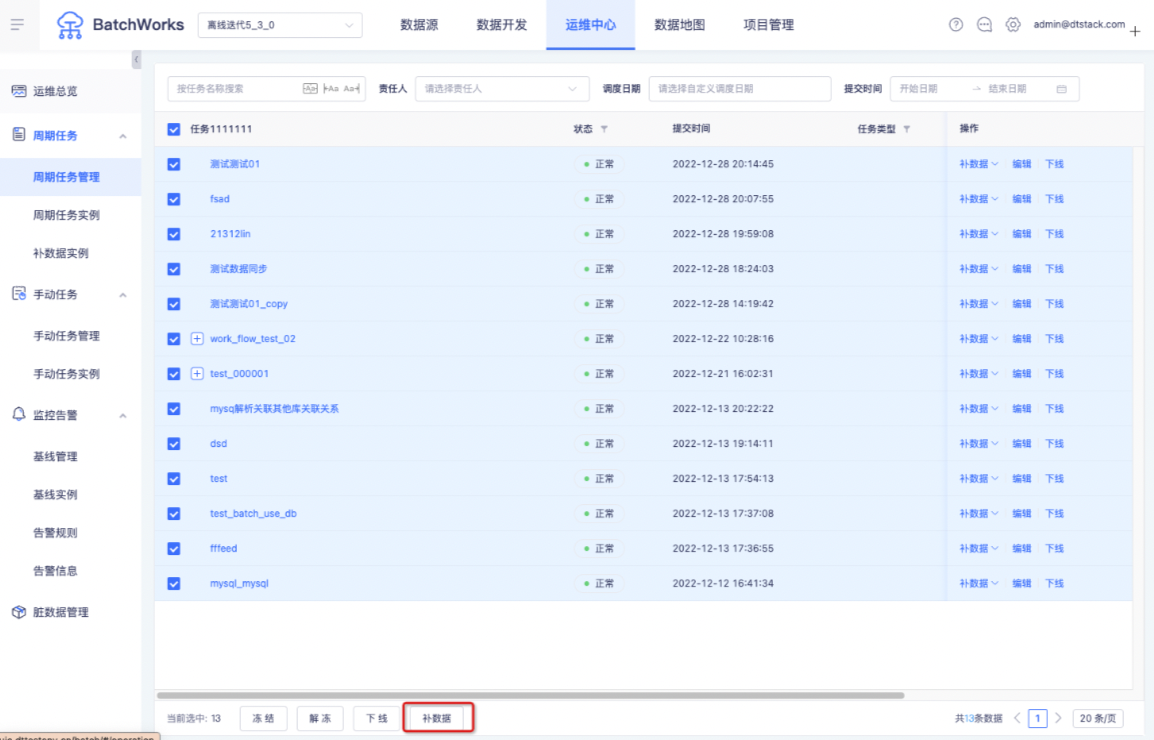
「周期任务管理->补数据」打开批量任务补数据弹窗,如下图所示
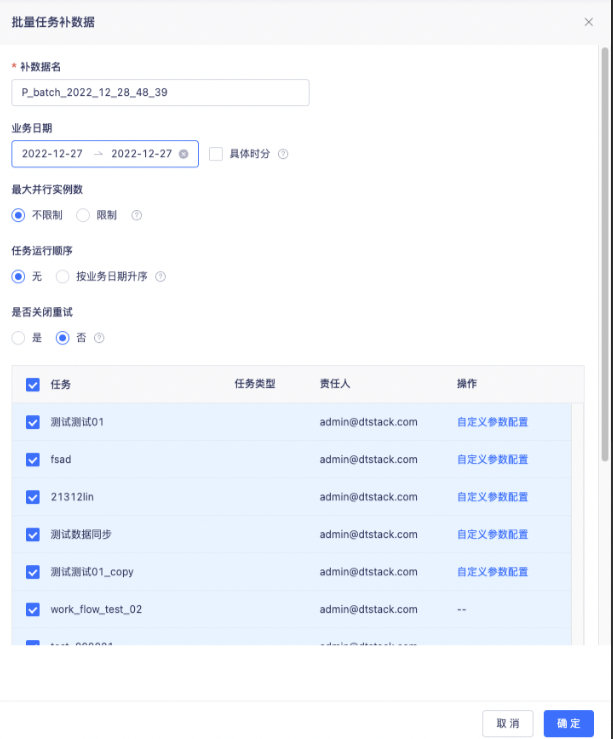
补数据名:**默认生成名称:P当前操作用户名创建时间,支持用户自定义**
业务日期:支持历史和未来的任一时间区间
若勾选「业务日期」后的’具体时分‘复选框,在后方展示「具体时间」字段。
具体时间:产生指定的业务日期内,指定的时间范围内计划开始运行的实例。
例如: 业务日期:2019-01-01~2019-01-03 具体时间:01:30~03:00 表示:2019-01-01~2019-01-03期间内,每天的01:30~03:00开始运行的实例,时间范围为闭区间,时间范围选择了23:59后,计划23:59开始运行的实例也会产生。
最大并行实例数:可选择无限制和自定义并行实例数。无限制是在资源允许的情况下全部提交到yarn上运行。若选择限制,则最大并行数上限为100。
任务执行顺序:
选择“无”时,在任务没有配置跨周期自依赖的情况下,所有实例并发运行。
选择“按业务日期升序”时,在任务没有配置跨周期自依赖的情况下,对于当前任务会按业务日期(包括时分)升序运行,例如9.1的实例运行结束(成功或失败均可),9.2实例才会开始运行。
选择按业务日期升序运行时,同一任务的上个实例运行结束后下个实例才会运行
是否关闭重试:
选择“是”时,任务本身所配置的失败重试策略失效,实例一旦失败不再重试。
选择“否”时,任务本身所配置的失败重试策略仍有效。
选中的任务列表:
可以在此处进行复核需要进行补数据的任务,不需要的任务取消勾选,点击确认后将不执行补数据。
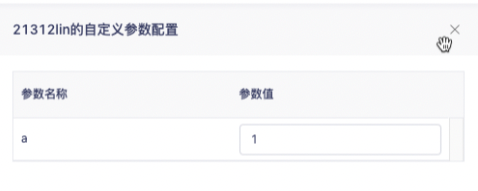
支持对存在「运行参数」的任务类型任务(Spark SQL、Hive SQL等任务类型支持配置「运行参数」,工作流父节点、虚节点等任务类型不支持配置「运行参数」)进行「参数赋值」操作,如下图。参数重新赋值后,补数据将以新的参数值替代原任务中配置的运行参数参数值。
选择工作流进行批量补数据的特殊操作说明:
当同时选中工作流父节点和非全部子节点时,弹窗中实际选中的是整个工作流;
当只选中工作流里面的部分子节点时,弹窗中实际选中的仅是它部分子节点;
三、当前任务上下游补数据
按任务上下游关系补数据,即目前已实现的补数据方式。一般上游任务补数据后下游任务也需要重新运行,因此按上下游关系补数据是比较常用的补数据方式。
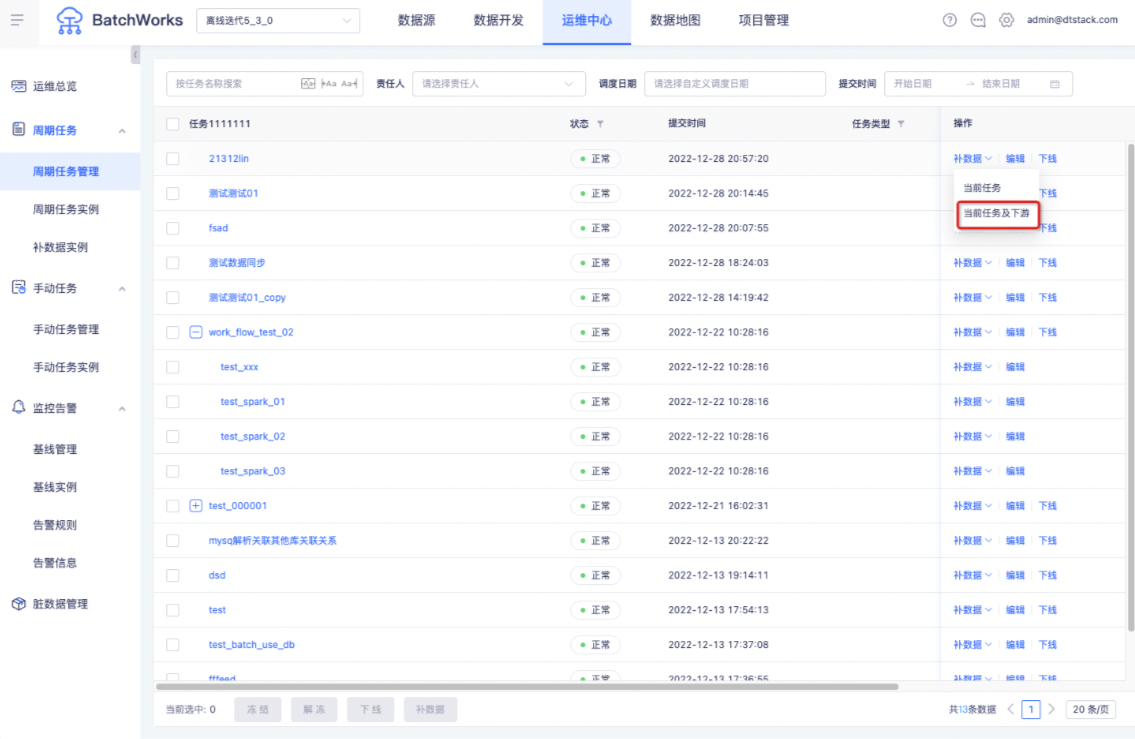
「周期任务管理->操作->补数据->当前任务及下游」打开任务上下游补数据弹窗,如下图所示
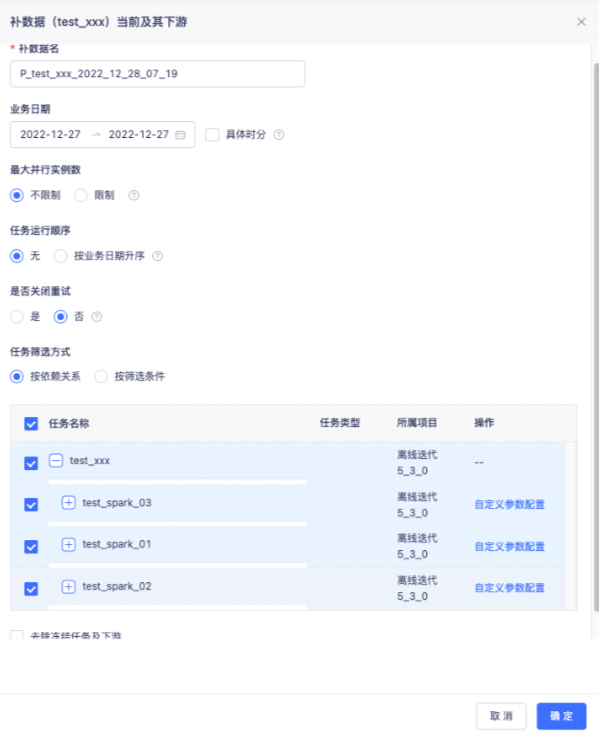
补数据名:**默认生成名称:P任务名称创建时间,支持用户自定义**
业务日期:支持历史和未来的任一时间区间
若勾选「业务日期」后的’具体时分‘复选框,在后方展示「具体时间」字段。
具体时间:产生指定的业务日期内,指定的时间范围内计划开始运行的实例。
例如: 业务日期:2019-01-01~2019-01-03 具体时间:01:30~03:00 表示:2019-01-01~2019-01-03期间内,每天的01:30~03:00开始运行的实例,时间范围为闭区间,时间范围选择了23:59后,计划23:59开始运行的实例也会产生。
最大并行实例数:可选择无限制和自定义并行实例数。无限制是在资源允许的情况下全部提交到yarn上运行。若选择限制,则最大并行数上限为100。
任务执行顺序:
选择“无”时,在任务没有配置跨周期自依赖的情况下,所有实例并发运行。
选择“按业务日期升序”时,在任务没有配置跨周期自依赖的情况下,对于当前任务会按业务日期(包括时分)升序运行,例如9.1的实例运行结束(成功或失败均可),9.2实例才会开始运行。
选择“按业务日期降序”时,在任务没有配置跨周期自依赖的情况下,对于当前任务会按业务日期(包括时分)降序运行,例如9.2的实例运行结束(成功或失败均可),9.1实例才会开始运行。
选择按业务日期升序/降序运行时,同一任务的上个实例运行结束后下个实例才会运行
是否关闭重试:
选择“是”时,任务本身所配置的失败重试策略失效,实例一旦失败不再重试。
选择“否”时,任务本身所配置的失败重试策略仍有效。
去除冻结任务及下游:勾选后冻结的任务及其所有的下游任务不纳入补数据范围内,默认不勾选;
任务筛选方式:
- 按依赖关系
展示当前任务及其下游,支持对存在「运行参数」的任务类型任务(Spark SQL、Hive SQL等任务类型支持配置「运行参数」,工作流父节点、虚节点等任务类型不支持配置「运行参数」)进行「参数赋值」操作,如下图。参数重新赋值后,补数据将以新的参数值替代原任务中配置的运行参数参数值。
- 筛选条件批量补数据[专业版、旗舰版]
此方式本质也是按任务上下游关系补数据,与按任务依赖关系筛选方式的区别在于不会轮循当前任务的所有下游任务,因此在下游任务数量很大的情况下能避免操作的卡顿。如下图所示
按条件筛选后,实际选中的任务范围计算公式如下
(当前任务下游 and 选中项目 and 选中任务类型)的任务 + 白名单的任务 - 黑名单的任务
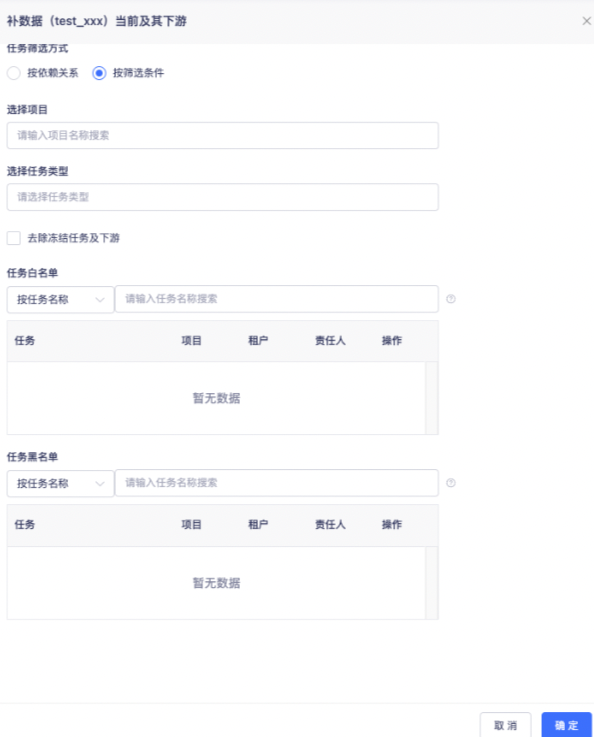
选择项目:可选离线产品中用户为数据开发及以上角色的所有租户的所有项目,选中项目代表选中项目下所有的任务。
任务类型:可选范围为所有任务类型
任务白名单:白名单内的任务为选中项目之外另外需要补数据的任务,可选范围为离线产品当前用户为数据开发及以上角色的所有租户的所有项目的已提交的任务。
任务黑名单:黑名单内的任务为选中项目之内不需要补数据的任务,可选范围为离线产品当前用户为数据开发及以上角色的所有租户的所有项目的已提交的任务。
若选中的多个任务在同一棵依赖树上,则按原依赖关系的顺序运行。
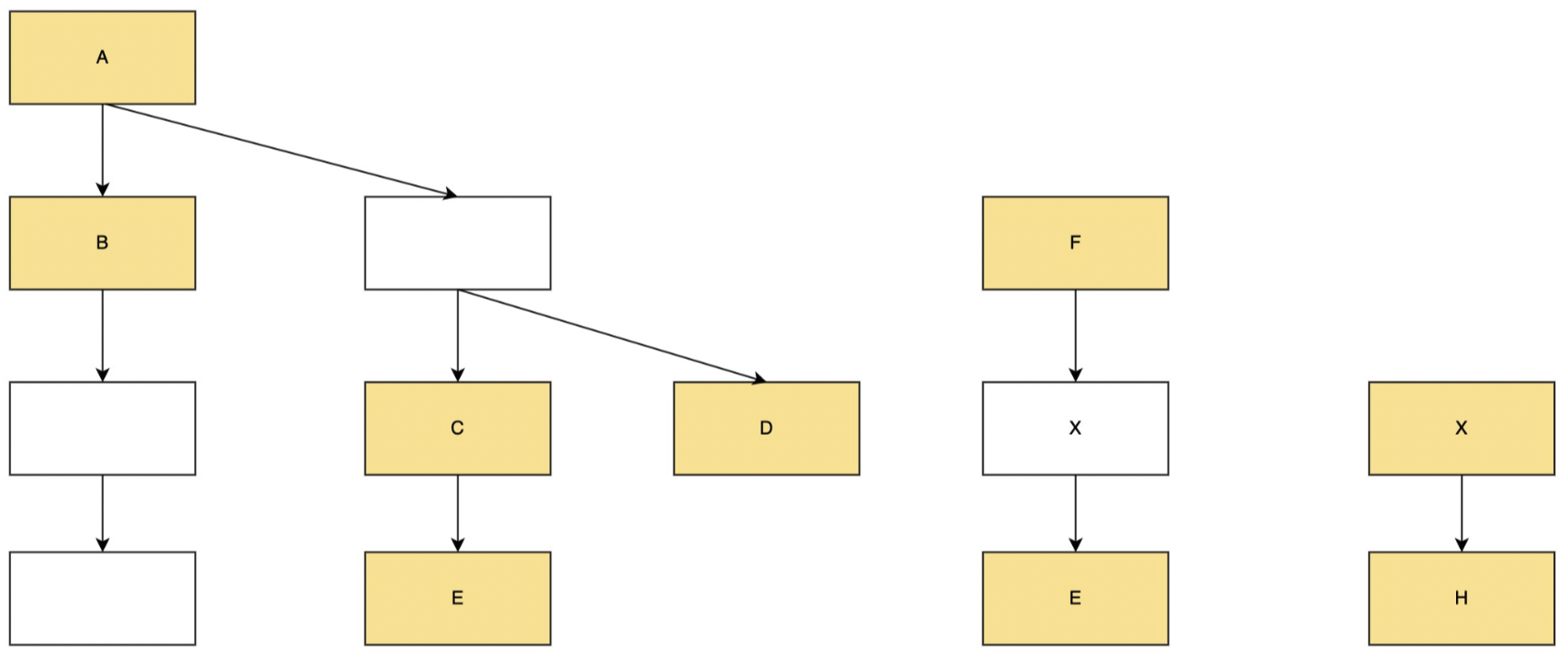
例如上图所示,不管选中的任务之间是否存在直接依赖关系,都会按依赖树的先后顺序执行。
假设某次补数据选中的任务是A~H,这些任务分属于3棵依赖树,则在补数据实例运行时,属于一棵依赖树中的任务,即使实际选中的任务依赖存在断层(例如ACDE、FG),仍需要按原依赖顺序执行,规则如下:
1)生成的补数据实例列表中的实例为选中任务对应的实例(例:选择F和G生成补数据实例,则补数据实例包中仅有FG,没有X)
2)实例依赖视图为原依赖树的完整视图,包括未选中的任务(例:依赖树2中G的依赖视图展开是FXG)
3)按原依赖树的完整视图的顺序运行实例,运行到被选中补数据的实例时正常运行(例:依赖树2中的FG正常运行),运行到未被选中补数据的实例会被直接置成功
工作流补数据
对工作流补数据可分为2种情况:对工作流整体补数据、对局部节点补数据:
- 对工作流整体补数据,在「任务列表」的工作流一行点击「补数据」按钮,弹窗中列出工作流名称,不会列出内部节点名称,对此执行补数据即可
- 对工作流部分节点补数据:
- 方法1:在「任务列表」中,将工作流内部节点展开,选择待补数据的节点,在其内部节点的某一行点击「补数据」
- 方法2:在依赖视图面板中工作流显示为一个整体,点击「展开」icon,在展开的工作流弹窗点击「补数据」
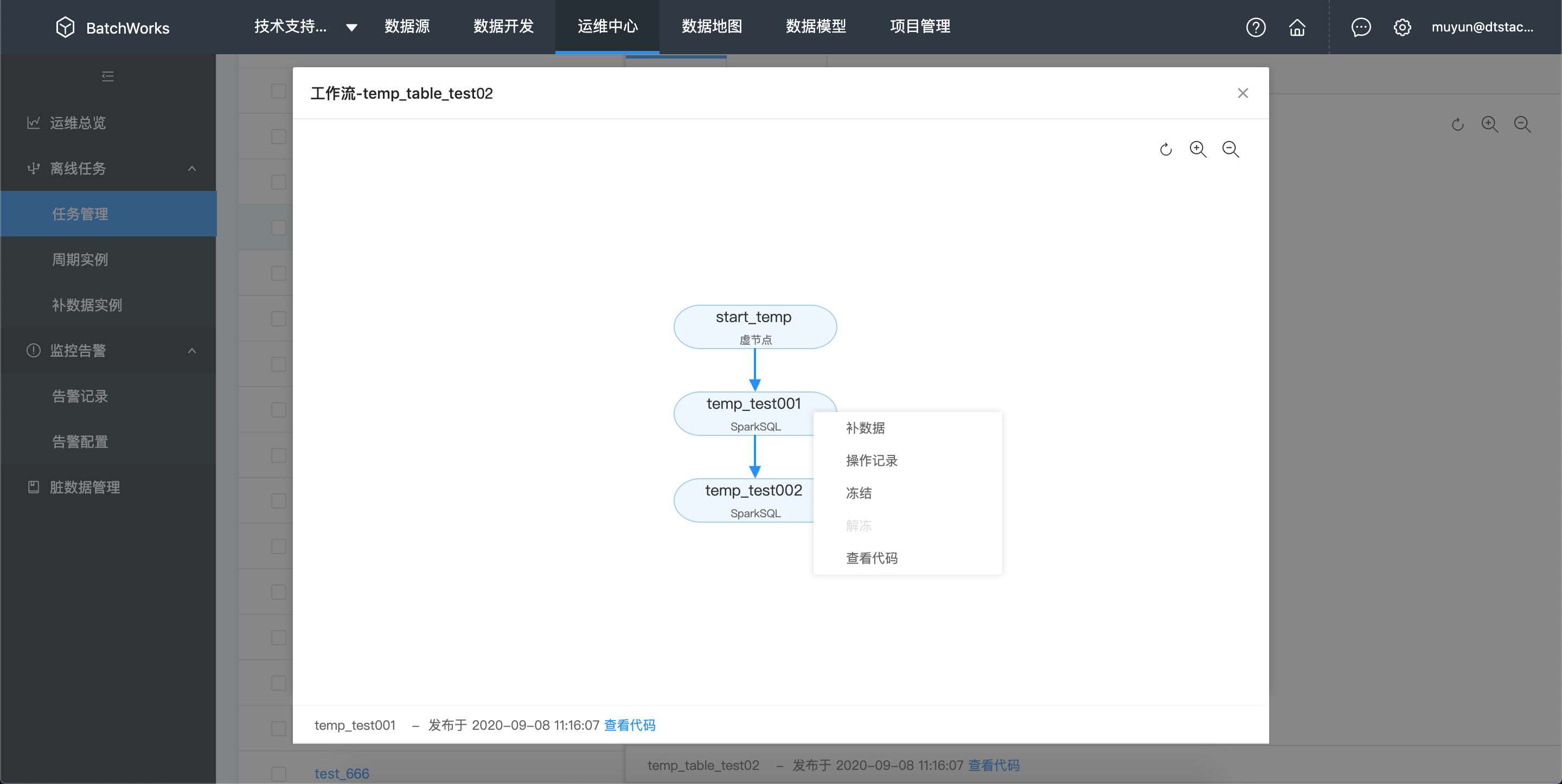
任务下线
任务提交后调度系统将根据其配置的调度周期定期生成实例,若由于业务下线等原因针对某些任务不需要按原计划周期调度,可进行下线处理。
任务冻结是将任务临时冻结,生成的实例也会处于冻结状态,且任务可在「任务管理」中展示。具体可参考实例的状态流转
任务下线是将任务回退至任务提交前的状态,重新提交后才会在「任务管理」中展示。
任务下线操作
提交到调度的所有任务都可进行「下线」操作,包含冻结的任务
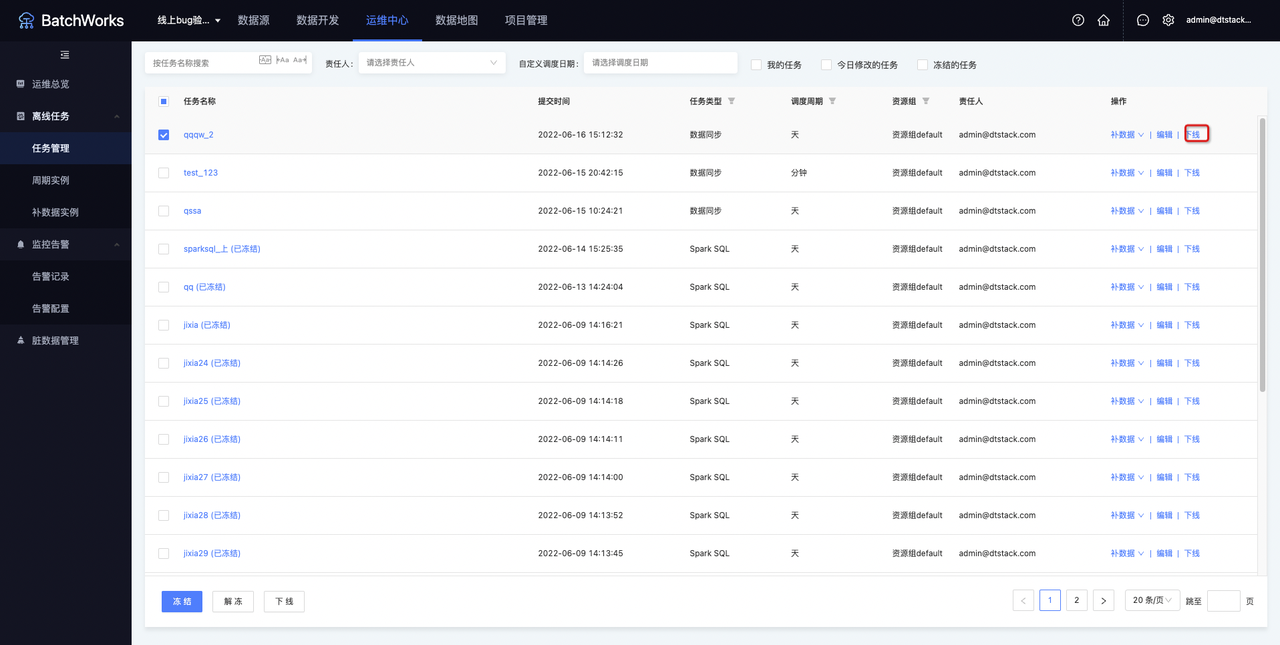
单任务下线
进入「离线任务->任务管理」页面,点击任务操作的「下线」按钮,可对单任务进行下线。
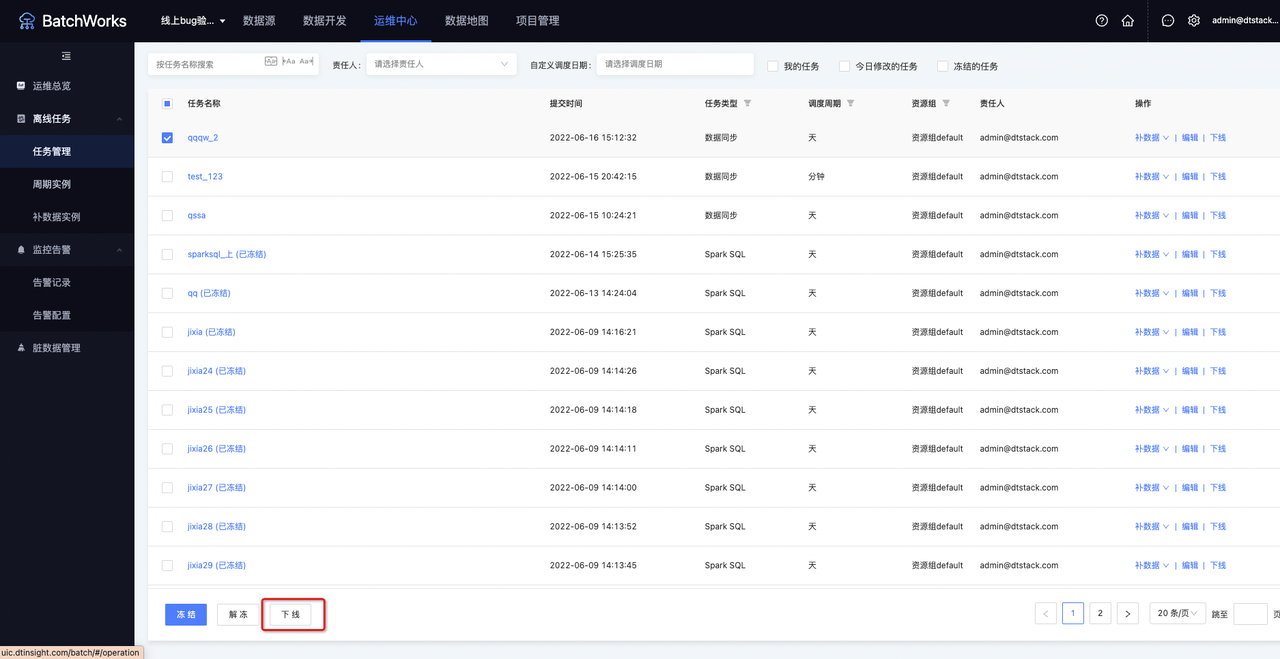
批量任务下线
进入「离线任务->任务管理」页面,勾选需要下线的任务,点击「下线按钮」,可对批量任务进行下线。
任务下线后的影响
1、任务
在「运维中心->任务管理」列表里自动移除;
在「数据开发」页面提交状态变更为未提交;
任务提交记录保留;
在「数据开发->调度依赖」的上游依赖任务配置的任务列表保留,但此任务在数据开发依赖视图中将会断开所有上下游依赖,成为一个孤立节点。
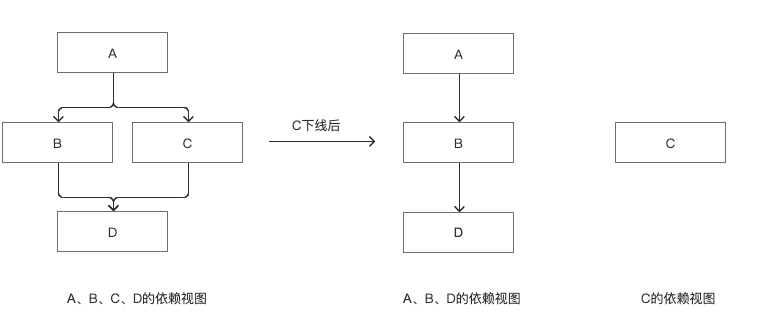
2、实例
- 对于周期实例和补数据实例的直接影响
平台默认的生成实例的时间是每天晚上22点,在这个时间点之前下线任务,那么此任务第二天的实例将不会生成。若在这个时间点之后下线任务,则第二天的实例已生成,针对历史和新的周期实例及补数据实例的状态将会有以下变化:
(1)“等待提交”状态变为“自动取消”状态
(2)运行成功、提交失败、运行失败、自动取消、手动取消、冻结、提交中、等待运行、运行中——状态不变
(3)任务下线后实例仍可被杀死,但对实例进行重跑、置成功并恢复调度、重跑并恢复调度,跑到下线任务的实例时会提示失败。
- 任务重新提交后对实例的影响
任务重新提交后历史和新实例恢复正常操作
3、任务告警
若任务下线,则告警规则中配置的任务被移除。
依赖视图
在「任务列表」中点击任务名称,在任务右侧会展开依赖视图面板,依赖视图中,展现了任务与其上下游任务的依赖关系,默认展开当前任务及其下游1层任务
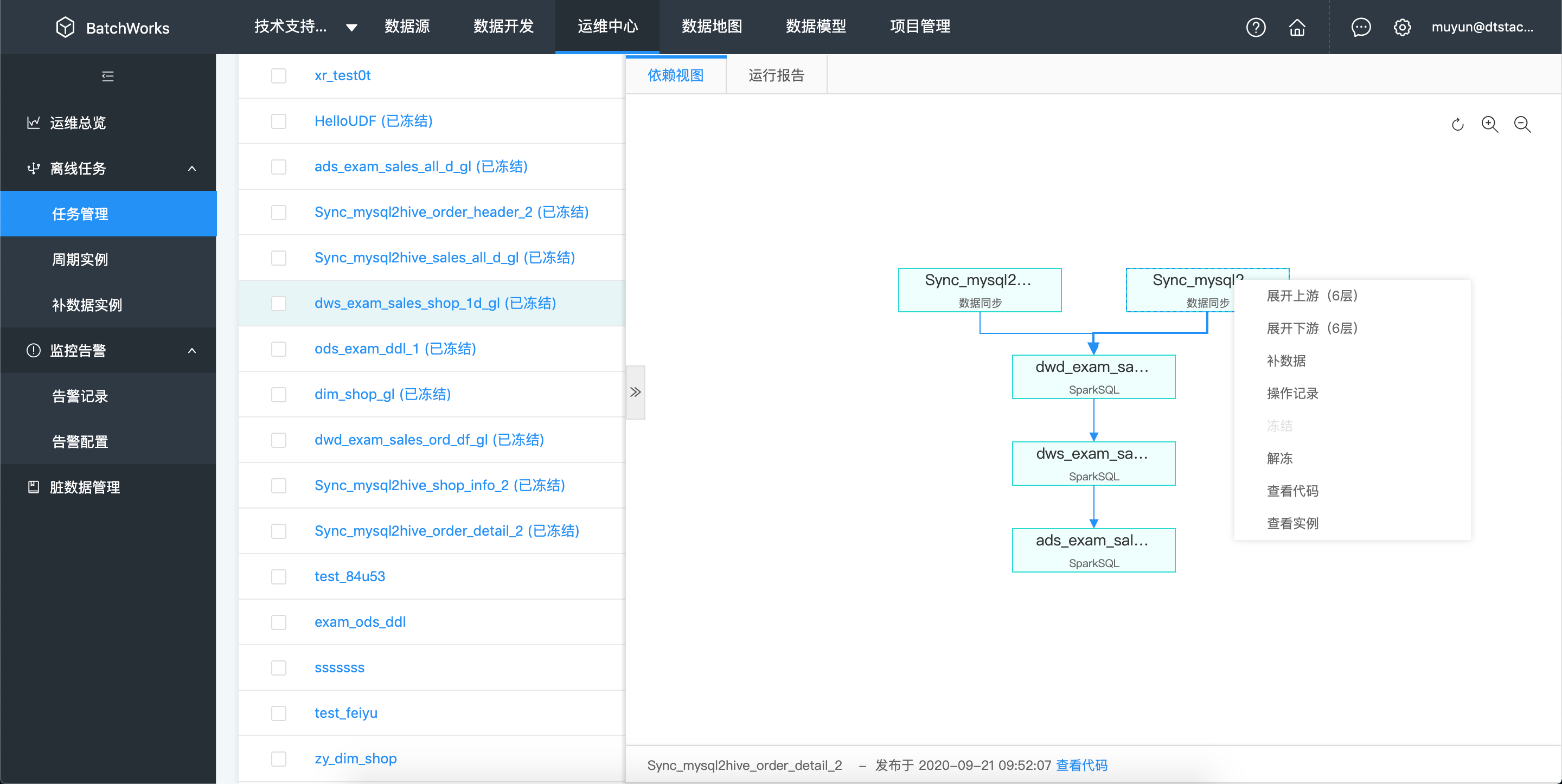
基本操作
依赖视图中的基本操作如下:
- 绘图区域:
- DAG图的拖拽:按住左键,可对DAG图进行整体拖拽移动
- DAG图的刷新:点击「刷新」icon,可对依赖视图整体刷新(通常用于回到最初选择的任务),需注意,刷新后,已经展开的上下有关系、缩放比例将会重置
- DAG图的放大、缩小:点击「放大」或「缩小」icon即可
- 查看代码:点击后,从当前页面跳转至数据开发页面
- 右键菜单:在依赖视图中,在某个任务上点击鼠标右键,弹出右键菜单
- 展开上/下游(6层):以当前节点为基准,展开当前节点的上下游6层任务,与当前节点平行的任务将不会展现
- 补数据
- 操作记录:展现本任务的操作记录,操作记录包括:创建、提交、冻结/解冻
- 冻结/解冻:对当前任务进行冻结/解冻
- 查看代码:与绘图区域的「查看代码」相同
- 查看实例:点击后跳转至「周期实例」页面,并按此任务名触发一次搜索,业务日期设置为当天
刷新DAG图后,已经展开的上下有关系、缩放比例将会重置
工作流
工作流的基本操作与普通任务相同,区别体现在以下几点:
- 绘图区域:与普通任务相同,区别在于,工作流整体体现为DAG图中的一个节点,需要再次点击「展开」icon,在新的弹窗中展开工作流内部节点
- 右键菜单:
- 补数据:见上文对「补数据」的描述
- 操作记录:展现工作流整体的操作记录,若需要查看工作流内部节点的操作记录,需进入工作流内部节点弹窗查看
运行报告
运行报告中显示此任务在最近一段时间内的执行时长分析,若为同步任务,还支持统计读取和写入的数据量、脏数据量
统计图中的最近次数,其中包括了补数据的信息