数据读取方式
库表方式
概述
数据同步向导模式中,除了文件类型和半结构化类型的数据源,其他数据源都支持直接进行按照库表的方式进行读取。
操作说明
如图所示,「配置方式」为「选择库表」时,可以通过选取「schema」和「表」的方式进行数据读取配置。schema和表支持选择的范围为数据源链接配置用户支持访问的所有库表。
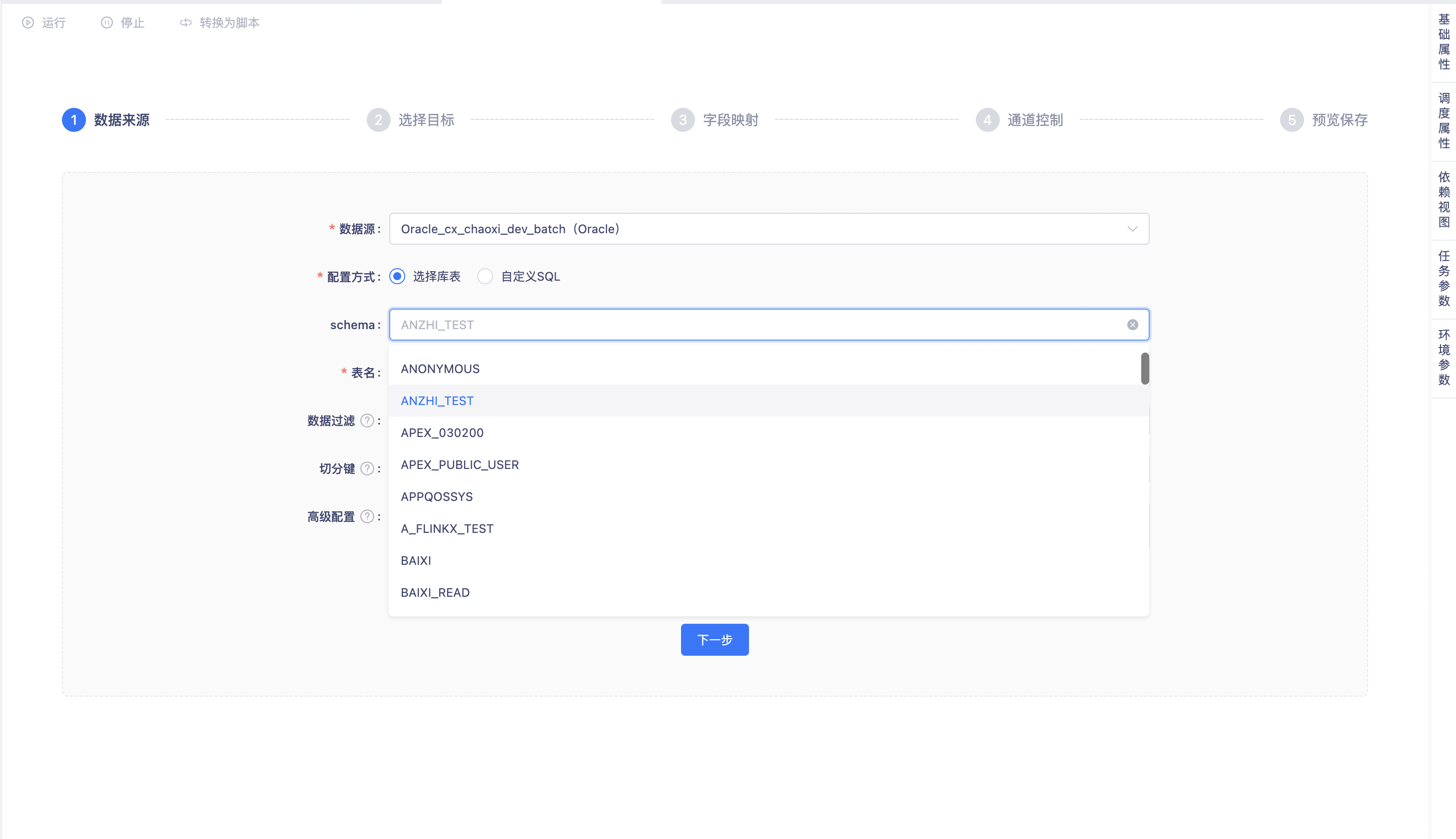
当选择当前项目或其他项目meta数据源作为数据来源时,schema和表的选择范围将会存在以下限制
1、表选择时,脏数据表将不展示
2、当前项目的meta数据源进行schema选择时,仅展示当前项目的meta schema;其他项目的meta数据源引入到当前项目进行schema选择时,仅展示其他项目的meta schema。
因meta schema对应的用户是控制台配置的用户,集群下所有项目的meta数据源对应的用户都是同一个,而数据同步的用户权限判断是以数据源连接用户作为判断对象,因此针对meta schema开放schema的选项会导致任一项目可访问别的项目的meta schema
自定义SQL方式
概述
数据同步向导模式中部分数据源支持填写自定义SQL,可直接使用自定义SQL对一张表或者多张表进行粗加工,再对得到的结果进行读取,例如select * from test,即代表选中整张test表。
目前支持自定义SQL的数据源范围如下:Oracle、MySQL、PostgreSQL、SQLServer、TDSQL、Greenplum、DB@、达梦Oracle&Mysql、KingBase、GaussDB、TiDB、ADB、HANA、Phoenix、Solr。
操作说明
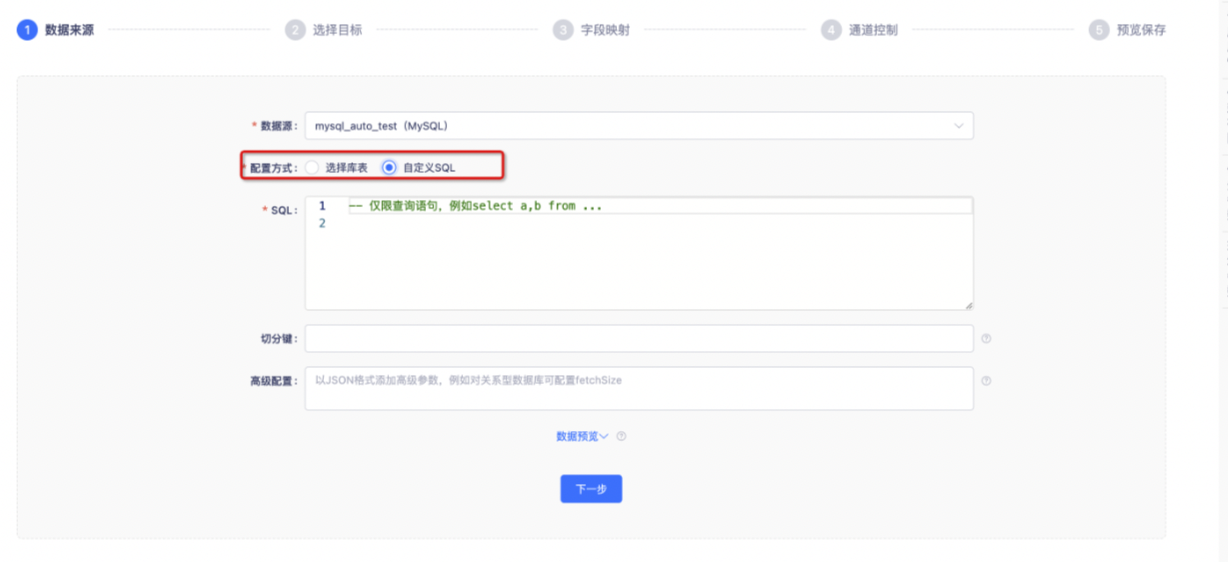
如图所示,在支持Custom SQL的数据源作为数据来源的向导模式中,支持选择配置方式。如图所示,配置方式支持选择「选择库表」或「自定义SQL」。
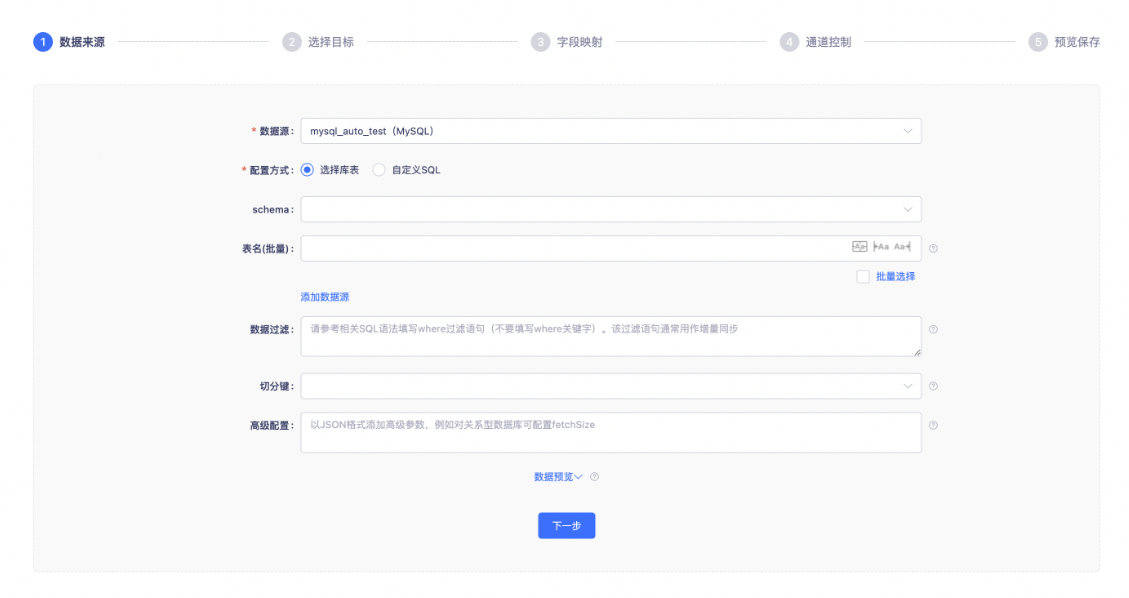
当配置方式选择「选择库表」时,如下图所示,依次选择shcema和表。
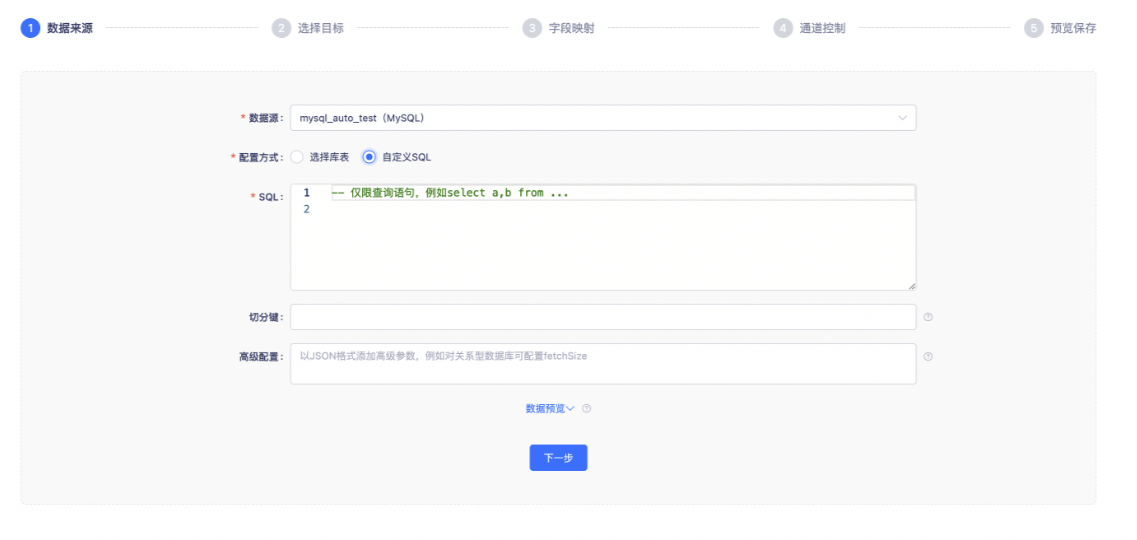
当配置方式选择「自定义SQL」时,如下图所示,可以通过对一张表或者多张表进行粗加工,再对得到的结果进行读取。例:select a,b from c。
通过自定义SQL选中的库表,可在字段映射中解析出来,如下图所示
transformer
在脚本模式中,可以通过transformer用于配置转换SQL,原理是通过将source注册成表,对表进行sql过滤写到下游。所有数据源都可以通过这种方式进行过滤。

数据切分的几种方式
Range切片(jdbc)
获取splitPk(切分键)在数据库中的最大值和最小值,根据并行度大小均匀地分成一个个区间分配给各个split。最终各个分片执行的读取数据的sql语句中会依据数据区间拼接类似 id>10 and id<20的where子句
一般关系型数据库要求splitPk一般是数值类型,TDengine的splitPK仅可支持timestamp类型
例如 splitPk=id,id值的范围为0-50,并行度=3,最终的sql语句类似于:
select ... from table ... where id >= 0 and id < 17 // task0
select ... from table ... where id >= 17 and id < 34 // task1
select ... from table ... where id >= 34 // task2
Mod切片(jdbc)
依赖于数据库提供的mod函数(取余),结合taskNum和总并行度拼接类似mod(id,2)=0的where子句。 例如splitPk=id,并行度=3,最终的sql语句类似于:
select ... from table ... where mod(id,3)=0 // task0
select ... from table ... where mod(id,3)=1 // task1
select ... from table ... where mod(id,3)=2 // task2
File切片(文件系统)
先获取所有路径下的文件,根据配置读取的并发数,进行分片,如下图

FTP支持自定义并发读取,详情查看「同步任务配置- FTP」