2024年6月更新日志
上线时间:2024-6
数据开发
离线AI+功能【6.2】
离线开发支持对接AIGC接口,支持智能代码优化、智能注释、智能解释、Text 2 SQL、日志智能解析等功能
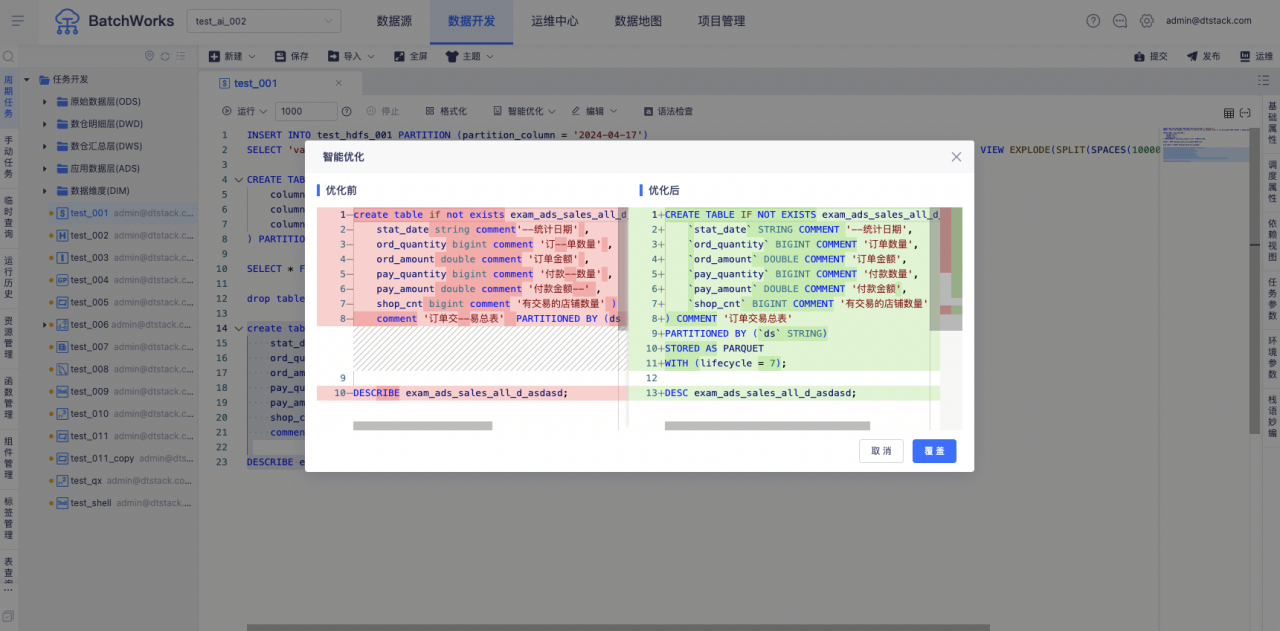
代码优化&智能注释&智能解释
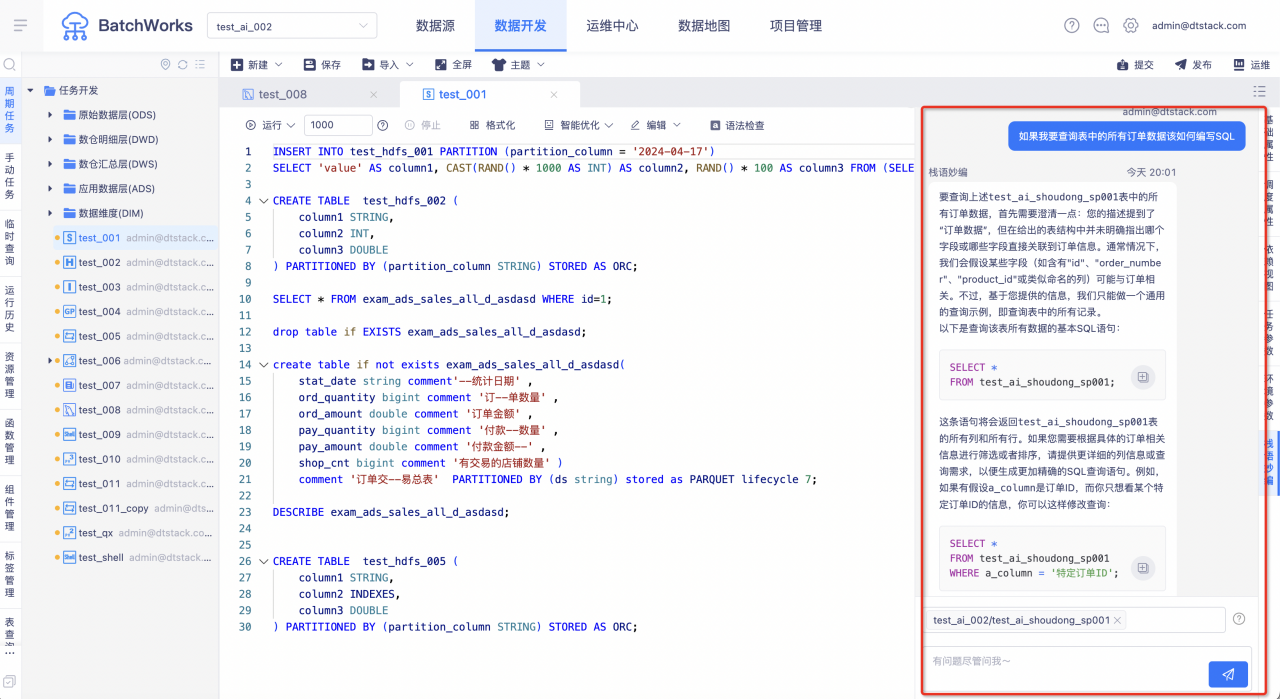
Test 2 SQL
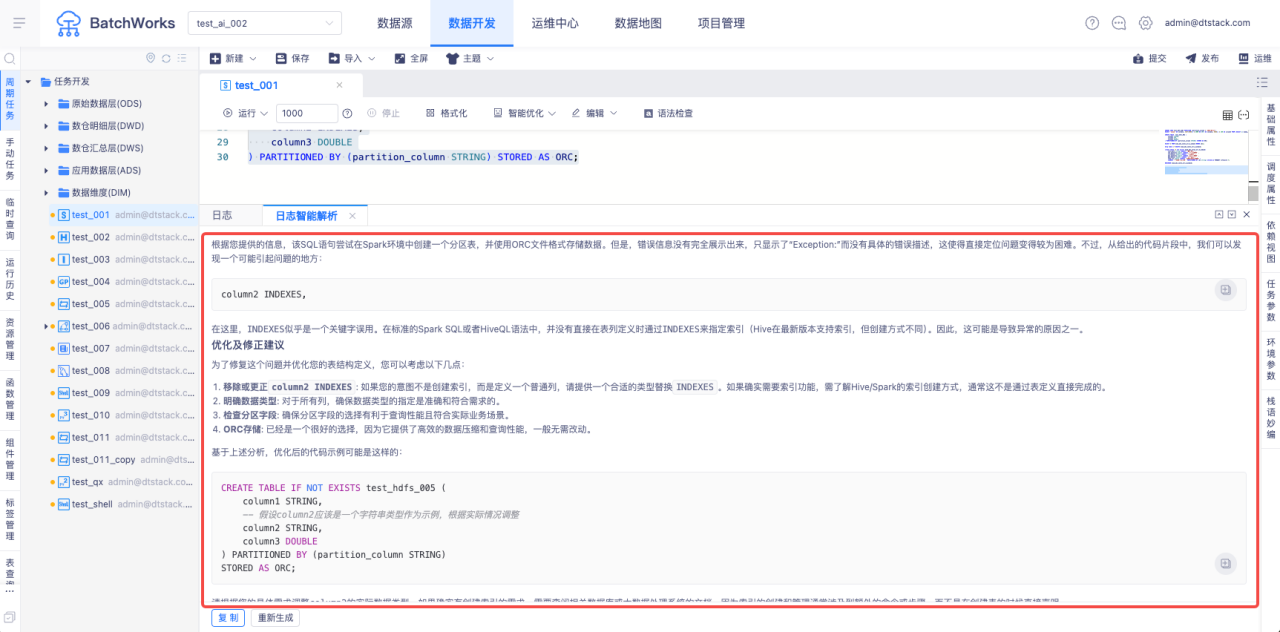
日志智能解析
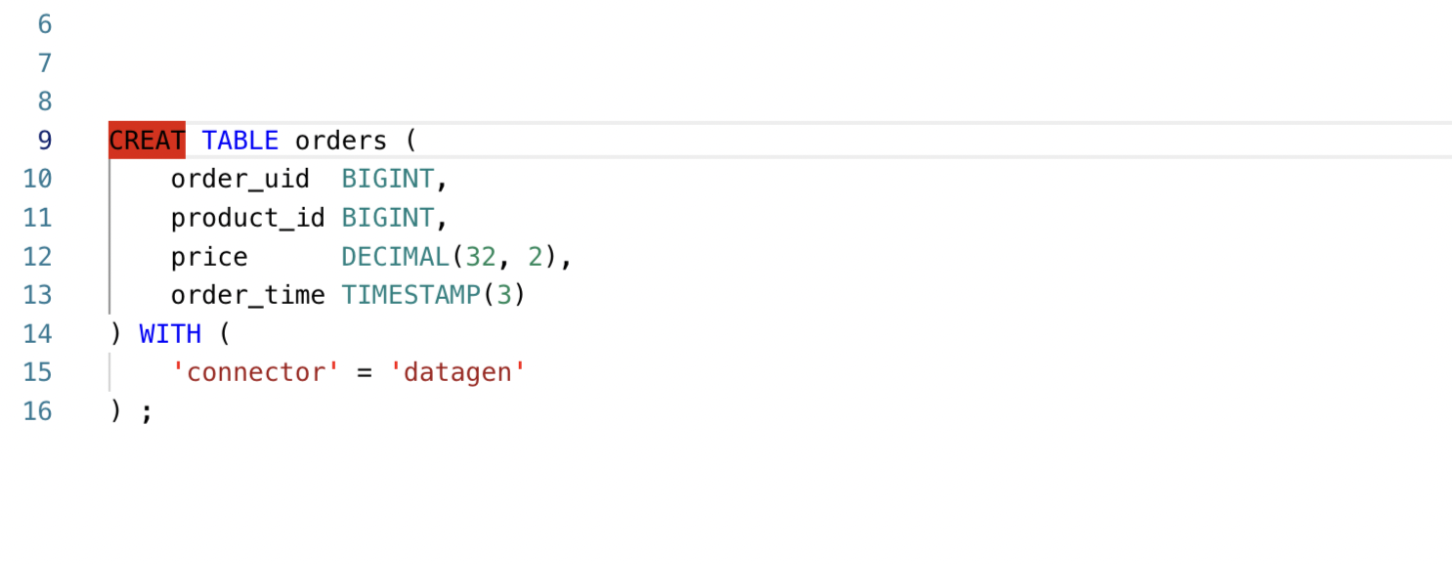
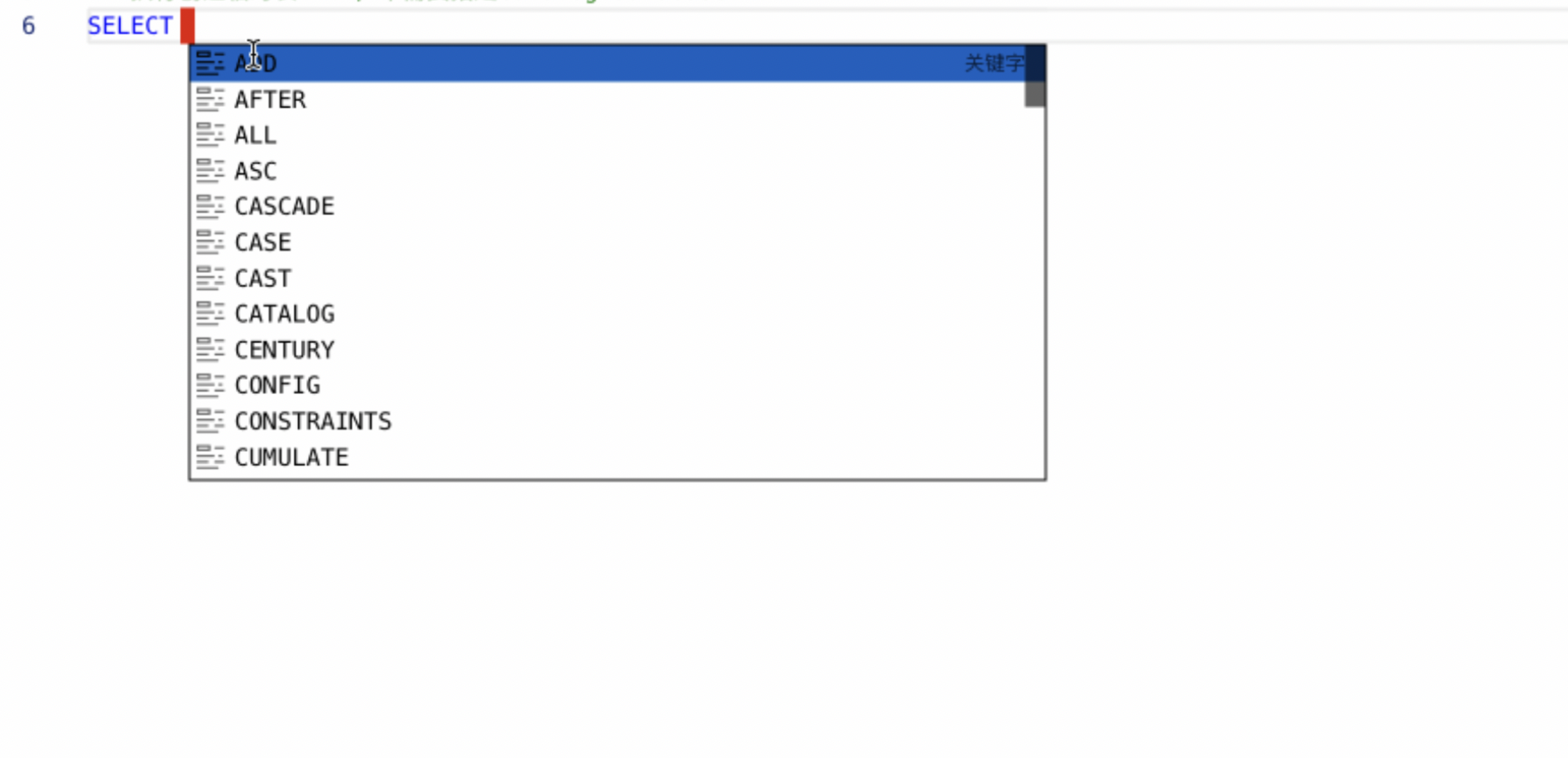
SQL编辑器升级【6.2】
主要针对以下几个场景进行了优化:1、语法高亮 2、错误飘红 3、语法自动补全

支持Doris计算引擎【6.2】
在离线中支持Doris计算引擎,支持周期任务、数据同步、手动任务、临时查询、语法提示、表查询、函数管理、存储过程、依赖推荐、任务上下游参数、代码模版、按项目、个人粒度绑定数据库账号、执行计划、导入本地数据等功能
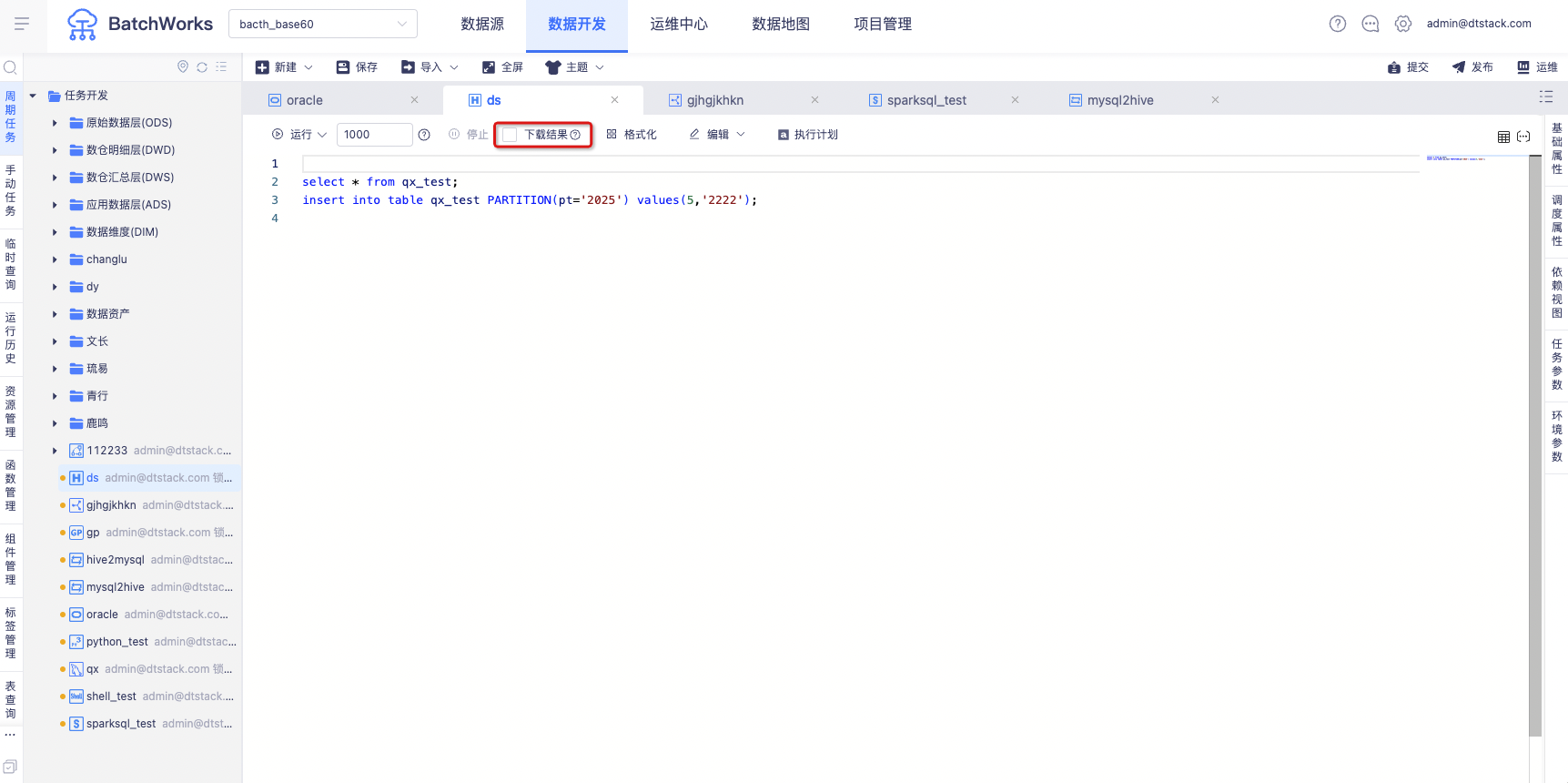
Hive SQL临时查询运行速率优化【6.2】
在Hive SQL中新增「下载结果」单选按钮,当用户无需下载结果时,可以显著提升Hive SQL的执行速率。
| SQL耗时(平台数据按页面接口时间计算) | ||
|---|---|---|
| 序号 | 优化后平台耗时(单位:s) | 优化前平台耗时(单位:s) |
| 1 | 52.62 | 129.13 |
| 2 | 96 | 120.35 |
| 3 | 51 | 168.14 |
| 平均值 | 66.54 | 139.21 |
复杂查询在优化后,查询耗时明显缩短,响应时间是原来的一半。原因是任务直接查询,节省了提交yarn队列和获取yarn任务结果的时间。
Spark SQL函数注册优化【5.2】
背景:客户日常在使用Spark SQL函数的过程中,通常写的是Hive SQL函数,但是客户自己可能并不清楚自己写的是Hive SQL函数,这样就会导致在Spark SQL函数中创建不了,导致报错
优化:
1、Spark SQL目录下的udf既可以是Hive udf,也可以是Spark udf。用户在创建udf的时候,离线侧进行判断,解析用户创建的udf是Spark udf还是Hive udf,帮助用户完成注册。
2、部署了Sparkthitft才会展示Spark SQL函数,部署了hive server才会展示hive sql 函数。
Yarn TFlog日志下载优化【6.2】
日志乱码问题解决
HDFS表查询优化【6.2】
背景:当数据量过大时
1、服务请求异常
2、limit或者count 无法正常返回结果
3、数据地图预览无法查看数据
优化:
Split的分片处理逻辑调整
运维中心
补数据支持设置执行时间【6.2】
场景一:
业务场景存在数据更新,希望能够对Spark SQL任务定时进行数据的重跑,例如每天进行前七天为业务日期的数据的重跑,目前产品上的方案是 每天手动进行补数据的操作。但是客户觉得每天去手动补数据非常麻烦,因为他们任务量大,可能需要一天手动补很多数据。因此周期补数据就可以满足客户的以上场景
场景二:
某企业为不影响周期任务的正常运行,经常在凌晨进行补数据,需要凌晨人工操作。现在设置补数据运行时间为2:00即可
功能:
1、支持定时补数据、周期补数据功能
2、运维中心新增「补数据任务」菜单,可统一管理「补数据任务管理」和「补数据任务实例」页面
立即运行补数据实例
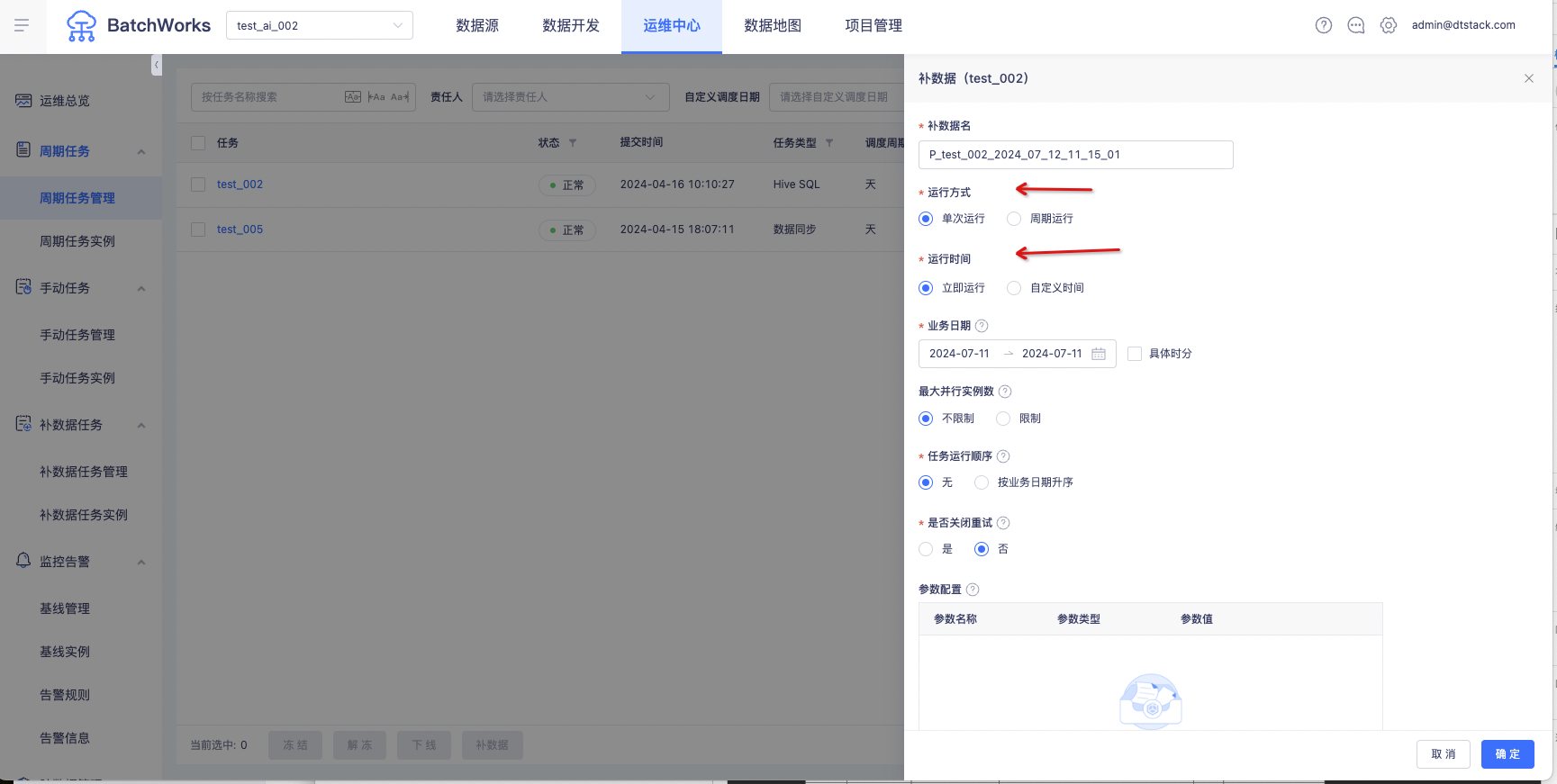
定时运行补数据实例
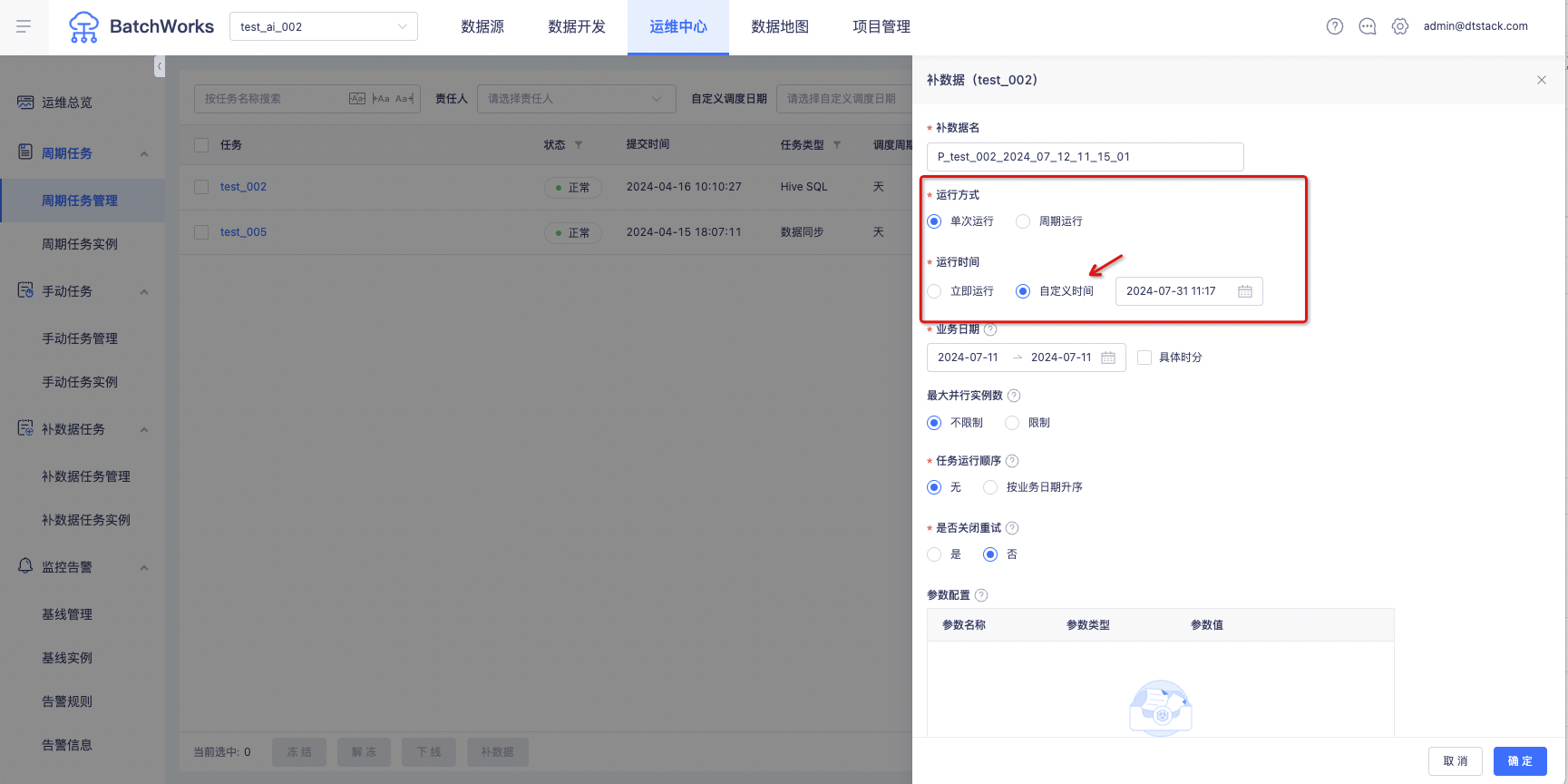
周期运行补数据实例
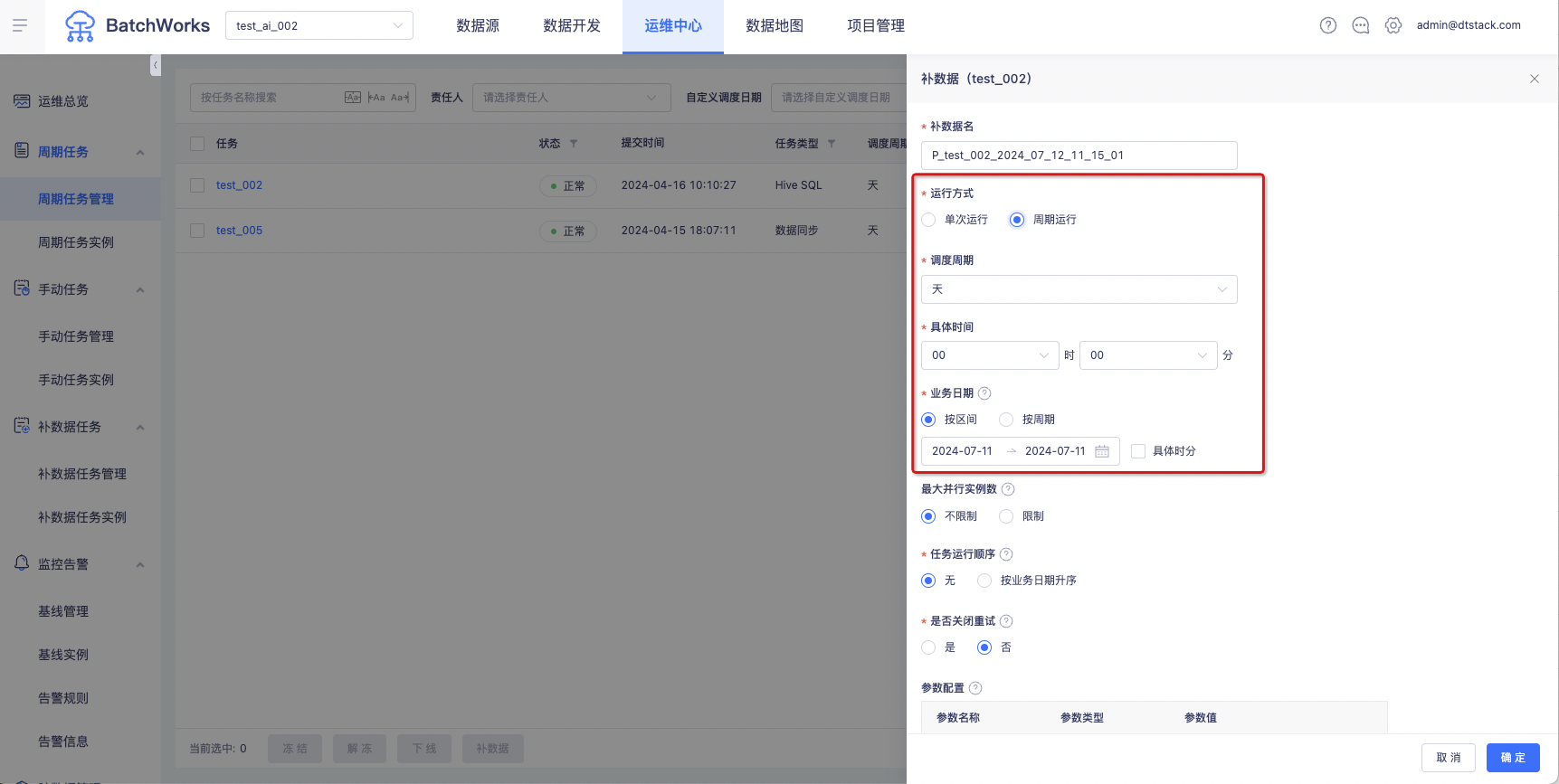
周期补数据任务运维
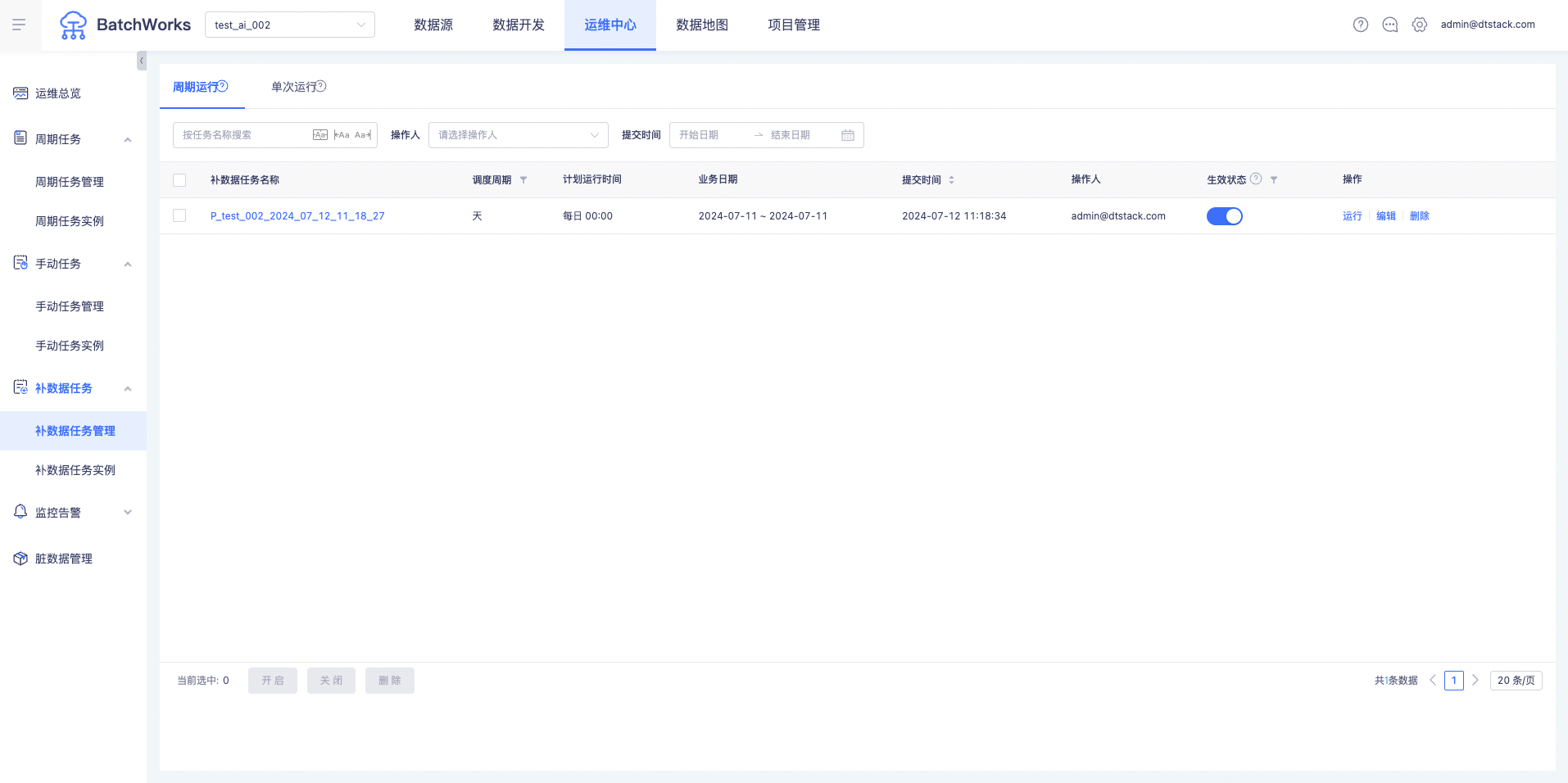
立即补数据&定时补数据任务运维