派生指标
概述
派生指标基于原子指标进行开发生成,一般是结合实际的业务场景,通过聚合原子指标的度量列,筛选原子指标的维度列,形成有实际业务统计含义的派生指标 基于用户在页面上的配置信息,指标平台会自动生成派生指标计算sql脚本。
一个原子指标可以派生出很多派生指标。
配置派生指标的步骤整体包括「设置基本信息」、「设置技术信息」、「设置调度信息」、「生成指标」四步。
技术信息
相比较原子指标的配置生成方式,派生指标的技术信息生成,主要是基于用户在页面上相关信息项的选择配置,然后平台自动将其拼接组合成一段完整的sql脚本
下面具体说明一下派生指标配置过程中,技术信息的配置说明
选择原子指标
因为派生指标是基于原子指标进行开发的,所以在配置派生指标的过程中,平台会要求用户在所有已发布的原子指标里选择需要派生的那一个,然后再基于选择的原子指标的相关信息,引导配置其他技术信息。
这里选择是所有已经发布的原子指标哦。
选择派生维度
维度选择遵以下原则:
- 从选择的原子指标里包括的维度中,选择此次派生指标需要派生的维度
- 支持选择多个派生维度,根据此次派生指标的实际业务需求进行选择,如:当选择【消费金额】原子指标,来配置【当日消费金额总和】,需要从「区域维度」统计各个地区当日消费金额分布情况,这时候,就只需要从【消费金额】的维度里选择「区域维度」即可
- 平台后续的指标计算落地,均会根据选择的维度进行分组统计
计量单位
通过计量单位的设置,记录指标计算结果的单位。
如当统计「账户余额」指标时,可以通过计量单位「万元」的登记,清晰地获取到指标计算结果中的「20」对应的是「20万元」
时间维度和统计周期
有聚合必然有统计时间范围,通过 时间维度选择统计的时间来源,结合统计周期的选择,组合形成指标的统计时间范围,如「当日消费金额总和」这个指标时间维度选择的「消费时间」,统计周期选择的「当日」,即计算的是 ‘消费时间是当日的消费金额总和’
统计周期单选,值域来源于【统计周期】模块,具体可以查看统计周期模块的说明。
业务限定
业务限定创建的,与当前指标引用的原子指标对应的数据模型相同的记录可被选中,最终作用于where后作为过滤条件使用。最多支持添加5个业务限定记录。
试计算
基于技术信息中设置的信息,系统通过试计算可以在线查看指标计算的统计sql,校验配置的准确性,整体是以select开头的逻辑sql。
试计算通过的前提下,才能进入下一步配置。
脚本举例
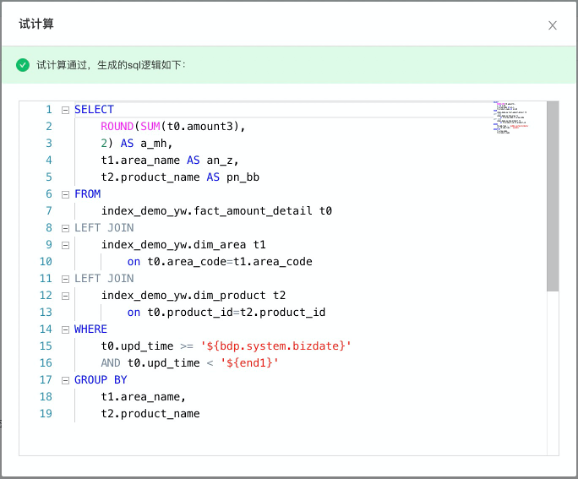
统计周期对应的脚本体现在where条件后面,目前遵循 左闭右开 的规则,对照【统计周期】模块中配置的信息,大于等于开始时间,小于结束时间。
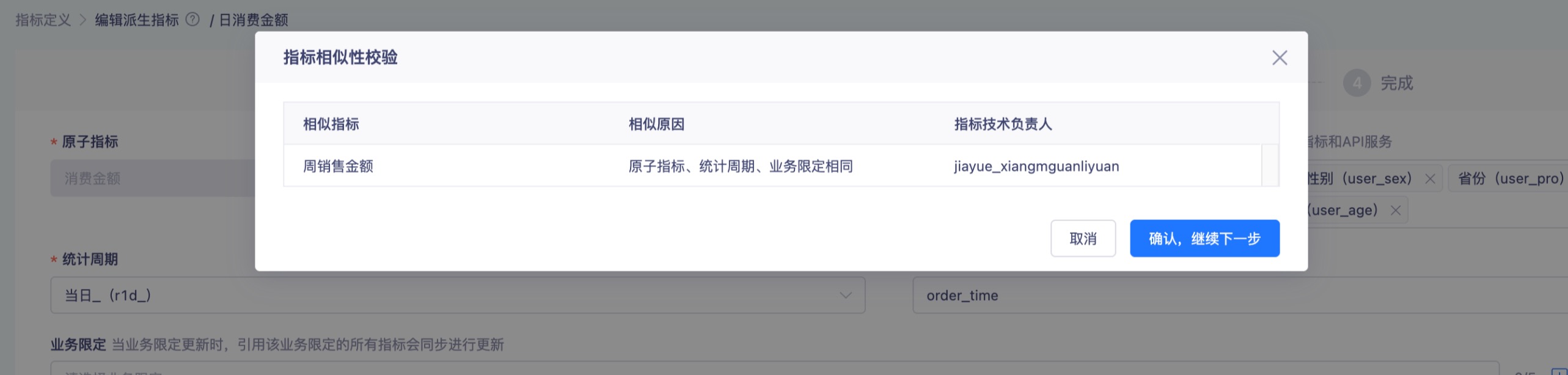
配置指标技术信息时,系统会针对指标相似性做校验,对于相似指标会做提示,若用户认为该可接受相似指标的存在,则可忽略该提示继续配置。目前系统会对如下相似场景做相似性提示:
- 选择原子指标相同 且 统计周期相同 且 业务限定相同的派生指标,判断为相似派生指标(相似原因:原子指标、统计周期、业务限定相同)
指标落表
平台提供两种指标落表方式,一种是自行计算指标落表,将结果表与指标平台定义的指标进行关系绑定;另一种是由平台落表,平台完成从建表、建任务、计算数据并写入结果表的全过程。
若对应的数据模型定义的指标数据由平台生成,则不可选择自行计算落表方式。
针对Doris引擎而言,考虑引擎特色,指标可选择不落表。配置方式:数据查询方式 = 即席查询
指标落表自行完成
设置方式:第三步设置加工信息中,指标加工方式定义为「手动生成」。
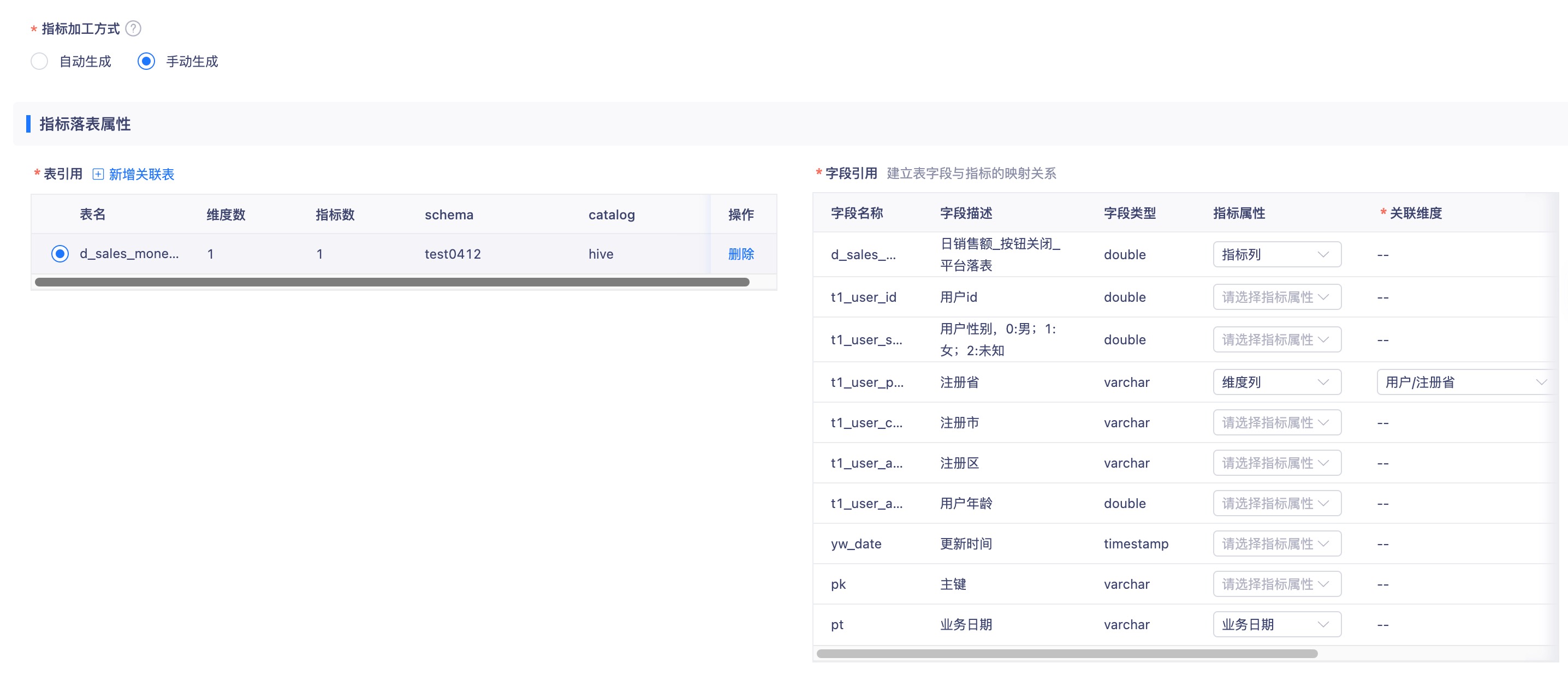
- 第一步:新增关联表,选择需要注册的表,选择后,表会添加至左侧列表
- 第二步:选择需要定义的表,右侧显示对应的字段,定义字段中与本次定义指标相关的指标列、维度列、业务日期列。
- 维度列:字段定义为维度列后,需要在关联维度中将该维度列与指标定义的维度绑定,至少需要选择一个字段作为维度列
- 指标列:一个指标针对一张表只可选一个指标列
- 业务日期:一个指标针对一张表只可选一个业务日期,选择为业务日期的字段,需要在日期格式列中定义日期格式。目前平台支持yyyyMMdd 或 yyyy-MM-dd格式。
从规范性角度考虑,目前平台对一张表的字段的指标属性定义是唯一的,即,对于一张宽表而言,部分字段之前已经在其他指标中注册过,则本次注册到当前指标是,只需定义指标列即可,不可定义其他指标属性。若想对维度列、业务日期做修改,需要先取消其他指标的绑定关系才可修改。
指标落表平台完成
设置方式:第三步设置加工信息中,指标加工方式定义为「自动生成」。
设置为平台落表的,需要定义落表内容、调度信息等内容。
落表内容定义
可指定维度进行落表,一个维度组合只能定义一次,不可重复定义。请至少定义一个结果表。

系统会基于选择的聚合维度定义一个默认的指标结果表名称,用户可在此基础上修改,编辑时不支持修改聚合维度、物理表名称,只可删除重建。
定义后,需要进行试计算,试计算通过的可继续定义指标。
调度信息
不同于原子指标,派生指标一般是根据实际的场景进行了进一步的聚合统计,所以需要对其计算结果进行定期落地,平台通过调度信息的配置,生成对应的调度任务提交到【运维中心】,然后通过调度任务的执行,实现指标计算结果的周期性落地。
目前一个指标对应一个调度任务,所有维度结果计算将在同一个任务中运行完成。
调度信息包括「调度属性」、「依赖属性」、「其他属性」三块:
调度属性
- 调度类型:周期性调度
- 出错重试:即任务执行失败的重试机制设置,默认不勾选即不重试,勾选后设置重试次数和每次重试间隔的时间
- 调度周期:目前包括「天」、「周」、「月」三种类型,如果选择了「天」,则表示此任务是每天执行一次
| 调度周期 | 参数设置 |
|---|---|
| 天 | 天调度任务,表示此调度任务是每天自动执行一次,选择之后需要配置「具体时间」,即任务固定的执行时间: 1.格式:精确到分钟,默认00:00 2.值域:00:00到23:59 |
| 周 | 周调度任务,表示每周特定几天的特定时间点自动执行一次,选择之后需要配置「选择时间」和「具体时间」: 1.选择时间:下拉多选,星期一 到 星期天 一共7个选项 2.具体时间:执行的具体时间点,同「天」调度 |
| 月 | 月调度任务,表示每月特定几天的特定时间点自动执行一次,选择之后需要配置「选择时间」和「具体时间」: 1.选择时间:下拉多选,每月1号 到 每月31号 一共31个选项 2.具体时间:执行的具体时间点,同「天」调度 |
针对源表数据量较大或者一些比较重要的指标,建议设置出错重试,保证指标任务运行的稳定性。
在设置调度周期的时间时,建议考虑一下当前指标的上游数据同步情况,尽可能地避免过早执行导致计算结果不正确的情况。
依赖属性
任务依赖关系包含两类:任务之间的上下游依赖和任务自身前后跨周期调度依赖
- 任务之间的上下游依赖:支持进行指标间的依赖关系配置和跨租户/跨产品/跨项目的其他调度任务的依赖关系配置。如:指标B必须在指标A计算完成后才能开始计算,即指标A是指标B的上游指标,这时候通过依赖属性的配置。配置步骤如下:
- 点击「添加依赖」按钮进行上游依赖任务选择;
- 选择任务所属租户:选项范围为当前登录用户有租户权限的租户集合,默认填充当前租户;
- 选择任务所属产品:指标管理或离线开发,默认填充指标管理;
- 选择任务所属项目:基于选择的租户、产品,选项范围为当前登录用户有项目权限的项目集合,默认填充当前项目;
- 选择任务:基于选择的租户、产品、项目,选项范围为除指标血缘关联的上游指标所在任务外的其他任务,每次可选一个任务,若要依赖多个,请多次添加。平台会自动根据上游指标,找到其对应的指标任务,在【运维中心】模块中实现上下游任务的依赖关系。
- 一个派生指标可以添加多个上游指标,即依赖多个上游指标任务
- 不支持添加原子指标为上游指标,因为原子指标没有调度任务
- 不支持添加未发布的指标为上游指标
- 任务自身前后跨周期调度依赖:包括如下五个选项,其中,任务结束包括成功、失败、取消3种情况。
- 不依赖上一调度周期:不依赖其他周期
- 自依赖,等待上一调度周期成功,才能继续运行:等待当前指标对应的指标任务,每次执行前都要等他上一次的周期运行成功,比如一个每天5点跑的任务,1号的5点的周期实例跑失败了,这时候2号5点的周期实例也不用跑了
- 自依赖,等待上一调度周期结束,才能继续运行:区别与上一个选项,只要运行结束即可,不管是成功、失败、还是取消,只要不是正在运行即可
- 等待下游任务的上一周期成功,才能继续运行:等待当前指标任务的所有下游任务上一周期运行成功,如果当前指标任务下游有5个任务,就要等这5个都运行成功,一个没成功都不行
- 等待下游任务的上一周期结束,才能继续运行:区别与上一个选项,只要运行结束即可
其他属性
包括「优先级参数」和「同环比设置」
- 优先级参数: 手动设置指标任务优先级,值越小,优先级越高,数值范围1-100,默认1,设置了任务优先级后,可能不容易观察到效果,原因是优先级的判断是弱于任务的计划时间和上下游依赖的,只有在大量任务同时满足了计划时间+上下游依赖的前提下(即满足提交至引擎的条件),任务会大量堆积的时候,优先级参数才会体现较为明显的效果。
- 同环比设置: 默认不开启同环比,当开启了同环比后,在此指标的【结果查询】,会自动根据当前指标的计算规则,按照对应同环比的计算公式,计算出结果
| 名称 | 说明 |
|---|---|
| 日同比 | 日同期,今天与上月同一天比较,如2021年10月7日和2021年9月7日相比较 |
| 月同比 | 月同期,今天与去年同一天比较,如2021年10月7日和2020年10月7日相比较 |
| 日环比 | 日上期,今天与昨天相比较,如2021年10月7日和2021年10月6日相比较 |
| 季环比 | 季上期,今天与上个季度同一天相比较,如2021年10月7日和2021年7月7日相比较 |
各种参数的优先级判断顺序:任务计划时间 > 任务上下游 > 任务优先级参数。
同环比的计算是平台实时根据指标结果结果计算得出,不落指标表。
调度信息配置完成后,支持点击「预览」,在线查看调度任务的sql脚本,此处的sql脚本区别于上一步试计算的脚本,主要是基于上一步指标技术信息的配置,自动生成包括 创建表、插入表 语句在内的完整的任务脚本,然后结合调度信息,待指标发布后,提交至运维中心执行任务,调度任务后续的执行维护具体见运维中心
保存与发布
配置完派生指标相关信息,进入最后一步【完成】步骤,同样可以选择「保存」或者「保存并发布」操作,但是 如果只是保存的话,派生指标不会在【指标市场】中发布展示,且不会提交对应的调度任务到【运维中心】,其他指标也无法使用此派生指标,此时的指标是未发布的状态, ,只有 选择保存并发布后,相应的派生指标才会在【指标市场】中发布展示,此时派生指标就可以被其他指标使用了,同时也会提交对应的调度任务到【运维中心】更新调度任务 :
- 每发布一次,均会生成一个新的版本,在指标对应的【变更记录】模块中可以查看到对应指标所有的历史版本,支持在线进行 版本对比,具体的变更规则见版本变更
- 如果仅仅只是保存后的的派生指标,会在指标定义列表中展示,此时的派生指标因为是未发布的,所以不会产生新版本
派生指标一次性只能生成一个,暂时不支持批量生成。
配置完生成派生指标后,即生成对应的派生指标元数据信息,包括:
- 基本属性:包括基本信息、发布信息、技术信息;
- 血缘关系:当前指标的上下游关系及应用版本信息(仅显示已发布指标),并可根据时间范围和维度筛选进行结果记录查询;
- 变更记录:当前指标的历史版本信息,可进行版本间对比,每次最多支持2个版本间进行对比;
- 应用信息:当前指标的应用信息,包括上游引用指标信息、指标共享信息、API信息、数据权限及告警规则信息;
其中技术信息为试计算的sql,是基于页面的配置信息自动拼接生成,整体是‘select from…’的格式。
相比较原子指标,派生指标默认会生成其对应的调度任务。