6.1.3更新日志
上线时间:2023-10-30
功能新增
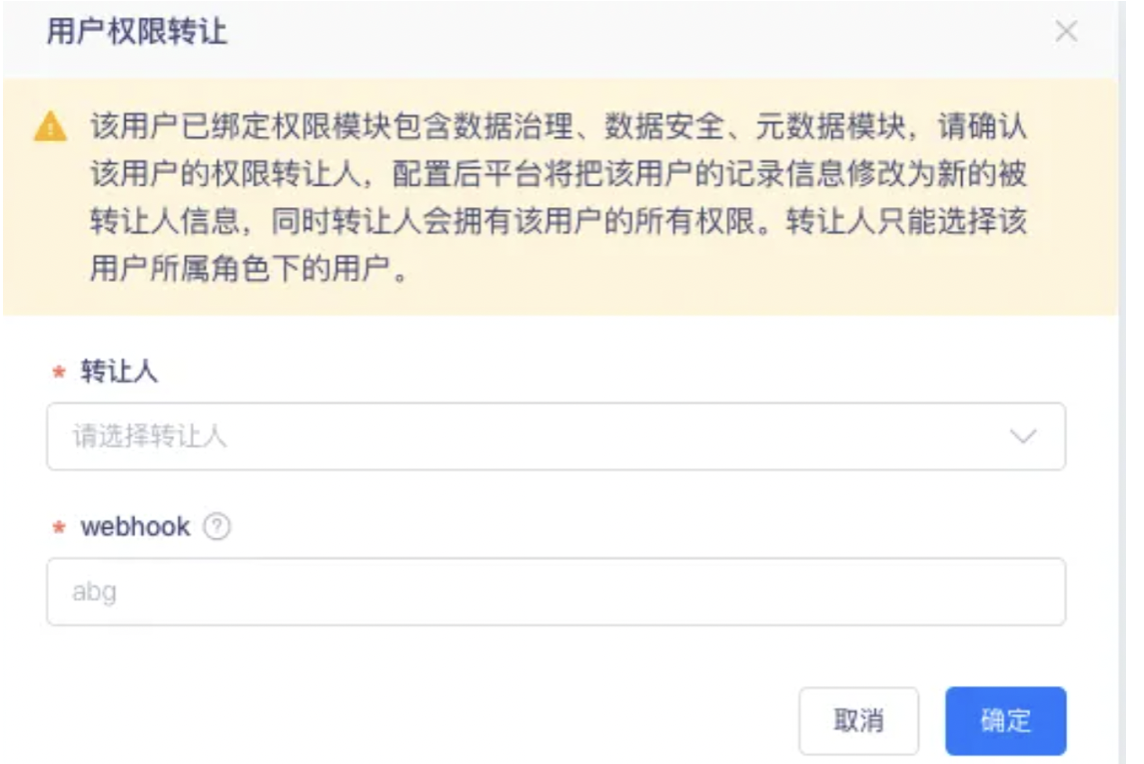
【平台管理】移除用户时需进行用户权限转让【上线版本:6.0】
需求背景:1.当人员离职时,需支持自动交接,移除产品操作时需要进行用户信息校验,若已经负责了数据治理模块的具体项目/有关联的待处理问题、有关联的通知信息配置。需要进行提示,并需进行权限转让后再移除产品
功能:用户移除的时候进行权限交接,包括告警配置,权限信息等信息的交接.
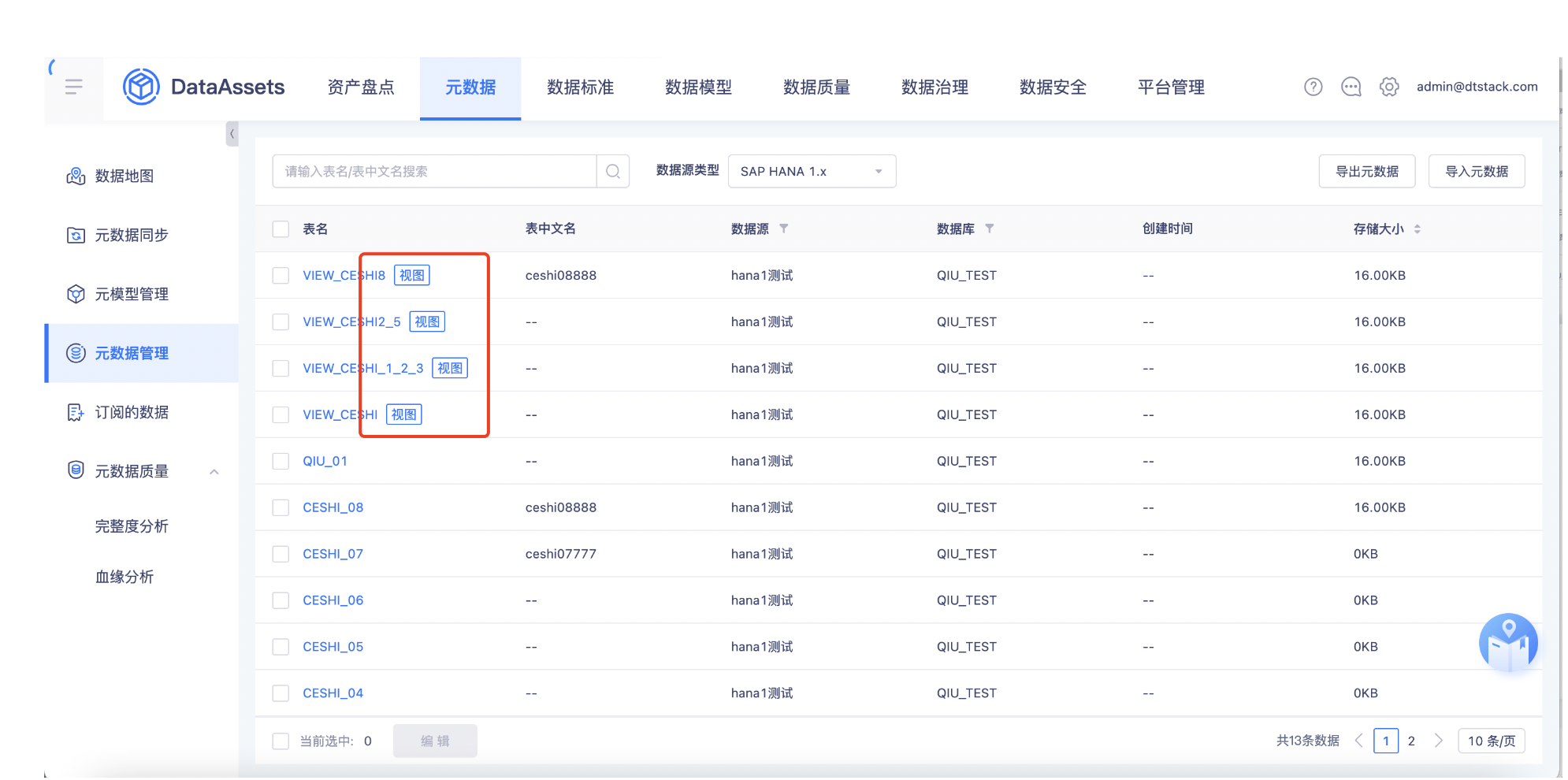
【元数据】oushudb/oracle类型数据源支持视图同步【上线版本:6.0】
功能:oushudb/oracle类型数据源需要支持视图同步
【元数据】元数据周期同步增加数据库过滤条件【上线版本:5.3】
背景:迭代遗留BUG修复,逻辑优化
功能:元数据周期同步增加数据库过滤条件,新增、编辑周期任务按钮优化元数据周期同步列表,增加数据库、数据表的展示
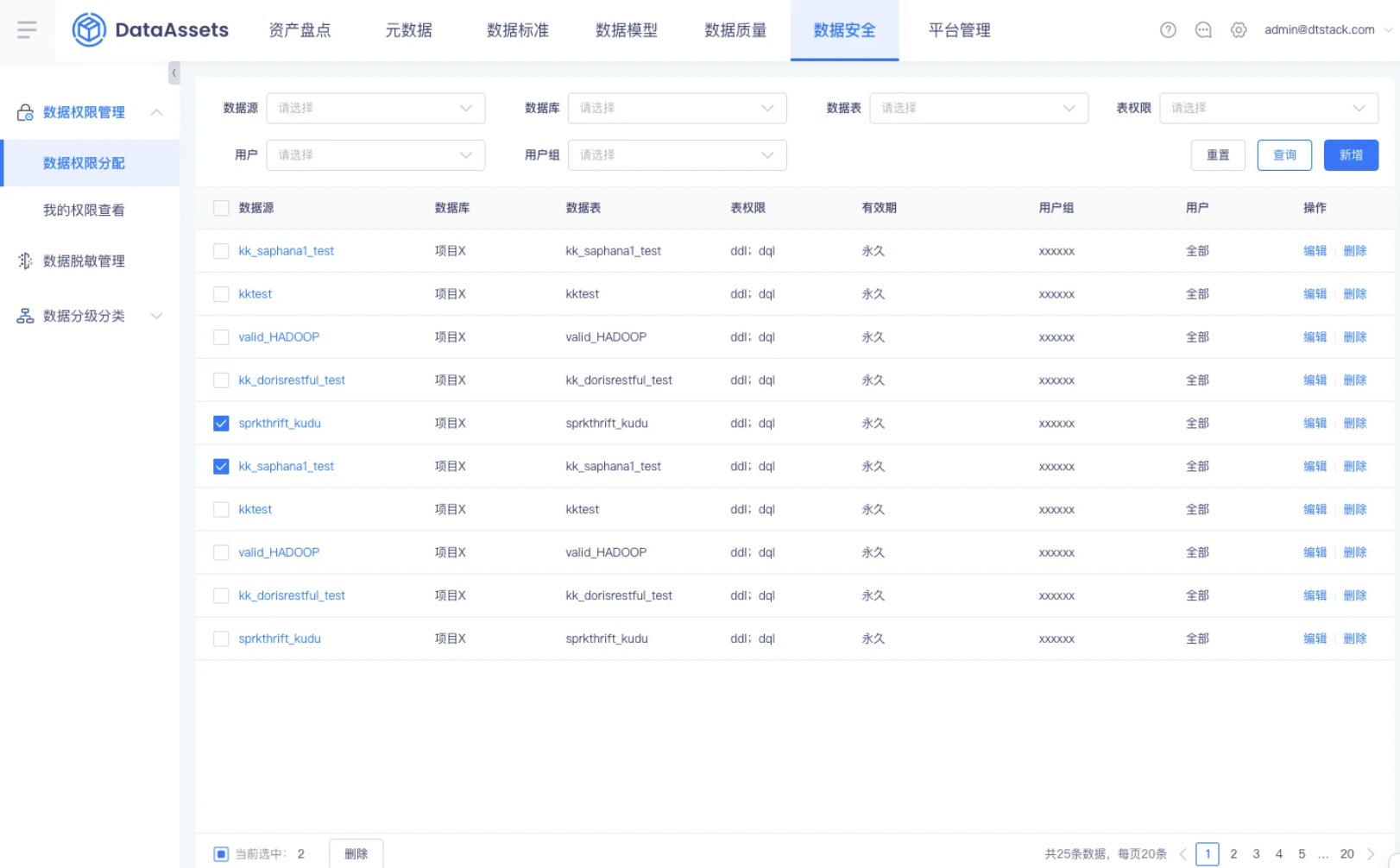
【数据资产】平台层数据权限管理,包含表级、行级、列级权限的授予与申请【上线版本:6.0】
功能:支持进行数据权限的配置,可配置数据权限范围、生效用户。支持按照库、表、行、列维度进行数据权限的配置。支持表级权限的申请(扩充行、列权限的申请),申请通过后,在权限配置的页面,自动为此用户所在的用户组,添加这条权限信息.(审批中心进行审批)
功能优化
【元数据】sparkthrift元数据同步问题处理【上线版本:5.3】
背景:sparkthrift元数据同步时若有一张表同步失败,后续表无法进行继续同步
需求:sparkthrift调整优化
【matadata】sqlparser还不支持flinksql 的create view血缘,metadata配合改造【上线版本:5.3】
需求:血缘信息展示优化
【元数据】元数据同步优化(日志优化)【上线版本:5.3】
功能内容:同步失败的表,不仅展示表名,还要展示这个表所属数据库元数据同步时,针对每个同步实例,已同步表数量、全部表数量的计算优化同步失败,查看日志时,看不出失败原因,日志目前只会打印最后一张同步失败的表的日志,没有保留全部的同步失败日志。日志在同步表记录列表中可以查看每个同步失败的表的日志
【数据质量】任务列表支持展示任务提交人、自定义sql语法校验优化【上线版本:5.3】
功能:元数据周期同步增加数据库过滤条件,新增、编辑周期任务按钮优化元数据周期同步列表,增加数据库、数据表的展示
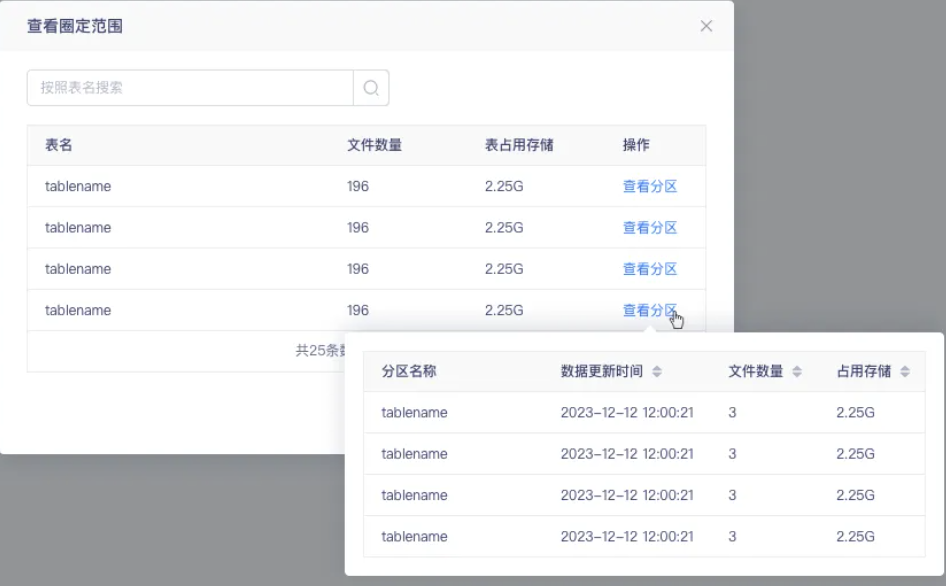
【数据治理】「小文件治理」 周期治理规则配置时展示具体每个分区的文件数量【上线版本:5.3】
背景:在进行周期治理配置的时候,配置了周期治理规则,当表数量达到规则阈值时,没有跑治理任务,问题是由于配置的周期治理规则中存在分区表,对于分区表来说,逻辑是基于分区去做治理的,而不是基于表去做治理
功能:周期治理规则的规则配置页面要进行优化,针对分区表,需要【查看分区】操作,点击展示每个分区表对应的文件数量;
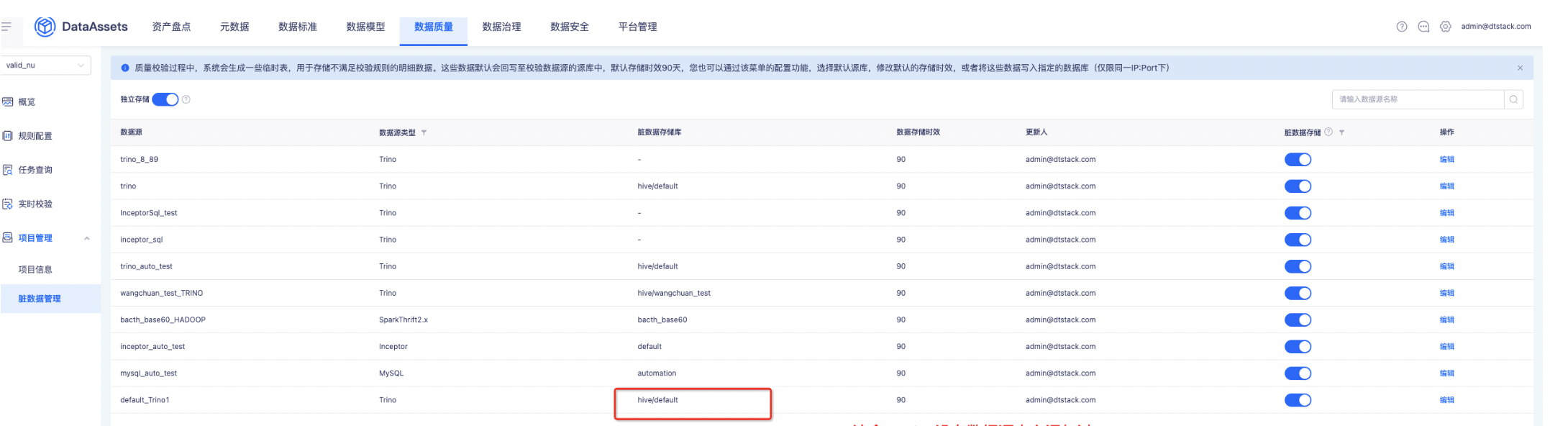
【数据质量】脏数据存储数据库只能配置数据源中心添加过的catalog【上线版本:5.3】
功能:脏数据存储数据库只能配置数据源中心添加过的catalog
【数据质量】表级报告增加显示schema、catalog字段【上线版本:6.0】
功能:对于trino数据源配置多表检验时,表级监控报告展示catalog及schema表
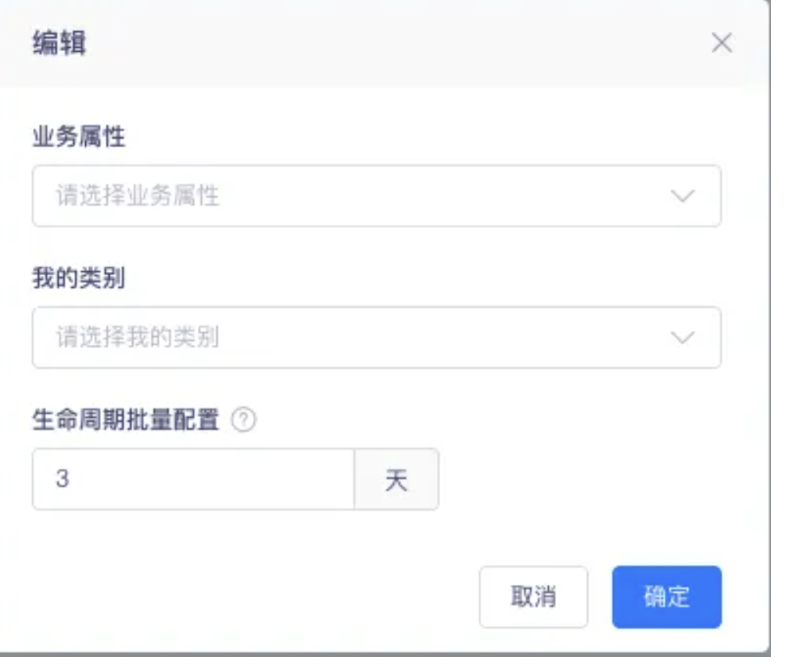
【数据质量】表生命周期支持批量设置【上线版本:6.0】
功能内容:支持批量修改表的生命周期
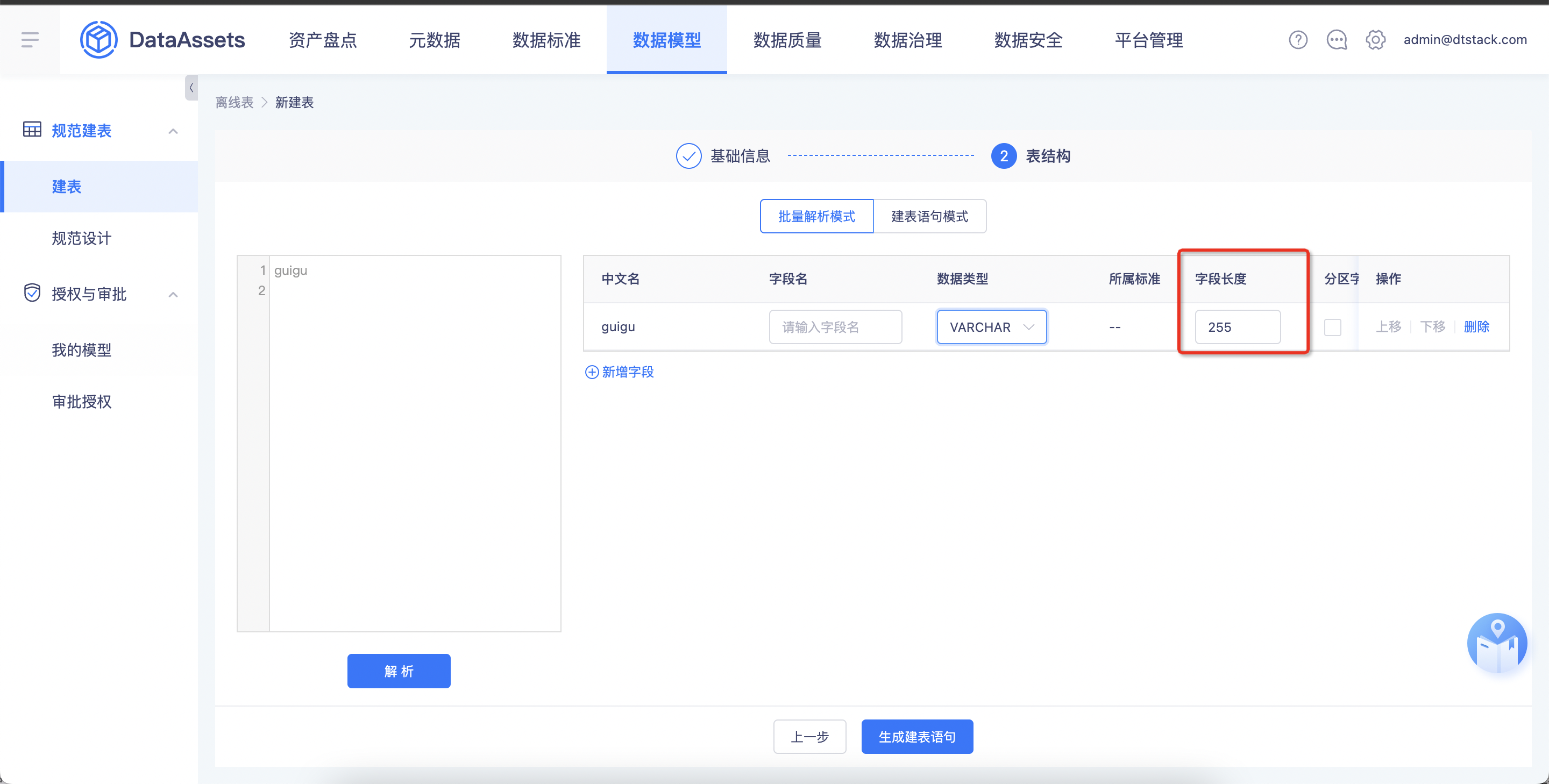
【数据模型】字段类型设置varchar支持自定义字符长度【上线版本:5.3】
功能:字段类型varchar支持自定义字符长度 .数仓层级为非必选字段,若未选择数仓层级,表名的前缀无信息
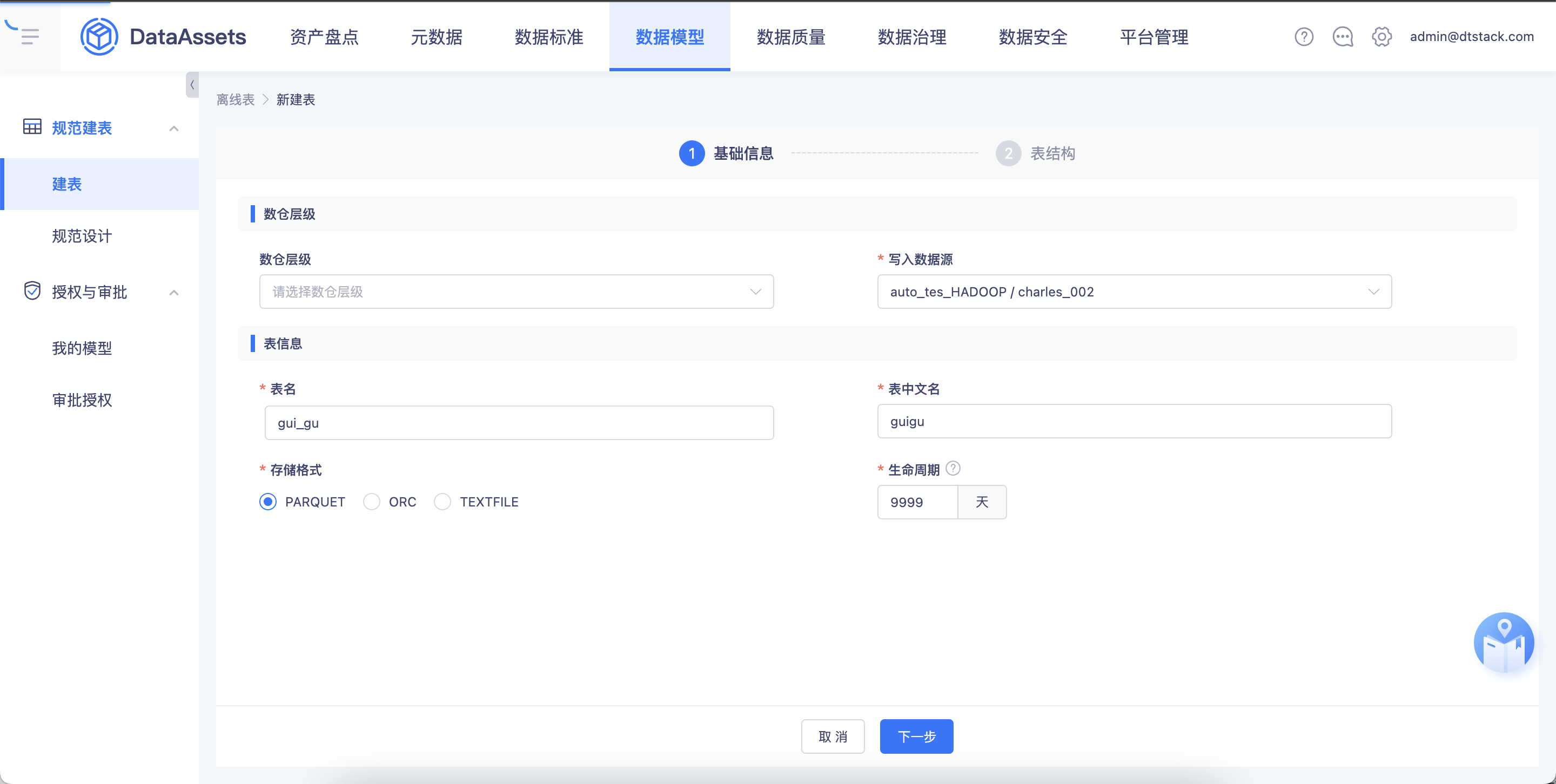
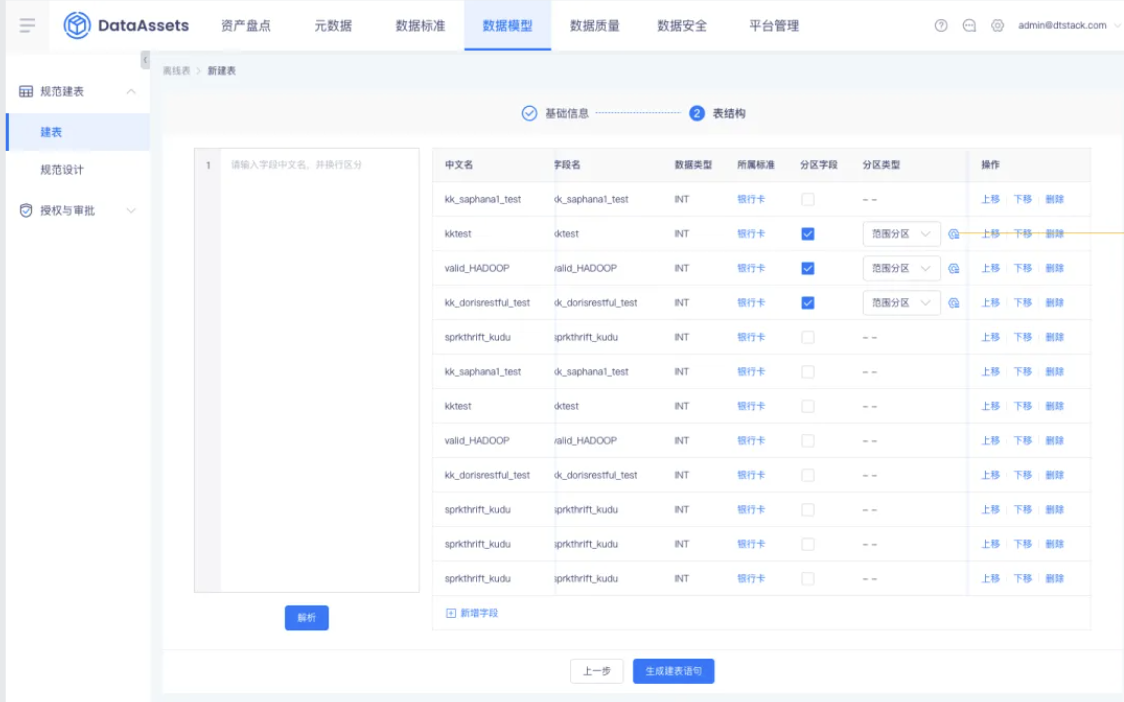
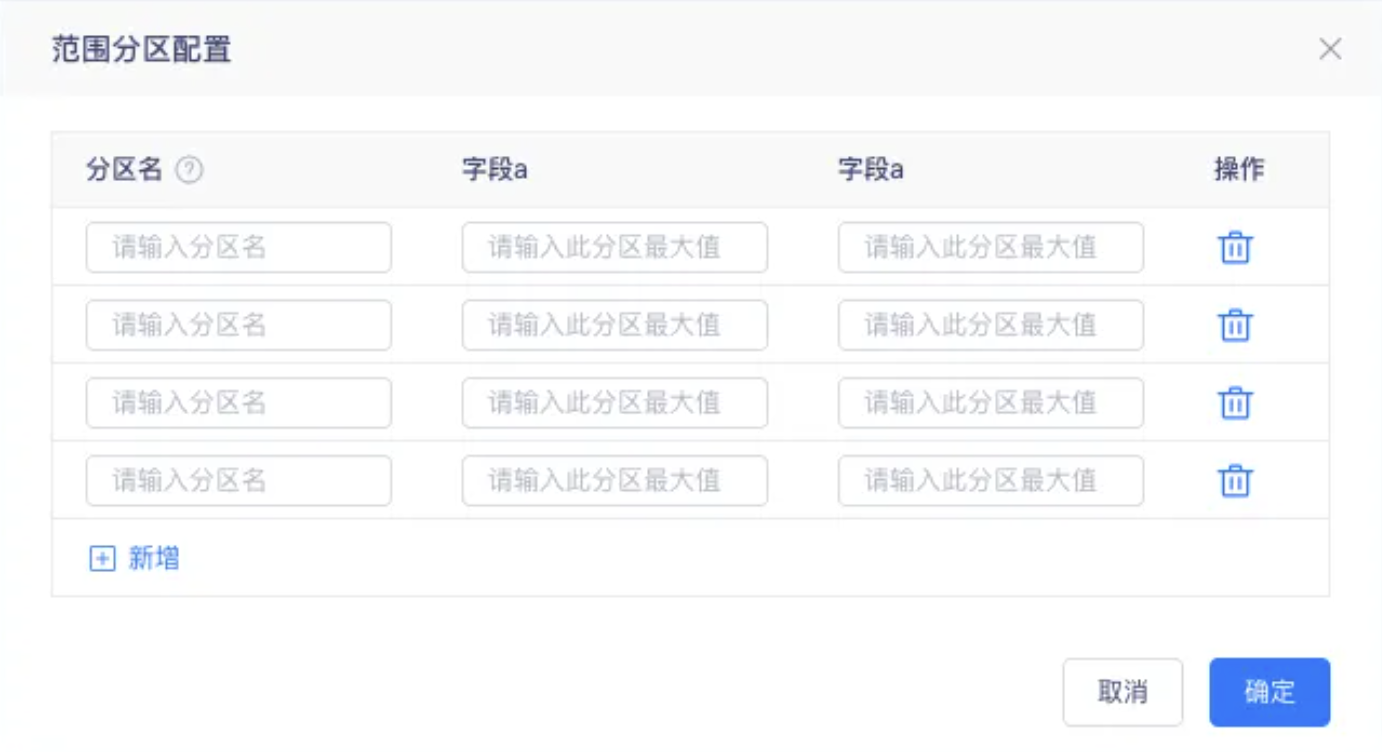
【数据模型】建表时支持配置分区范围【上线版本:5.3】
功能:性能优化,方便用户在创建时能自定义分区范围,减少操作流程,完善用户体验.
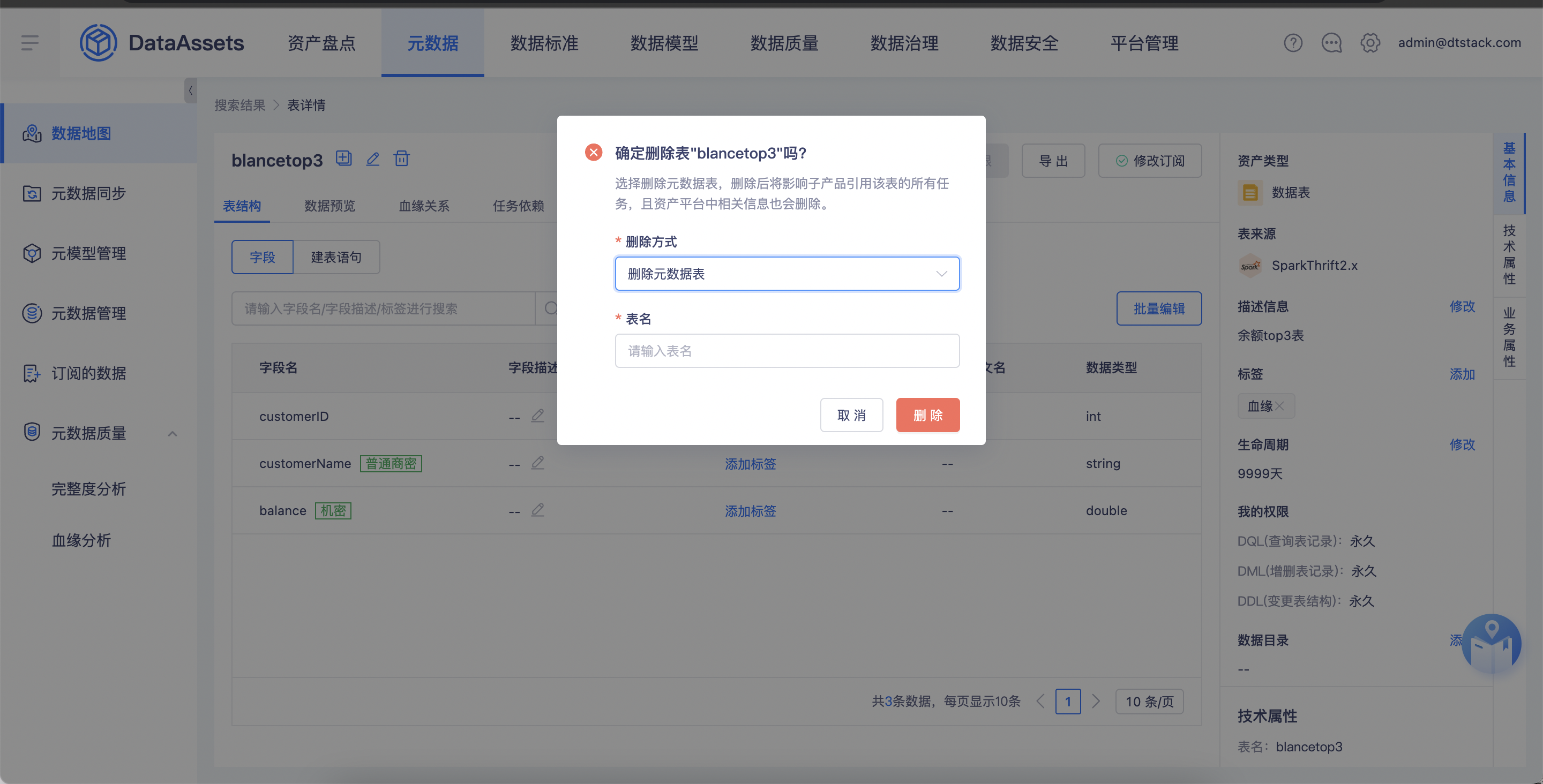
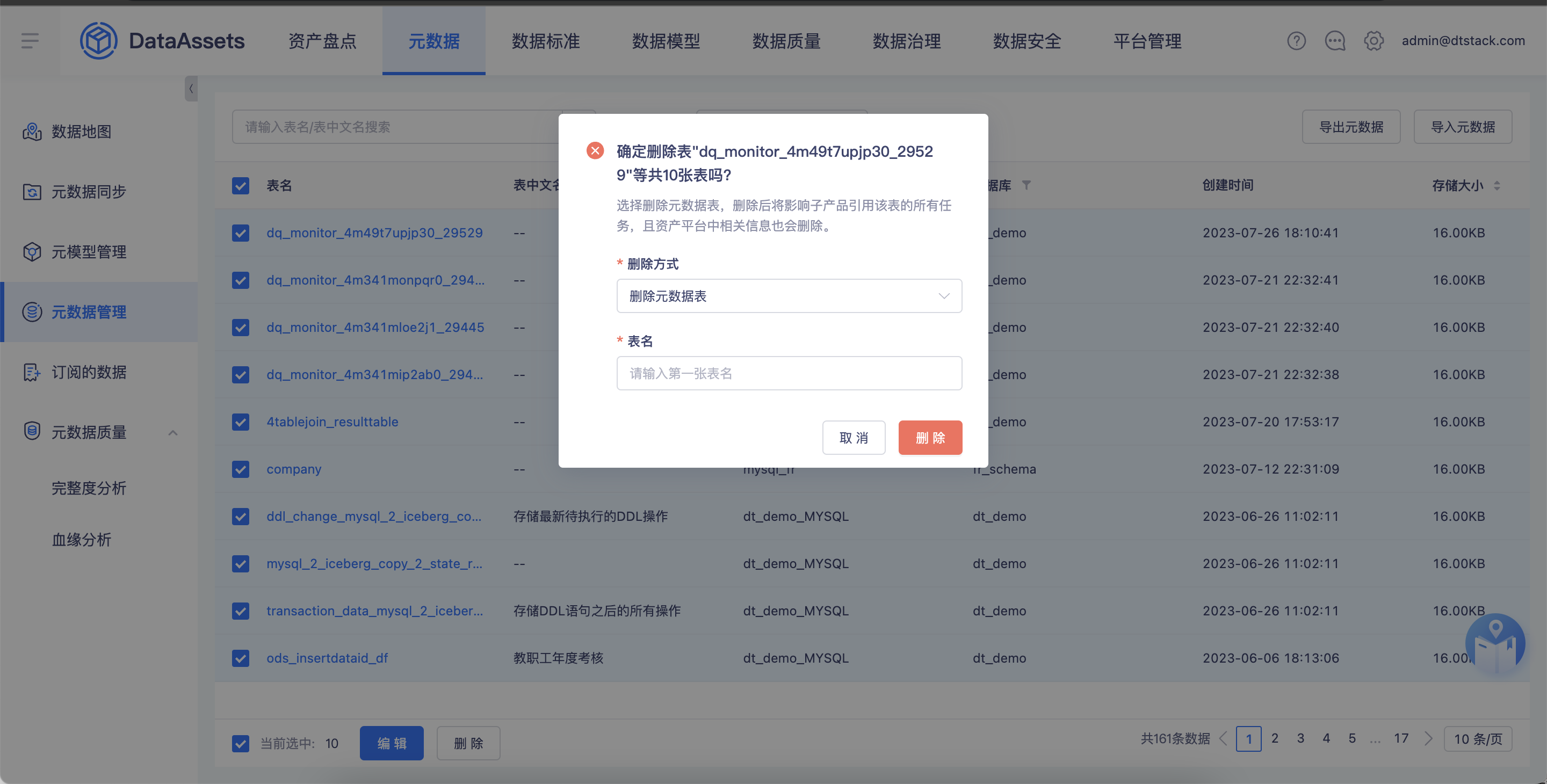
【数据模型、数据地图】表删除逻辑优化【上线版本:5.3】
背景:优化之前数据地图不可删除多余同步表的问题,支持批量删除
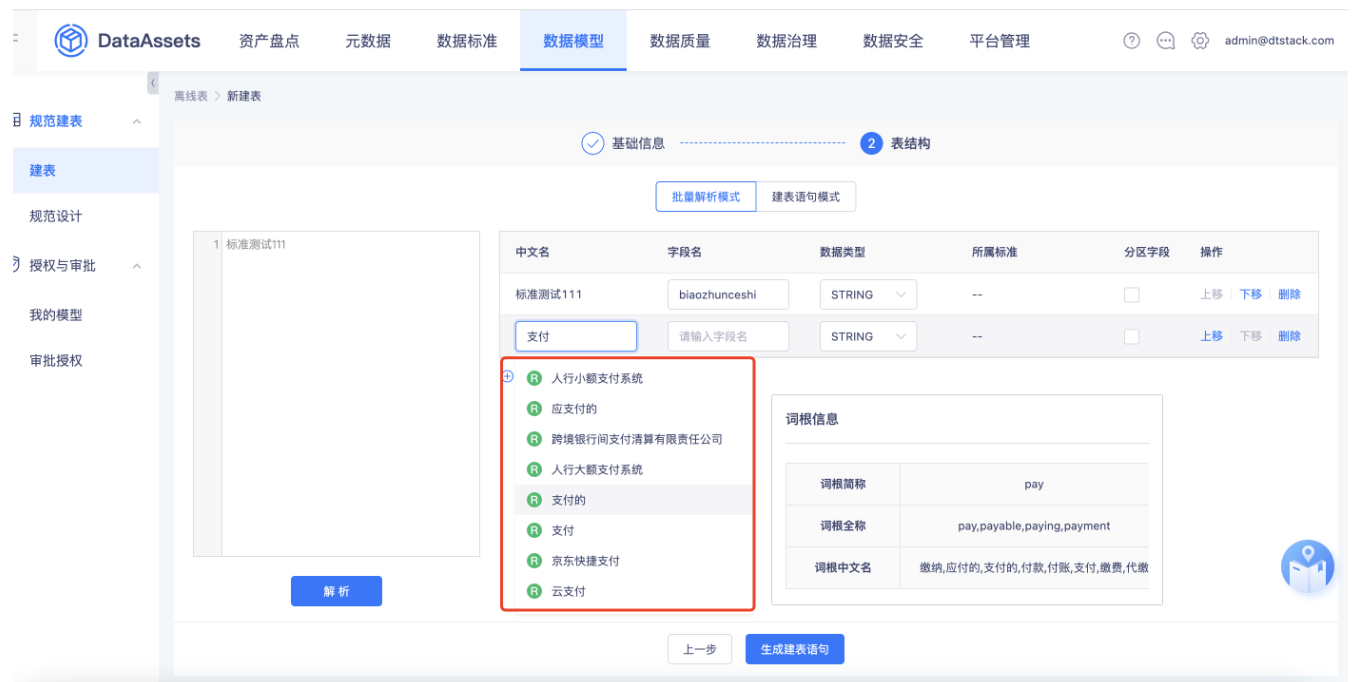
【数据标准】标准映射逻辑优化【上线版本:5.3】
匹配逻辑优化:
- 根据标准获取到对应的标准英文名称、英文缩写,并按照下划线 "" 进行切分得到一个词组,将标准对应的英文名称按照 "" 切分后得到的词进行词根匹配,将匹配到的词根的简称和全称放入最终的词组中。举例:【loan_amt】数据标准,分词后得到{loan,amt}。然后在「词根管理」中查到【loan-loan】、【amt-amount】,最后得到的集合A={loan,amt,amount}。
- 如果表字段包含 "",则按照 ""对字段进行切分,如果不包含则按照驼峰命名的形式进行切分,得到切分后的词组,如果上一步骤得到的词组集合A中包含字段切分后的词(忽略大小写),则算匹配成功。
数据资产针对所有的子产品都要支持meta数据源的自动引入【上线版本:6.0】
功能:产针对所有的子产品(离线、指标、标签)都要支持meta数据源的自动引入,针对指标、标签,需要支持指标标签生成的trino类型meta数据源的自动引入
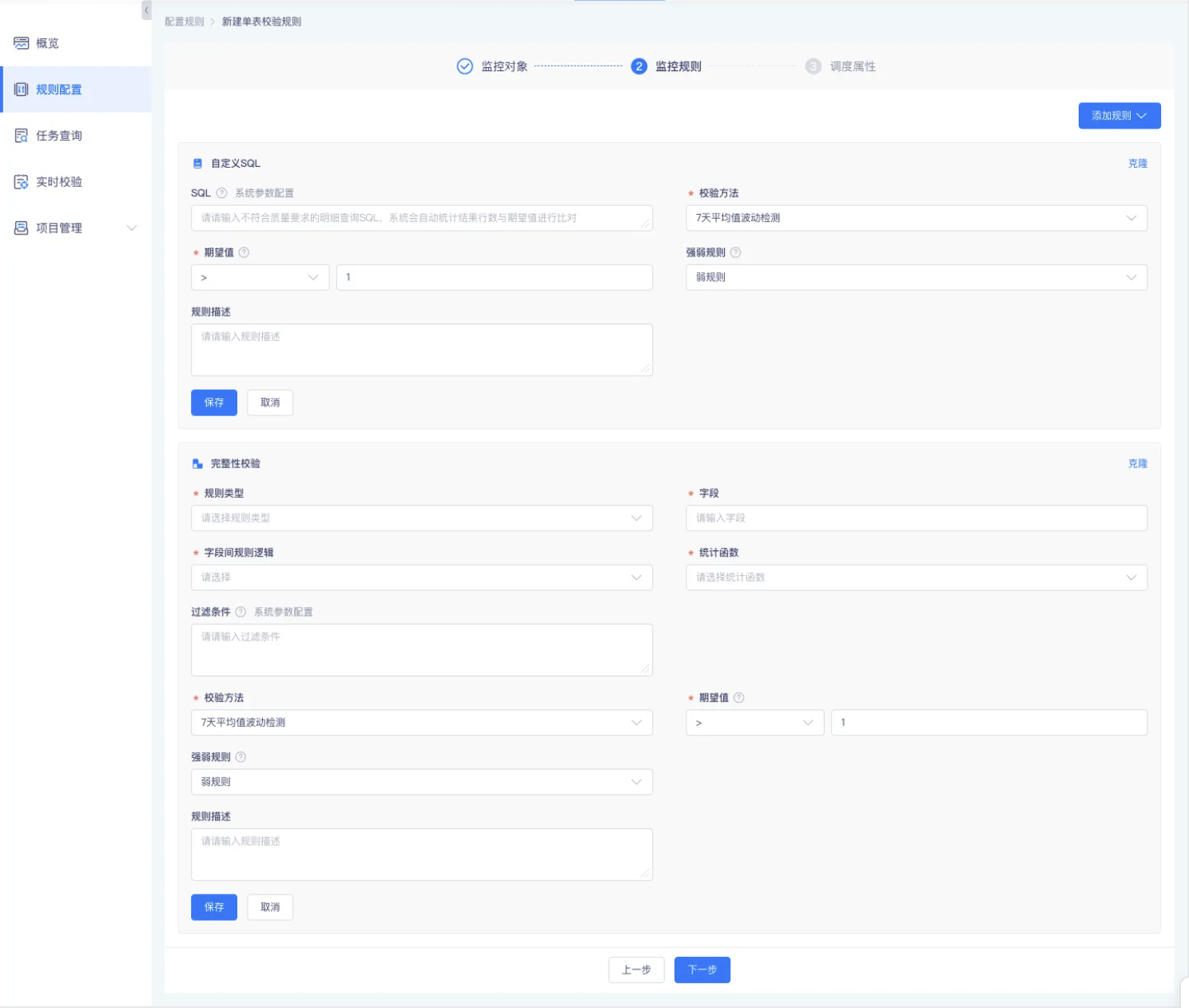
针对单表每个字段可以批量生成校验规则【上线版本:5.3】
背景: 数据质量管理模块,可以批量配置规则。举例:表A有a,b,c,d4个字段,要检查空值率或者零值率,支持字段多选,并配置相应规则。目前现状:选择a,b字段,选择空值率。检查逻辑是 a is not null and b is not null。
功能:增加or或and筛选框,支持用户配置检验规则,新增效果检验规则选择a,b字段,选择空值率。生成规则1:检查逻辑是 a is not null;生成规则2:检查逻辑是 b is not null;
BUGFIX
【数据标准】概览页面实时更新【上线版本:5.2】
背景:迭代遗留BUG修复,逻辑优化
功能:元数据实现实时更新,当所存储的数据更新时,页面跟随数据一起同步
可定义资产概览中展示的默认数据源【上线版本:5.3】
背景:中山大学不关注MySQL数据源的情况,关注的是spark数据源的情况,因此需要将默认值修改.
功能:默认展示的数据源,展示数据源(按照数据源、数据库、数据表数量排序)最多的数据源类型,例如如果用户spark数据源下面的数据源数量最多,默认的就展示spark类型,涉及到的展示模块包含资产盘点页面以及元数据管理页面
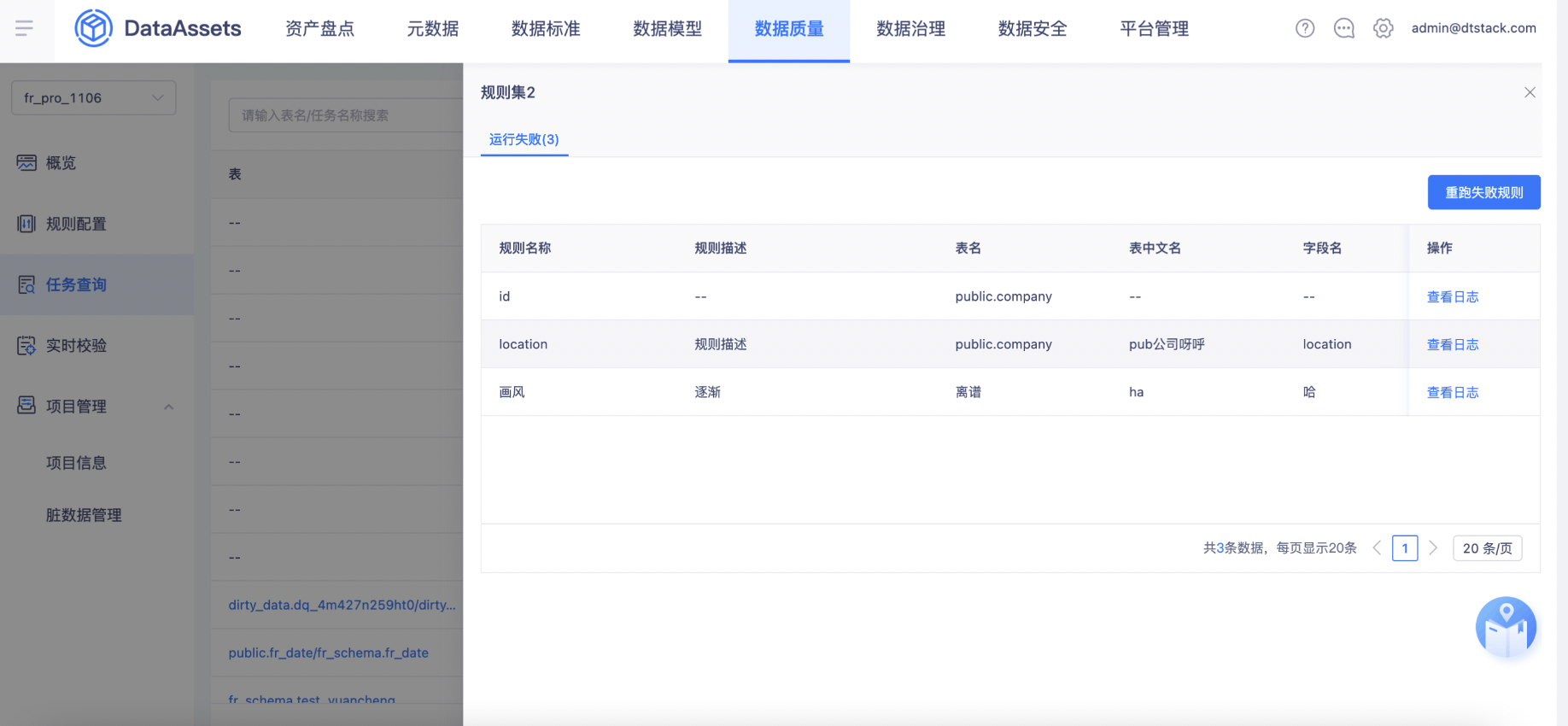
【数据质量】规则集修改之后「任务查询」中历史运行详情被修改【上线版本:5.3】
背景:bug转化而来,规则集修改后,查询该规则集修改前的历史运行详情,详情内容被修改。
功能:现有的设计逻辑是新建规则会覆盖掉历史运行的规则记录,需要调整下这个逻辑,每运行一次规则集,都需要保存这一次所对应的规则,不能让新的规则覆盖掉历史运行的规则,否则查看历史的运行详情,内容就会被修改掉。