5.3.2更新日志
上线时间:2023-01-04
血缘问题优化【实现全链路血缘前提】
冗余血缘移除:
- 【背景】:当前现状当存在血缘关系时,会生成两条血缘关系,此问题需要解决,否则全链路会产生非常多的冗余血缘
- 【需求】:只展示一条血缘
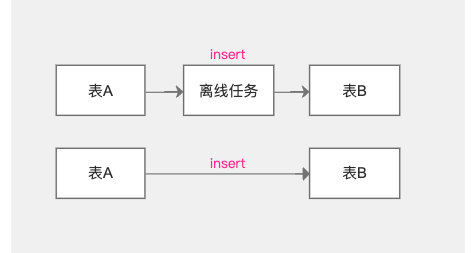
关键字支持-现状说明:
- 当表发生delete、drop、trancate数据清空时,表与表之间、表与任务之间的血缘关系删除
- 当任务下线、删除时,表与表之间血缘依旧存在,表与任务之间的血缘关系删除
【保留表与表之间流向原因】:原来的数据流向依旧存在
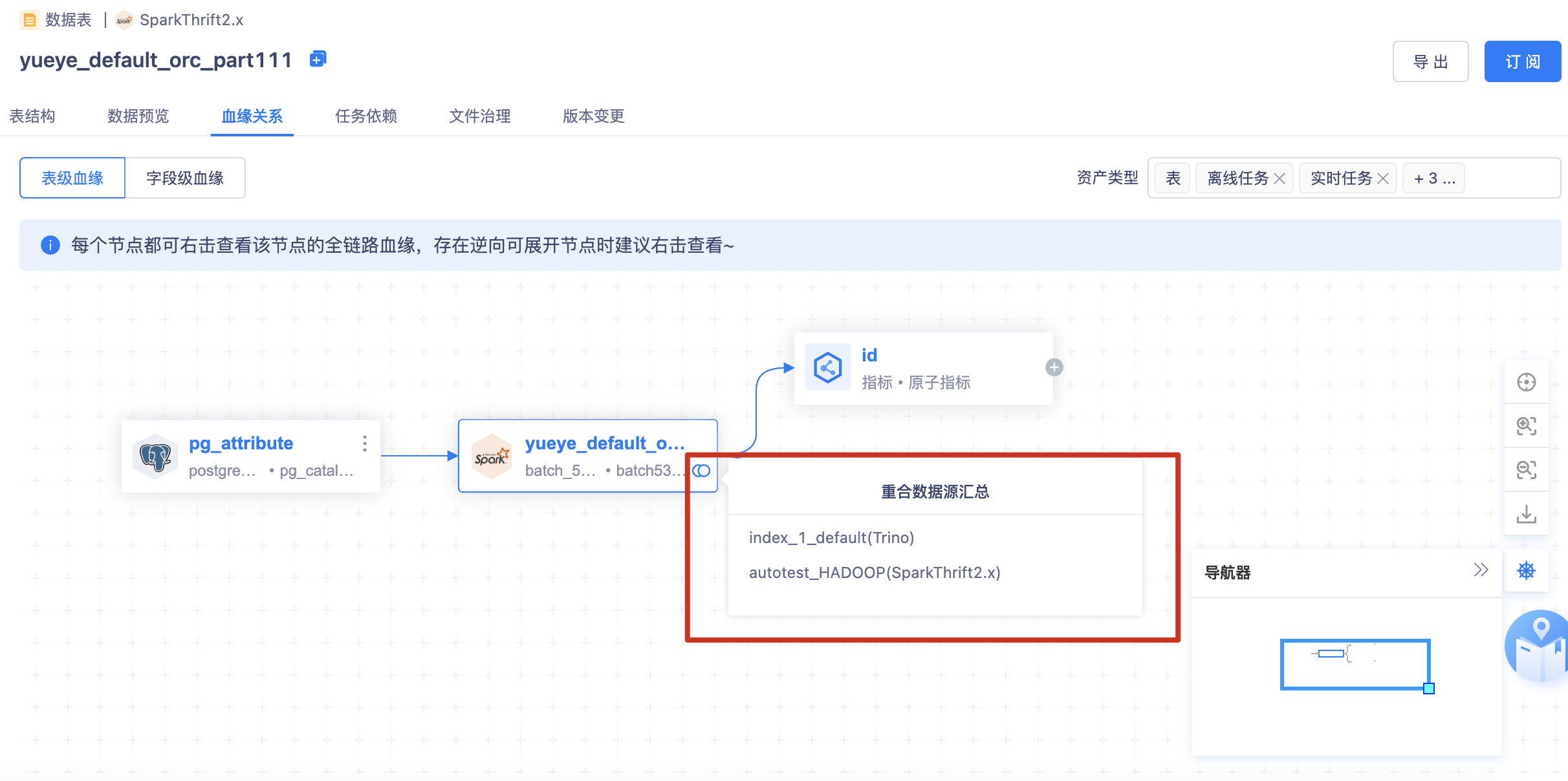
重合数据源:
- 【背景】:标签指标对接的是trino引擎,离线对接的是sparkthrift,如果不解决唯一性问题,无法串联全链路血缘
- 【需求】:不同链路间的血缘不相互影响,但是汇总成同一链路展示
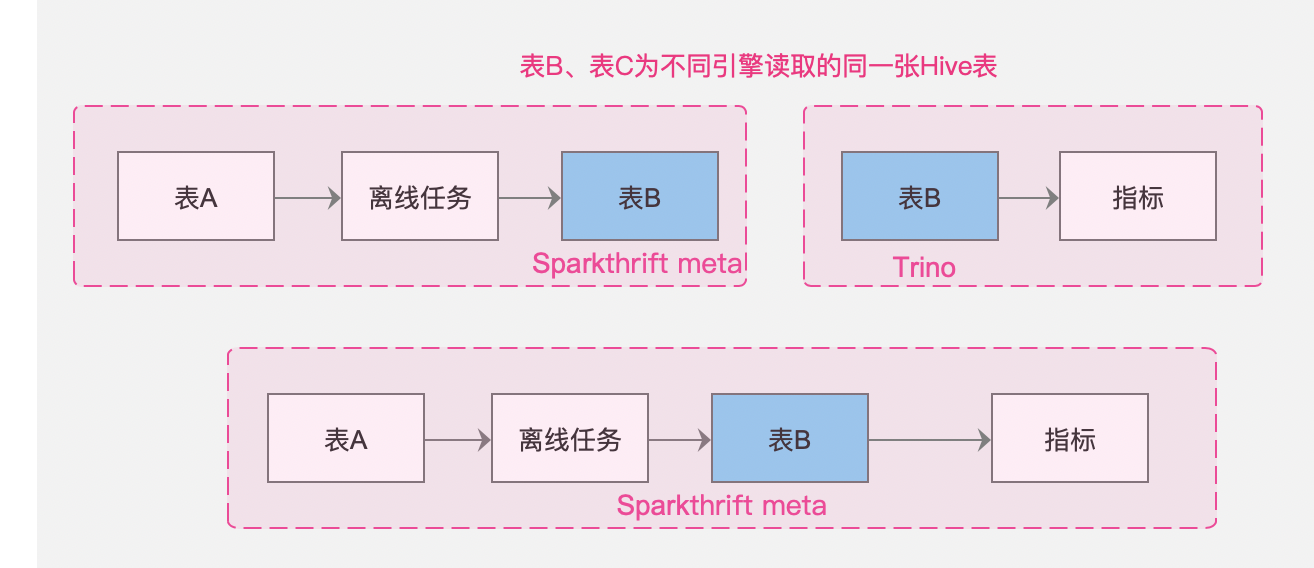
【数据源唯一性区分(IP、port及特殊处理)】解决的问题:
不同的引擎读取同一张控制台的hive表(如sparkthrift、trino)
- 数据源中心建立的不同的数据源,其实是同一个数据库
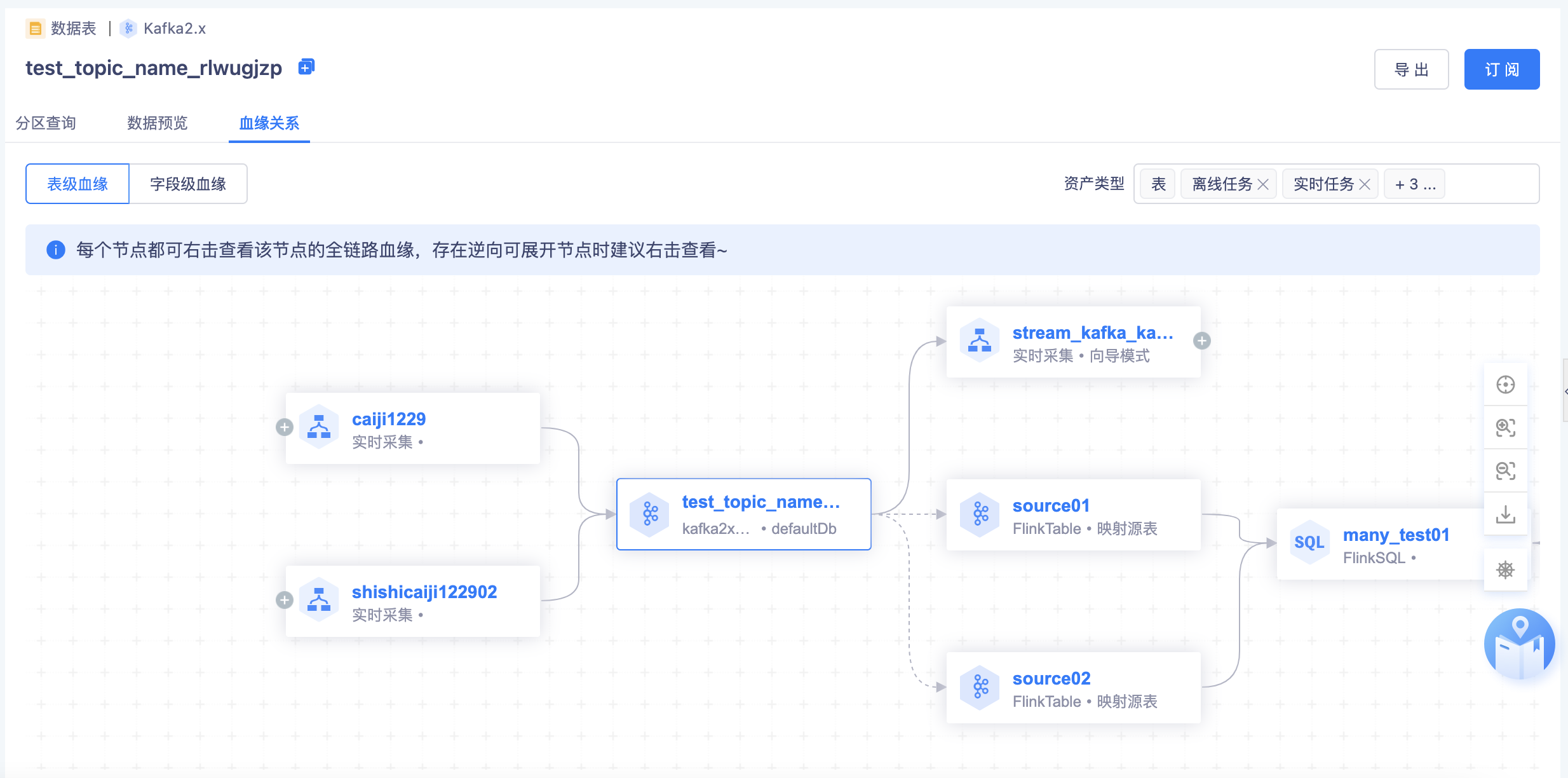
全链路血缘
【现状】:已实现了表、离线任务、API维度的血缘链路,指标、标签平台现有平台内的血缘已迁移过来
【本期】:打通了表→标签、表→指标、实时任务
【整体说明】:数据资产平台已初步实现数栈内部全链路血缘关系的打通,包括表、实时任务、离线任务、API、指标、标签(部分细节后期优化)
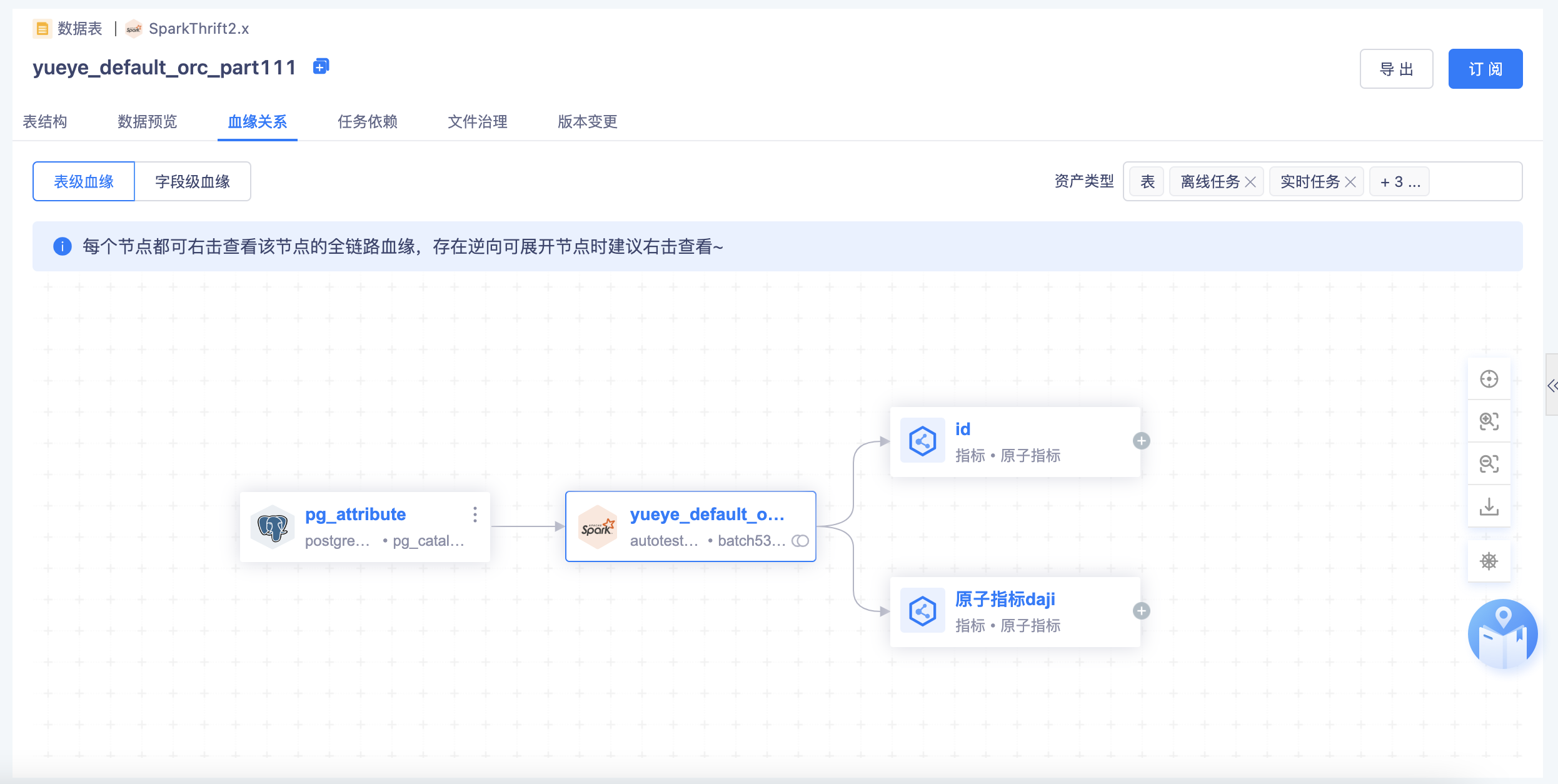
表→指标:
- 根据指标平台的【指标的生成】记录【表→指标】之间的血缘关系
- 指标的生成包括【向导模式】、【脚本模式】
- 指标平台如果有变动,比如删除、下线了某个指标,资产平台需要更新血缘视图
- 支持指标的字段血缘解析
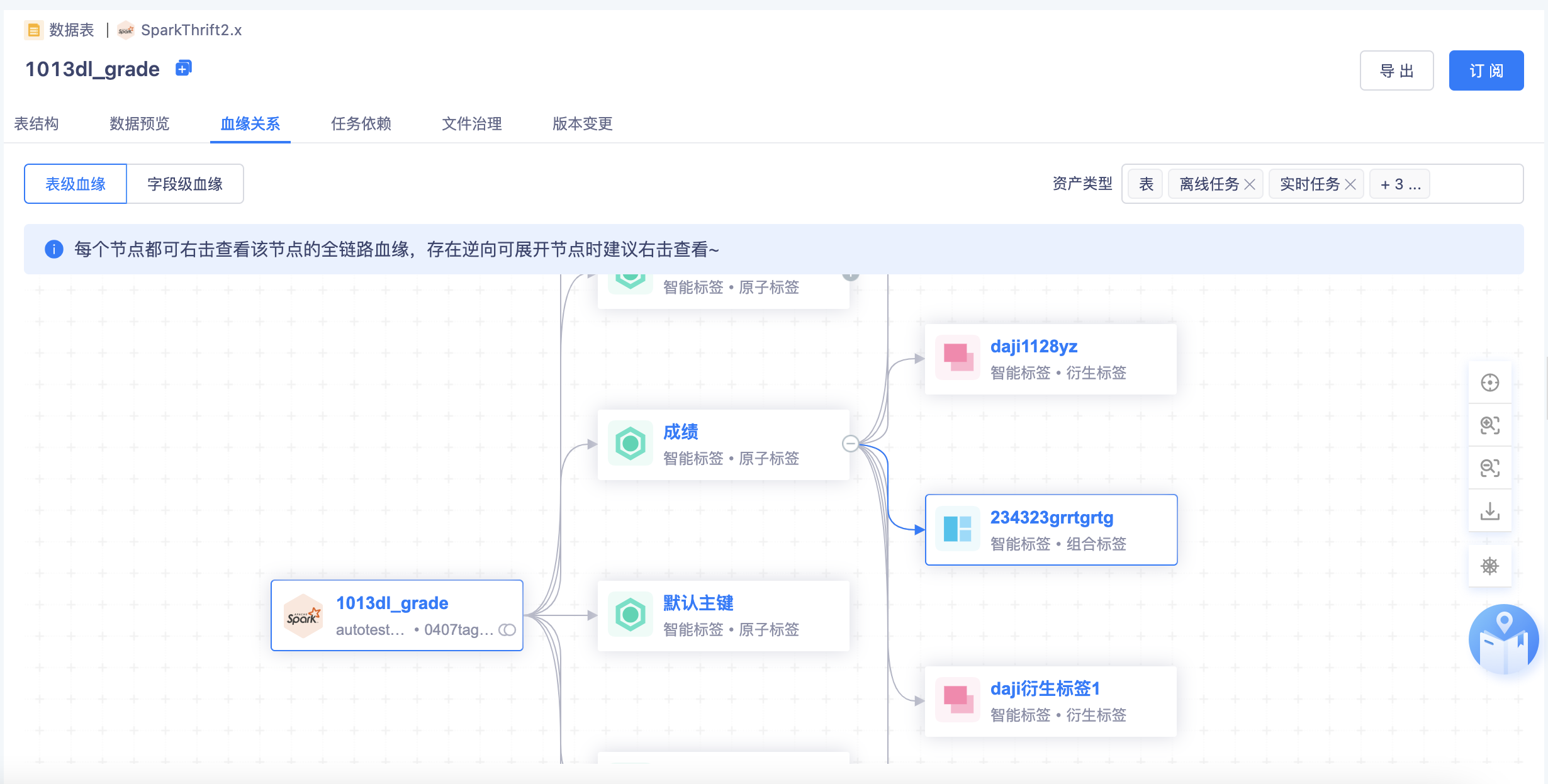
表→标签:
- 根据标签平台的【标签的生成】记录【表→标签】之间的血缘关系
- 标签通过实体和关系模型创建,实体中需要关联主表和辅表,关系模型中有事实表和维表,并且关系模型可存储为实际的物理表,因此血缘链路包括数据表、标签。
- 标签的生成包括【向导模式】和【脚本模式】
- 标签平台如果有变动,比如删除、下线了某个标签,资产平台需要更新血缘视图
- 支持标签的字段血缘解析
实时任务:
- 任务类型有两种:实时采集任务和FlinkSQL任务,FlinkSQL任务存在字段血缘关系
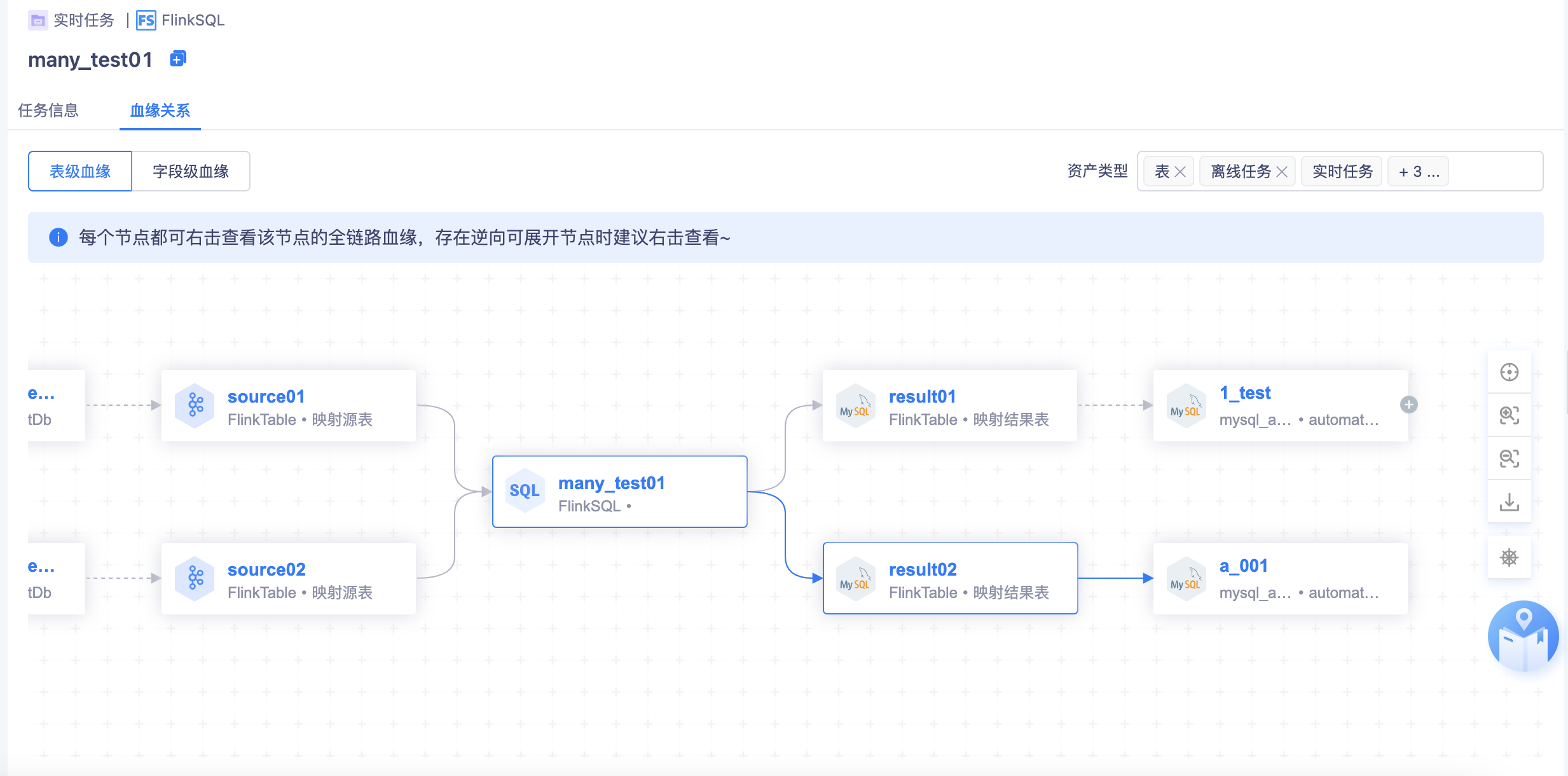
- 支持kafka侧的血缘关系展示
血缘展示优化
右上角筛选项:
- 优化为多选菜单,表、离线任务、实时任务、API、标签、指标(默认选中全部维度,当前进入的维度选中且不可取消)
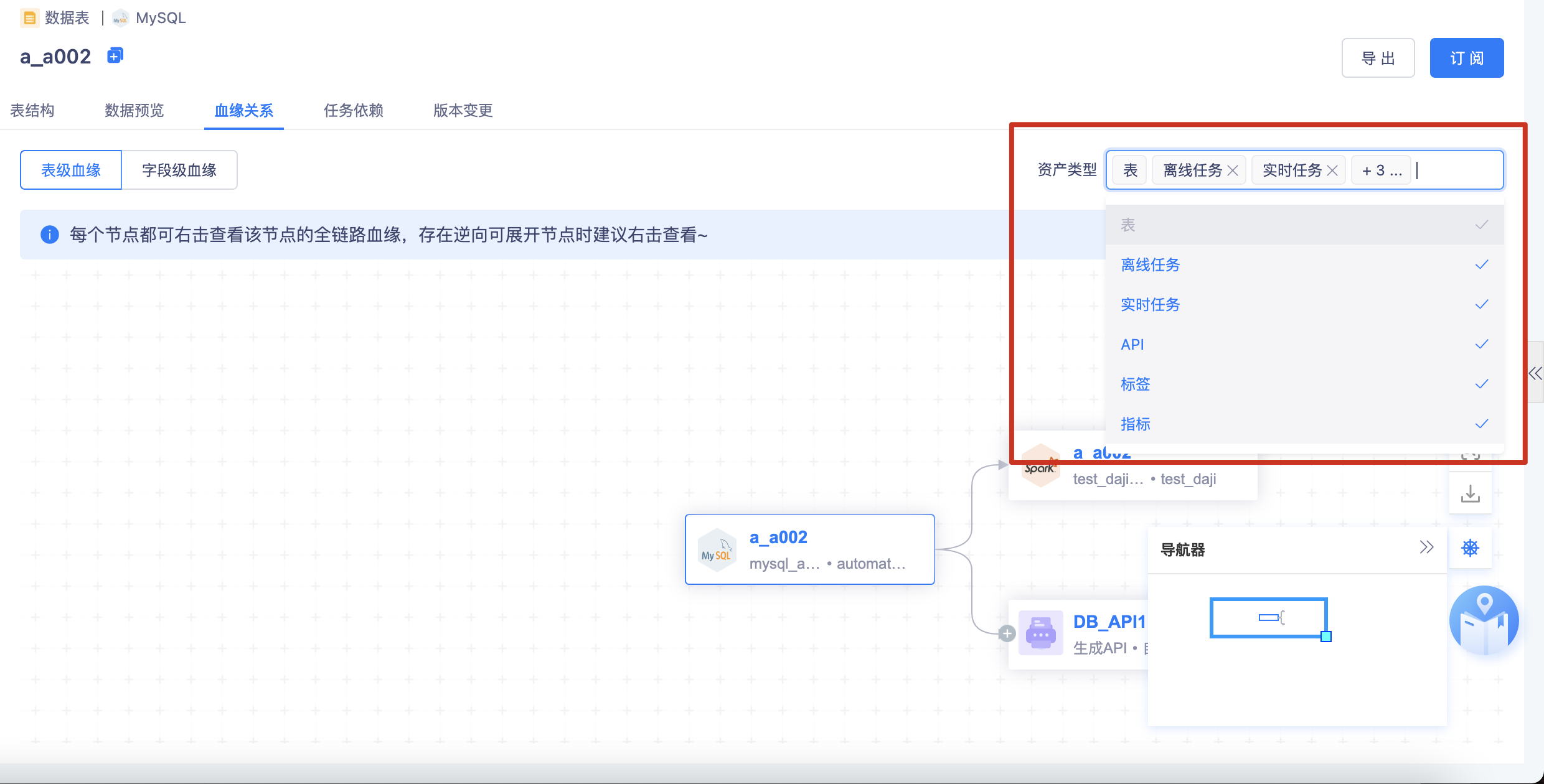
字段血缘:不展示右上角的筛选项
逆向血缘全局提示:
- 进入血缘关系页面,进行全局提示:“进入血缘每个节点都可右击查看该节点的全链路血缘,存在逆向可展开节点时建议右击查看~”
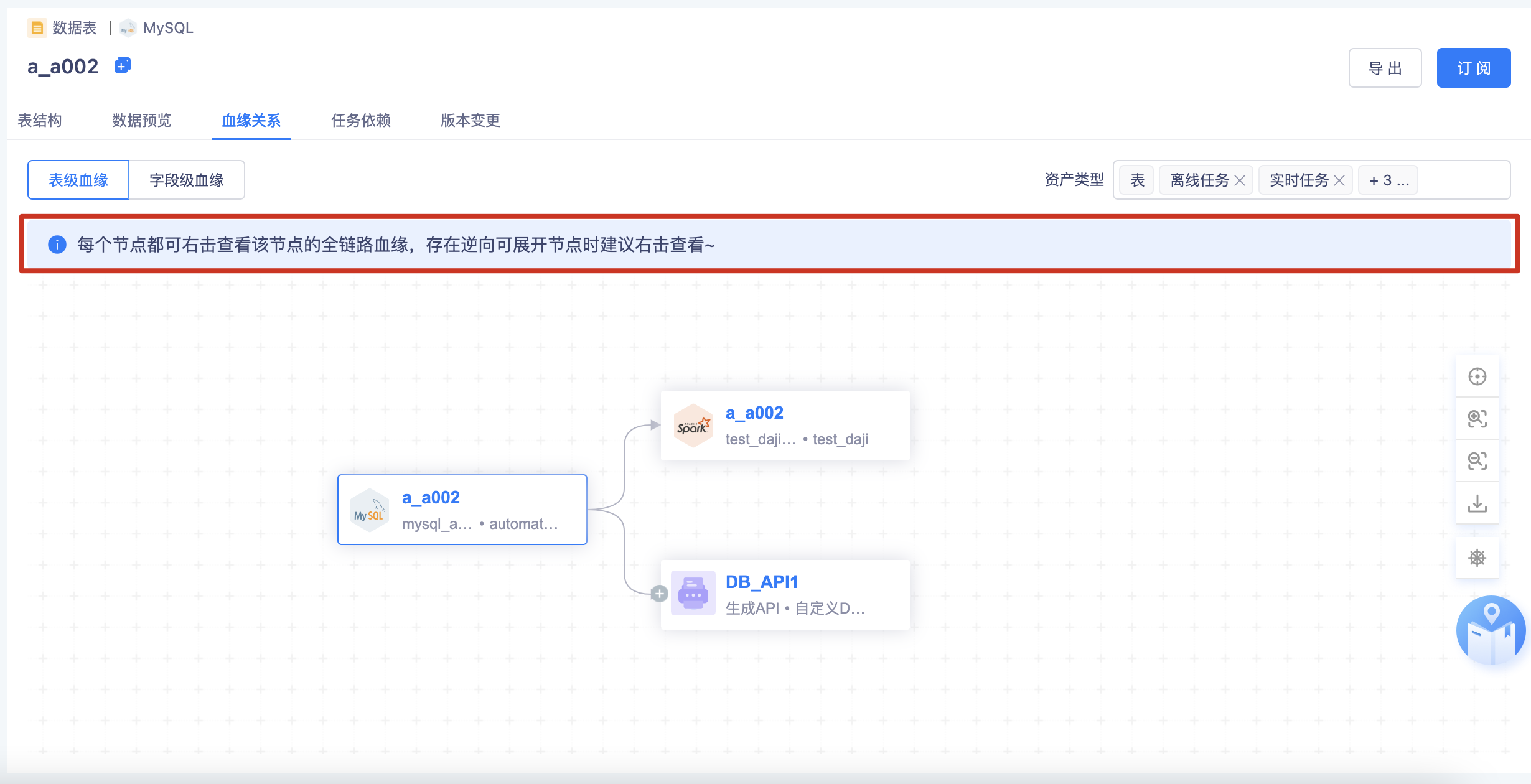
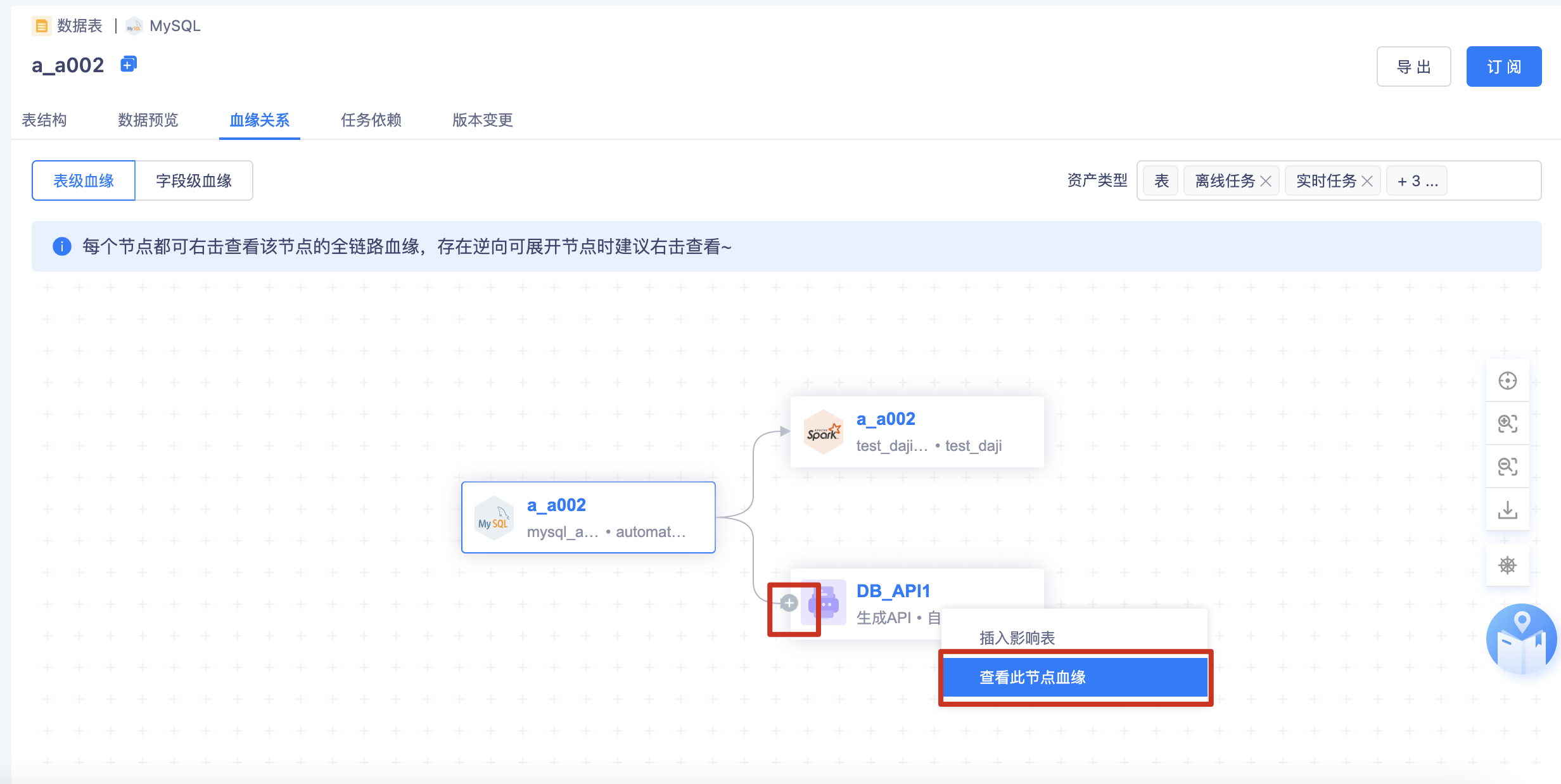
- 右击查看当前节点的血缘会更完整
离线数据地图迁移
- 【目标】:未来会全部迁移到数据资产平台,因此资产侧数据地图需要兼容离线侧数据地图的全部功能
- 【本期】:完成AnalyticDB PostgreSQL的元数据接入+自动授权
license收敛
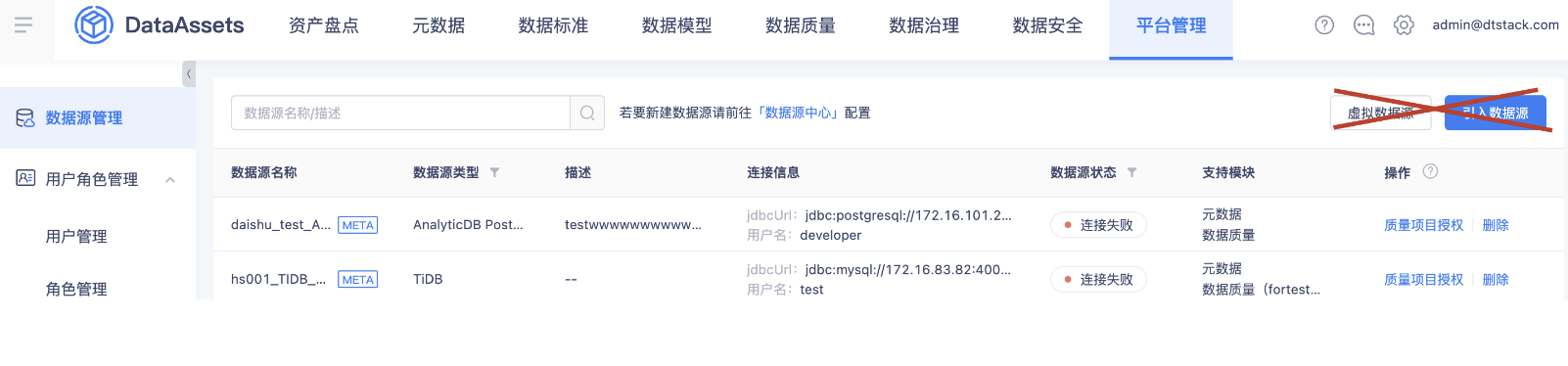
经过慎重考虑,为强化数据资产的产品定位,丰富产品核心功能,现决定从5.3版本开始收敛【引入外部数据源】功能,未来新客户购买资产后,默认没有【引入外部数据源】功能,只管理数栈内部的数据资产。招标参数已修改:https://dtstack.yuque.com/pd2/promotion_lib/eeva32#752b
💡 产品定位:聚焦在数栈内部资产管理。不再是客户侧全部数据资产的管理(范围广、难复用、资产管理价值低、客户定制需求多),数栈内部资产包含表(子产品计算引擎对接的数据源,如hive、sparkthrift等相关的meta数据源)、标签、指标、API等,不涵盖外部接入的数据源(之前也只能做元数据采集)。
因此,未来不会再承接数栈外部的数据源接入,专注于数栈内的资产管理。
资产取消【引入数据源】功能如图所示:
从5.3版本开始,分三类客户升级和部署,部署方案如下:
- 【资产质量合并部署&升级】:「适用于已经部署过资产和质量两款产品的老客户升级,或者购买5.3及更新版本的新客户部署」。
💡 默认以该方案部署,原有承诺的功能不受影响,拥有合并后平台所有功能,默认无【引入外部数据源功能】,老客户允许勾选【接入外部数据源功能】

- 【资产升级】:「适用于仅部署过资产的老客户升级」
💡 原有承诺的功能不受影响,无合并后的【数据质量】模块。默认勾选【引入外部数据源功能】,可取消

- 【质量升级】:「适用于仅部署过质量的老客户升级」,「功能模块」默认只有数据质量、平台管理
💡 原有承诺的功能不受影响,无合并后的【数据资产】相关模块,允许接入外部数据源。默认勾选【引入外部数据源功能】,可取消

DatasourceX优化
【存储】、【表行数】逻辑优化:
- 背景:直接从metastore读取是不准确的,之前flinkx是支持通过脚本更新存储和表行数,flinkx升成datasourcex之后,相关analyze逻辑没有带过来
- datasourcex优化了对部分数据源的【存储】、【表行数】的脚本统计,包括hive1.x、2.x、3.x(cdp/apache)、sparkthrift、impala、inceptor
- 注意影响:更新【存储大小】【文件数量】逻辑
【存储大小】【文件数量】更新逻辑优化:
- 背景:数据治理新增了meta数据源的文件数量,又因为文件数量这个属性是datasourcex支持,普通的数据源也需要新增这个属性
- datasourcex对部分数据源的【存储大小】【文件数量】的脚本统计,数据治理结束后,更新【存储大小】【文件数量】逻辑
前端页面升级
- 资产盘点
- 元数据标签页面
- 元模型管理

- 分区优化