5.3.0&5.3.1更新日志
上线时间:2022-11-03&2022-11-24
数据源
新增数据源支持
- Greenplum、DB2、PostgreSQL(V5.3.0)
- Hive3.x(Apache)、Hive3.x(CDP)、TDSQL、StarRocks(V5.3.1)
Meta数据源自动授权支持:
- Hive3.x(Apache)、Hive3.x(CDP)(V5.3.0)
- TiDB(V5.3.1)
本期对Meta数据源的库表同步进行了优化(V5.3.1):
- 数据库-同步当前这个数据源对应的库
- 数据表-同步当前这个数据源对应库下的所有数据表
数据地图(V5.3.1)
【新增指标】指标进数据地图,作为资产平台的一类资产
【kafka元数据优化】:Kafka隐藏表结构,新增分区查询tab。
【原因】Kafka topic的每条数据的字段不一致,无法通过表结构合理展示字段信息。
筛选优化
「标签筛选优化」:标签采集到的任务,之前没有根据实体进行区分,会出现标签名称相同的情况。本期为标签添加「所属实体」属性并在快速筛选栏增加实体筛选。
「表标签优化」:
表维度进入时,显示「表标签」,其他维度显示「标签」。【原因】防止用户对表和字段打的标签混淆。
- 各个维度打的标签相互隔离,从不同维度进入时,不再能看到全部标签。【举例】从离线任务维度进入时,现在只能看到给离线任务打的标签。
数栈内部全链路血缘(V5.3.1)
API血缘
- 实现了表到API、API到API的血缘链路打通。
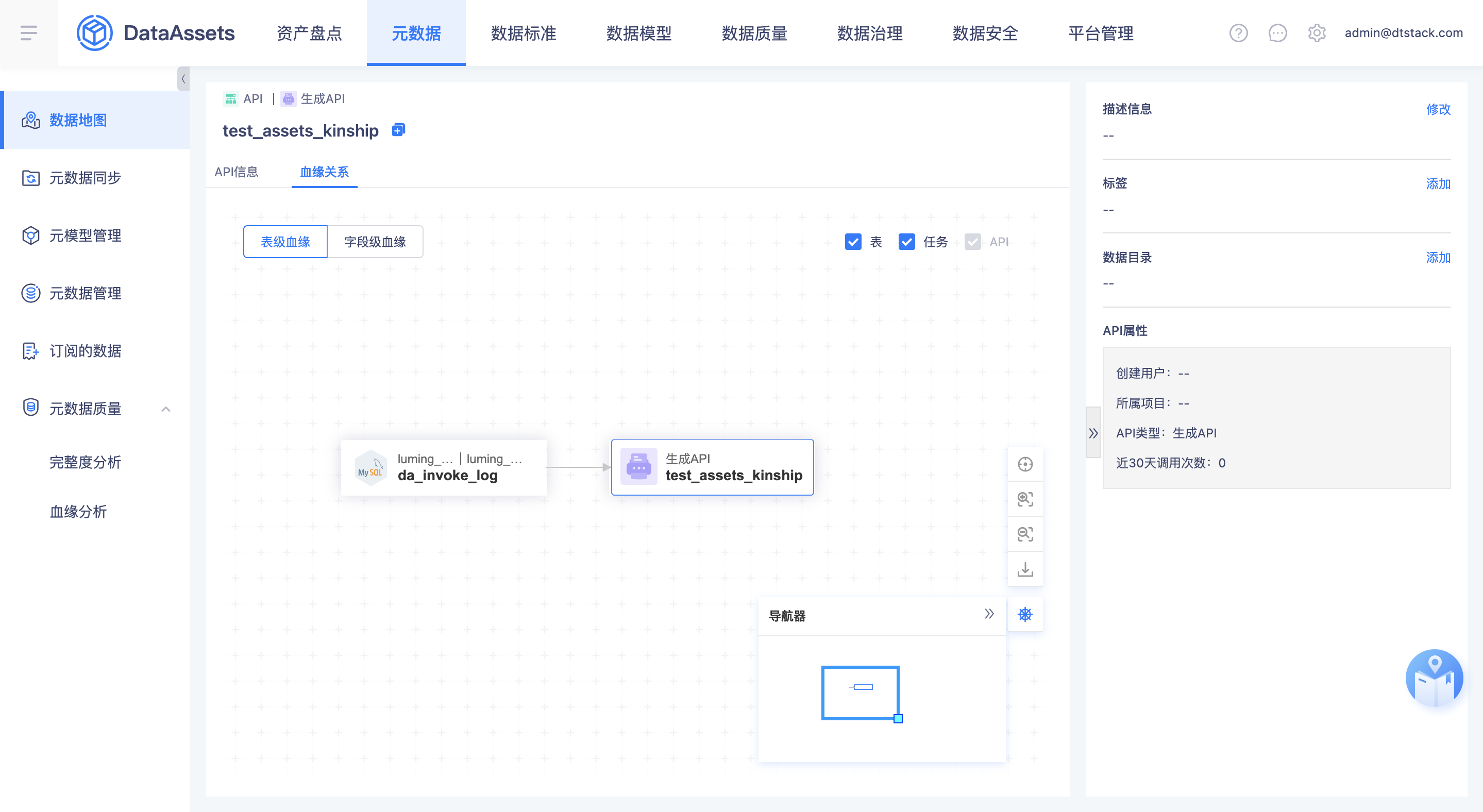
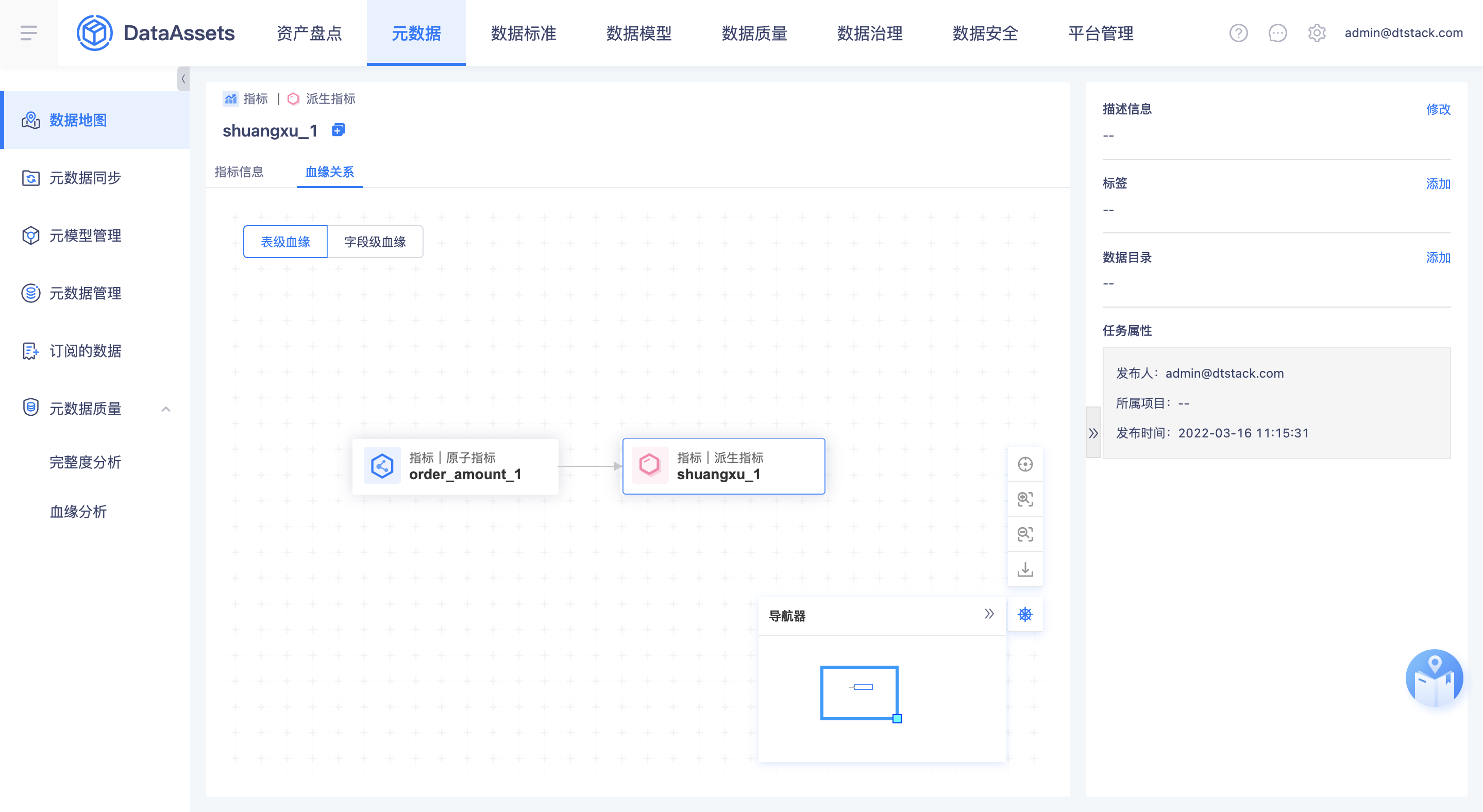
指标/标签血缘
- 本期把指标标签内部的血缘关系先拿到资产进行展示,下一期会实现表到指标、表到标签的血缘关系。
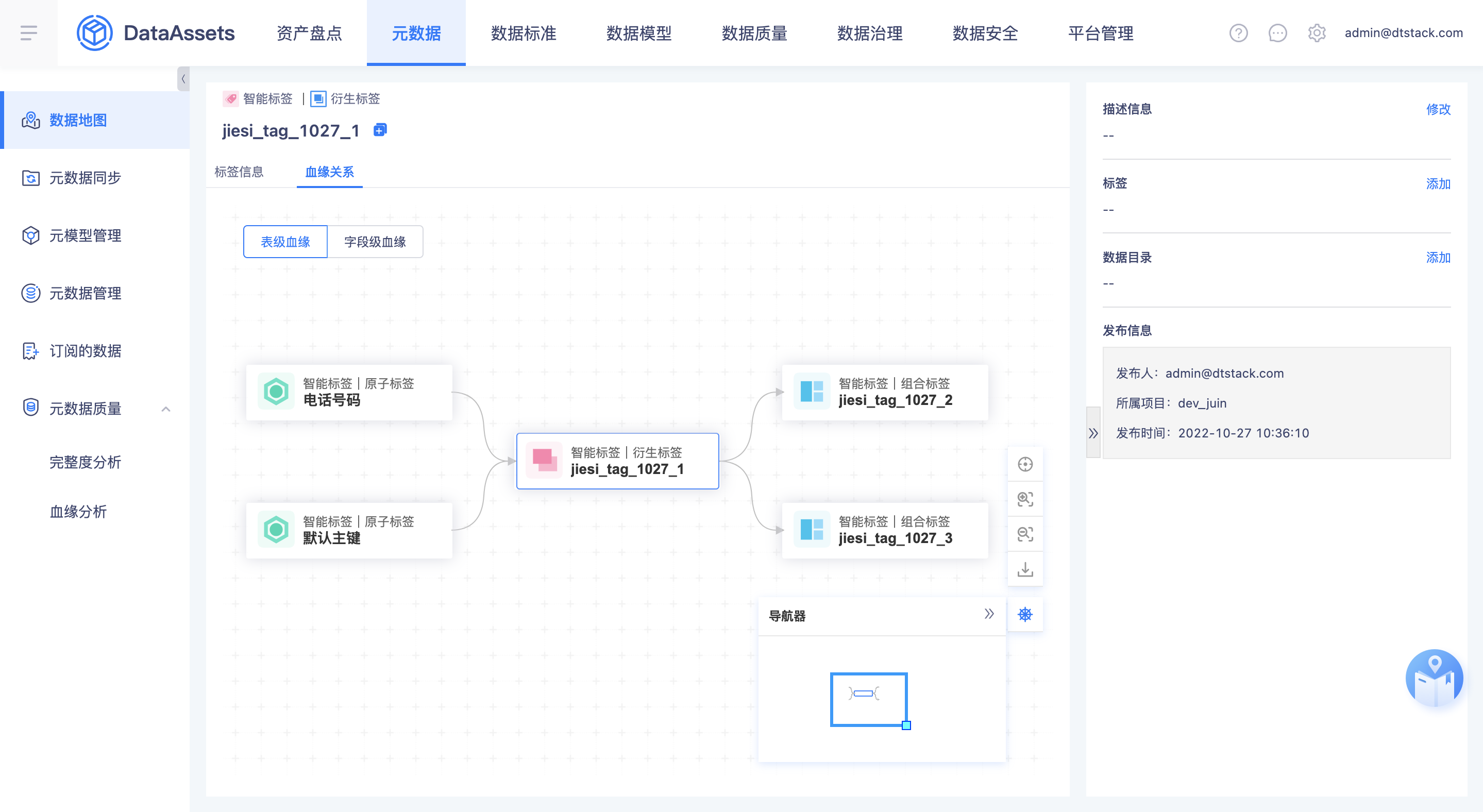
血缘优化
- 血缘解析新增truncate关键词:当表发生trancate数据清空时,表与表之间、表与任务之间的血缘关系需要删除
- 排除自身到自身的血缘以及重复展示的血缘
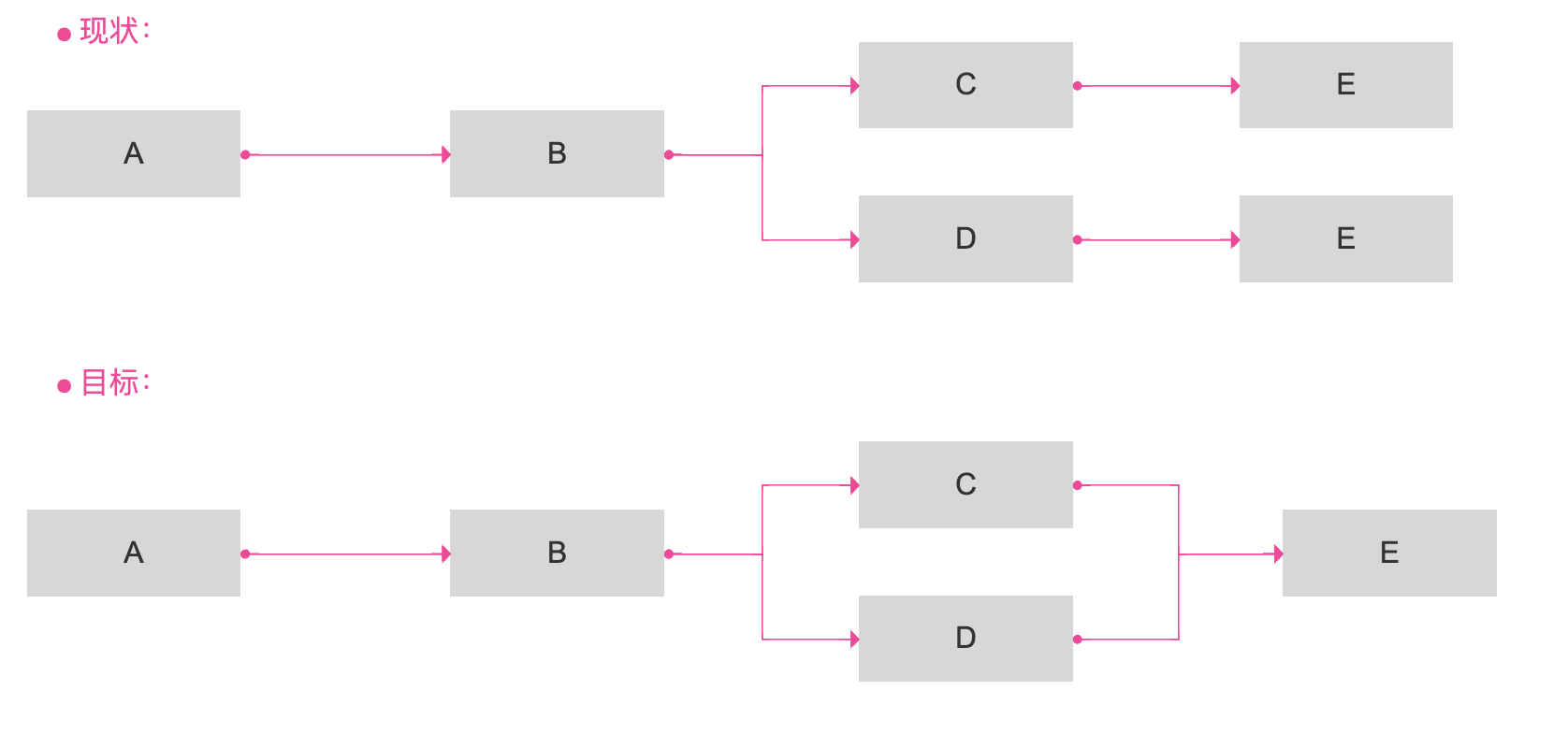
解决线段与表相互覆盖问题:
- 直角的血缘流向线段改为弯曲的灰色线
- 支持拖动
- 高亮当前覆盖或点击的表的流入和流出
离线数据地图迁移(V5.3.1)
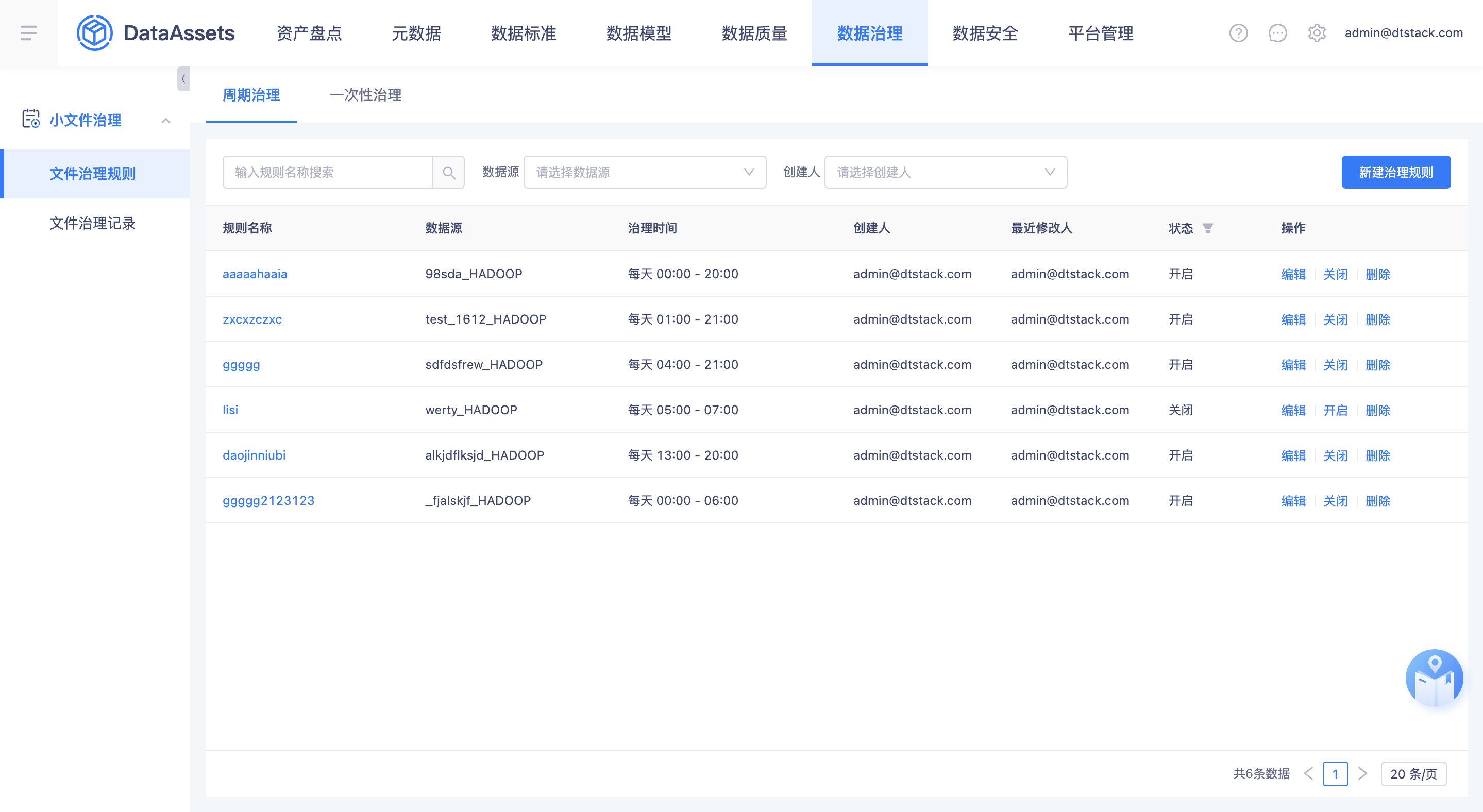
数据文件治理
- 将离线侧的数据文件治理迁移到资产侧的数据治理模块并进行优化和兼容,治理规则包括周期治理和一次性治理。
治理范围:经过元数据同步的SparkThift、Hive(1.x/2.x)、Hive3.x(Apache/CDP)的meta数据源。Hive3.x(Apache/CDP)接入资产后需要对应支持到数据治理模块,目前暂不支持。
优化调整:
- 周期治理「选择项目」改为「选择数据源」,治理范围为可选的meta数据源,下拉框排序按照时间进行倒序。
- 一次性治理「选择项目」改为「选择数据源」,治理范围为可选的meta数据源下的Hive表。
- 小文件治理的时间如果超过3小时则治理失败。超时的时间条件改为可配置项,可由配置文件支持,默认为3小时。
- 占用存储的统计目标由一个分区/表改为一个文件。
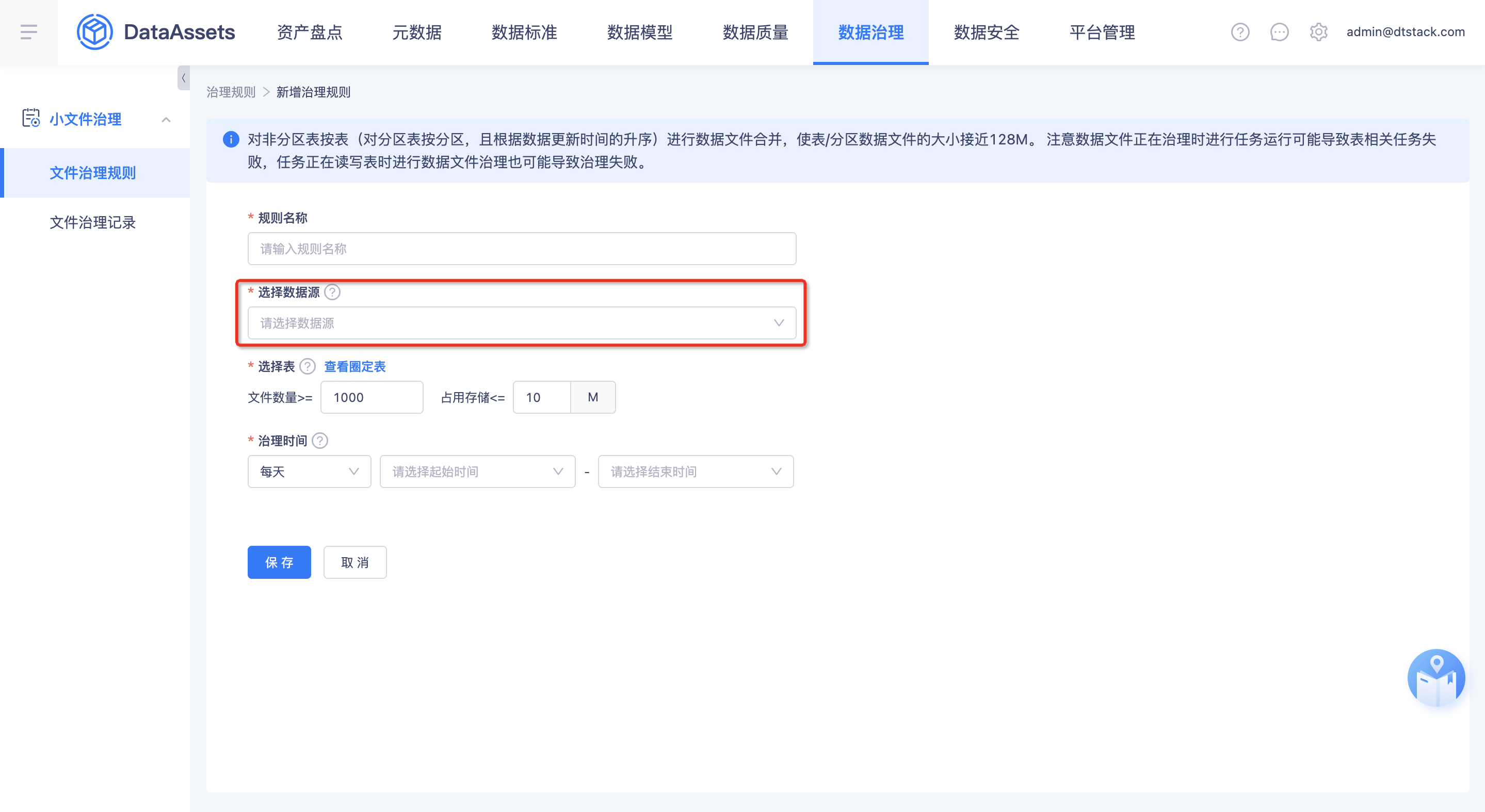
优化功能(V5.3.1)
元数据同步取消初始化流程:
- 背景:V5.2合并改造,元数据同步与数据源管理功能拆分之前,原有逻辑是在引入数据源后会先进行初始化,初始化完成后会一次性拿到所有库表名称,进行元数据同步时再去查拿到的库表信息。这将占据较多的资源和存储,并导致存在较多无用数据,如资产盘点加载数据慢等问题。
- 优化:取消数据源引入之后的初始化流程,在元数据同步时实时查询数据源内库表信息。
元数据中心耦合关系优化
增量SQL优化:目前元数据中心的定位基础元数据中心,可以支持单独部署,但是现在增量SQL无法支持
产品权限优化:某个客户有资产权限,在指标侧调用元数据中心的数据模型没问题,但是客户如果没有资产权限,调用元数据中心的数据模型就会提示没有权限
脏数据:
- 管理默认存储实效为90天,全局提示对应修改;脏数据管理范围针对当前项目。
数据源插件优化
- 同步全部库表参数,实际库表发生变化,优化:不传参数,数据源插件实时去查库表名称
- binlog关闭后重新开启:脚本已停止,没有被重新唤起,再次开启时需要自动唤起
词根匹配准确率提高:界面上增加的词根、标准需要加入分词器,解决了字段中文名按照分词去匹配,出现某些情况下无法匹配的问题。