快速上手
本文通过创建Iceberg表、基于Iceberg的离线计算、基于Iceberg的实时计算,来上手熟悉数据湖的特性和使用场景。
创建Iceberg表
在【数据源中心】创建「Hive Metastore」和「Sparkthrift」数据源并授权【数据湖】。
在【数据湖-数据源】中引入这两个数据源。
在【数据湖-元数据管理】中创建Catalog、Database。
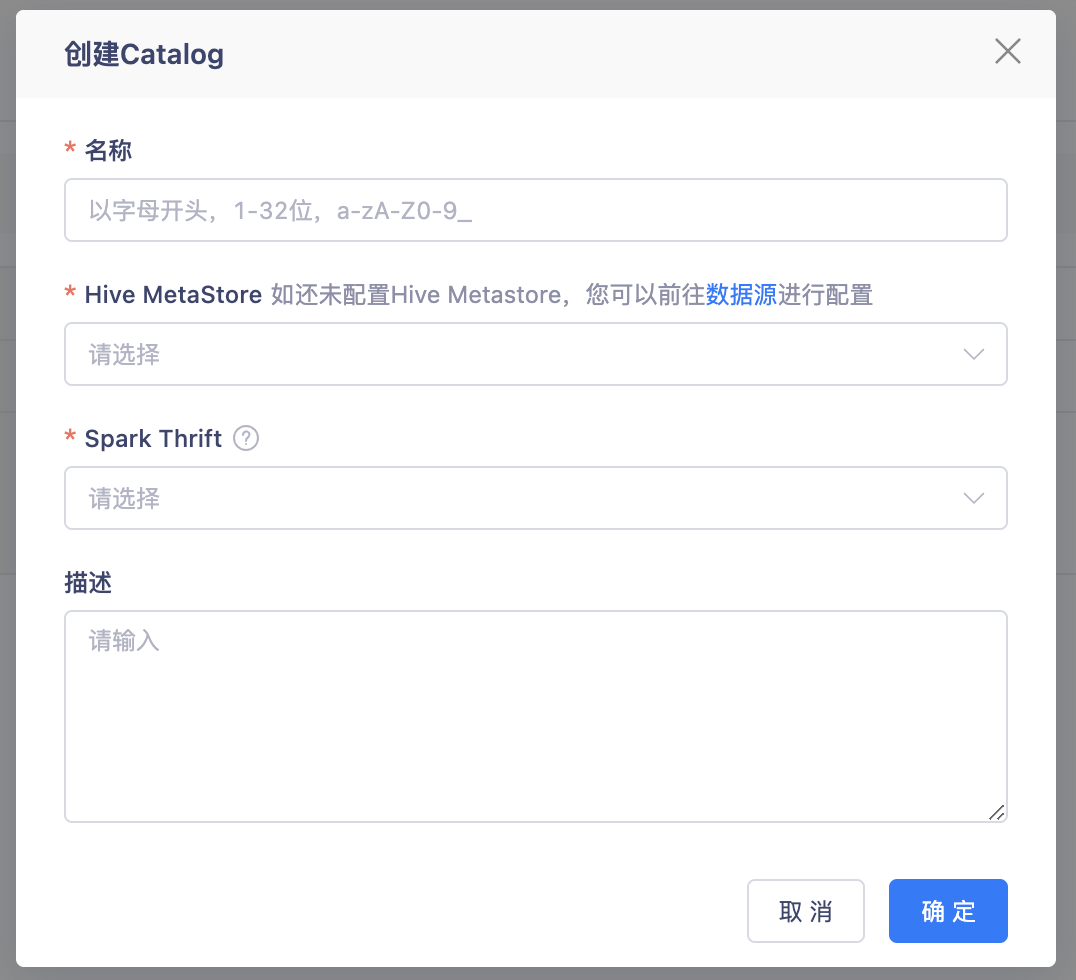
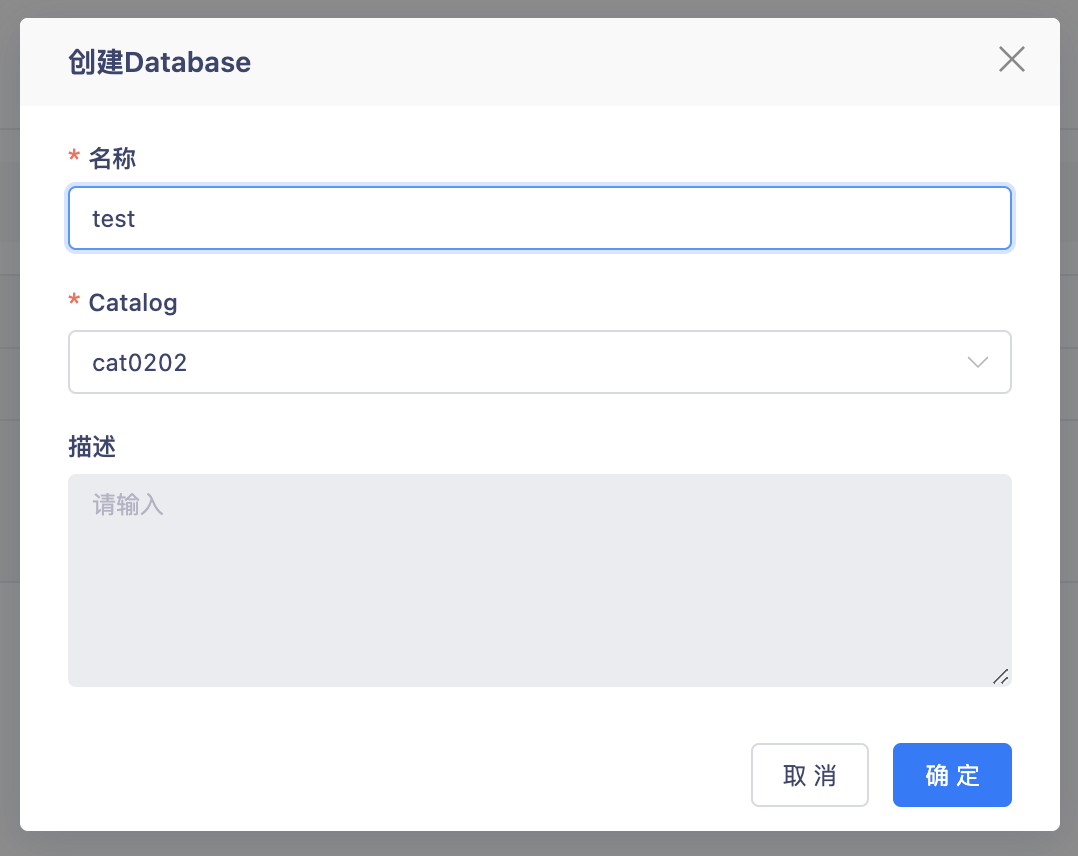
创建Iceberg表
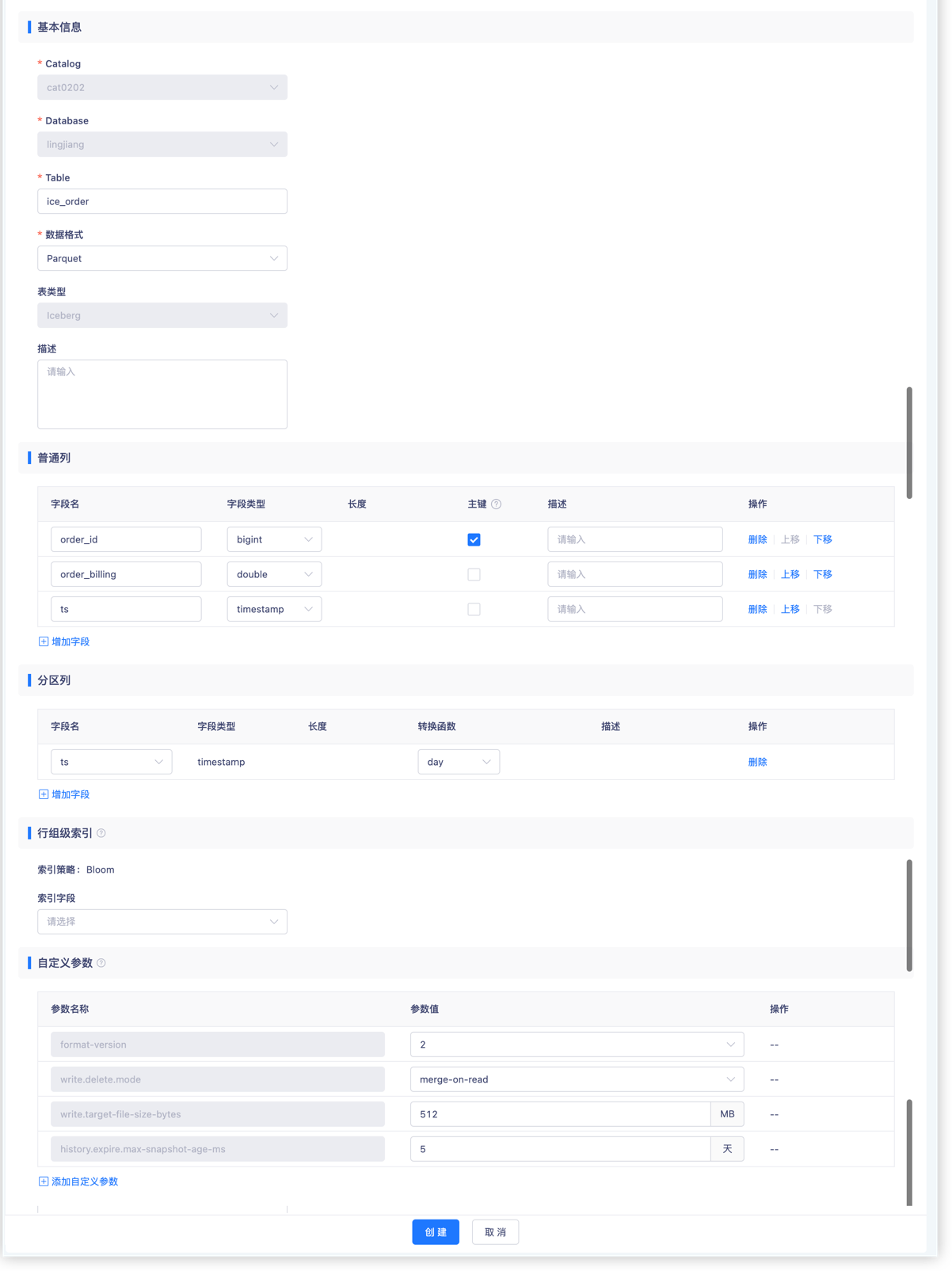
您也可以通过SQL模式创建:
CREATE TABLE cat0202.lingjiang.ice_order (
order_id bigint,
order_billing double,
ts timestamp,
primary key(id) NOT ENFORCED)
USING iceberg
PARTITIONED BY (days(ts))
基于Iceberg的离线计算
数据离线入湖
- 数据源中心配置Iceberg
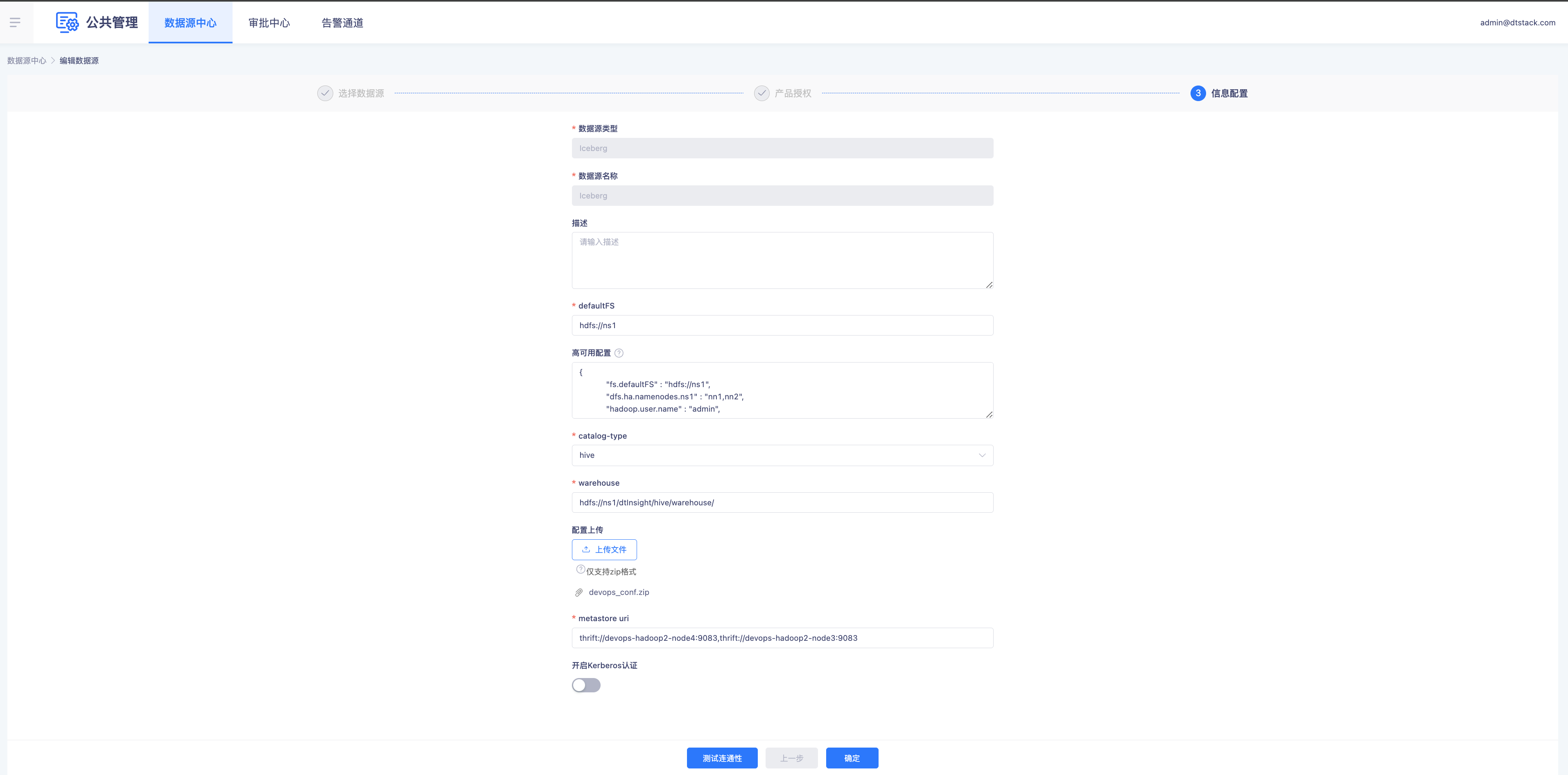
- 创建数据同步任务配置写入Iceberg
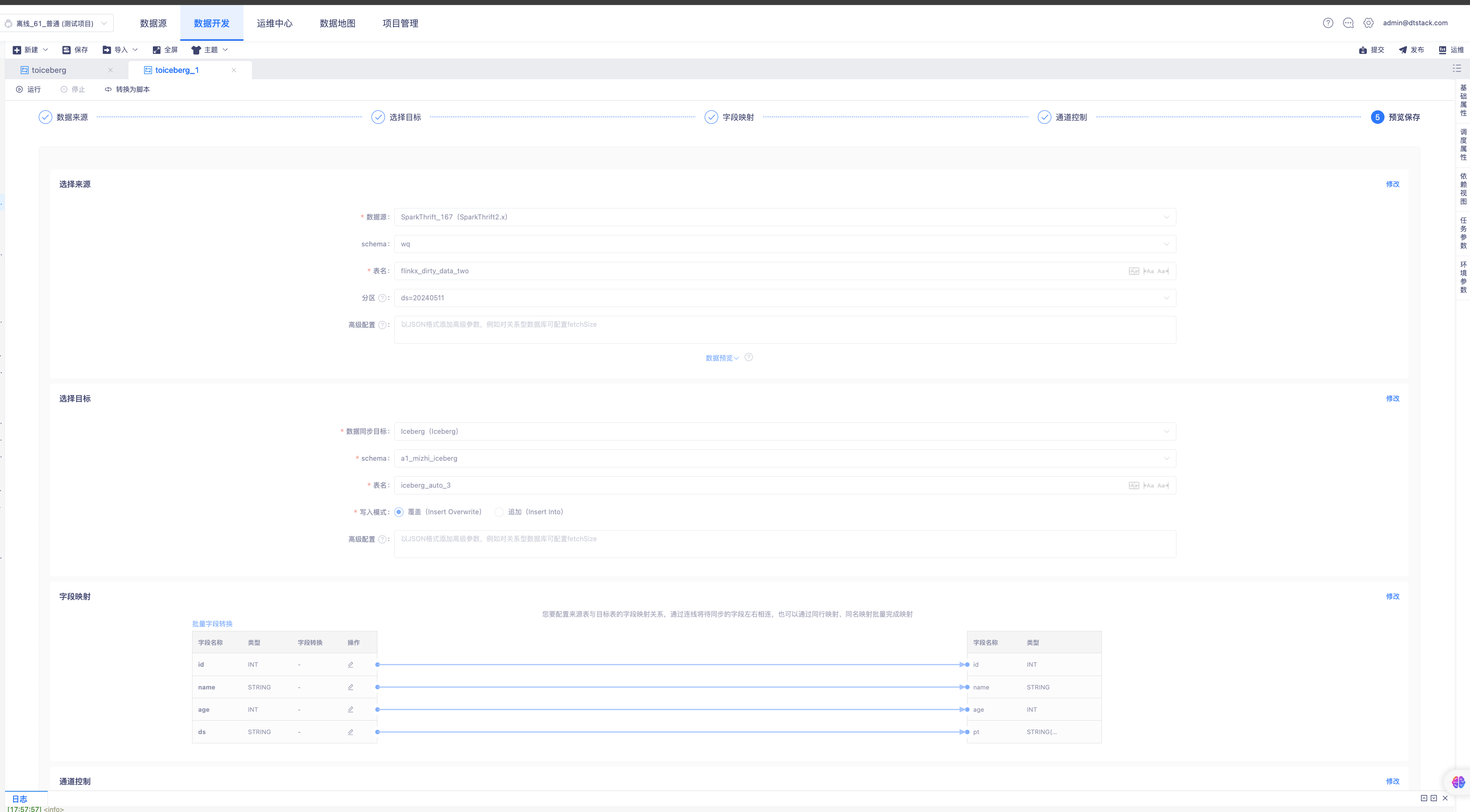
- 运行任务
- 入湖完成,湖仓一体查询Catalog表信息
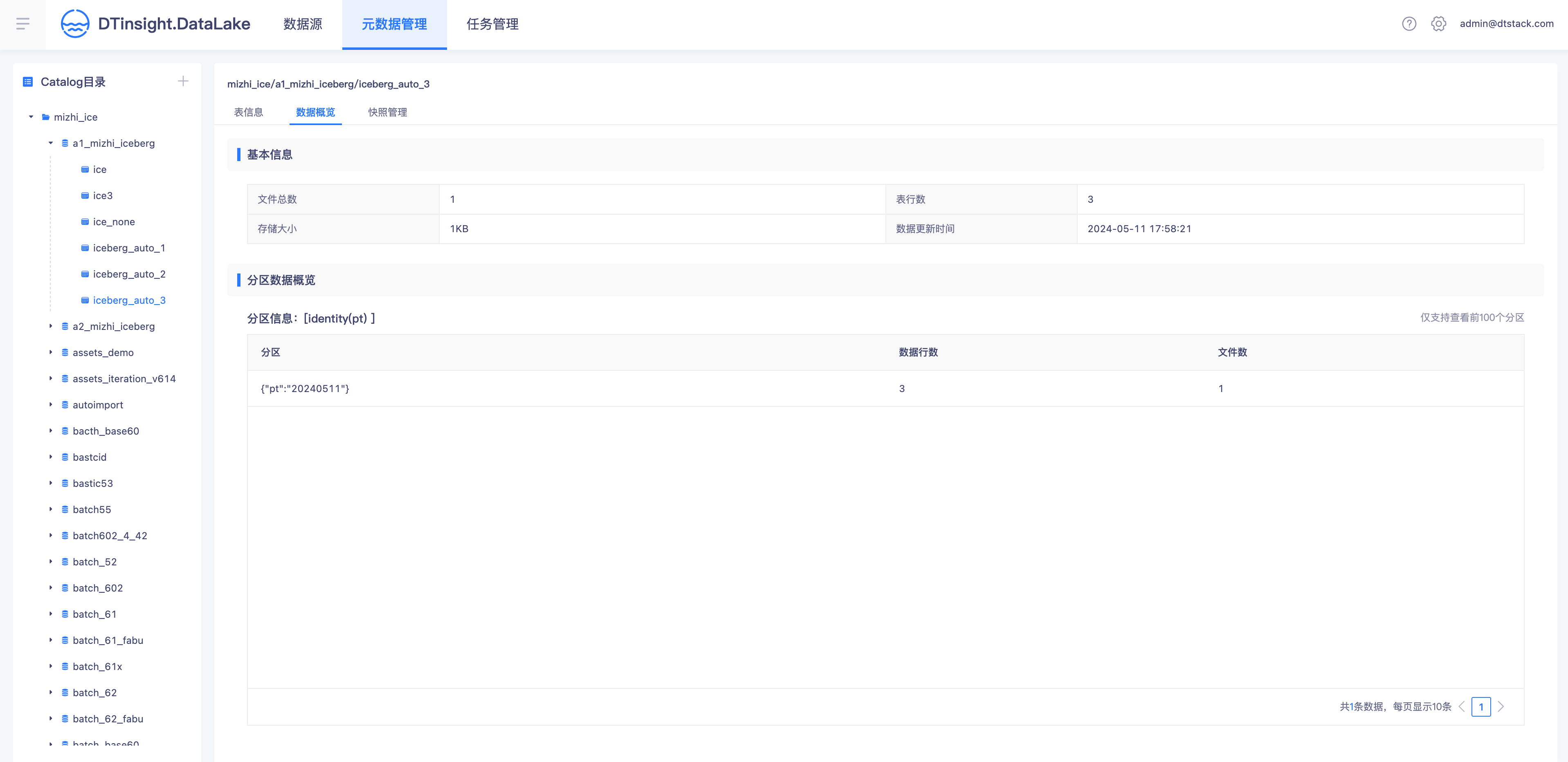
湖数据的批计算
note
Spark版本请使用3.x,并确认写入iceberg表的HMS和Spark引擎属于同一集群。
如果要在【数栈-离线平台】开发任务,请先在【控制台-多集群管理-计算组件-Spark】中,将Spark3.2作为默认引擎,并在DataLake中配置参数:
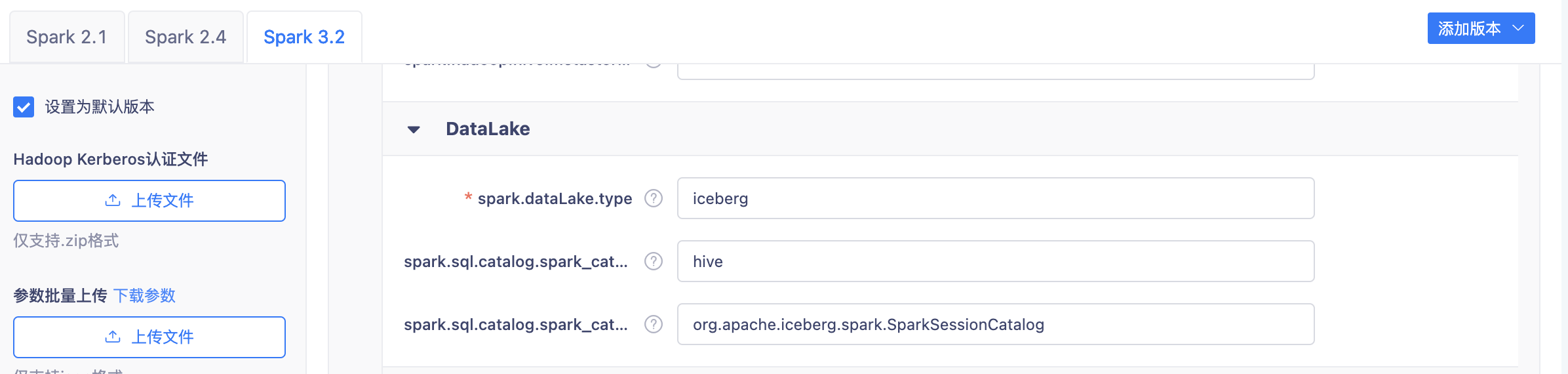
如果需要在外部计算平台开发任务,请先在Spark配置文件【spark-defaults.conf】中完成如下配置:

-- 验证Iceberg分区特性:数据写入自动分区;隐藏分区式查询
##写入4条数据
INSERT INTO lingjiang.ice_order VALUES
(1,12,cast('2023-02-10 14:25:59' as timestamp)),
(2,99,cast('2023-02-10 22:22:22' as timestamp)),
(3,111,cast('2023-02-11 11:11:11' as timestamp)),
(4,33,cast('2023-02-11 13:13:13' as timestamp))
##查询分区信息。会显示已经根据分区设计days(ts),自动创建了2023-02-10和2023-02-11两个分区
SELECT * FROM lingjiang.ice_order.partitions;
##查询数据。只需要限定业务时间,自动查询指定分区数据,而不会全表扫描
SELECT * from lingjiang.ice_order where ts>'2023-02-11 11:11:11';
-- 验证数据更新能力
##修改编号为1的订单金额,调整为100
UPDATE lingjiang.ice_order
SET order_billing=100 where order_id=1
-- 更多Iceberg的特性能力,您可以访问[https://iceberg.apache.org/docs/latest/]进行查看。
基于Iceberg的实时计算
数据实时入湖
- 数据源中心配置HiveMetastore
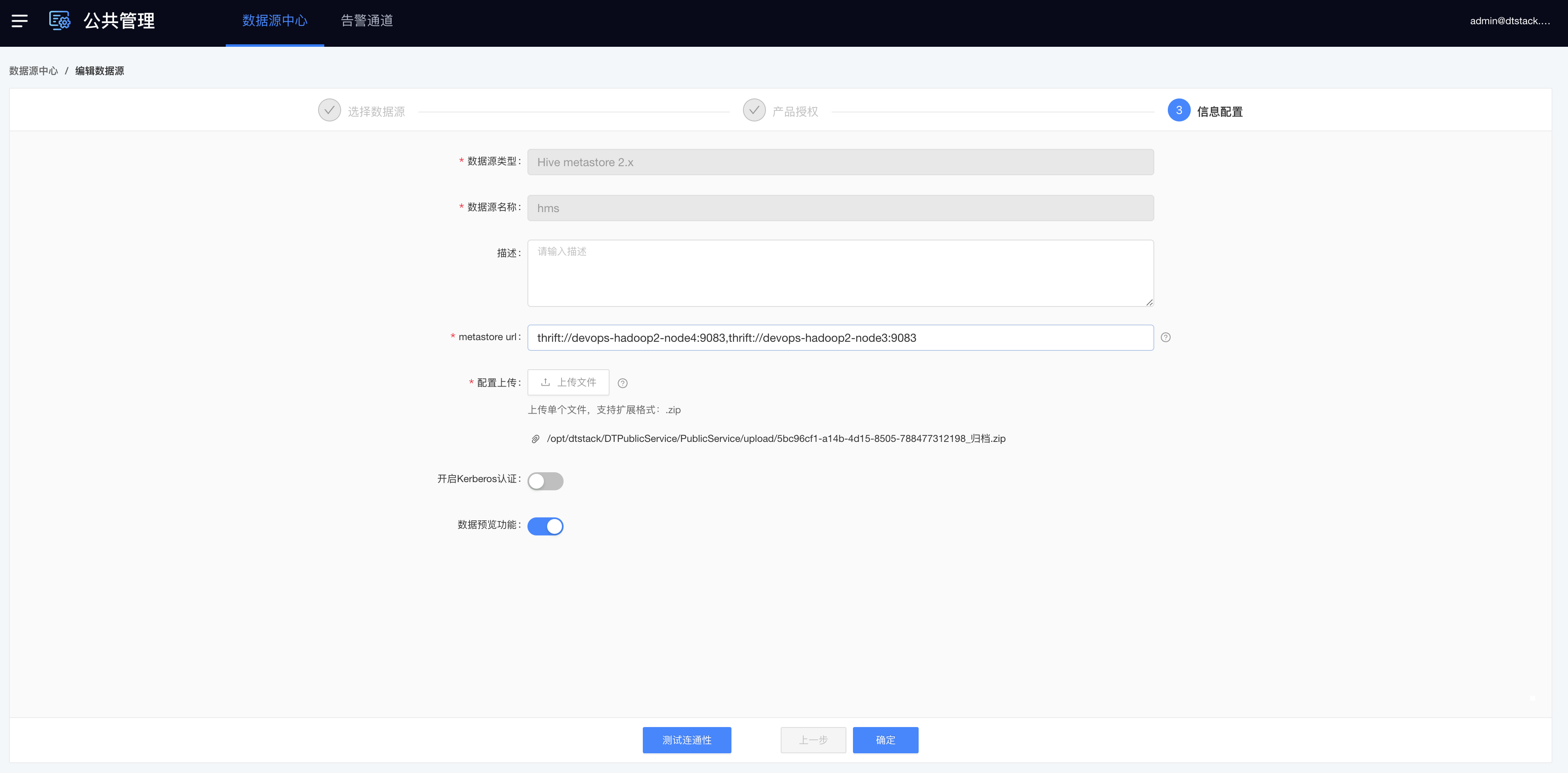
- 表管理-配置Catalog
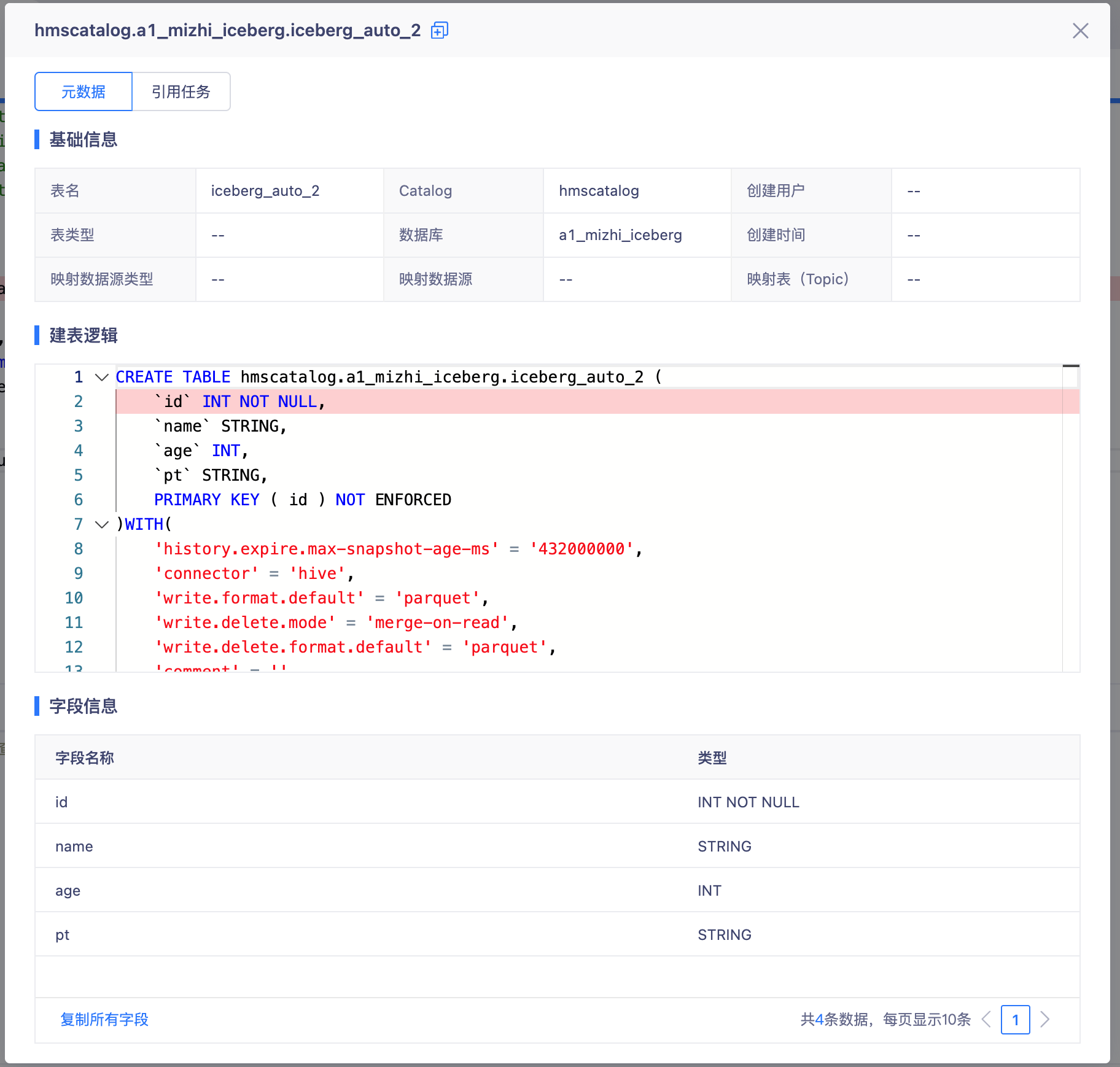
- 创建FlinkSQL任务编写SQL
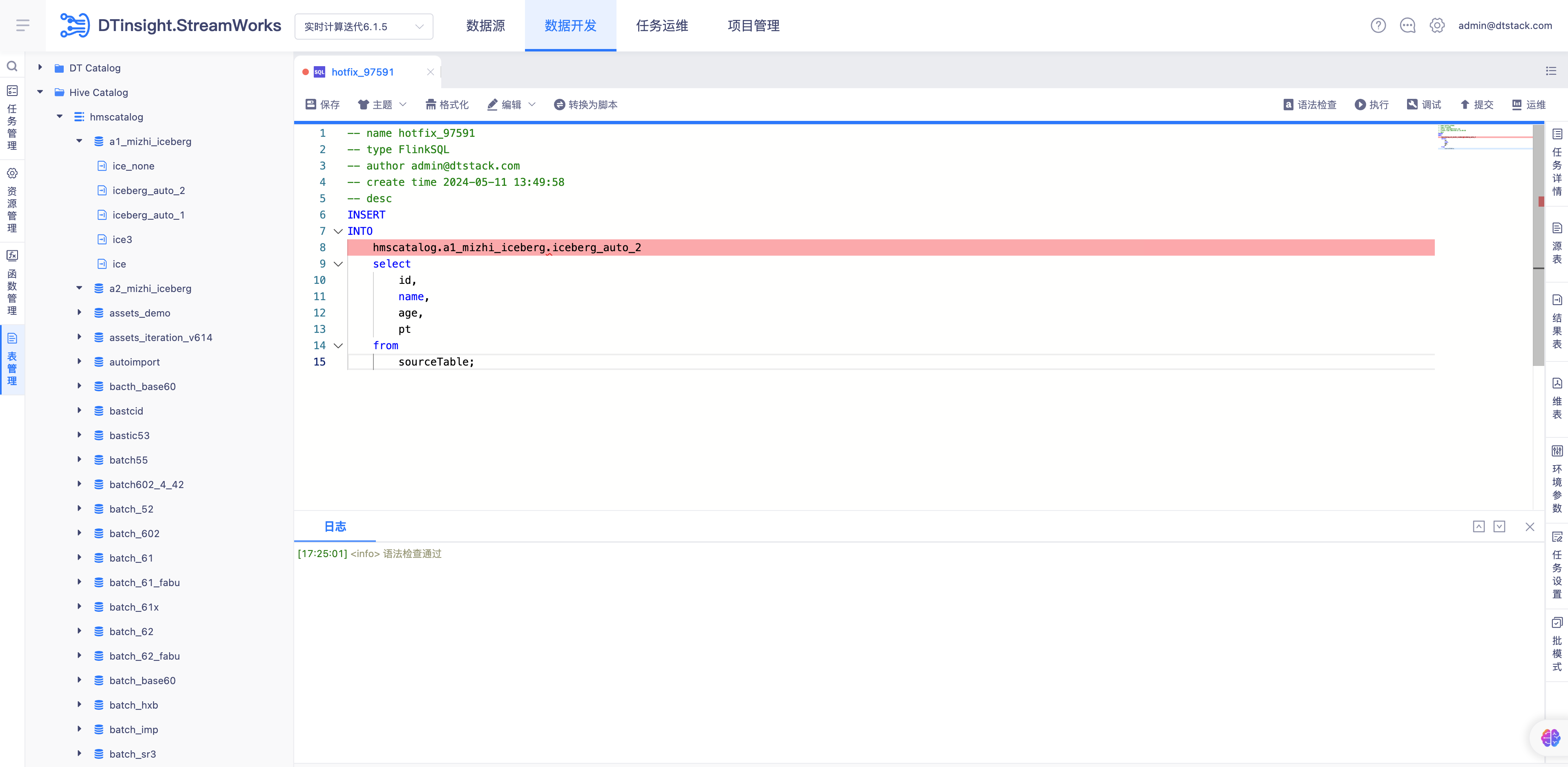
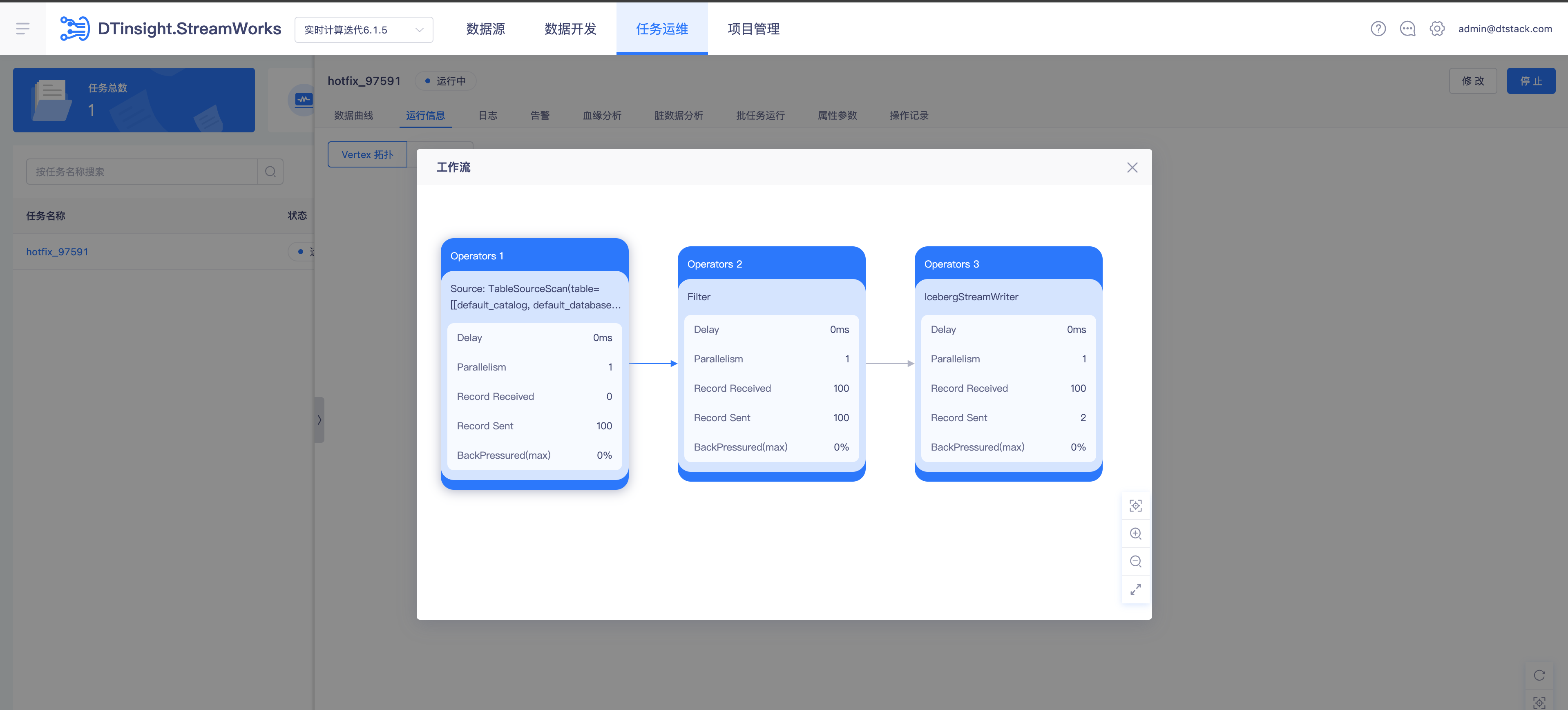
- 提交调度运行任务
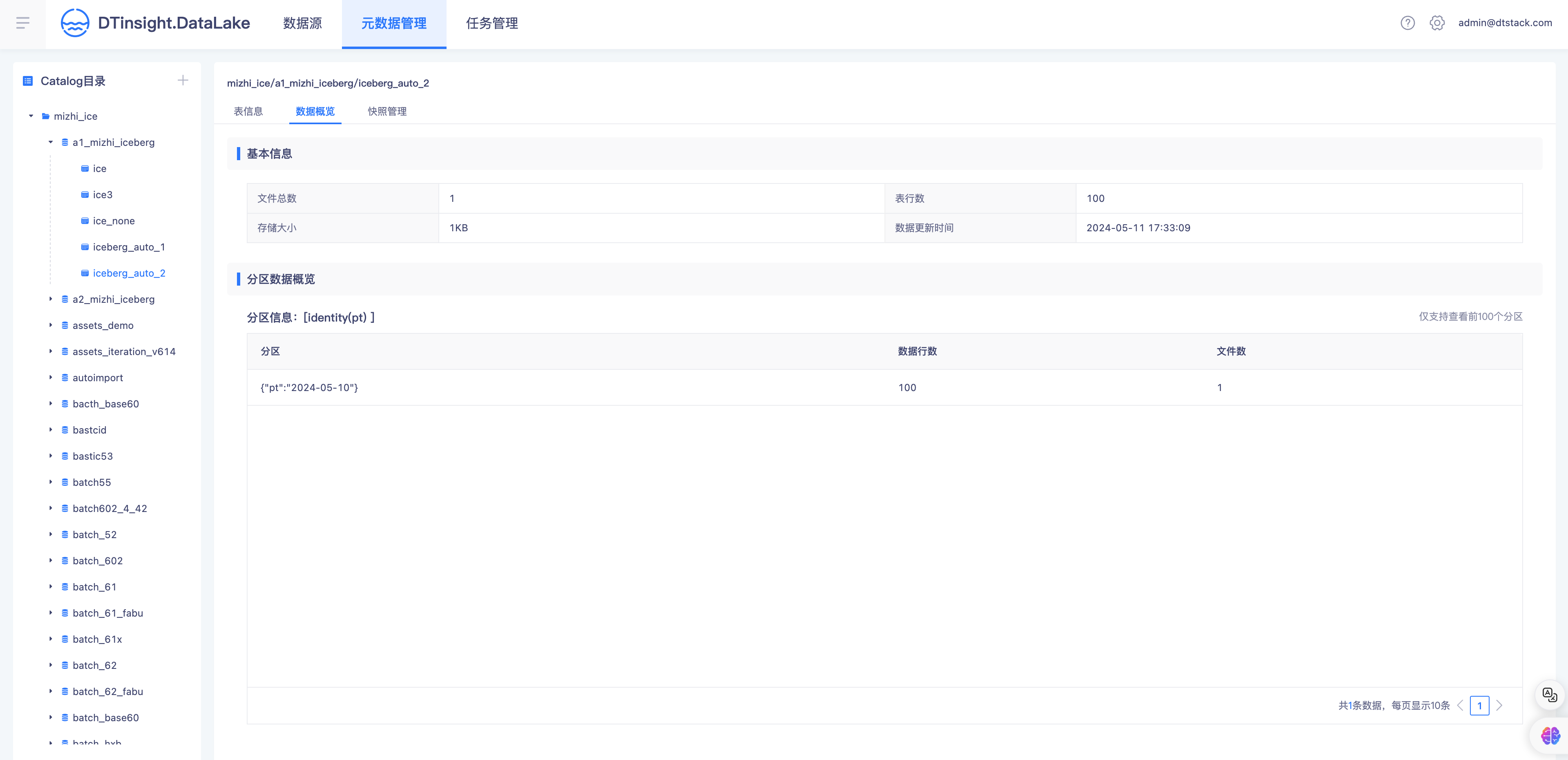
- 入湖完成,湖仓一体查询Catalog表信息
湖数据的流计算
note
- Flink版本请使用1.12及以上,并确认写入iceberg表的HMS和Flink引擎属于同一集群。
- 如果要在【数栈-实时平台】开发任务:
- 先在【控制台-多集群管理-存储组件-HDFS】中,下载Hadoop配置文件和Keberos认证文件(如有)。
- 然后到【数栈-公共管理-数据源】中,创建Hive Metastore,上传刚刚在控制台下载的文件。
- 最后到【数栈-实时平台-数据开发】的表管理功能中,创建Hive Catalog并引用上面创建的HMS。
-- 验证流式数据入湖iceberg
CREATE TABLE source1
(
id INT,
name STRING,
ts timestamp
) WITH (
'connector' = 'stream-x',
'number-of-rows' = '100000', -- 输入条数,默认无限
'rows-per-second' = '1' -- 每秒输入条数,默认不限制
);
INSERT INTO ice_test.lingjiang.ice_source SELECT id,name,ts from source1;
-- 验证基于iceberg的flinksql开发
##不需要维护flink映射表,直接基于HiveCatalog中的库表进行开发
INSERT INTO ice_test.lingjiang.ice_sink SELECT id,name,ts from ice_test.lingjiang.ice_source;