集群配置
概述
点击集群名称或者操作中的【集群配置】,进入「集群配置」界面,用户可以通过「集群配置」来对每个集群底部组件配置进行查看和管理。
集群配置分为以下几部分:
- 公共组件:配置公共信息,SFTP配置公用的配置信息和认证信息,Ranger、Ldap和Common组件和数据安全有关。
- 资源调度组件:配置集群要用于运行任务的资源调度组件信息;
- 存储组件:配置数据存储的组件;
- 计算组件:控制台配置的计算组件类型决定了子产品中能创建什么类型的任务。
公共组件
点击右上角的【编辑】键,进入「编辑」状态。
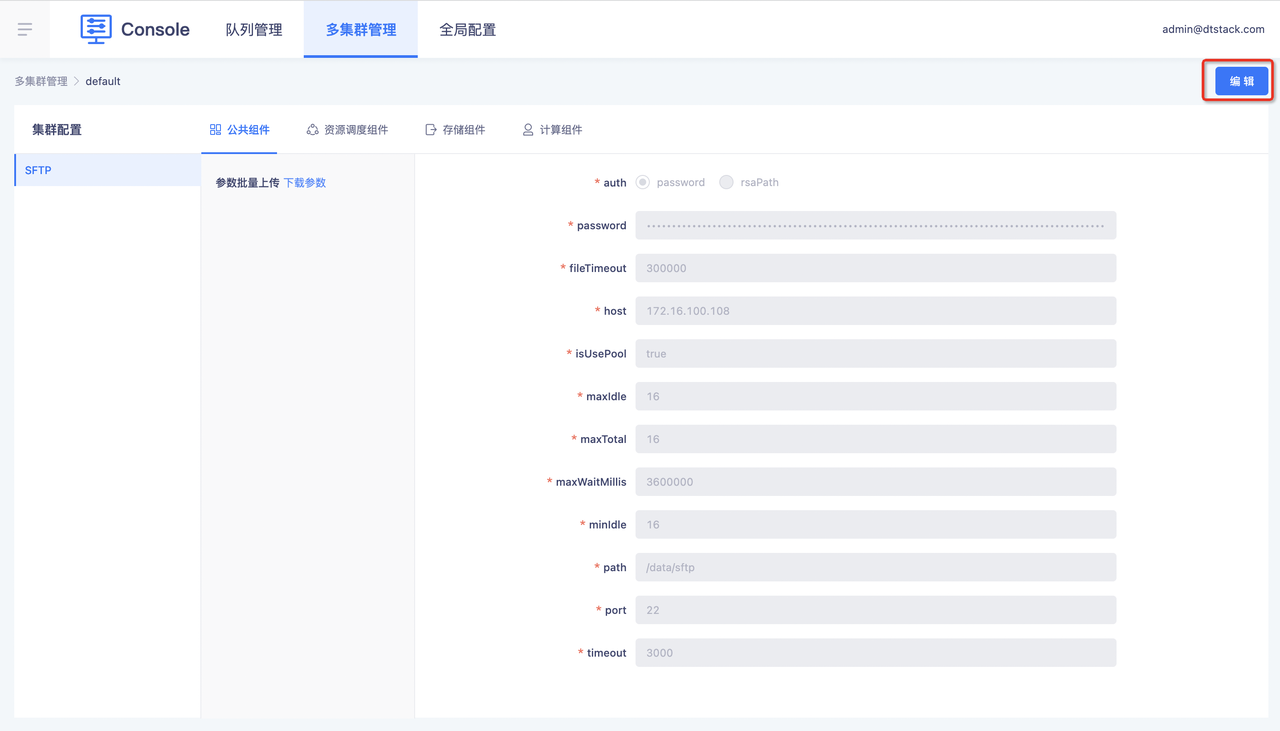
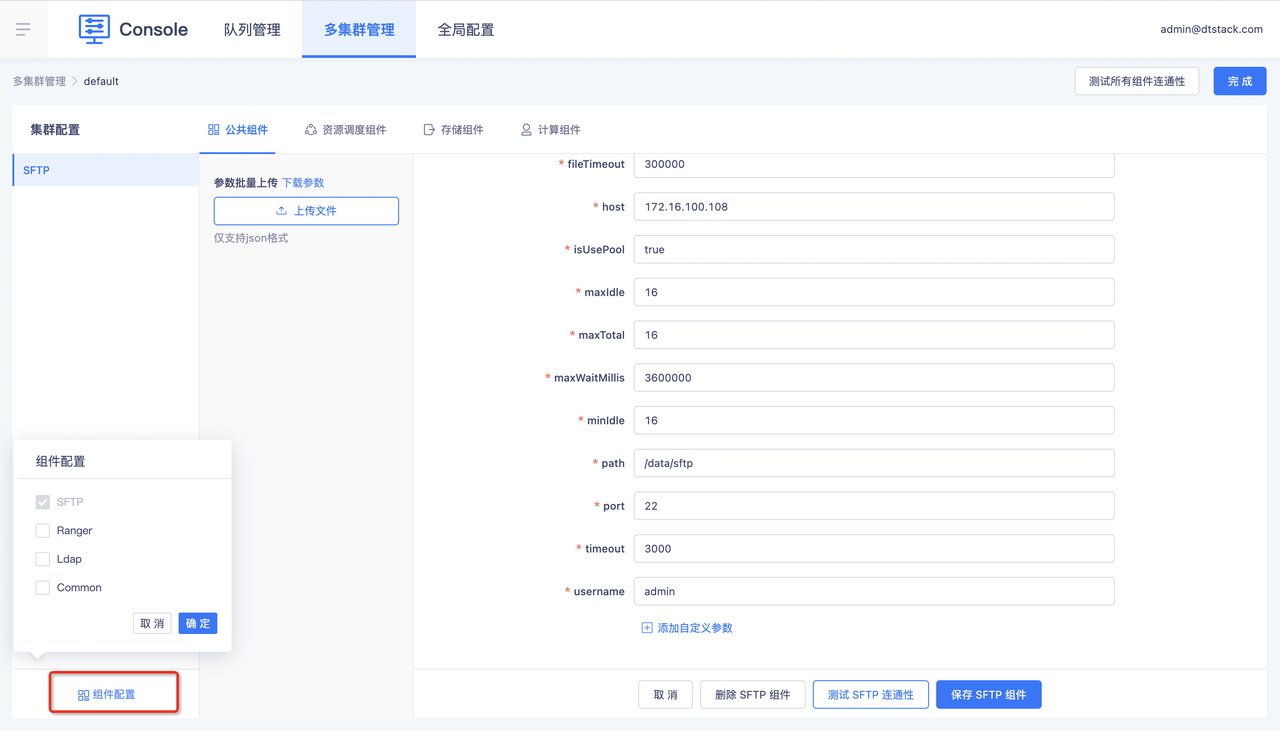
点击【组件配置】,选择自己要新增的组件SFTP。
SFTP配置中,其他配置都是默认值,只有四个配置需要自己手动填写:
- auth:选择连接host的方式
- password:选择password之后填写连接host的密码;
- rsaPath:选择rsaPath之后填写host的RSA密钥对来连接;
- host:主机的IP地址
- username:host的username
Ranger、Ldap和Common组件和数据安全有关,用户可按需配置。配置了Ranger和Ldap后,数栈会进行如下操作:
- 将数栈的历史用户映射到ldap上,并在本地维护一份用户和ldap的关系表
- 将数栈的角色体系映射到ranger里的role。
- 后续走代理逻辑时,将从本地的关系表中获取代理信息,不用ldap用户对接登录的信息。
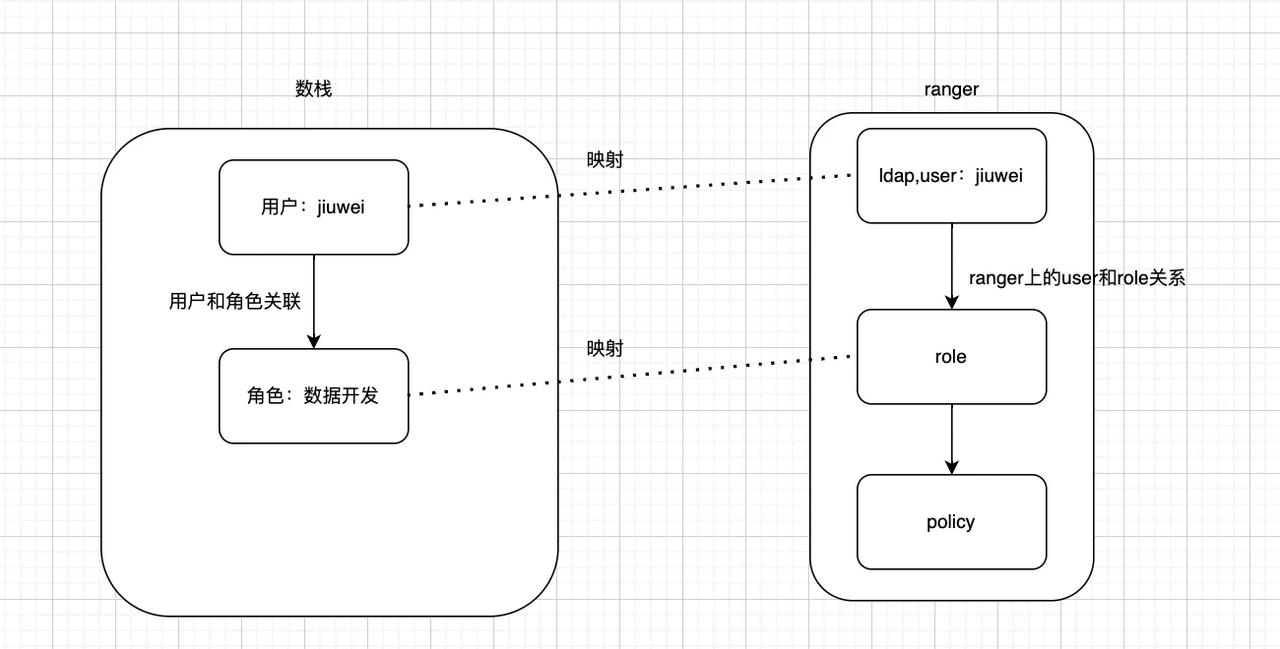
举例:客户希望开启ranger+ldap做权限管控,并且能够和数栈内的uic用户关联,用uic用户登陆的时候能够使用ranger这套底层的权限管控。那么在控制台--集群配置完成ldap信息之后,数栈内的uic用户会自动在ldap里面创建数栈用户,比如数栈内本来有个用户是“jiuwei@dtstack.com”,配置完成后数栈会自动在ldap中创建jiuwei账户,客户那边需要做的就是重新在ranger中分配下jiuwei这个账户的权限信息。
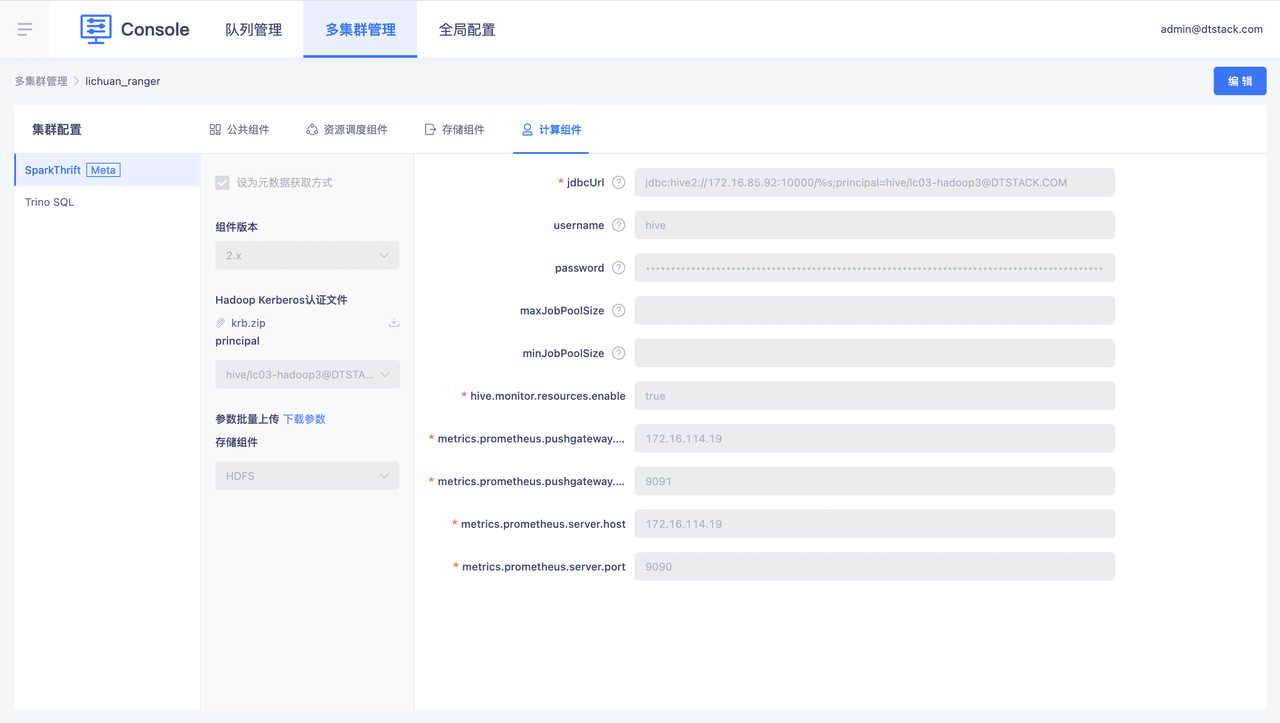
资源调度组件
在资源调度组件界面中,在「组件版本」中选择Hadoop版本,并在「配置文件」中打包上传配置文件,则右侧会解析上传的文件,并回显其中的参数。参数含义可参考Hadoop官方文档相关内容。
「配置文件」用于配置资源信息,为后续资源组配置划分队列。
「Hadoop Kerberos认证文件」用于配置用户在Hadoop中进行Kerberos身份认证的文件。
「SSL文件」用于配置集群中SSL认证的文件。
存储组件
在存储界面界面中,在「组件版本」中选择Hadoop版本,并在「配置文件」中打包上传配置文件,则右侧会解析上传的文件,并回显其中的参数。参数含义可参考Hadoop官方文档相关内容。
「Hadoop Kerberos认证文件」用于配置用户在Hadoop中进行Kerberos身份认证的文件,保护Hadoop集群免受未经授权的访问和攻击。通过Kerberos身份验证,Hadoop可以确保只有授权的用户才能访问集群中的数据和资源。开启kerberos后,就只有授权的用户才能去访问HDFS和YARN,这样就可以有效保证Hadoop的数据安全
「SSL文件」用于配置集群中SSL认证的文件。
计算组件
用户可新增自己需要的计算组件,完成配置之后即可在子产品中创建对应类型的任务。
权限管控方式
支持灵活的权限管控方式,用户可以选择是否通过数栈进行权限管控,通过数栈进行权限管控指在数栈层面管控权限。

通过数栈的权限管控
用户可以在web管控权限或者开启对接数据安全平台。
- web层管控权限
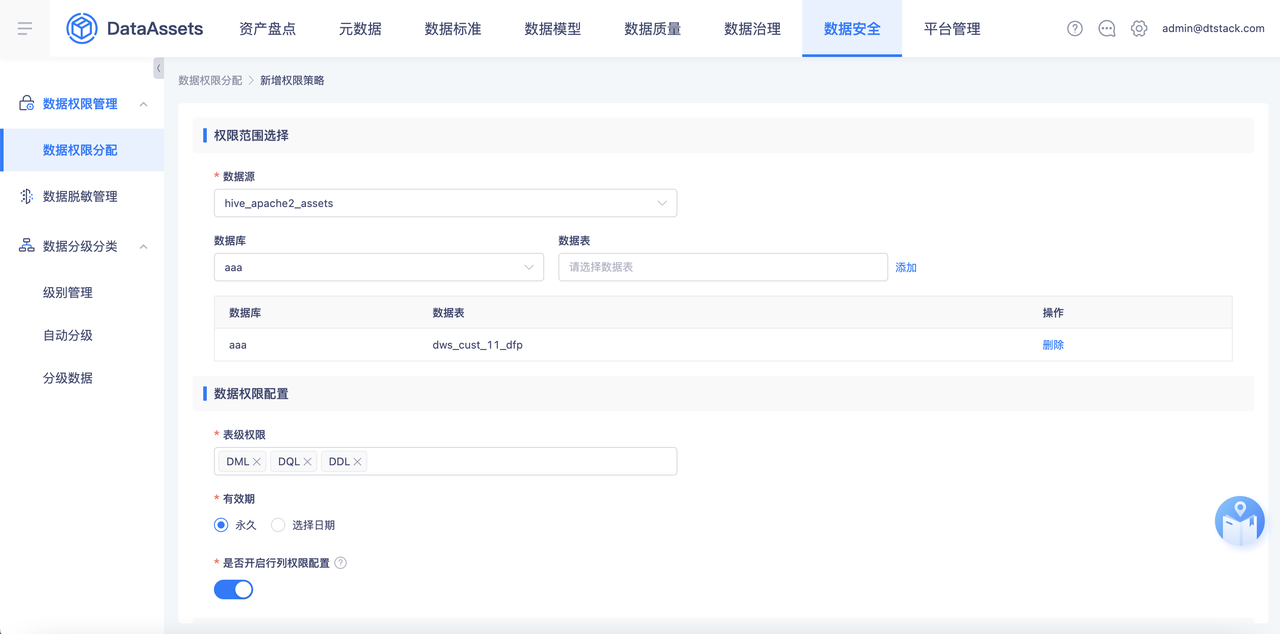
在各个子产品进行数据权限的配置,配置后数据权限只在数栈内生效。以资产平台为例,管理员可在「数据安全」-「数据权限管理」-「数据权限分配」中通过数据权限分配,以数据源、数据库、数据表、表权限、行列权限的粒度进行数据权限的分配,可指定具体用户/用户组被赋予的数据权限信息。
- 对接数据安全平台
配置数据安全平台相应服务之前,租户需要将数栈对应的Ldap及Ranger连接信息配置好。

在「集群配置」-「公共组件」中配置Ldap和Ranger组件。注意:对接数据安全平台时,Ranger组件只支持2.2版本。

Ldap及Ranger连接信息配置好后,在「集群配置」-「计算组件」中配置好相应的Hadoop SQL/trino服务,保存后会默认同步至ranger创建相应的服务。服务可用的前置条件:运维侧已经部署相应的Ranger Plugin,且服务名称与console配置的保持一致。
Hadoop SQL指通过SQL访问Hadoop内的数据,包括通过Hive、SparkThrift、Impala访问Hadoop内的数据。相当于数栈页面上的HiveSQL、SparkSQL、ImpalaSQL。

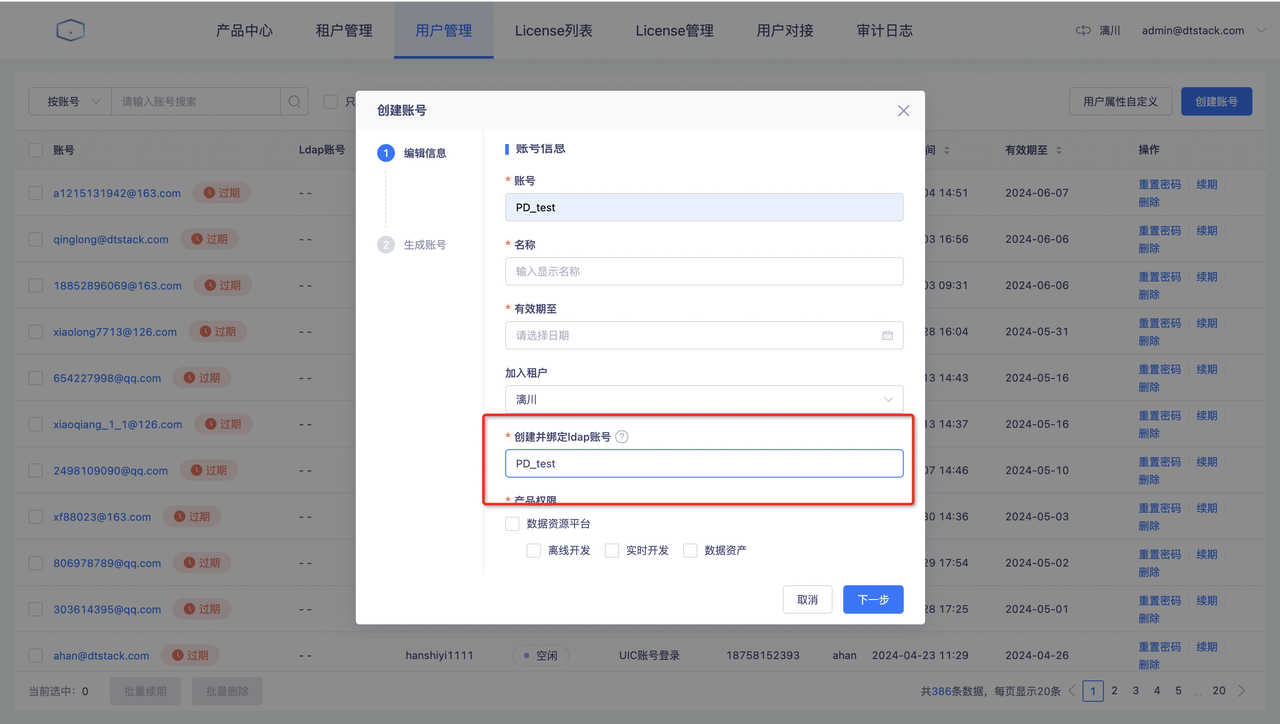
在「用户中心」-「用户管理」中创建账号时创建并绑定ldap账号。
不通过数栈的权限管控
如果用户不希望通过数栈管理权限,例如在用数栈前已经直接用了自己的ranger/tdh的guardian,数栈也可进行用户认证的对接,即在需要数据权限校验处进行用户身份信息传递,进而实现数栈外的权限管控。下面将介绍这两种管控方式要如何配置实现:
1、ranger管控权限
为了能够让数栈的用户在执行任务时,能够让ranger管控到用户的权限,数栈提供了两种方案。
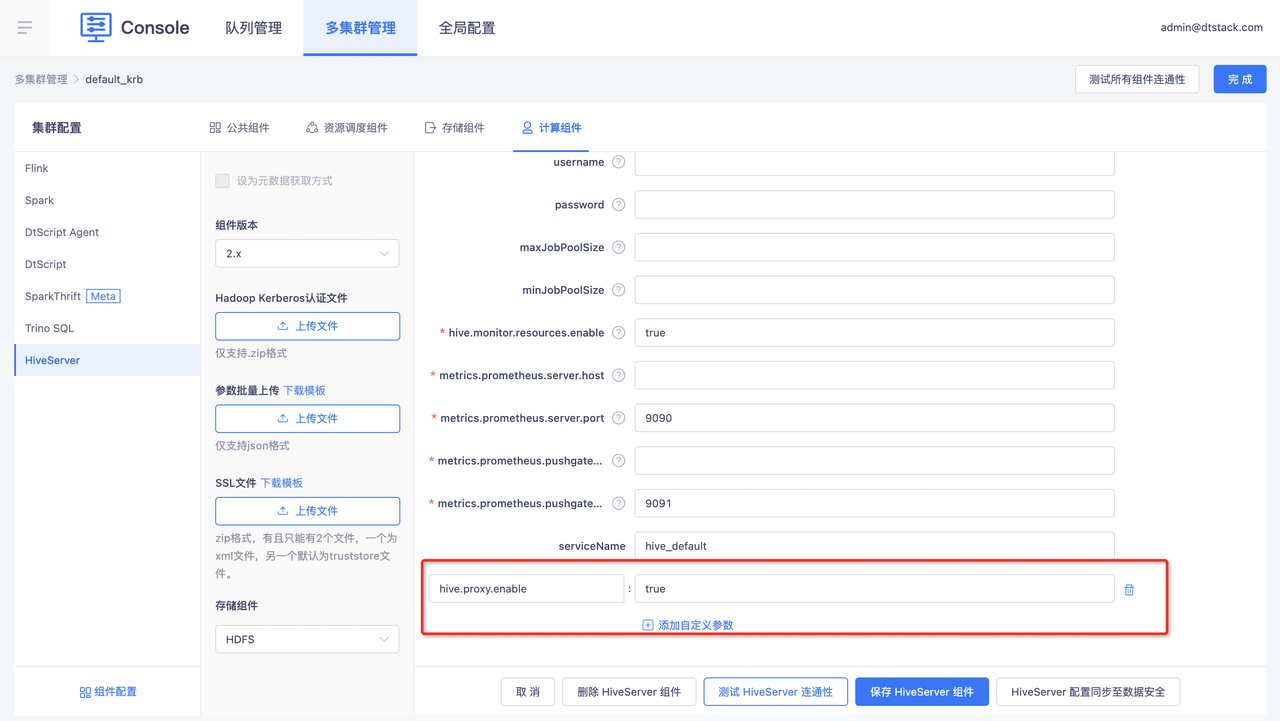
方案一:仅对hive组件的管控
客户在自己的ranger上配置权限,数栈支持在hive组件参数里加上这个参数hive.proxy.enable=true,这个时候执行hive sql时,调度会从业务中心拿取用户对接登录的ldap账号,填充代理信息。
方案二:对spark、flink等组件支持管控。
目前数栈支持对spark、flink、trino、spark、hdfs、inceptor、hive、dtsctipt进行ranger管控,需要在控制台配置ranger和ldap组件,并在common模块开启这个参数hadoop.proxy.enable。当上面两个组件配置并开启hadoop.proxy.enable后,调度将支持把代理信息传递到底层引擎,由引擎设置相关参数,让任务走ranger管控。
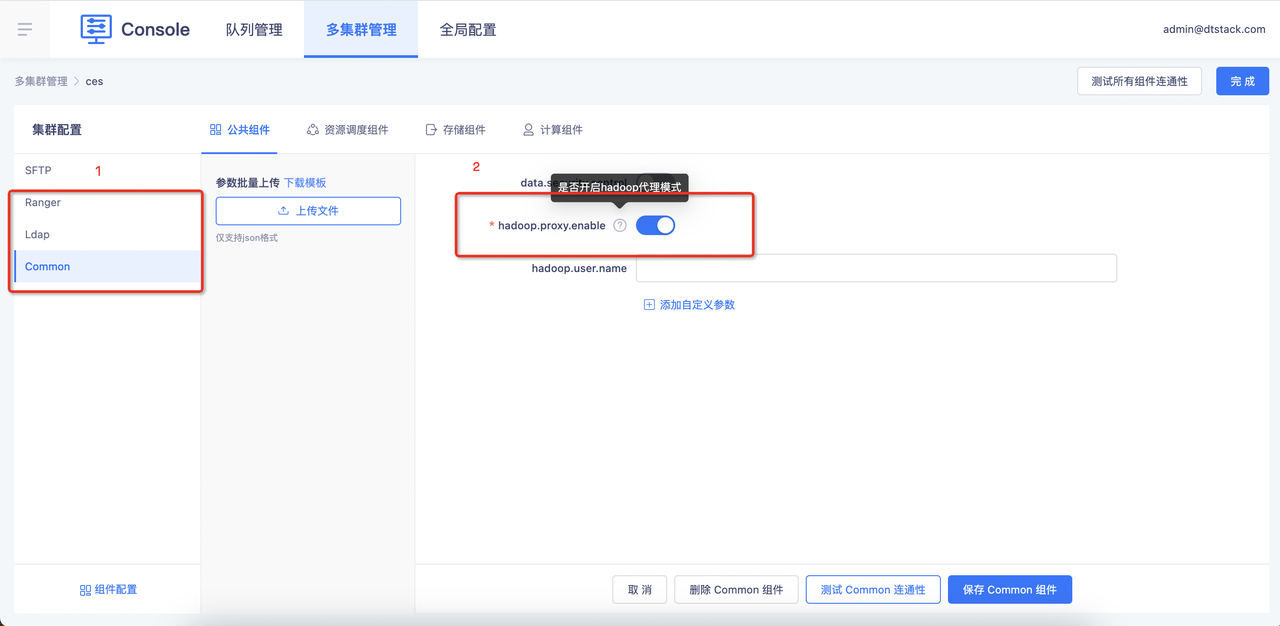
配置好后,在执行sql或提交任务时,会从业务中心获取当前账号所绑定的ldap账号信息。
- 方案二兼容方案一,支持方案二支持后,hive的管控同样生效。
- 若客户需要对hive、inceptor进行管控,且不需要打通数栈用户-角色与ranger的user-role,可采用方案一并自己在ranger上配置user和policy的关系,从而达到执行sql时受管控权限的目的。
- 若客户需要对hive、spark、flink、trino、spark、hdfs、dtsctipt进行管控,且需要同步数栈的用户和角色到ranger上,可采用方案二来实现数栈用户-角色体系与ranger的user-role体系互通,从而达到ranger权限管控的目的。
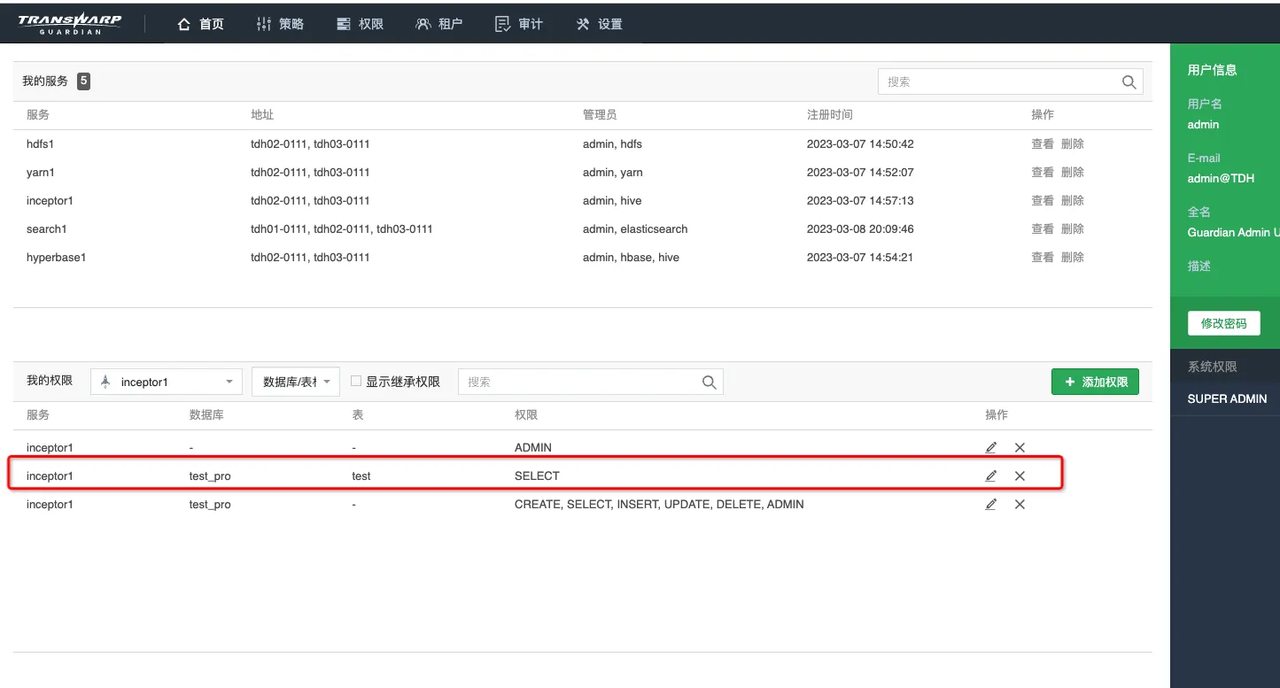
2、guardian管控权限
在TDH集群中开启guardian,正确设置权限。
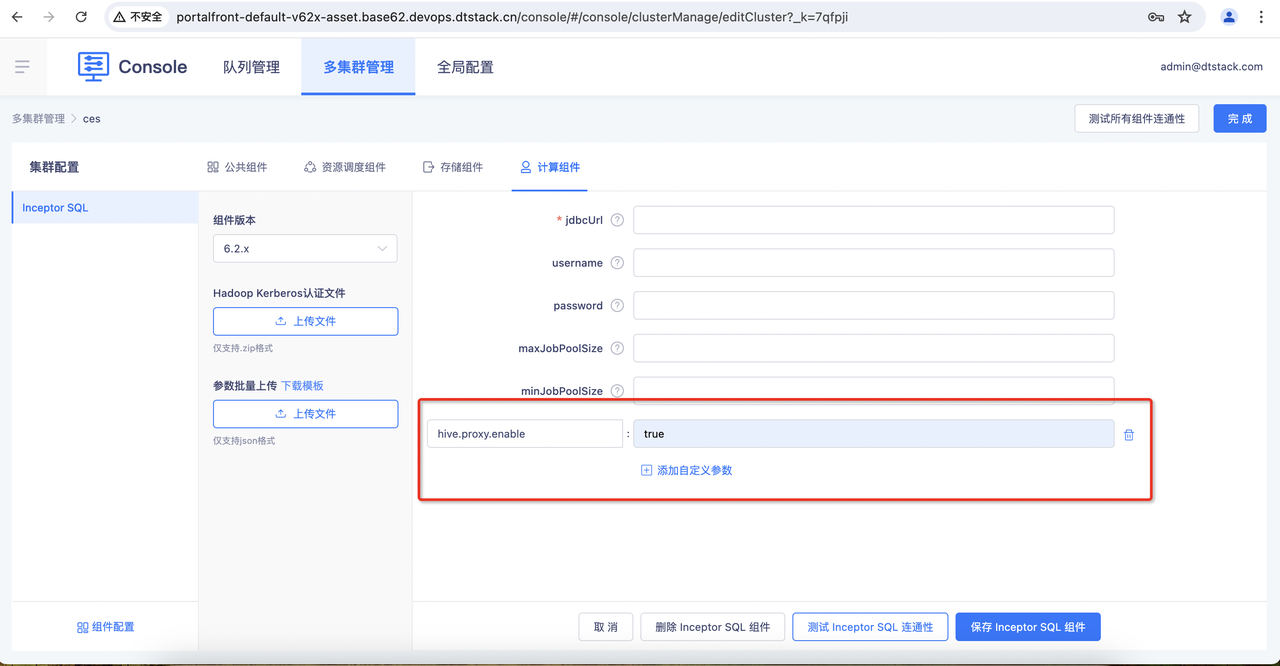
在计算组件中新增Inceptor组件开启guardian,在配置信息中新增自定义参数hive.proxy.enable=true,当值为true时开启guardian以代理的方式执行任务。
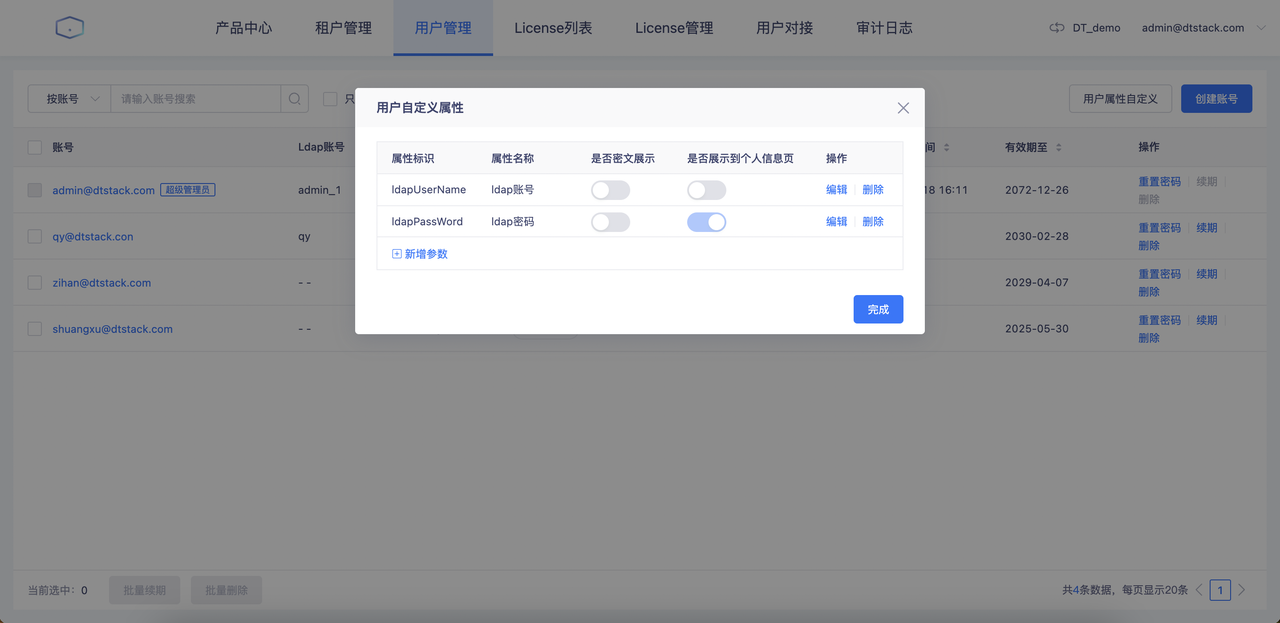
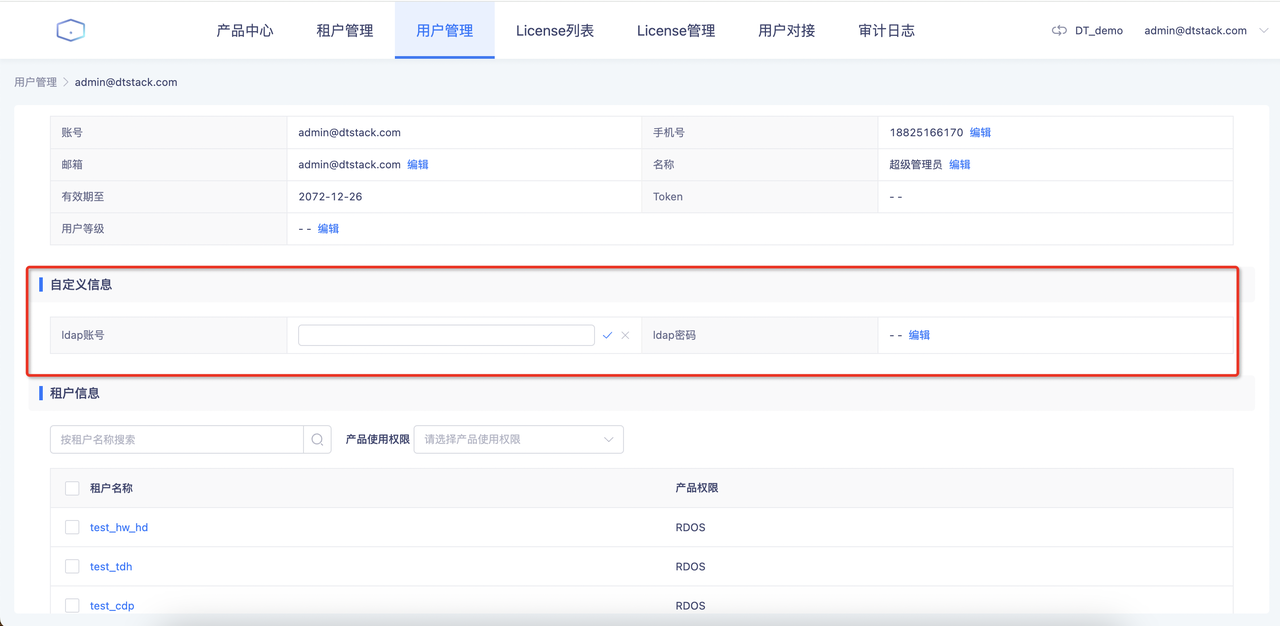
进入「用户中心-用户管理」页面,新增用户自定义属性ldapUserName、ldapPassWord。新增之后可以在账号详情页面编辑属性值。ldapUserName、ldapPassWord的value会映射回对应的guardian代理用户。
若当前租户绑定的「集群配置」中已经配置了Ranger和Ldap,就不需要配置自定义属性ldapUserName、ldapPassWord了。