服务编排
服务编排,可以按照业务逻辑,以串行、并行和分支等结构编排多个API及函数服务为工作流。
服务编排默认为关闭状态,需进入「项目管理」模块开启服务编排功能。开启的必要条件是Server部署2台及以上,且至少1台单独用于服务编排,服务编排开启后不可关闭。
适用场景
服务编排,是将多个API以一定的形式相互组合起来,当某些API仅存在部分信息,需要与其他API联合起来使用时,使用服务编排可降低调用方的成本,几种典型场景:
1+N模式:入参相同,一次调用多个API
假设:最近2年的订单数据存储在HBase中,当日的订单数据存储在MySQL中,业务上需要根据某个订单的唯一id查询,因此订单数据可能在HBase中,也可能在MySQL中。
传统的开发方式:
- 管理员:在API平台中创建一个查询历史订单的API(
order_hist),创建一个查询当日订单的API(order_today)。 - 调用方:申请两个API的权限
- 调用方:在业务端的代码中,分别调用2个API,将二者的查询结果集合并,得到最终结果。
基于服务编排的开发方式:
- 管理员:前2步与传统方式相同,均需配置2个基础API。
- 管理员:创建服务编排(
order_all),通过「函数」将order_hist和order_today的结果集合并,最终返回唯一的订单信息。 - 调用方:直接申请并调用
order_all即可,无需关注内部逻辑。
串连模式:将第一个API的查询结果作为入参,调用第2个API
假设:当前存在2个API:用户信息(user_info)和订单信息(order_info), user_info的返回值中包含着当前未结束的订单id(Column : unclose_order_id)。现需要先得到用户信息,根据用户信息中的user_info.unclose_order_id作为入参,调用order_info,查询此用户的未结束订单。
传统的开发方式:
- 管理员:在API平台中分别创建用户信息(
user_info)和订单信息(order_info)两个API。 - 调用方:申请2个API的权限。
- 调用方:在业务端代码中编写如下逻辑:先调用
user_info,得到查询结果,再将结果中的unclose_order_id作为入参来调用order_info,得到此用户的订单信息。
基于服务编排的开发方式:
- 管理员:前2步与传统方式相同,均需配置2个基础API。
- 管理员:创建服务编排(
user_info_order),通过服务编排上下游,将user_info和order_info两个API串连起来,得到最终结果。 - 调用方:直接申请并调用
user_info_order即可,无需关注内部逻辑。
条件判断模式:根据不同的入参调用不同的API
与第一种1+N的模式类似,但略有不同:
1+N模式:每次都会将N个API调用一次。
条件判断模式:根据入参的不同情况,只调用下游的某一个API。
假设:最近2年的订单数据存储在HBase中,当日的订单数据存储在MySQL中,业务上需要根据:是否历史订单(0/1)+订单唯一id来查询。当为历史订单时,只查询HBase,当日订单时,只查询MySQL。相比场景1的处理方式,可对2个数据库分别降低50%的查询负载。
传统的开发方式:与场景1相同。
基于服务编排的开发方式:
- 管理员:前2步与传统方式相同,均需配置2个基础API。
- 管理员:创建服务编排(
order_all),通过「条件判断」,判断「是否历史订单」的值,为0时调用order_today,为1时调用order_hist。 - 调用方:直接申请并调用
order_all,入参增加一个「是否历史订单」的参数。
- 只有租户管理员及以上角色才有服务编排、函数的权限
- 条件分支节点底层基于Python2.x执行,受限于Python的执行性能,不建议将服务编排用于高并发或大量复杂计算的场景
服务编排
服务编排的创建入口与创建普通API类似,进入「API管理-API管理-API」页面,点击「创建服务编排」按钮即可。
基本信息配置
服务编排的基本信息配置与普通API类似,不再赘述。
高级配置
画板
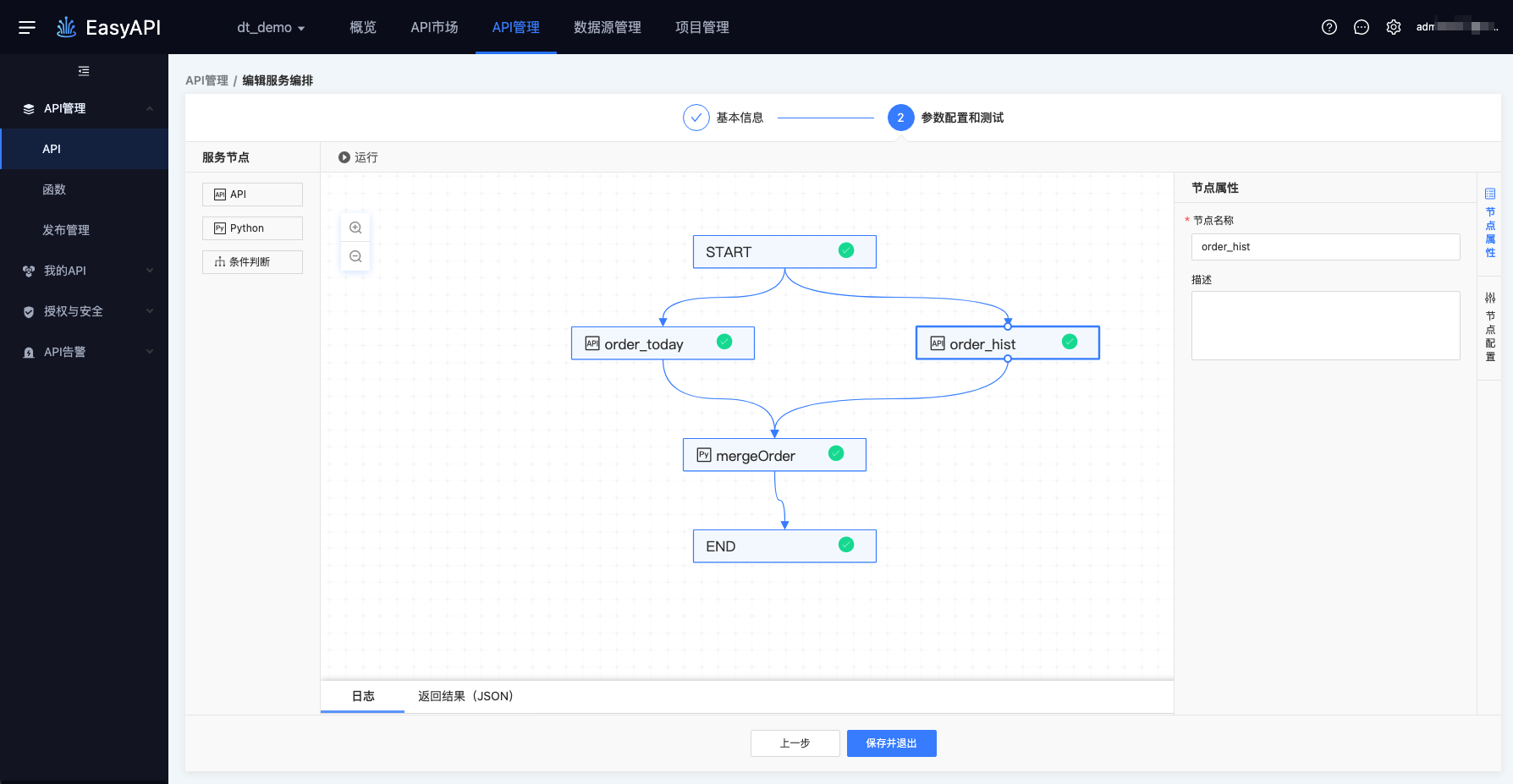
如下图所示,进入服务编排编辑页面,中心为画板区域,可从左侧「服务节点」区域拖拽各类节点进入画板。可在画板中通过拖拽的方式编辑工作流。
START、END节点是无法删除的固定节点,代表着服务编排的开始和结束。
构建依赖关系:鼠标Hover在每个节点的顶部或尾部,按住左键进行节点之间的连线。
可点击右键,删除依赖关系。
用户可拖拽各类服务节点至画板,和已有的START、END节点相连以配置服务编排逻辑, 相连的节点间存在依赖关系(右键单击可解除)。
其他约束条件:
- START节点可有多条输出连线
- API、Python节点必须同时有输入输出连线
- END节点只能有1条输入连线
- 所有连线不可成环
节点传参
使用服务编排,需首先理解各节点之间的传参方式,各节点间均是基于JSON方式进行传参,从头部的Start节点开始,至中间的各个节点,均采用JSON形式取Key和Value的值。可在后文的具体示例中查看参数填写方式。
可通过JSON Path的方式获取对应的Key/Value,若JSON为数组,也可以采用数字下标方式访问,如下表:
| JSONPath表达式 | 含义 |
|---|---|
| $. | 获取节点的根对象 |
| $.param | 获取节点根对象的param参数值 |
| $.param[0] | 获取节点根对象的param参数中的第1个值 |
管理节点
START节点
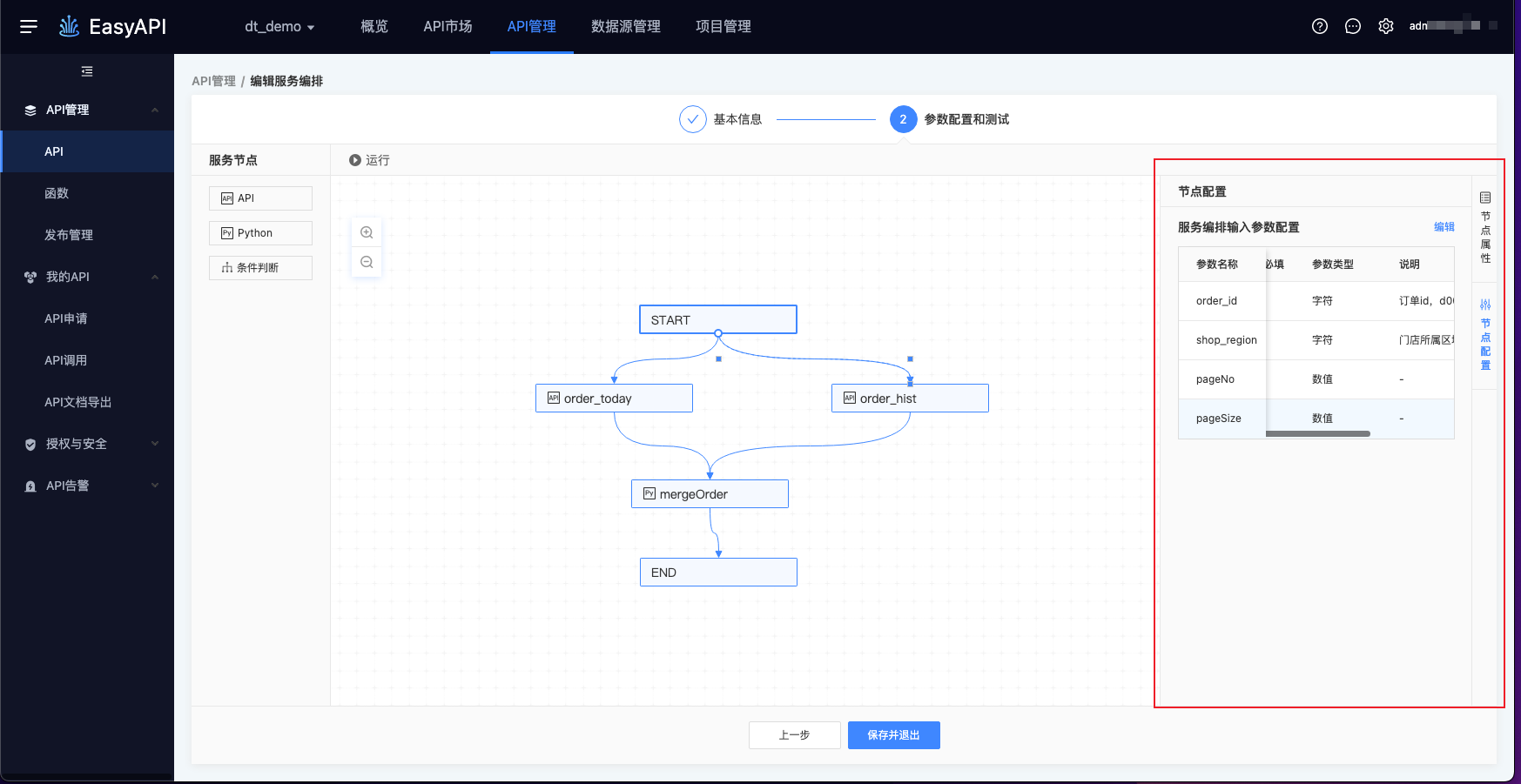
START作为统一外层参数传递入口,在画布中是固定无法删除的。START入参的定义,可通过右侧面板的「节点配置」来配置,START本身并不处理入参,而是将入参传递给下游的各节点。
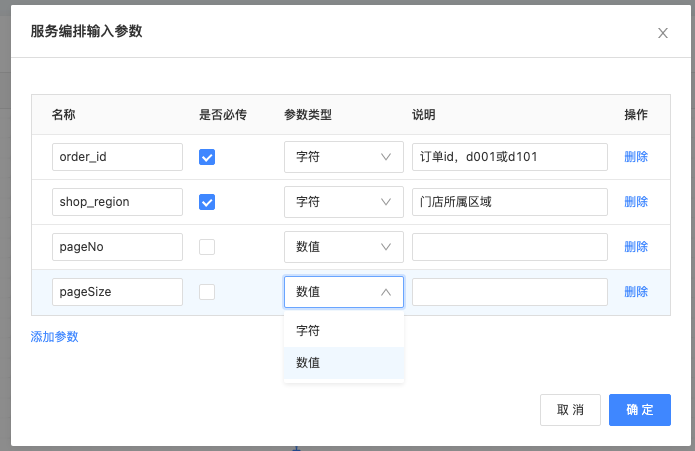
点击「节点配置」面板的「编辑」,可在弹窗中编辑START节点的入参。点击弹窗左下角的「添加参数」后,在列表中添加一个入参,每个入参包含如下信息:
- 名称:入参的Key,中间不能包含空格,建议使用英文字符开头,不建议使用中文等特殊字符。
- 是否必传:在调用服务编排时,此参数是否必填。
- 参数类型:仅支持字符、数值两种类型。
- 配置输入参数校检验表达式:可参照API创建>高级配置中参数说明创建API
- 默认值:参考创建API默认值
- 说明:参数的说明内容。
在上述截图中,入参的order_id和shop_region作为START节点的入参,将传递给下游的order_today和order_hist两个API中作为入参,详见下面的场景示例。
END节点
EDN节点比较简单,表示服务编排的结束,END节点本身不做任何数据处理,服务编排的返回结果在于END上游节点的返回结果。
由于END不做任何数据处理,所以END节点只能有一个实际的上游(1条实线或者多条虚线连接),当使用条件判断节点时会遇到虚线,1条实线表示1个实际输出数据的上游,而多条虚线表示只会有1个实际输出。所以END节点只能有1个上游的实际输出。
API节点
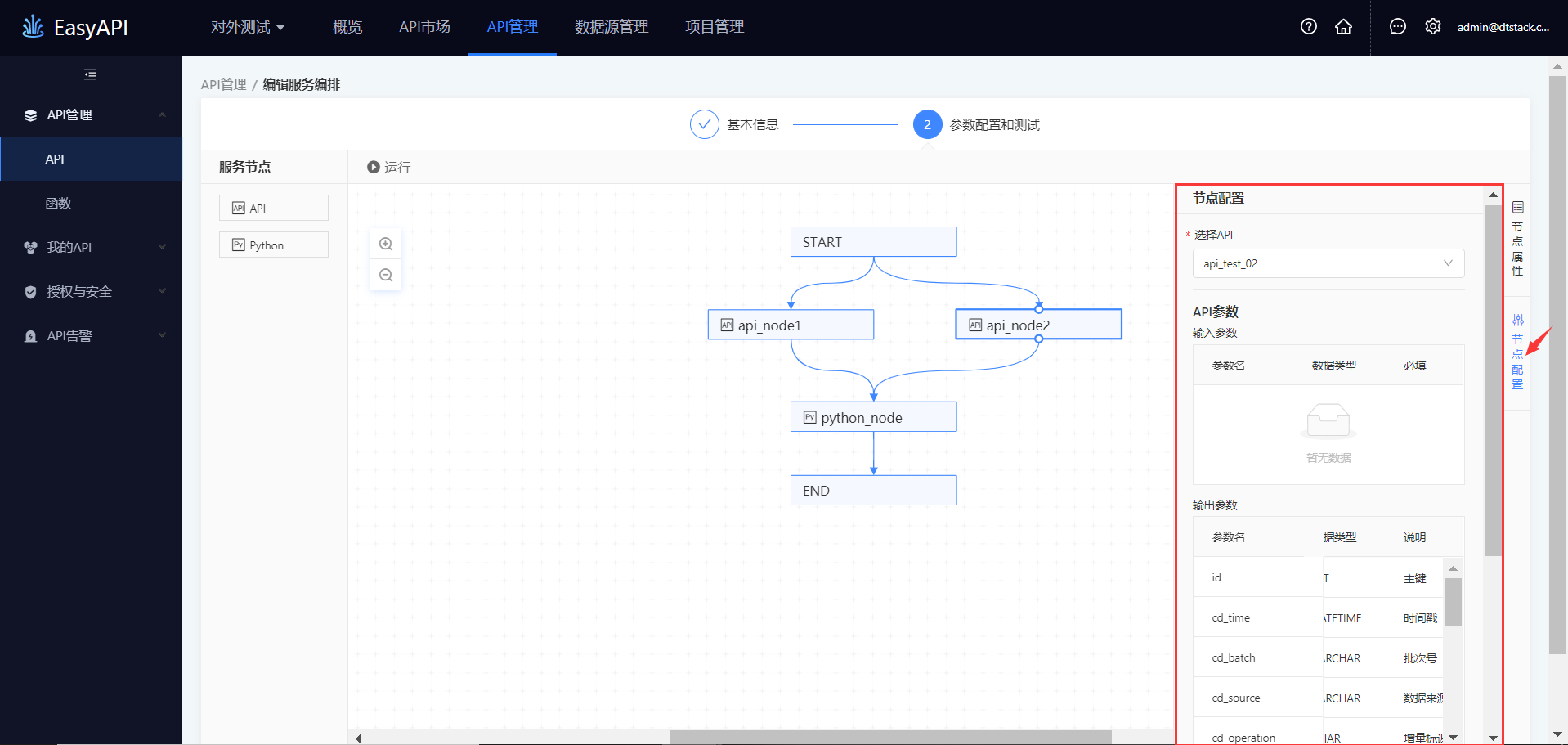
API节点表示调用指定的API,从「服务节点」区域拖拽API节点至画布中,需在右侧面板配置:
调用哪个API:进入「节点配置」面板,选择API,只能选择已保存、已提交、已发布状态的API。
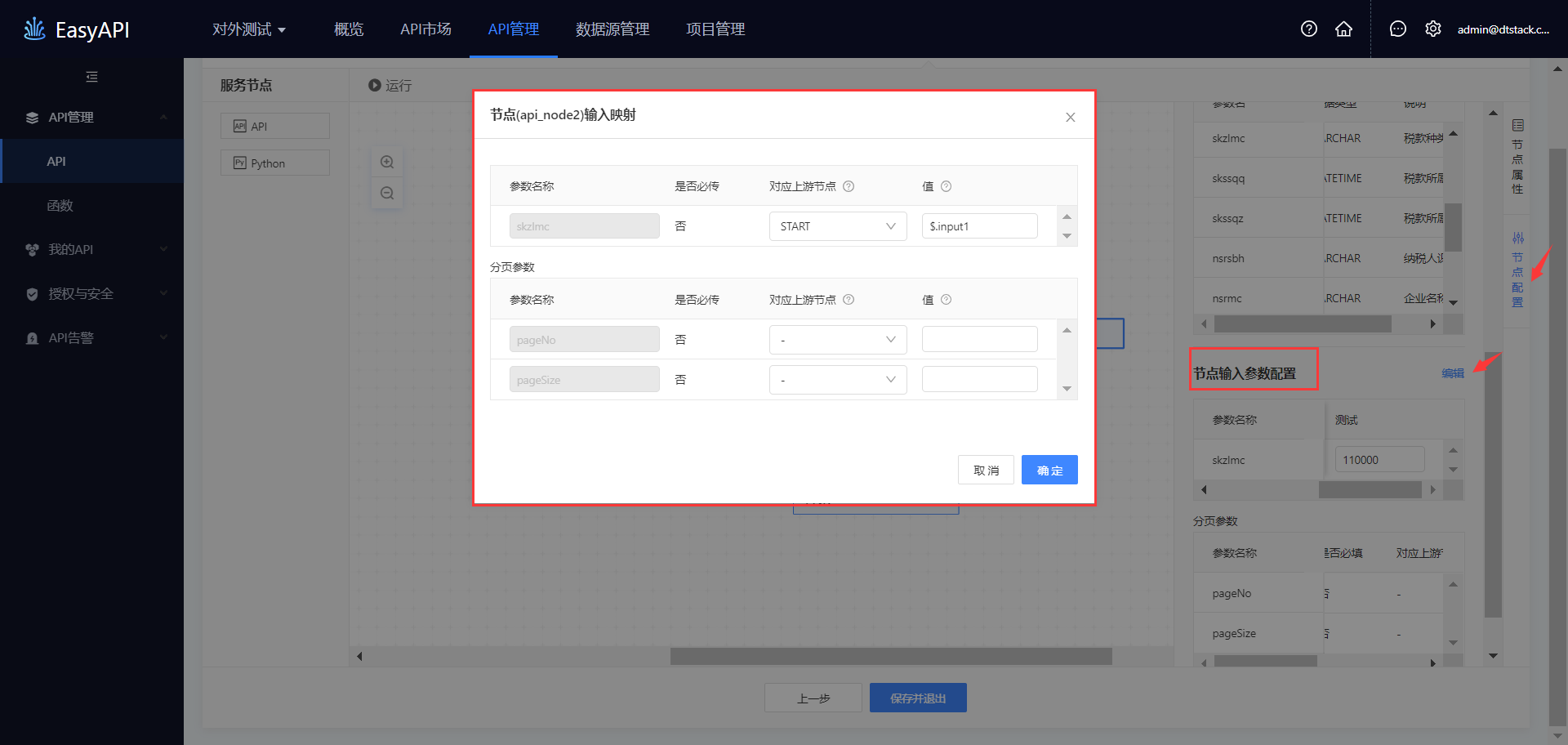
调用API时的入参:在「节点配置」面板,查看「节点输入参数配置」,可点击「编辑」按钮,在弹窗中编辑API的入参。
节点名称:进入「节点属性」面板,输入节点名称,节点名称仅支持中文、英文、数字、下划线。
描述:在「节点属性」面板输入此节点的描述,不超过256个字符。
API节点输入参数配置
是否必传:「是否必传」选项为「是」时,正式调用时必须输入json格式的入参。
对应上游节点:当前节点的输入参数与其上游的一个或多个节点的输出字段映射关系,字段的可选范围为与该节点有直接连线的上游节点,“-”表示该节点无上游关系。
示例:api_node2节点skzlmc参数的入参由START节点传递,故api_node2需先于START节点构建连线关系,START节点存在指向api_node2的箭头,并通过
$.input1识别START节点传递的参数。值:上游节点为API、Python时必填,填写内容为JSON Path格式,上游节点为Python时JSON Path格式区分大小写。
分页参数:API实际输出如果超过1000条,默认以1000条/页的形式进行分页。用户可通过START节点传参的方式指定获取某页的API输出内容,若不指定,系统默认获取第一页内容(即前1000条数据),用户可通过配置文件修改每页可获取的记录数。但需注意的是,每页可获取的记录越多,服务编排运行的整体耗时越长,性能会受到一定影响。
Python节点
Python节点在服务编排过程中可以对数据进行简单的加工和处理。用户配置Python节点后,还需配置「节点名称」、「描述」、「选择Python函数」以及「节点输入参数配置」
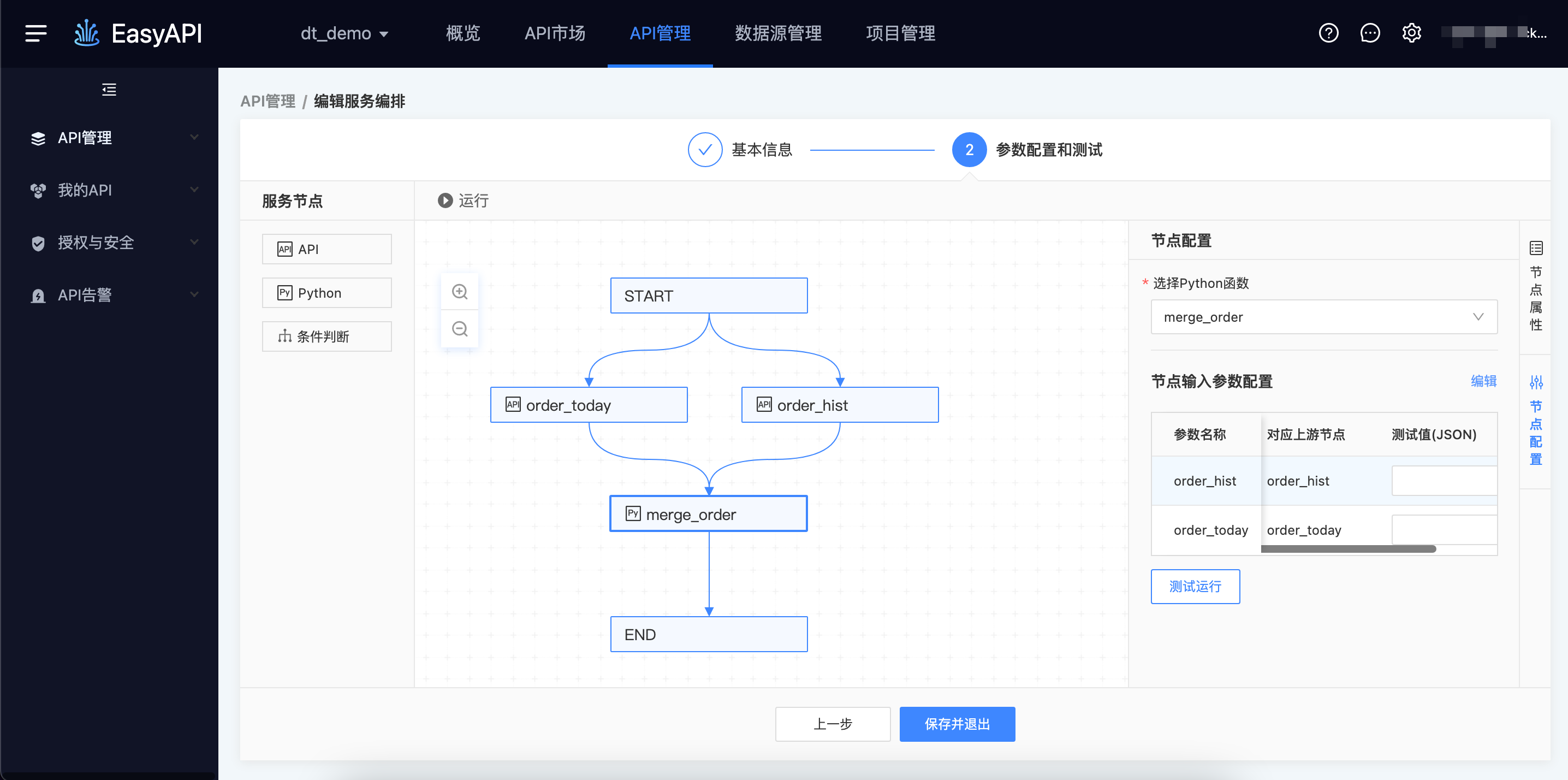
节点名称、描述:与API类型节点相同。
选择Python函数:可选择已经保存的函数,当需要对服务编排测试时,需自行保证函数的逻辑正确性。
节点输入参数配置:
Python节点的输入参数,是在Python函数创建时定义的,在服务编排画板中,只需维护Python上游节点与其入参的对应关系。上游节点的全部查询结果将传递给Python节点。
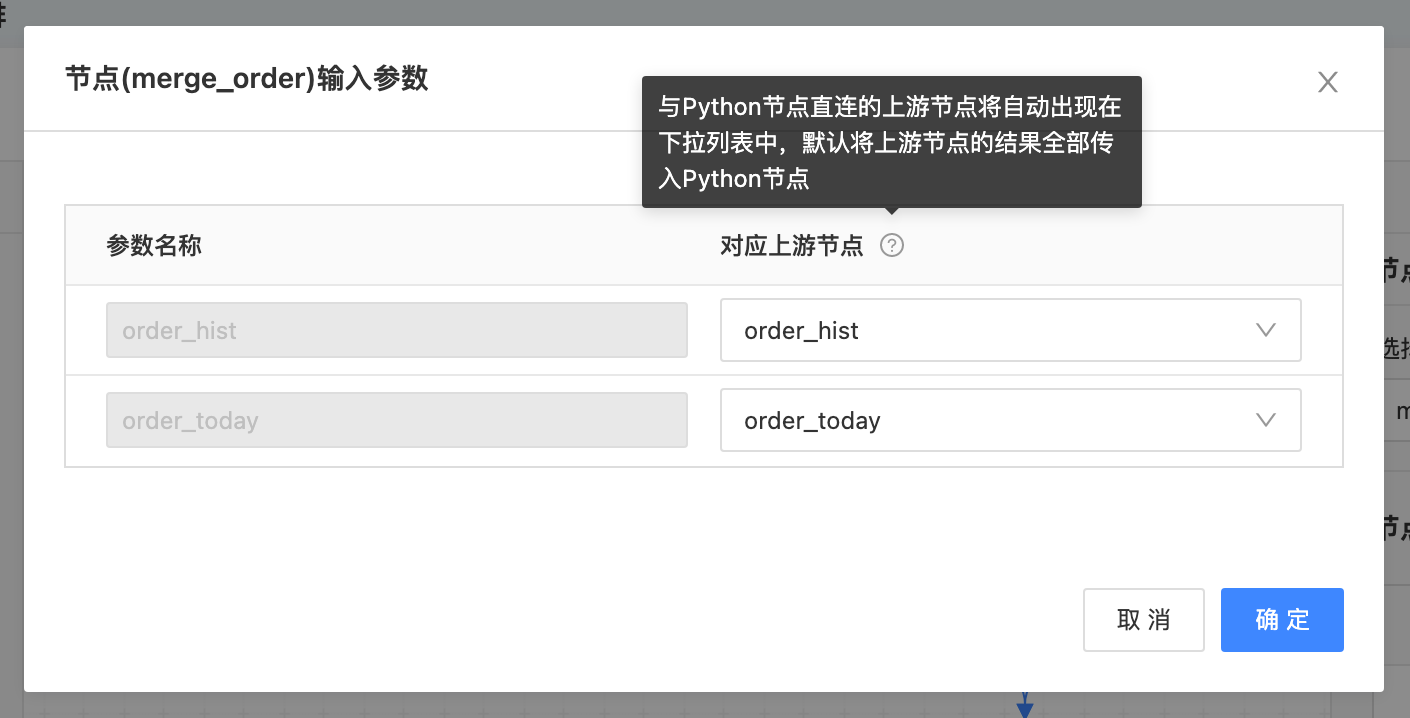
默认将上游节点的结果全部传入Python节点,当上游结果为数组时,需在Python中按数组的方式处理。
条件判断节点
条件判断节点的具体场景,可参考条件判断模式:根据不同的入参调用不同的API,当用户需根据入参的不同情况来调用下游的某一个API时,适合使用条件判断节点。
用户从左侧的「服务节点」拖拽「条件判断」节点至画布中,并配置参数,如下图所示:
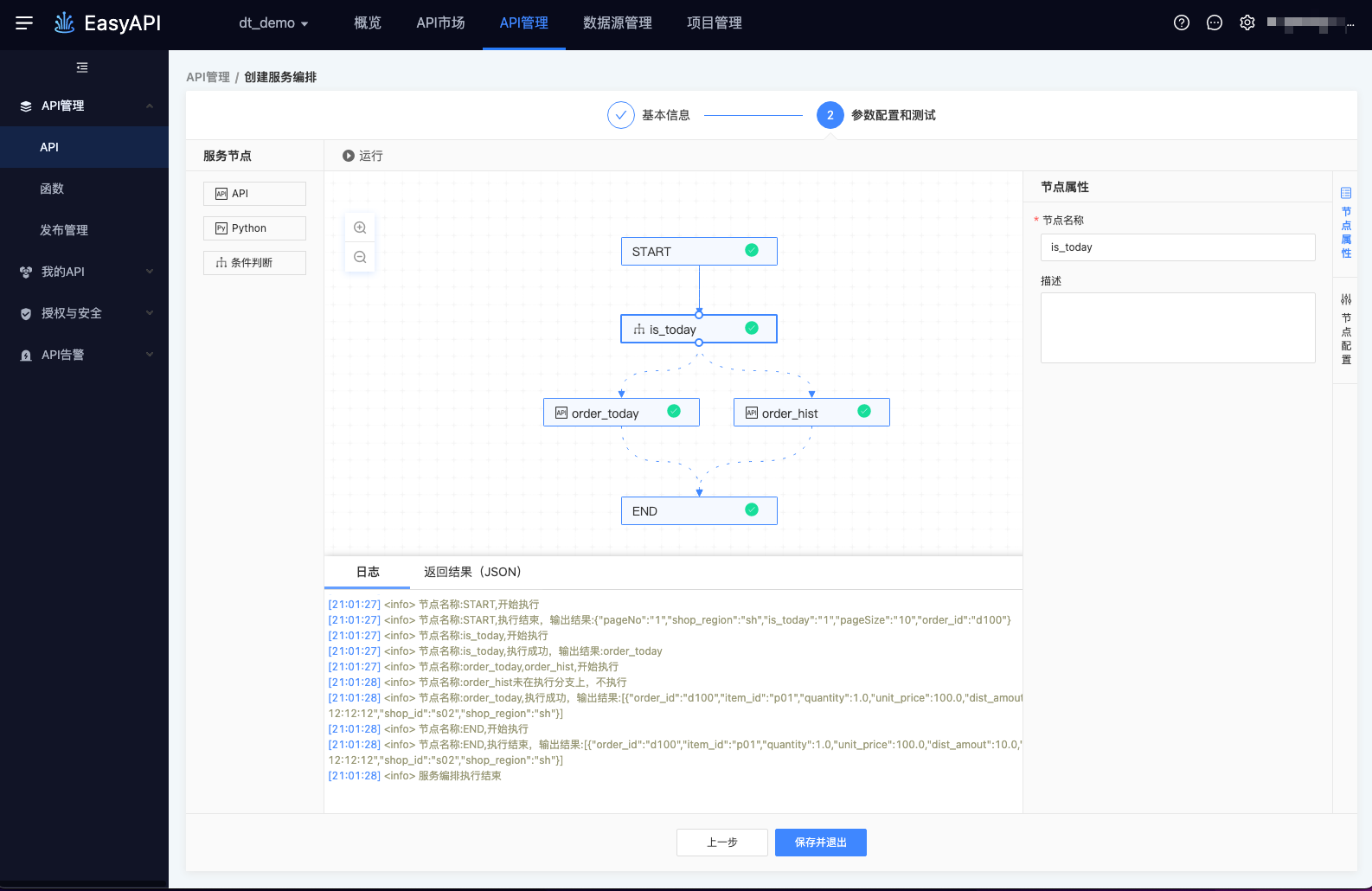
条件判断节点的参数配置参数如下:
- 节点名称、描述:与API类型节点相同。
节点输入参数配置:条件判断节点仅支持1个入参,需配置:
- 参数名称:不同于API或Python节点,条件判断节点的参数名称需用户填写,需要与上游节点的输出参数的
key相对应。 - 参数类型:仅支持数值、字符两种。
- 是否必传:此参数是否必传。
- 对应上游节点:本节点的输入参数,从哪一个上游节点来。
- 值:上游节点输出的哪一个值(
key)将作为本节点的输入。
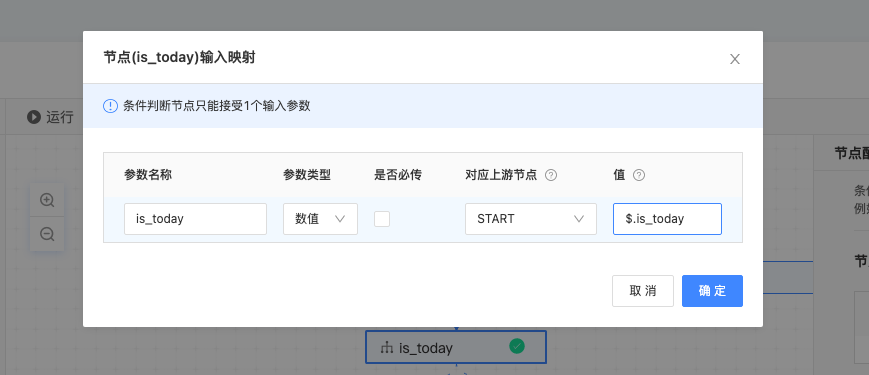
节点输出配置:即条件判断的具体逻辑,根据输入的不同情况,调用下游的不同API:
操作符:支持
=、>、>=、<、<=、!=、in、not in、like、not like、is null、between操作符,使用方式如下:操作符 适用范围 备注 =、!=数值 / 字符 >、>=、<、<=数值 in、not in数值 / 字符 可以通过英文逗号分割输入多个值,不支持指定分隔符。 like、not like字符 必需包含至少一个 %字符。is null数值 / 字符 判断输入为空,依然是需要 key存在,value为空。当key不存在时,需配置入参为非必填。between数值 判断数值是否在某个开/闭区间,例如[3,5)表示>=3且小于5。 值:根据不同的操作符填写不同的判断数值。
调用API:当满足当前的条件时调用的API,注意需提前在画布中配置好下游API的连线,才可以选到API。
顺序调整:在条件判断节点中,系统将按从上到下的顺序依次判断是否满足条件,第一个满足条件的API将被正常调用,之后立即停止剩余条件的判断。当有多个API同时满足条件时,系统只按顺序调用第一个满足条件的,剩余的API不会被调用。
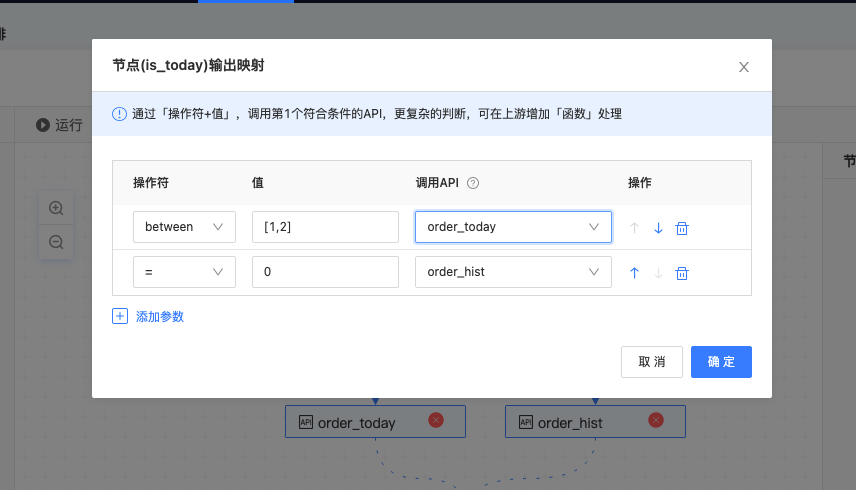
若有更复杂的条件判断时,建议在上游增加「函数」进行个性化处理。
条件判断与连线类型
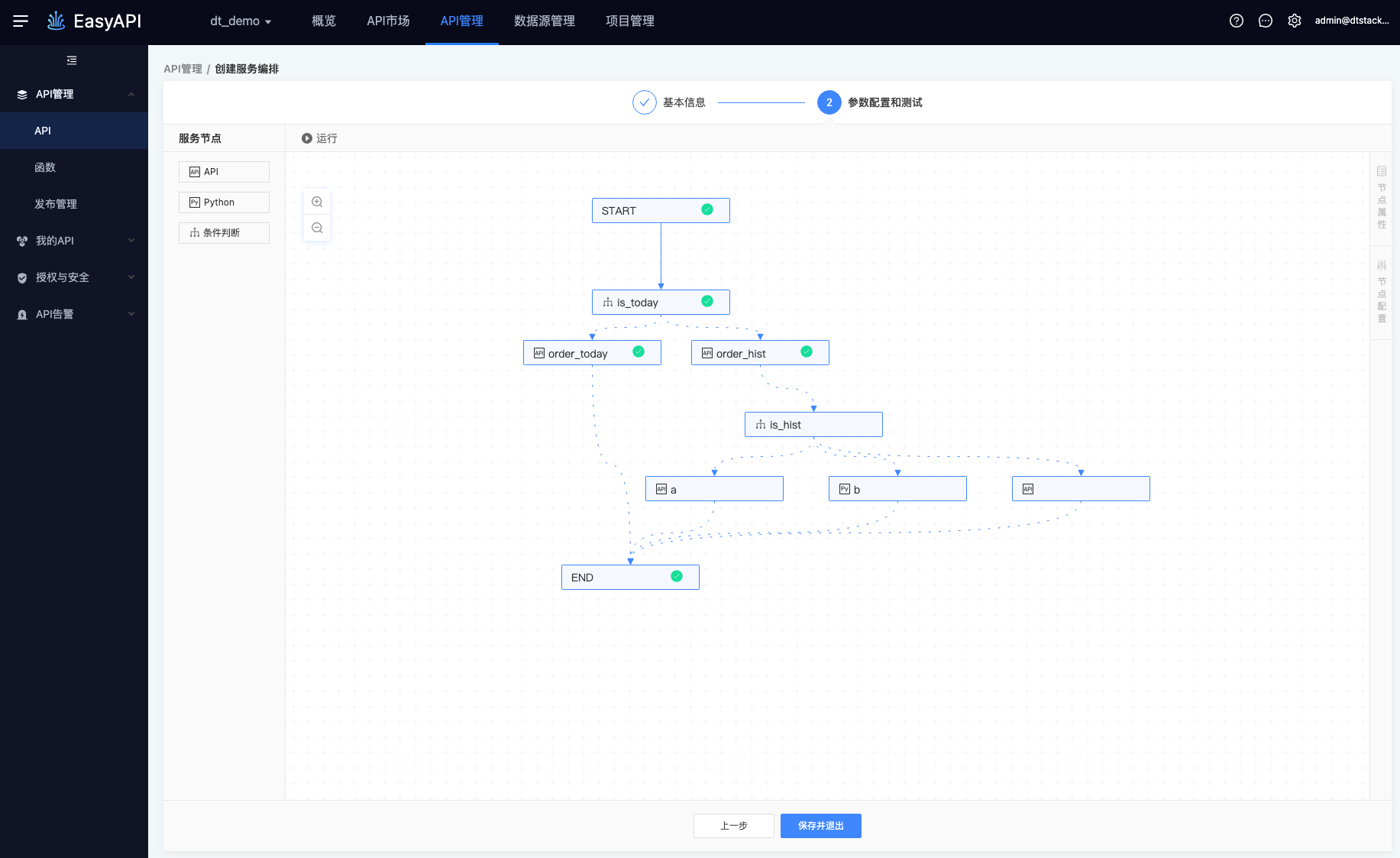
当画布中出现条件判断节点时,与条件判断节点直接、间接相关的节点将会以虚线的形式显示。虚线表示在实际调用时仅会有一条连线被实际调用,也就是说:以虚线的形式连接,表示不一定发生实际调用。
因此,出现条件判断节点时,其下游均会以虚线的形式存在,表示实际只有一条线被调用,如下图所示:
运行与测试
在服务编排完成各项配置后,可对单点测试或进行完整的服务编排测试。
单点运行
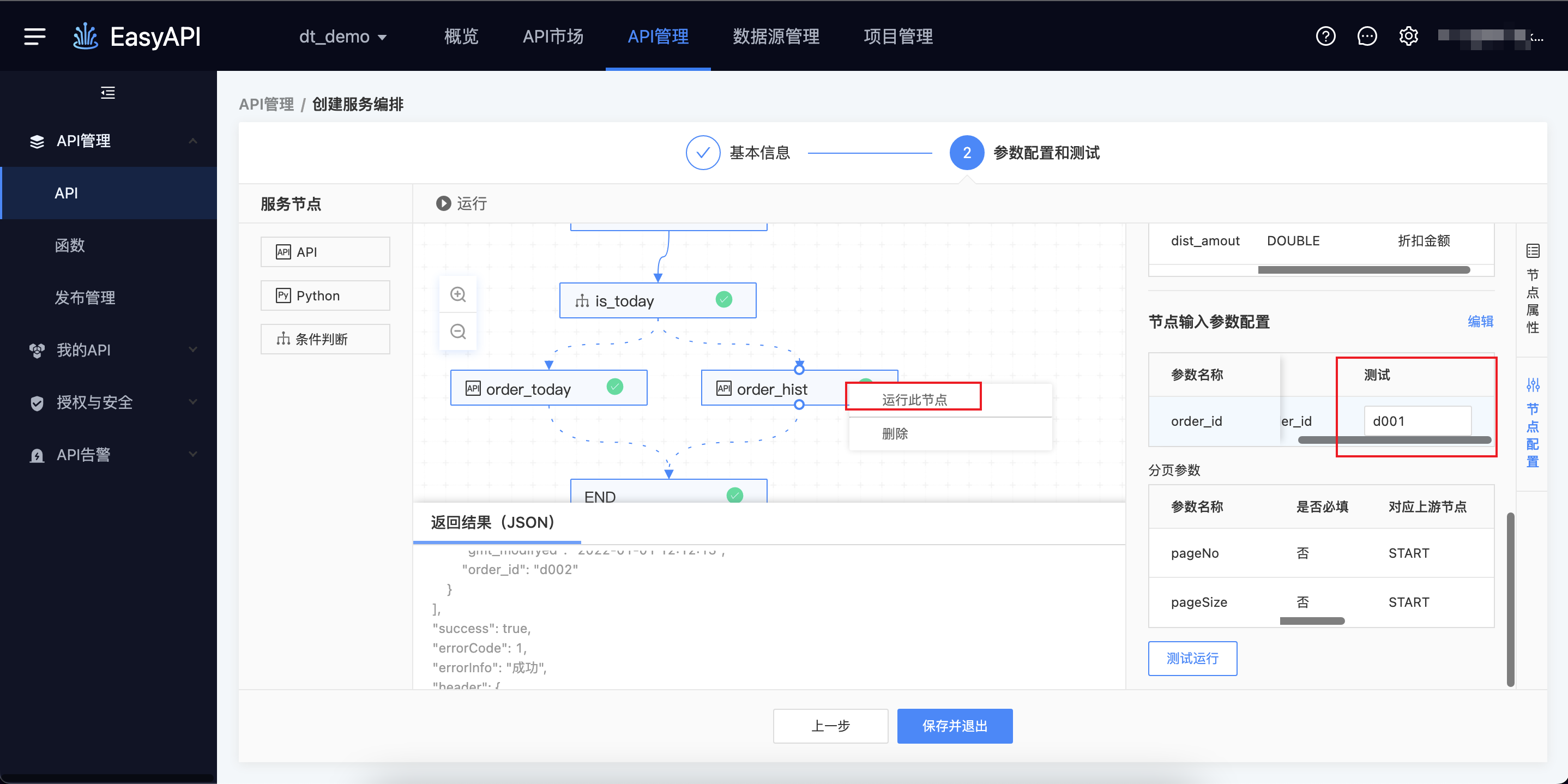
以JSON格式填入测试值,右键单个节点后,点击「运行此节点」可对单个节点的提交版本进行测试。
- 以API节点为例,在此节点的「节点配置」面板中,找到「节点输入参数配置」,在入参最右侧的「测试」栏中输入测试值。
- 完成测试值输入之后,右键点击「运行此节点」按钮,可触发运行。
- 点击完成后,可在下方查看运行日志。
- API节点,其运行日志与调用API获取的返回结果相同。
- Python节点的运行日志包括过程日志、输出结果(JSON)和输入参数(JSON)。
- 条件判断节点不支持单点运行测试。
全流程运行
点击START节点后,可在右侧面板输入START节点的测试值,之后点击左上方的「运行」按钮,系统基于START节点中的测试值运行服务编排所有节点,获得最终结果。
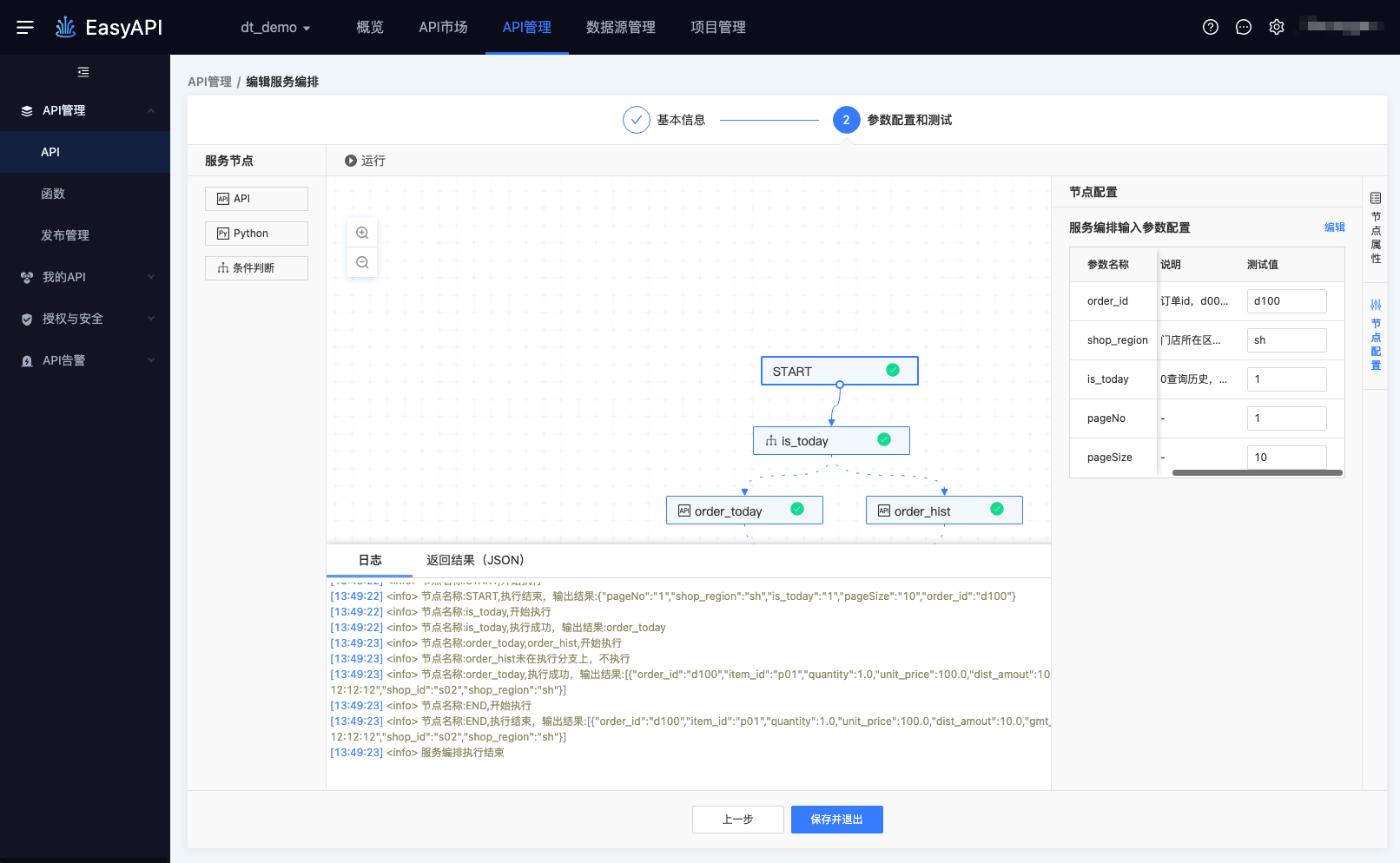
- 有一个节点运行失败时整个流程停止运行。
- 服务编排一旦执行无法人为终止,建议在本地调试完毕后再于本服务中测试。
函数管理
Python函数是服务编排的重要组成部分,可支持将多个API的输出结果整合为一个结果输出。进入「API管理-API管理-函数」菜单,可查看、新增或编辑函数,主要包括如下信息:
基本信息
- 函数名称:只支持英文、数字、下划线,且须以英文开头,同一项目内不允许重名。
- 运行环境:支持Python 2.7以及python3.9。
- 所属文件夹:只支持选择叶子结点中的文件夹。
- 描述:对函数的文字描述。
代码编写
函数具体信息配置的页面如下图所示:
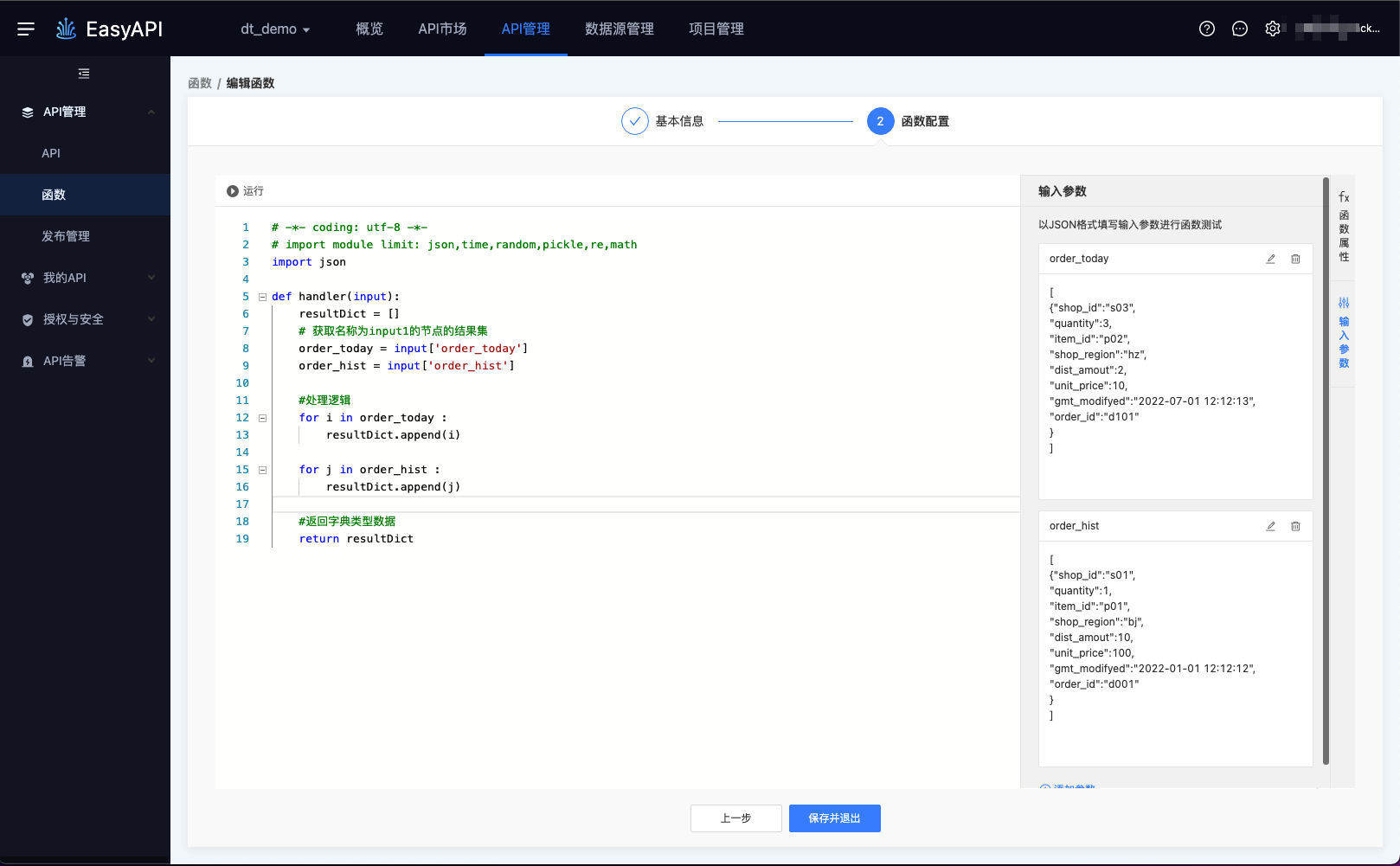
- 函数处理入口:
handler,注意此函数名称不可修改,且只能有唯一的1个。 - 依赖包:系统默认引入json依赖包(基于Python 2.7),目前平台支持引入的包包括module, limit, json, time, random, pickle, re, math, datetime, hashlib, requests, httplib2, marshmallow, urllib2, fernet。
入参与返回
入参的配置
入参的名称、样例值,用户需在右侧的「输入参数」面板中配置,如上图所示,入参包括2部分:
- 参数名称(
key):只支持英文、数字、下划线。 - 入参样例(
value):样例仅用于函数的测试,便于用户验证函数逻辑。样例数据必须以JSON格式传入,支持JSON数组。
- 这里的输入样例需结合函数实际使用的场景,例如上游为API的查询结果,可能为数组,则这里需输入数组。
- 每个函数至少配置1个入参,不超过20个。
入参的获取
在Python代码中获取入参,是通过在handler函数中的input方法,通过入参的 key值来获取value,例如:
# ……
def handler(input):
api1 = input['input_key'] ## 这里根据入参的key来获取value
## ……
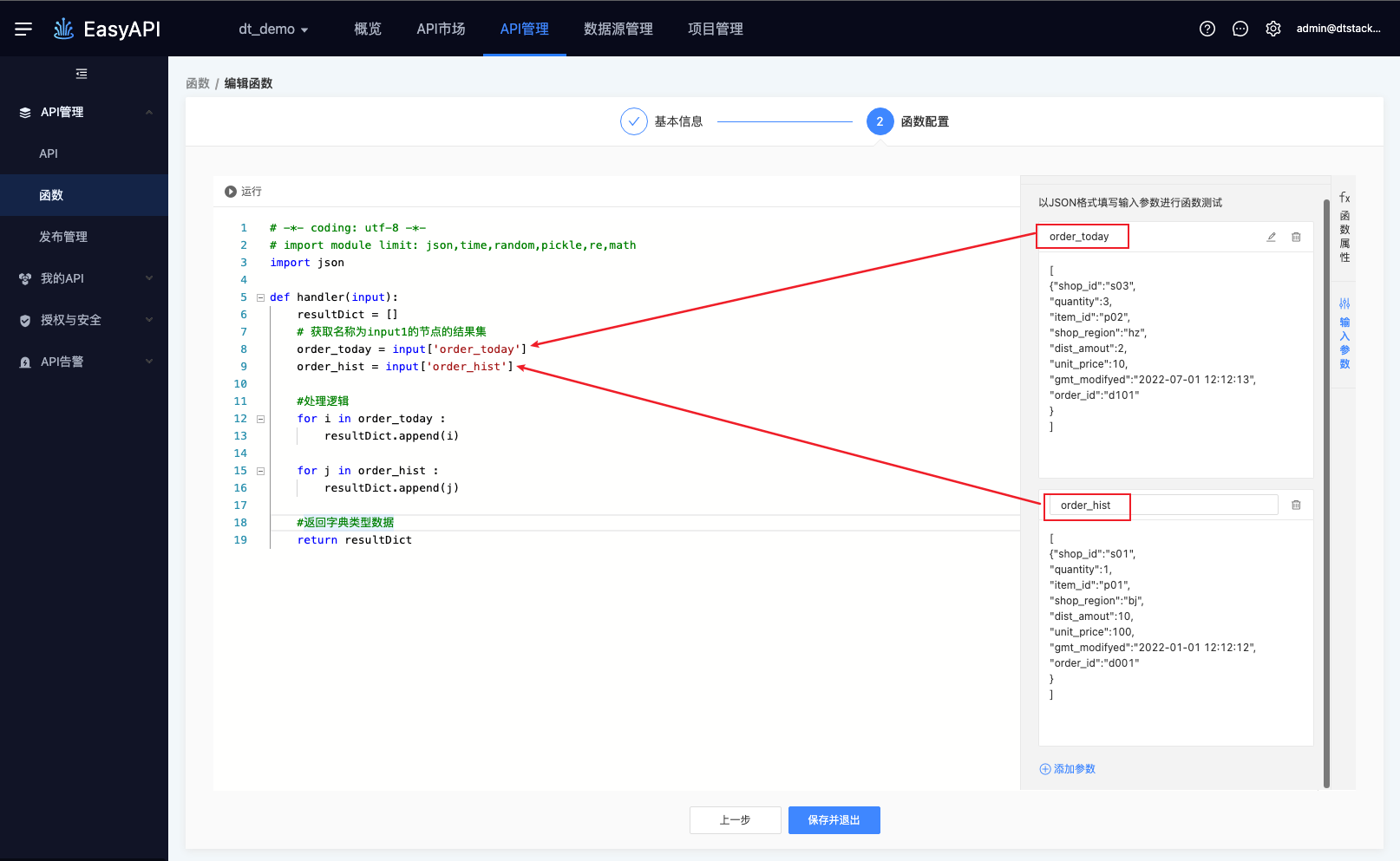
函数的返回
函数的返回是通过Python中的return语句返回,用户可根据情况修改此变量名,但仅支持返回字典型数据。
上述代码原文:
-- 函数处理逻辑:获取order_today和order_hist的返回结果,将2个结果合并为一个数组后返回
# -*- coding: utf-8 -*-
# import module limit: json,time,random,pickle,re,math
import json
def handler(input):
resultDict = []
# 获取名称为input1的节点的结果集
order_today = input['order_today']
order_hist = input['order_hist']
#处理逻辑
for i in order_today :
resultDict.append(i)
for j in order_hist :
resultDict.append(j)
#返回字典类型数据
return resultDict
-- order_today入参
-- 入参名称:order_today
-- 入参样例:
[
{
"shop_id": "s03",
"quantity": 3,
"item_id": "p02",
"shop_region": "hz",
"dist_amout": 2,
"unit_price": 10,
"gmt_modifyed": "2022-07-01 12:12:13",
"order_id": "d101"
}
]
-- order_hist入参
-- 入参名称:order_hist
-- 入参样例:
[
{
"shop_id": "s01",
"quantity": 1,
"item_id": "p01",
"shop_region": "bj",
"dist_amout": 10,
"unit_price": 100,
"gmt_modifyed": "2022-01-01 12:12:12",
"order_id": "d001"
}
]
函数属性
函数属性中记录了一些基本信息,函数的名称、 创建人、版本、引用情况等,可点击右侧的「函数属性」面板查看。
- 历史版本:记录每一个版本的提交时间和发布时间,若一个提交版本存在多次发布,只记录第一次发布时间,无发布时间记为“-”
- 引用信息:记录引用此函数的特定状态下的服务编排(特定状态包括已保存、已提交、已发布)
测试运行
点击「运行」按钮后,用户可在下方的执行结果中查看返回结果,运行成功的函数才可以提交,提交后可使用第三方工具进行测试。
Python函数一旦执行无法人为终止,建议Python代码在本地调试完毕后再于本服务中测试。
提交
用户完成函数编辑、测试后,需在函数管理列表中点击「提交」、「发布」,当用户需提交/发布整个服务编排时,其所依赖的函数也必需处于提交/发布状态。
函数经测试成功后才可以提交。
服务编排与API、函数的依赖关系
服务编排依赖于API及相关的函数,由于API存在保存、提交、发布等过程,下面对服务编排的操作做说明:
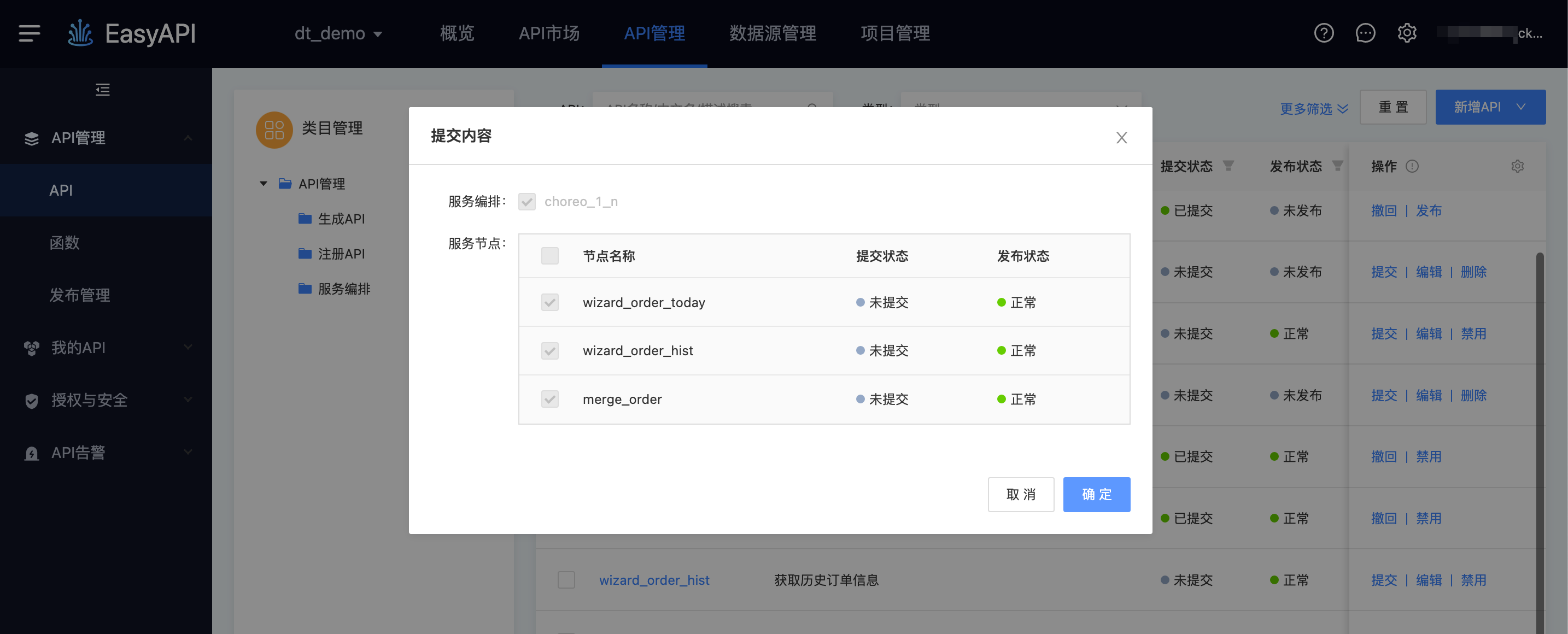
整体上,服务编排与依赖的资源存在「同进退」的关系,大多数情况下,需同时提交、发布、撤回(可选)。
提交:依赖的API、函数需处于「已提交」的状态,否则将对依赖的资源做强制提交,在提交之前用户可查看当前的服务编排所依赖的API、函数等资源。
发布:依赖的API、函数需处于发布正常的状态,若未进行过发布,则在发布服务编排时,将会对依赖的资源做强制发布。
撤回:用户可选择所依赖的资源是否同时撤回,例如在撤回服务编排的同时,一起撤回所依赖的函数或API。
二次发布:当服务编排所依赖的资源已经发布过之后,服务编排在发布时可选择是否同时发布依赖资源,当同时发布时,其所依赖的API、函数将会更新。